






深度学习自然语言处理 原创
作者:wkk
考虑到自然语言在许多科学和工程领域表达的数学问题的丰富性,使用大语言模型(LLM)来解决数学问题是一项有趣的研究工作。今天给大家介绍一篇微软研究院联合欧美高校关于如何使用GPT-4解决数学问题的研究论文。
之前的许多工作研究了如何使用LLM解决基本的数学问题,本文探索了使用GPT-4解决更复杂和更具挑战性的数学问题。论文评估了使用GPT-4的各种方法,其中主要贡献是提出了MathChat架构,这是此项工作新提出的会话问题解决框架。通过对MATH数据集中困难的高中竞赛问题进行评估,展现了所提出的对话方法的优势。
下面让我们一起来探究MathChat的模型结构,看看它是如何做到从容应对数学难题的!

论文:An Empirical Study on Challenging Math Problem Solving with GPT-4
地址:https://arxiv.org/abs/2306.01337进NLP群—>加入NLP交流群
1.前言
随着大语言模型的发展,其在跨领域内的各项任务上发挥出了出色的性能。考虑数学在众多科学和工程领域内起到的关键作用,因此探索大语言模型用于解决数学问题是极具研究价值的。对于GPT-4语言模型,鲜有研究探索其解决数学问题的能力。本研究在Bubeck等人的研究基础上调整和评估了几种现有的使用LLMS的方法来适应GPT-4的使用,包括普通提示符和思维程序(POT)提示符。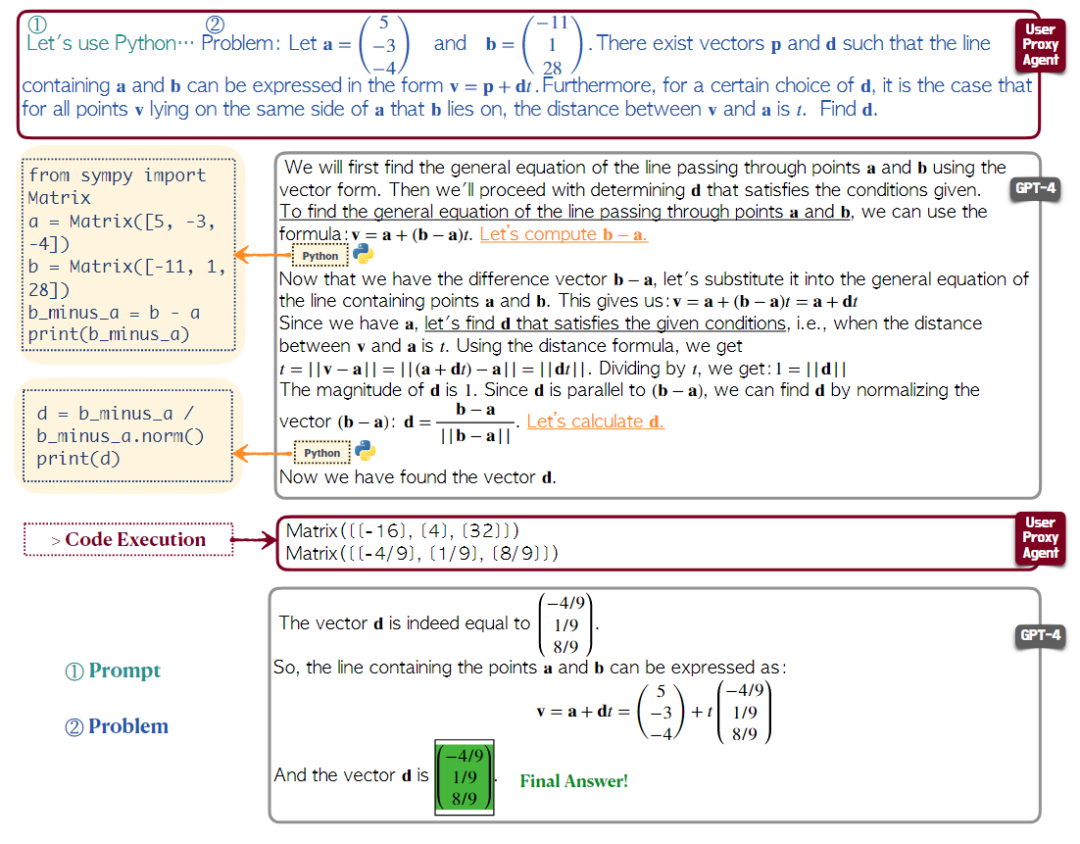 上图是使用MathChat解决数学问题过程的示例。用户通过将数学问题发送到GPT-4来启动对话。从GPT-4的响应中,用户能够提取代码并按顺序执行它们。其记录了之前运行的有效代码,并将与新代码共同执行,以反映模型的逐步推理进度。结果将返回给GPT-4,GPT-4将继续其问题解决过程。在Iddo等人的研究基础上,进一步提出了MathChat,工作流程如下图所示
上图是使用MathChat解决数学问题过程的示例。用户通过将数学问题发送到GPT-4来启动对话。从GPT-4的响应中,用户能够提取代码并按顺序执行它们。其记录了之前运行的有效代码,并将与新代码共同执行,以反映模型的逐步推理进度。结果将返回给GPT-4,GPT-4将继续其问题解决过程。在Iddo等人的研究基础上,进一步提出了MathChat,工作流程如下图所示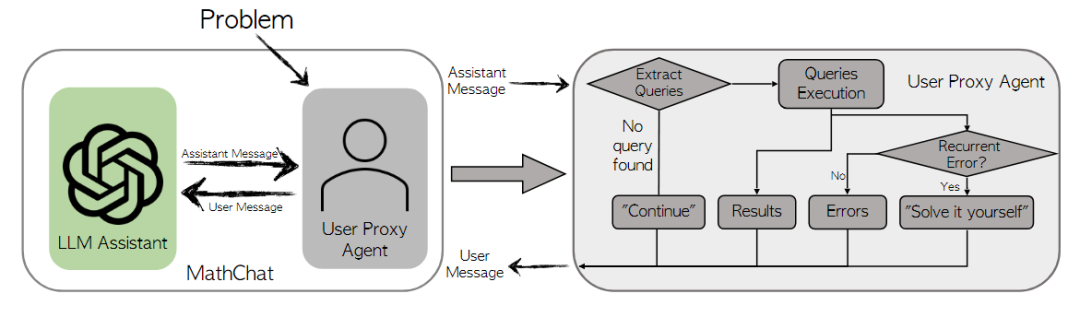 这是一个为基于聊天的LLM量身定制的对话框架,其中数学问题是通过模型和用户之间的模拟对话来解决的,然后对MATH数据集(一个来自各种比赛和教育水平的数学问题的综合集合)进行评估。我们的研究针对该数据集中的5级难度问题,这些问题主要由具有挑战性的高中竞争问题组成。评估表明,MathChat可以将以前的提示方法进一步提高6%,并且可以在一半的类别上达到60%的准确率,同时还展示了具有不同提示和不同工具的MathChat的可扩展性。
这是一个为基于聊天的LLM量身定制的对话框架,其中数学问题是通过模型和用户之间的模拟对话来解决的,然后对MATH数据集(一个来自各种比赛和教育水平的数学问题的综合集合)进行评估。我们的研究针对该数据集中的5级难度问题,这些问题主要由具有挑战性的高中竞争问题组成。评估表明,MathChat可以将以前的提示方法进一步提高6%,并且可以在一半的类别上达到60%的准确率,同时还展示了具有不同提示和不同工具的MathChat的可扩展性。
2.现有的数学问题求解中使用LLM的方法
本节介绍使用现有的LLM各种方法,这些方法可用于解决数学问题。包括专门为数学问题解决而设计的技术,之后总结了一般方法。从我们的调查中,目前只有一种方法是针对具有挑战性的数学问题,而其他大多数方法都是在小学数学上进行评估的。
2.1专门为数学问题解决而设计的技术
尽管有创造性的方法将LLM用于不同的任务,但只有少数方法被提出用于解决数学问题。通过使用LLM将算术计算和其他涉及数学问题解决的基本操作装载到程序中。具体而言,使用Codex通过将CoT提示与代码交错,将数学问题分解为可运行的步骤,从而生成可执行的Python代码来解决数学问题。还使用Codex生成基于代码的问题答案。虽然促使模型解决数学单词问题,有研究探索了程序辅助编码对大学级问题的能力,包括从math数据集中随机抽样的问题。除了使用Python,还提出了一种解决基本算术和逻辑问题的方法,将生成的答案连接回问题,并让模型预测原始条件,以验证该答案的正确性。
2.2一般方法
可用于改进数学求解的一般方法包括(1)chain-of-thought prompting、(2)multi-stage prompting、(3)tool-using和(4)self-consistency。其中,本文回顾了一些最新的研究方法。Timo等人训练一个工具转换器,它可以决定何时发送API调用。Bhargavi使用few-shot提示来交错逐步推理和工具使用。Aman等人的研究首先使用GPT-3.5生成输出,并使用相同的模型给出输出的反馈,然后要求模型根据反馈细化输出。尽管这些通用方法可以应用于解决数学单词问题,但这些方法不是为解决数学问题量身定制的,并且主要在更简单的数学任务上进行评估。
3.MathChat:用于解决数学问题的对话框架
A conversational framework with user proxy agent:MathChat是一个模拟LLM助手和用户之间模拟对话的框架。这里,用户是在与LLM助手的对话中扮演用户角色的代理。在MathChat中,助手和用户共同解决数学问题。初始化提示用于指示LLM助手以某种期望的方式与用户协作解决问题。该框架以这种对话方式设计,以便利用最先进的LLM的聊天优化功能。该框架的另一个明显好处是,它能够进行多回合对话,这在解决需要多步骤推理和工具使用的复杂问题时尤其有用。
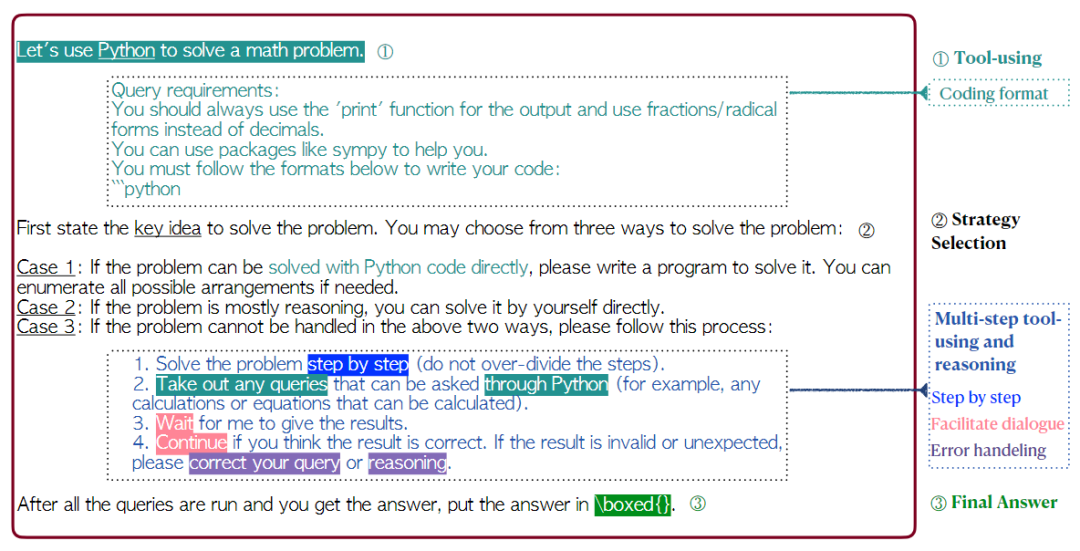
Prompting and tool-using in MathChat:通过适当的修改,可以将现有研究中的有效提示方法(如CoT和工具使用)集成到MathChat框架中。具体来说,对于初始消息中的提示,我们聚合了多种有效的提示技术来指导LLM助手。我们在图4中展示了设计好的提示,它由三个主要组件组成。
1). Tool-using Prompt: 该组件提示LLM使用正确格式的Python编程来解决问题。使用“query reqiurement”小节来指定编码格式,以便用户代理可以解析代码并返回相应的结果。如下图所示:

2). Problem-Solving Strategy Selection Prompt: 该组件指示助手从三种可能的解决问题的策略中进行选择,并在最后一种策略中执行多阶段推理和工具使用。问题解决策略包括以下三种情况,涵盖了现有数学问题解决文献中最有效的策略。
Case1: 编写一个Python程序来直接解决问题。
Case2: 不使用Python直接解决问题。这种策略允许GPT-4运用其固有的推理能力来解决手头的问题。
Case3: 逐步解决问题,并使用Python帮助进行数学运算。如果前两种方法不合适,我们要求模型选择这种方法来解决问题。我们创建了多步骤工具使用提示符的零样本版本,该提示符允许模型在多步骤推理和Python代码之间灵活交错。在这种情况下,要求模型处理程序运行中的错误和意外结果。3). Final Answer Encapsulation Prompt: 提示的此组件指示LLM助手将最终答案包含在'\boxed{}'中,该答案将用作结束对话的指示符。LLM助手和用户代理之间的这种交互将继续进行,直到检测到'\boxed{}'或达到最大轮数对话。如下图所示:
评估
数据集
Dan等人提出的MATH数据集,本文对其中的最高等级难度的数学题目进行评估,其中包括七类问题:Prealgebra, Algebra, Number Theory, Counting and Probability, Geometry, Intermediate Algebra, and Precalculus(前代数、代数、数论、计数和概率、几何、中间代数和前微积分)。在本研究中,删除了对几何问题的评估。
评估方法
以前的大多数工作都使用few-shot examples引出LLM和工具使用的推理,因而模型就会模仿示例来遵循所需要的格式或模式。选择与未回答的问题类似的示例,然后对这些示例进行注释,以涵盖LLM可能遇到的所有情况,多项现有研究揭示了GPT-4遵循指令的显著能力。因此,我们对zero-shot prompt技术感兴趣,该技术可以增强GPT-4的数学求解,而无需任何示例选择和注释。按照这个标准,使用引入的提示符和以下所有few-shot方法评估MathChat框架:Vanilla prompt、Program of Thoughts和Program Synthesis prompt。
vanilla prompt: GPT-4可以在无few-shot的情况下执行CoT推理。为了直接评估GPT-4在解决问题方面的性能,使用了一个默认提示,改编自MATH数据集中的小样本提示:"Solve the problem carefully. Put the final answer in \boxed{ }. {Problem}".
Program of Thoughts: 使用来自Chen等研究人员的zero-shot PoT提示,要求模型编写求解器函数来解决这个问题并直接返回最终答案。
Program Synthesis prompt: 与PoT类似,Program Synthesis(程序合成)提示方法使用提示来要求模型编写程序来解决问题:"Write a program that answers the following question: {Problem}".
评估细节
将GPT-4上的不同方法与OpenAI API的默认配置进行了比较。在MathChat中,仅允许GPT-4和用户之间的最多发送15条消息。如果用户从3次连续执行中检测错误,将明确地要求GPT-4自行解决每个步骤。为了避免用户的极长响应,代理将用户消息中的警告文本替换超过600个标记的任何结果,以要求GPT-4修改先前的代码。我们手动遍历所有方法的答案来计算所有正确答案。对于普通提示、程序合成和MathChat,我们要求GPT-4包含 "\boxed{ }"中的最终答案,因此只会提取框中的答案。对于PoT,我们遵循原始论文将求解器函数的反馈作为最终答案。
实验结果
主要结果
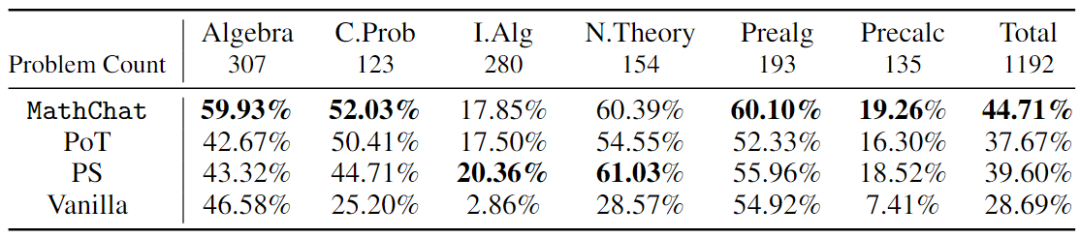
对MATH数据集中的6类的5级问题进行了评估。表1中报告了不同方法在每个类别中的解决问题的准确率。与GPT-4的普通提示相比,使用带有POT或PS的Python将整体准确率提高约10%。在涉及更多数字运算的类别(计数、概率和数论)和更具挑战性的类别(中级代数和预微积分)中发现这种改进。然而,对于代数和预代数,POT和PS几乎没有什么改进,甚至导致精度降低。与POT和PS相比,MathChat可以进一步将总准确率提高6%左右,并且在所有类别上都具有竞争力的性能。值得强调的是,与其他方法相比,MathChat将代数类别的准确率提高了约15%。综合考虑各种方法,中级代数和预微积分的求解准确率只有20%左右。其他类别的问题中,超过一半可以通过MathChat正确解决。
在MathChat上进行附加评估,并提供其他提示
MathChat能够轻松合并不同的提示和工具。本研究通过执行额外的评估来测试使用MathChat的两个替代初始提示,以证明其可扩展性。
(1) 使用Python的简化提示:在这种替代方案中,只保留Python编码格式的"query reqiurments"小节和默认提示中的逐步工具使用。
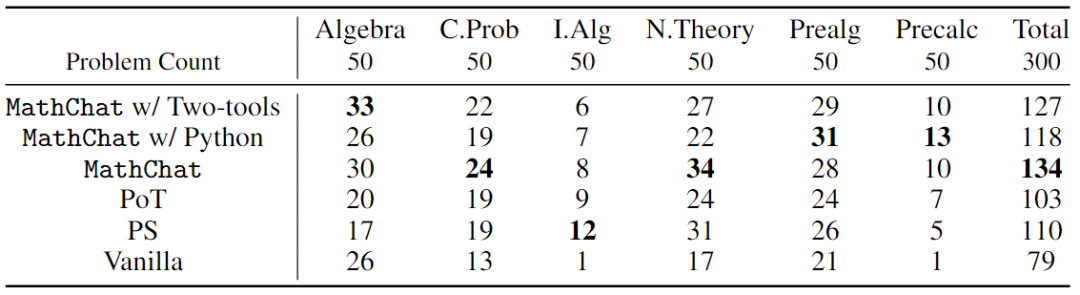
(2) Python和Wolfram Alpha的简化提示:在方案1的基础上,添加了Wolfram Alpha,这是一个计算引擎,作为LLM助手从中选择的附加工具。对六个问题类别中的每一个中随机抽取的50个示例进行评估。还在样本问题中包含了其他方法的结果,在下表中进行比较。MathChat仍然比具有两个新的提示的其他方法表现更好。使用MathChat,允许Python和Wolfram的逐步提示在代数上表现最好,而只有Python的新提示解决了Pre代数和Precalculus中的大多数问题,但在Number Theories上的性能更差。总体而言,带有默认提示的MathChat仍然表现最好。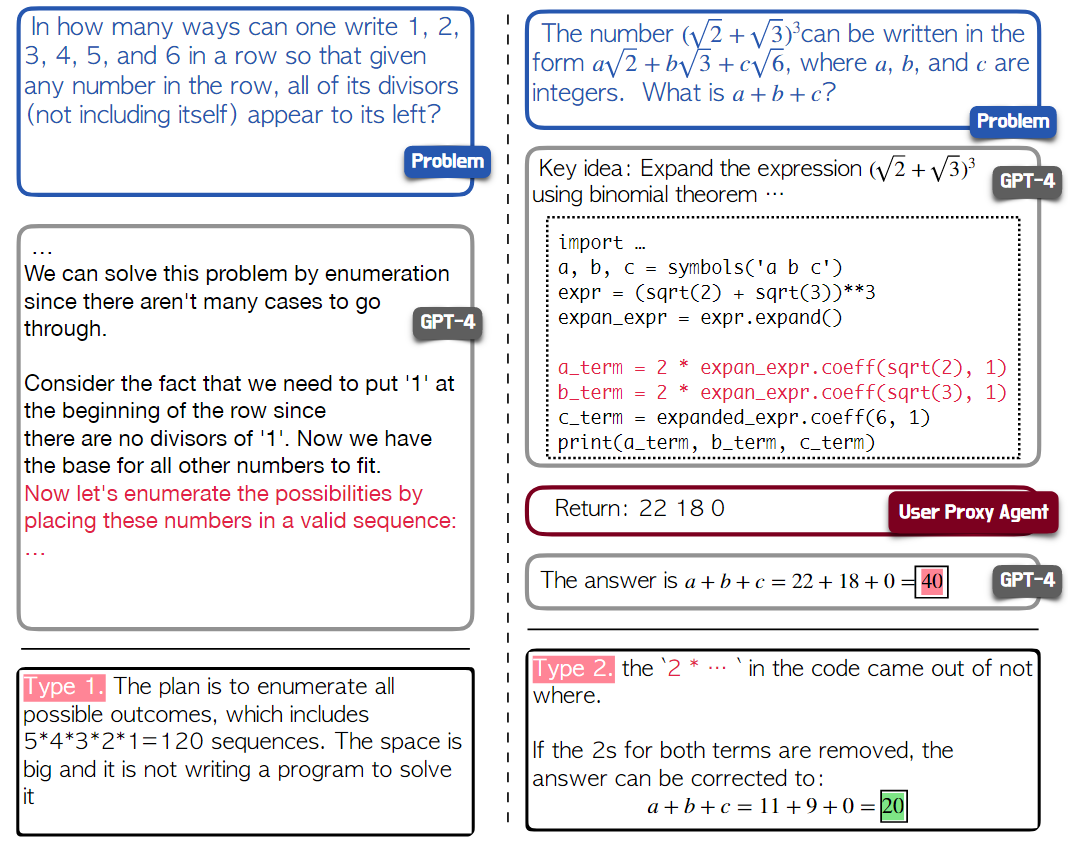
错误分析
原因
通过对错误案例进行总结,主要观察到以下三种失败原因。
(1) 未能设计或选择合适的计划或路径来解决问题
(2) MathChat未能完美地执行设计的计划
(3) 其他技术错误
总结与未来工作
本文对GPT-4在高等数学解题中的不同使用方式进行了评价。介绍了一个基于GPT-4的对话框架MathChat,它允许该模型与代理用户代理交互来解决数学问题。MathChat是为GPT-4等聊天优化模型设计的,它可以扩展,只需很少的工作就可以与不同的提示和不同的工具一起使用。在该框架的基础上,还推导出了一个提示符,该提示符集合了以往在MathChat上使用的提示技术。
对MATH数据集的5级问题的评估表明,MathChat在解决更复杂和更具挑战性的问题方面的有效性。尽管与以前的方法相比有所改进,但结果表明,即使在外部工具的帮助下,复杂的数学问题对于最近的强大LLM仍然具有挑战性。一方面,由于执行错误,GPT-4无法解决相当数量的问题。虽然MathChat试图改进这一点,但可以做进一步的工作来增强这个框架。
Human-in-the-loop扩展。基于GPT-4的MathChat具有很大的潜力,可以被改编成辅助驾驶系统,以帮助人们解决数学问题。MathChat的设计很自然地帮助人们与GPT-4进行交流。使用MathChat中的预设提示,用户可以直接输入问题并获得逐步的响应。此外,可以将MathChat系统设计为在每一步都停止,以允许用户覆盖代理代理的消息。我们设想这个系统可以让用户参与到解决数学问题的过程中,并促进学习。
进NLP群—>加入NLP交流群















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









