






来自:圆圆的算法笔记
进NLP群—>加入NLP交流群
GPT获得巨大成功的重要原因之一,就是其利用的in-context learning能力。利用海量的数据训练GPT这种大型语言模型,对于下游的NLP任务,使用一些示例(demonstration)和提示(prompt),就可以让其为我们产生正确答案。这和传统的pretrain-finetune模式有着巨大差异,in-context learning实现了不需要为每个下游任务finetune一个模型,只是给出示例和提示,就能让模型解决目标任务。
那么,in-ccontext learning为什么能不更新模型就达到和finetune相当的效果呢?谷歌和微软近期都发表了针对in-context learning原理的分析文章,它们都将问题的根源指向了一个点:基于Transformer模型的in-context learning的前向传播,和finetune模型中的反向传播,存在着紧密的联系。下面给大家介绍一下文中所阐述的基本思路。
第一篇文章是微软发表的论文标题:Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers。第二篇文章是谷歌发表的Transformers learn in-context by gradient descent。
1
关于in-context learning
In-context learning是随着GPT发展而产生的一种学习方法,它的核心方法是基于预训练的大语言模型(如GPT),将下游任务转换成示例(demonstration)和提示(prompt)的形式输入到GPT中,让GPT生成后续的文本,再将这些文本转换成任务答案。
In-context learning也分为多种类型,如Zero-shot、One-shot、Few-shot等,主要根据demonstration的个数来判定。下图是GPT3论文中的示意图。
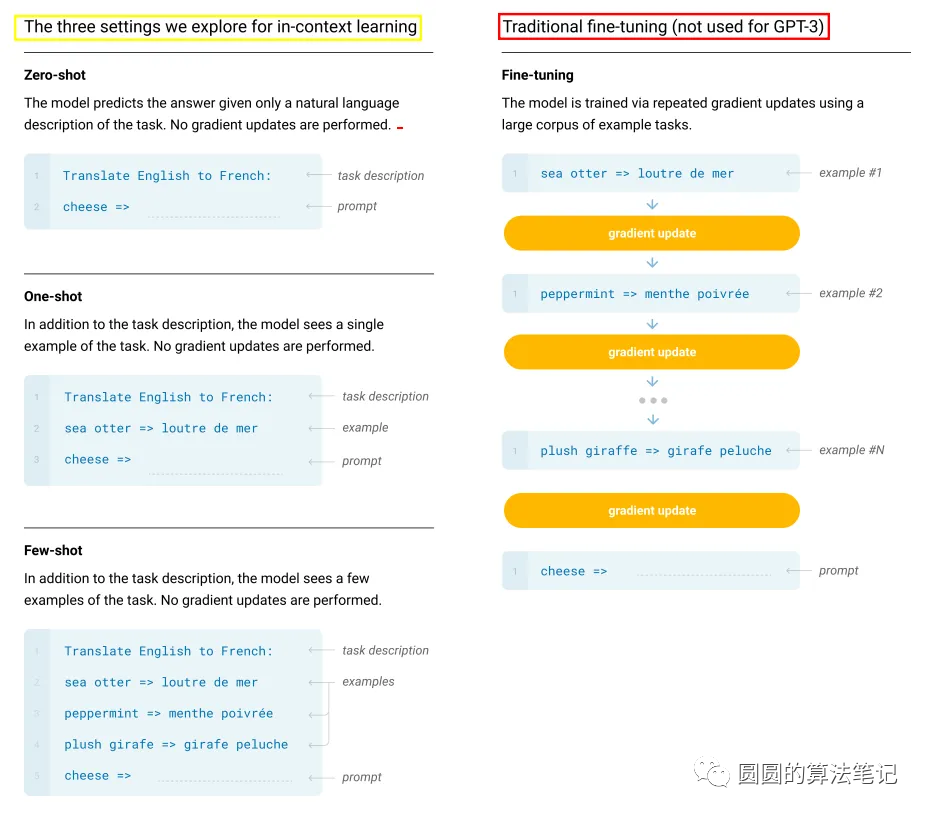
相比传统的pretrain-finetune架构,in-ccontext learning有着巨大的优势。它不需要为了每个子任务生成一个模型,不需要重复性的训练,减少了为了适配下游任务而带来的计算开销,也增强了预训练大模型的可扩展性,将NLP领域推向一个大模型中心的时代。
2
与梯度反传的关系
梯度反传,是深度学习模型训练的一个基本概念,即根据拟合目标,计算各个参数上的梯度,基于这个梯度更新模型参数,以达到模型逐渐向更好的方向对目标进行拟合的目的,这也是模型进行下游任务针对性finetune的原因。而最近微软和谷歌的论文指出,in-context learning其实就是在做梯度反传,下面我们以微软的文章为例,介绍一下in-context learning和梯度反传之间的关系。
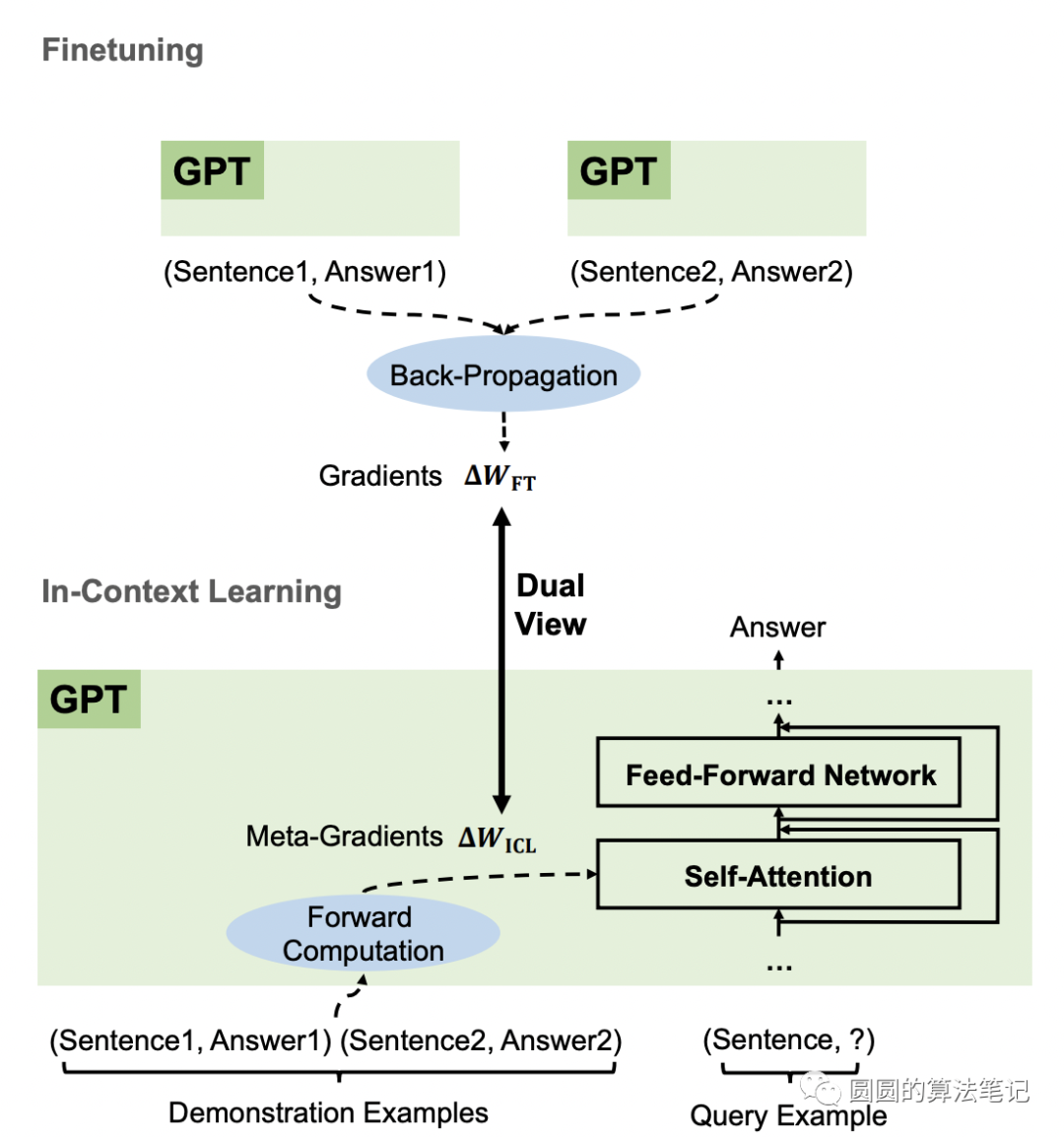
文中的核心点是:Transformer在进行in-context learning的前向传播过程中,等价于进行梯度的反向传播更新参数。在一个简化的线性模型中,反向传播梯度更新的过程可以表述为如下式子:
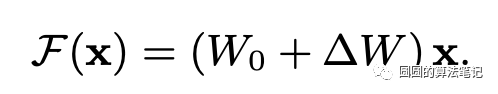
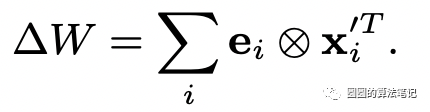
其中e表示梯度,x表示输入表示,二者的外积得到参数的梯度,原来的模型参数加上这个梯度变化,得到以此梯度更新后的新参数。而上述公式可以进一步转换为与attention相关的结构:
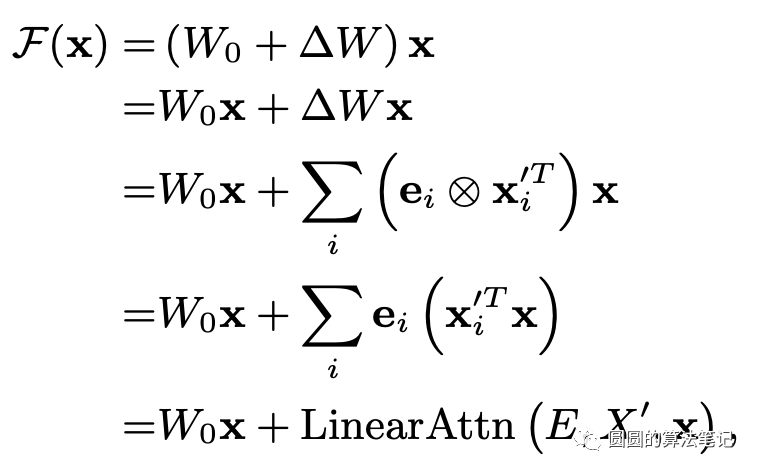
这里面的第二项就是attention结构,query、key、value分别为当前输入、历史输入和回传的梯度。这个转换表明,我们通过这种数据上的attention进行前向传播,可以达到梯度更新后的参数前向传播相类似的预测结果。
3
In-context learning的理解
文中将in-context learning理解为3个步骤。
第一步:一个基于Transformer的预训练语言模型作为一个meta-optimizer;
第二步:这个语言模型根据demonstration在前向传播过程中产生meta-gradient;
第三步:这个meta-gradient通过attention的方式,作用在原来的语言模型上,实现对目标样本的预测。
下面通过公式推导上述过程。在in-context learning,前向传播可以表示成如下形式:
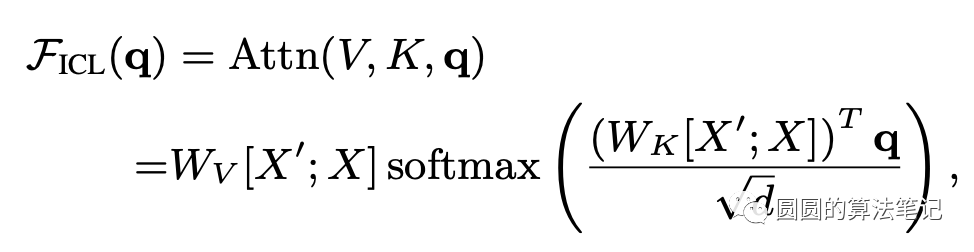
其中X和X'分别代表原始输入样本和demonstration样本。省略softmax等非线性操作,上面的公式可以进一步表述成如下形式:
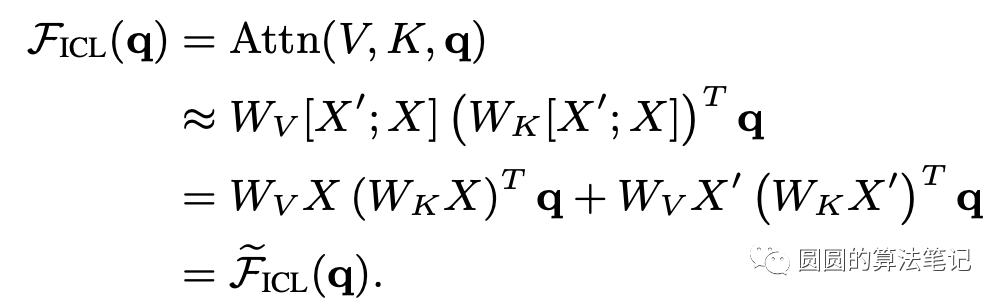
而它又可以进一步转换为梯度更新的形式:
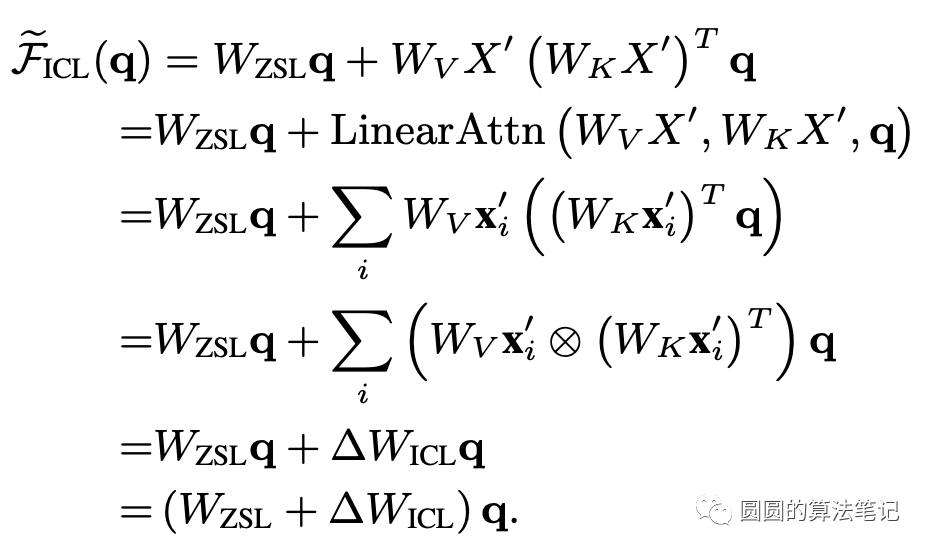
也就是说,in-context learning的前向传播过程,相当于对原来的ZSL参数进行了梯度更新,而这个梯度就来源于demonstration,通过attention的方式将其应用到当前样本的参数更新上,实现类似finetune的预测效果。
4
实验分析
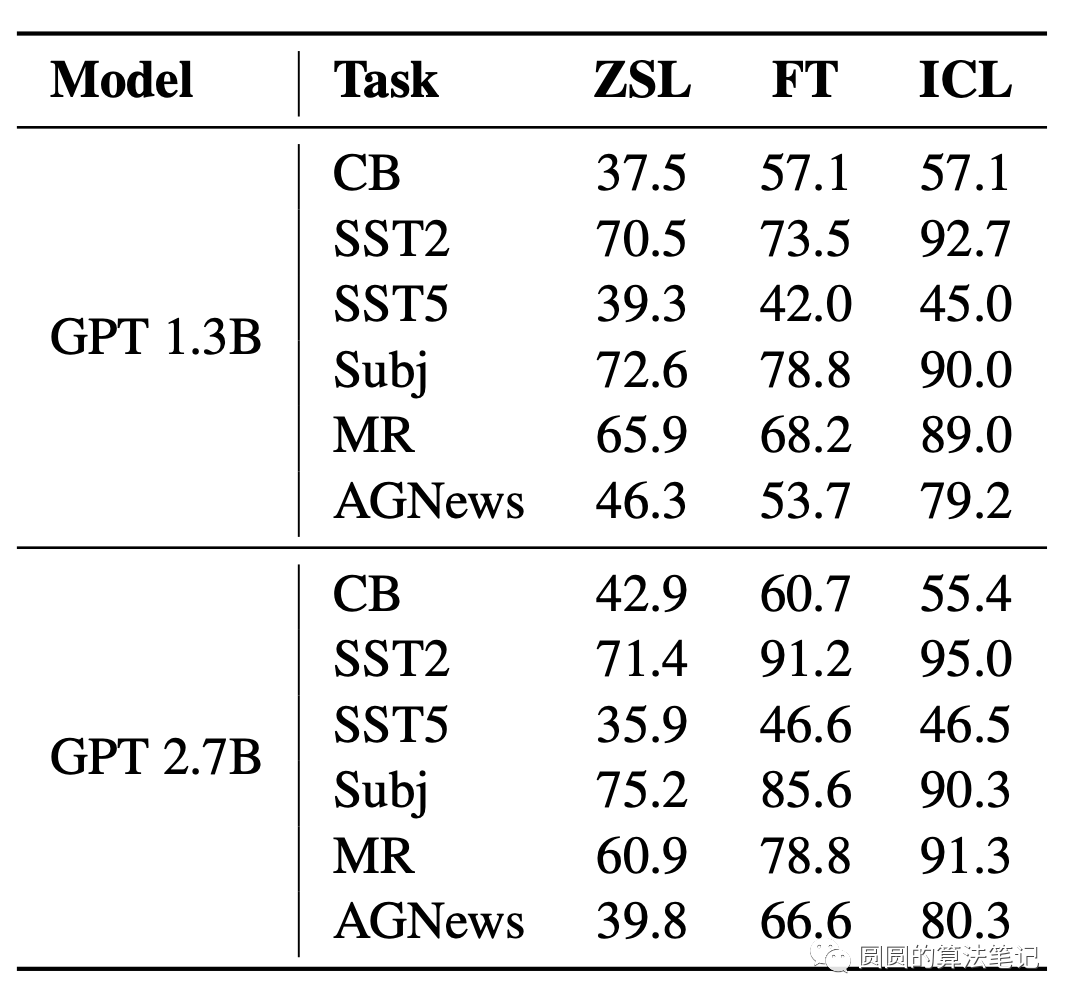
文中对比了在一些任务上,finetune和in-context learning的效果,发现二者在各个任务上的效果是非常相似的,也从实验的角度说明了finetune和in-context learning的相似性。
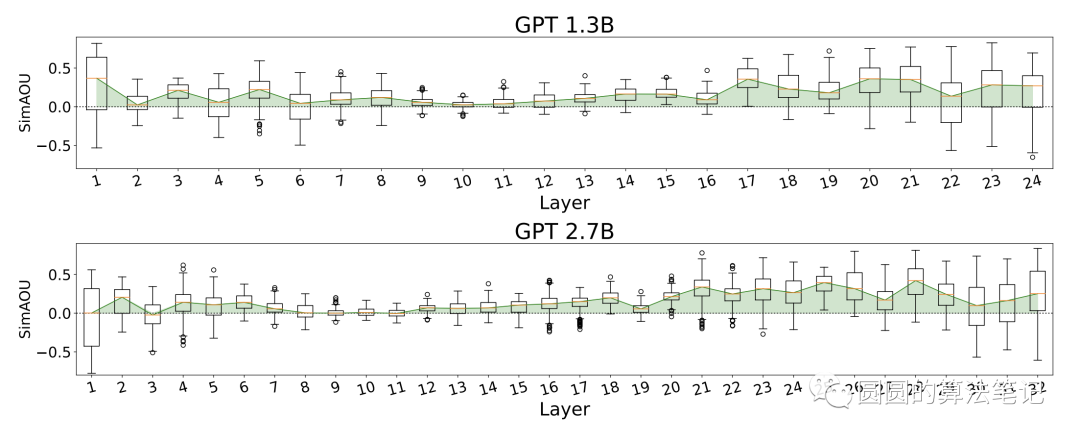
在模型表示层面,文中也对比了in-context learning的attention与finetune的表示结果差异,发现in-context learning和finetune的表示更加相近。这里面SimAOU衡量的是基于in-context learning的attention结果转化到梯度反传的差异,二者差异越小,表明两个方法越接近。
进NLP群—>加入NLP交流群(备注nips/emnlp/nlpcc进入对应投稿群)
加入星球,你将获得:
1. 每日更新3-5篇论文速读
2. 最新入门和进阶学习资料
3. 每日1-3个AI岗位招聘信息
















 1928
1928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









