






每天给你送来NLP技术干货!
来自:南大NLP

01
研究动机
对齐不同模态的语义是多模态预训练 (VLP) 模型的一个重要能力。然而,VLP模型的内部对齐机制是不可知的。许多研究已经关注到这个问题,其中一个主流方法是通过精心设计的分类探针实验来探究模型的对齐能力[1, 2]。但是我们认为简单的分类任务不能准确地探究的这个问题:第一,这些分类任务仍然将VLP模型当作黑盒子,只能从分类任务的指标上分析模型在某一个方面的对齐效果;第二,很多分类任务只需要使用图片-文本对中的部分信息就可以完成(例如一个区域,一个词组或者两者都使用)。

图1:给出1张图片与6个句子,测试不同的VLP模型会选择哪个句子与图片最匹配
为了进一步说明这一点,图1展示了1张图片和6个句子,其中句子 (a) 是对图片的合理描述,(b)-(f) 是不可读的5个句子。令人惊讶的是,我们测试的5个预训练模型都没有选择合理的描述 (a),这促使我们去深入研究VLP模型会认为哪一种句子是更符合图片的,即从文本视角探究多模态预训练模型的语义对齐机制。
如果人工去生成图1所示的不可读的句子,然后再去测试VLP模型是否对其有偏好是非常困难的,本文则考虑利用自动化的方式生成VLP模型偏好的句子。具体而言,我们可以把VLP模型认为哪个句子更好(匹配分数越大)作为一种反馈,来训练一个多模态生成模型,通过最大化匹配分数来生成为图片生成描述。通过这种方式,生成模型会放大VLP模型对句子的偏好并反映到生成的句子中。所以我们提出一个新的探针实验:使用图像描述 (captioning) 模型,通过分析生成的句子来探究VLP模型的多模态的语义对齐机制。
02
贡献
1.我们提出了一个新的探针实验:使用图像描述模型,通过分析生成描述来探究VLP模型的多模态的语义对齐机制。
2.我们在5个主流VLP模型上进行了探针实验,通过captioning模型生成的句子,分析了每一个VLP模型的语义对齐能力。
3.通过5个VLP模型反映出的对齐问题,总结了目前VLP模型存在的3个缺陷并进行了验证。
03
探针实验与分析
我们选择了5个主流的VLP模型,包括UNITER[3],ROSITA[4],ViLBERT[5],CLIP[6]以及LXMERT[7]。
我们使用COCO数据集作为我们探针实验数据集,使用FC model[8]作为实验的captioning模型。由于VLP的匹配分数不能直接反馈到图像描述模型,所以我们使用SCST[8]的方法来优化。
经过VLP 模型匹配分数的优化后,captioning模型生成的句子可以获得很高的匹配分数(表1左边所示),这说明VLP模型认为这些句子与图片更匹配了。直觉上,这些句子应该更好地描述了图像中的内容,但是我们使用图像描述指标测试这些句子却发现,它们的指标下降了非常多(表1右边所示),这促使我们去检查一下生成的句子发生了哪些变化。
表1:生成句子在图像描述指标和 VLP 模型匹配分数上的测试结果。CE表示使用cross-entropy作为loss训练的基础模型。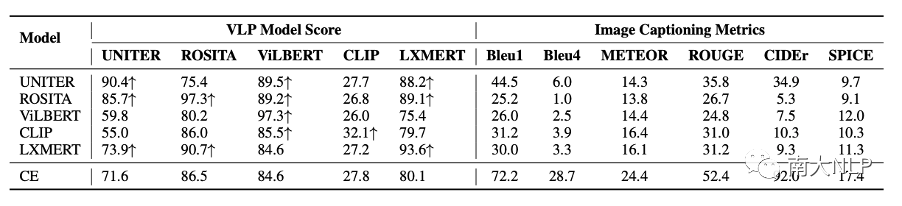
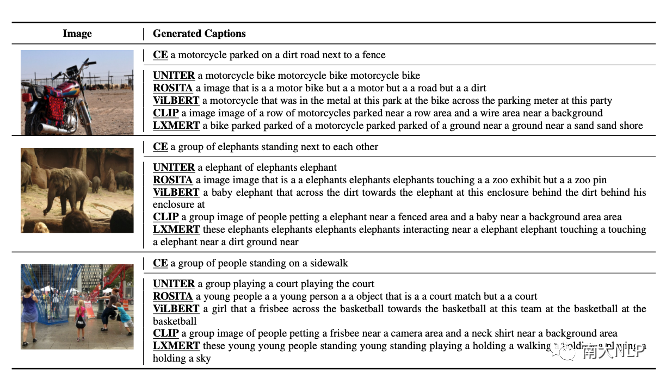 图2经过不同VLP模型的匹配分数优化后生成的句子
图2经过不同VLP模型的匹配分数优化后生成的句子
图2展示了经过匹配分数优化后生成的的句子,我们可以发现几乎所有的句子都已经变得不可读。我们从困惑度 (perplexity), 句子长度,视觉词的数量等角度对这些句子进行定量分析,发现这些句子已经与CE模型生成的句子有了非常大的变化 (如表2所示)。不仅如此,我们还发现每一个VLP模型似乎都对某些固定的句式有偏好,如图2中,被CLIP优化的captioning模型,生成的句子的前缀带 (prefix) 经常含有与“a image of”相关的词组。我们利用正则表达式,对这些句子的句式(pattern)进行进行总结(表3),可以发现每一个VLP 模型都有自己偏好的句式。
表2生成句子的困惑度,长度,视觉词数量的统计信息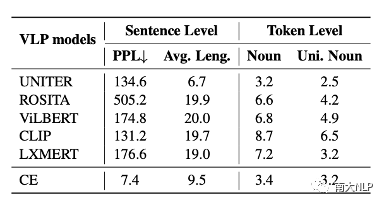
表3生成句子的句式统计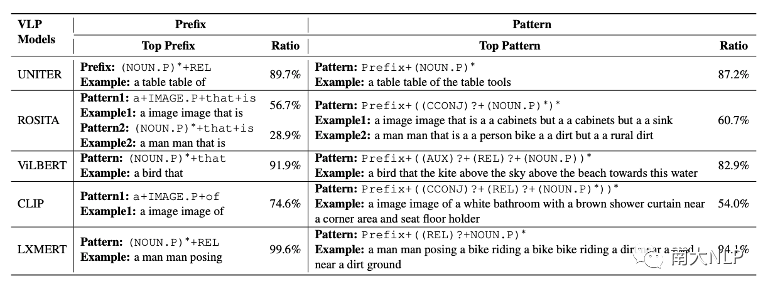
04
VLP模型的缺陷
通过上述对生成句子的定量分析,我们发现现在的预训练模型主要存在3个缺陷。为了验证这3个发现,我们使用了COCO测试集中的5000张图片。
(a)VLP模型在判断一个图片-句子对是否匹配的时候过于依赖图片中的区域特征和句子中的视觉词,而忽视了全局的语义信息是否对齐。
我们对CE生成的句子进行两种处理:替换视觉词 (Replacing visual words)和替换非视觉词 (Replacing other words)。从图3中我们可以发现替换视觉词会使得VLP模型的匹配分数大幅下降,但是替换非视觉词只会让匹配分数下降一点。需要注意的是,替换了非视觉词后的句子是不可读的,但是模型还是会认为这些不可读句子与图片是匹配的。
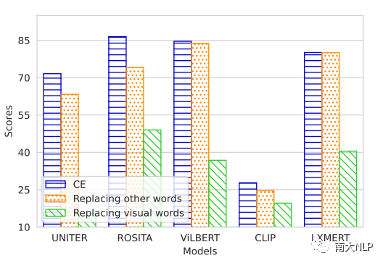
图3替换视觉词与替换非视觉词的匹配分数与原始分数的对比
(b) VLP模型会对偏好某些固定的句式,因此忽视了更重要的文本信息,如流畅度,语法等。
我们利用表3发现的句式,提取出CE句子的视觉词,把视觉词填补到这些句式中。我们仅仅是改变了句子的结构,就可以使得这些句子的匹配分数大幅提高 (表4所示)。
表4重构后句子的匹配分数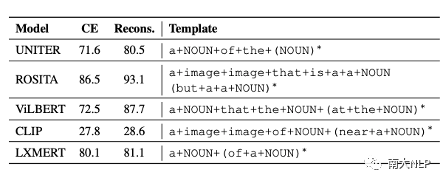
(c)VLP模型认为包含更多视觉词的句子更匹配图片,这会弱化图片中关键物体的作用。
我们把每张图片的ground-truth中的视觉词先提取出来,然后每次填充k (k=3,4,5,6,7) 个到句式模版中。从图4中可以看出,随着视觉词的增加,重构句子的匹配分数越来越高。
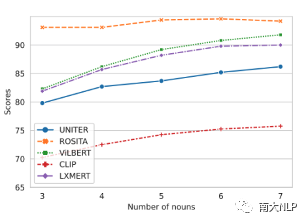
图4含有k个视觉词句子的匹配分数
05
总结
在本文中,我们利用图像描述模型提出一个新颖的探针方法。通过这个方法,我们从文本角度分析了VLP模型的语义对齐机制。我们发现现有的VLP模型在对齐方面有明显的缺陷。我们希望这些发现可以促进研究者设计更合理的模型结构或预训练任务。同时,研究者也可以使用我们的探针方法,分析其设计的VLP模型是否存在缺陷。
06
参考文献
[1] Jize Cao, Zhe Gan, Yu Cheng, Licheng Yu, YenChun Chen, and Jingjing Liu.2020. Behind the scene: Revealing the secrets of pre-trained visionand-language models. ECCV.
[2] Letitia Parcalabescu, Albert Gatt, Anette Frank, and Iacer Calixto. 2020. Seeing past words: Testing the cross-modal capabilities of pretrained v&l models. CoRR, abs/2012.12352.
[3] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. 2019.UNITER: learning universal image-text representations. CoRR, abs/1909.11740.
[4] Yuhao Cui, Zhou Yu, Chunqi Wang, Zhongzhou Zhao, Ji Zhang, Meng Wang, and Jun Yu. 2021. ROSITA: enhancing vision-and-language semantic alignments via cross- and intra-modal knowledge integration. ACMMM
[5] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. NeruIPS
[6] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. ICML
[7] Hao Tan and Mohit Bansal. 2019. LXMERT: learning cross-modality encoder representations from transformers. EMNLP
[8] Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. 2017.Self-critical sequence training for image captioning. CVPR
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~















 4825
4825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









