






来自:旺知识
应该微调自己的模型还是使用公开大语言服务接口(LLM API)?创建自己的模型可以完全掌控,但需要数据收集、培训和部署方面的专业知识。LLM API更易于使用,但会迫使将数据发送给第三方,并对LLM提供商产生代价高昂的依赖。本博文介绍了如何将LLM的便利性与定制模型的控制和效率相结合的方案。
基于识别新闻中投资者情绪的案例,本文展示了如何使用开源LLM创建合成数据,从而在几个步骤内训练自由的定制模型。本文定制的RoBERTa模型分析大型新闻语料库的成本约为2.7美元,而GPT4为3061美元;二氧化碳排放量约为0.12千克,而GPT4约为735至1100千克;延迟时间为0.13秒,而GPT4往往需要数秒;在识别投资者情绪方面的表现与GPT4相当(准确率均为94%,F1为0.94)。我们在文末提供了可重复使用的代码,可以将其应用于自己的用例。

图源:旺知识
作者:Morit, 张长旺,旺知识,CCF理论计算机科学专业委员会
内容目录
1 - 问题背景:使用案例没有数据
2 - 解决方案:用合成数据教出高效学生
3 - 案例研究:监测金融情绪
3.1 - 提示LLM对数据进行注释
3.2 - 开放源码模式与专有模式的比较
3.3 - 了解并验证(合成)数据
3.4 - 利用AutoTrain调整高效专业模型
3.5 - 不同方法的利弊
4 - 结论
1 - 问题背景:使用案例没有数据
想象一下,老板要求为公司建立一个情感分析系统。您可以找到100,000多个数据集,其中450~个数据集的标题中包含"情感"一词,涵盖Twitter、诗歌或希伯来语中的情感。这很好,但如果你在一家金融机构工作,需要跟踪投资组合中特定品牌的情感,那么这些数据集对你的任务都没有用。公司可以利用机器学习解决的任务数以百万计,但不太可能有人已经收集并发布了有关贵公司试图解决的确切用例的数据。
由于缺乏针对特定任务的数据集和模型,许多人转而使用通用LLM。这些模型规模庞大,通用性强,开箱即能处理大多数任务,准确性令人印象深刻。它们的应用程序接口简单易用,无需微调和部署方面的专业知识。它们的主要缺点是规模和控制:这些模型拥有数千亿或数万亿个参数,效率低下,只能在少数公司控制的计算集群上运行。
2 - 解决方案:用合成数据教出高效学生
2023年,一项发展从根本上改变了机器学习的格局:LLM开始与人类数据注释者平起平坐。现在有大量证据表明,在创建高质量(合成)数据方面,最优秀的LLMs的表现优于人群工作者,并达到了与专家相当的水平(例如Zheng等人,2023年;Gilardi等人,2023年;He等人,2023年)。这一发展的重要性无论如何强调都不为过。创建定制模型的关键瓶颈是招募和协调人类工作者创建定制训练数据所需的资金、时间和专业知识。随着LLM开始达到与人类同等的水平,现在可以通过应用程序接口(API)获得高质量的注释劳动;可重复的注释指令可以作为提示发送;合成数据几乎可以即时返回,计算是唯一的瓶颈。
2024年,这种方法将具有商业可行性,并提升开源技术对大小企业的价值。在2023年的大部分时间里,由于LLM API提供商的限制性商业条款,将LLM用于注释劳动的商业用途受到了阻碍。有了Mistral的Mixtral-8x7B-Instruct-v0.1等模型,LLM注释劳动和合成数据现在可以开放用于商业用途。Mixtral的性能与GPT3.5不相上下,而且由于采用了Apache2.0许可,其合成数据输出可用作商业用途的小型专业模型("学生")的训练数据。本博文将举例说明这将如何显著加快创建您自己的定制模型,同时大幅降低长期推理成本。
3 - 案例研究:监测金融情绪
想象一下,你是一家大型投资公司的开发人员,负责监测经济新闻对投资组合中公司的影响。直到最近,有两个主要选择:
微调自己的模型。这需要编写注释说明、创建注释界面、招募(群众)工作人员、引入质量保证措施以处理低质量数据、在这些数据上微调模型并部署模型。
将数据连同指令一起发送给大语言模型服务接口(LLM API)。可以完全跳过微调和部署,将数据分析过程简化为编写指令(提示),并将其发送给API背后的"LLM注释器"。在这种情况下,LLM API就是最终推理解决方案,可以直接使用LLM的输出结果进行分析。
虽然方案2在推理时成本较高,而且需要将敏感数据发送给第三方,但它比方案1更容易设置,因此被许多开发人员采用。
2024年,合成数据提供了第三种选择:将方案1的成本优势与方案2的易用性结合起来。简单地说,可以使用LLM("老师")为注释一小部分数据样本,然后在这些数据上微调一个更小、更高效的LM("学生")。这种方法只需几个简单的步骤即可实现。
3.1 - 提示LLM对数据进行注释
我们使用financial_phrasebank情感数据集作为运行示例,后续也可以调整代码以适用于任何其他用例。financial_phrasebank任务是一项三类分类任务,由16位专家从投资者的角度将芬兰公司财经新闻中的句子注释为"正面"/"负面"/"中性"(Malo等人,2013年)。例如,数据集中有这样一句话:"2010年最后一个季度,Componenta的净销售额翻了一番,从去年同期的7,600万欧元增至1.31亿欧元",注释者从投资者的角度将这句话归为"正面"。
我们首先要安装一些必需的库。
!pip install datasets # for loading the example dataset
!pip install huggingface_hub # for secure token handling
!pip install requests # for making API requests
!pip install scikit-learn # for evaluation metrics
!pip install pandas # for post-processing some data
!pip install tqdm # for progress bars然后,我们就可以下载带有专家注释的示例数据集。
from datasets import load_dataset
dataset = load_dataset("financial_phrasebank", "sentences_allagree", split='train')
# create a new column with the numeric label verbalised as label_text (e.g. "positive" instead of "0")
label_map = {
i: label_text
for i, label_text in enumerate(dataset.features["label"].names)
}
def add_label_text(example):
example["label_text"] = label_map[example["label"]]
return example
dataset = dataset.map(add_label_text)
print(dataset)
# Dataset({
# features: ['sentence', 'label', 'label_text'],
# num_rows: 2264
#})现在,我们为financial_phrasebank任务编写一个简短的注释指令,并将其格式化为LLM提示。该提示类似于您通常向人群工作者提供的指令。
prompt_financial_sentiment = """\
You are a highly qualified expert trained to annotate machine learning training data.
Your task is to analyze the sentiment in the TEXT below from an investor perspective and label it with only one the three labels:
positive, negative, or neutral.
Base your label decision only on the TEXT and do not speculate e.g. based on prior knowledge about a company.
Do not provide any explanations and only respond with one of the labels as one word: negative, positive, or neutral
Examples:
Text: Operating profit increased, from EUR 7m to 9m compared to the previous reporting period.
Label: positive
Text: The company generated net sales of 11.3 million euro this year.
Label: neutral
Text: Profit before taxes decreased to EUR 14m, compared to EUR 19m in the previous period.
Label: negative
Your TEXT to analyse:
TEXT: {text}
Label: """
在将此提示传递给API之前,我们需要为提示添加一些格式。目前大多数LLM都使用特定的聊天模板进行微调。该模板由特殊标记组成,能让LLM区分用户指令、系统提示和聊天记录中自己的回复。虽然我们在这里没有将模型用作聊天机器人,但省略聊天模板仍会导致性能悄然下降。您可以使用标记器自动添加模型聊天模板的特殊标记(更多信息请点击此处)。在我们的示例中,我们使用的是Mixtral-8x7B-Instruct-v0.1模型。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
chat_financial_sentiment = [{"role": "user", "content": prompt_financial_sentiment}]
prompt_financial_sentiment = tokenizer.apply_chat_template(chat_financial_sentiment, tokenize=False)
# The prompt now includes special tokens: '<s>[INST] You are a highly qualified expert ... [/INST]'现在,格式化的注释指令(提示)可以传递给LLM API。我们使用免费的HuggingFace无服务器推理API。该API非常适合测试流行模型。请注意,如果向免费API发送过多数据,可能会遇到速率限制,因为它是由许多用户共享的。对于较大的工作负载,我们建议创建一个专用推理端点。专用推理端点本质上是您个人的付费API,您可以灵活地打开或关闭它。
我们使用huggingface_hub库登录,以便轻松安全地处理API令牌。或者,你也可以将自己的令牌定义为环境变量。
# you need a huggingface account and create a token here: https://huggingface.co/settings/tokens
# we can then safely call on the token with huggingface_hub.get_token()
import huggingface_hub
huggingface_hub.login()然后,我们定义一个简单的generate_text函数,用于向API发送我们的提示和数据。
import os
import requests
# Choose your LLM annotator
# to find available LLMs see: https://huggingface.co/docs/huggingface_hub/main/en/package_reference/inference_client#huggingface_hub.InferenceClient.list_deployed_models
API_URL = "https://api-inference.huggingface.co/models/mistralai/Mixtral-8x7B-Instruct-v0.1"
# docs on different parameters: https://huggingface.co/docs/api-inference/detailed_parameters#text-generation-task
generation_params = dict(
top_p=0.90,
temperature=0.8,
max_new_tokens=128,
return_full_text=False,
use_cache=False
)
def generate_text(prompt=None, generation_params=None):
payload = {
"inputs": prompt,
"parameters": {**generation_params}
}
response = requests.post(
API_URL,
headers={"Authorization": f"Bearer {huggingface_hub.get_token()}"},
json=payload
)
return response.json()[0]["generated_text"]由于LLM可能不会总是以完全相同的统一格式返回标签,因此我们还定义了一个简短的clean_output函数,用于将LLM输出的字符串映射为我们的三种可能标签。
labels = ["positive", "negative", "neutral"]
def clean_output(string, random_choice=True):
for category in labels:
if category.lower() in string.lower():
return category
# if the output string cannot be mapped to one of the categories, we either return "FAIL" or choose a random label
if random_choice:
return random.choice(labels)
else:
return "FAIL"现在我们可以将文本发送到LLM进行注释。下面的代码会将每个文本发送到LLM API,并将文本输出映射到我们的三个干净类别。注意:迭代每个文本并将它们分别发送到API在实践中效率很低。API可以同时处理多个文本,通过异步向API批量发送文本,可以大大加快API调用的速度。
output_simple = []
for text in dataset["sentence"]:
# add text into the prompt template
prompt_formatted = prompt_financial_sentiment.format(text=text)
# send text to API
output = generate_text(
prompt=prompt_formatted, generation_params=generation_params
)
# clean output
output_cl = clean_output(output, random_choice=True)
output_simple.append(output_cl)根据输出结果,我们现在可以计算指标,看看模型在没有经过训练的情况下完成任务的准确度。
from sklearn.metrics import classification_report
def compute_metrics(label_experts, label_pred):
# classification report gives us both aggregate and per-class metrics
metrics_report = classification_report(
label_experts, label_pred, digits=2, output_dict=True, zero_division='warn'
)
return metrics_report
label_experts = dataset["label_text"]
label_pred = output_simple
metrics = compute_metrics(label_experts, label_pred)根据简单的提示,LLM对91.6%的文本进行了正确分类(准确率为0.916,F1宏为0.916)。考虑到LLM并不是为完成这项特定任务而训练的,这个结果已经相当不错了。
我们可以通过使用两种简单的提示技术来进一步改进这一点:思维链(CoT)和自我一致性(SC)。CoT要求模型先推理出正确的标签,然后再做出贴标决定,而不是立即决定正确的标签。SC是指多次向同一个LLM发送带有相同文本的相同提示。如果LLM回答了两次"正向"和一次"中性",我们就会选择多数("正向")作为正确标签。以下是我们更新后的CoT和SC提示:
prompt_financial_sentiment_cot = """\
You are a highly qualified expert trained to annotate machine learning training data.
Your task is to briefly analyze the sentiment in the TEXT below from an investor perspective and then label it with only one the three labels:
positive, negative, neutral.
Base your label decision only on the TEXT and do not speculate e.g. based on prior knowledge about a company.
You first reason step by step about the correct label and then return your label.
You ALWAYS respond only in the following JSON format: {{"reason": "...", "label": "..."}}
You only respond with one single JSON response.
Examples:
Text: Operating profit increased, from EUR 7m to 9m compared to the previous reporting period.
JSON response: {{"reason": "An increase in operating profit is positive for investors", "label": "positive"}}
Text: The company generated net sales of 11.3 million euro this year.
JSON response: {{"reason": "The text only mentions financials without indication if they are better or worse than before", "label": "neutral"}}
Text: Profit before taxes decreased to EUR 14m, compared to EUR 19m in the previous period.
JSON response: {{"reason": "A decrease in profit is negative for investors", "label": "negative"}}
Your TEXT to analyse:
TEXT: {text}
JSON response: """
# we apply the chat template like above
chat_financial_sentiment_cot = [{"role": "user", "content": prompt_financial_sentiment_cot}]
prompt_financial_sentiment_cot = tokenizer.apply_chat_template(chat_financial_sentiment_cot, tokenize=False)
# The prompt now includes special tokens: '<s>[INST] You are a highly qualified expert ... [/INST]'这是一个JSON提示,我们要求LLM返回一个结构化的JSON字符串,其中"原因"是一个键,"标签"是另一个键。JSON的主要优点是我们可以将其解析为Python字典,然后提取"标签"。如果我们想了解LLM选择此标签的原因,还可以提取"原因"。
process_output_cot函数会解析LLM返回的JSON字符串,如果LLM不返回有效的JSON,它就会尝试用上面定义的clean_output函数中的简单字符串匹配来识别标签。
import ast
def process_output_cot(output):
try:
output_dic = ast.literal_eval(output)
return output_dic
except Exception as e:
# if json/dict parse fails, do simple search for occurance of first label term
print(f"Parsing failed for output: {output}, Error: {e}")
output_cl = clean_output(output, random_choice=False)
output_dic = {"reason": "FAIL", "label": output_cl}
return output_dic现在,我们可以用新的提示重复使用上面的generate_text函数,用process_output_cot处理JSONChain-of-Thought输出,并多次发送每个提示以实现自一致性。
self_consistency_iterations = 3
output_cot_multiple = []
for _ in range(self_consistency_iterations):
output_lst_step = []
for text in tqdm(dataset["sentence"]):
prompt_formatted = prompt_financial_sentiment_cot.format(text=text)
output = generate_text(
prompt=prompt_formatted, generation_params=generation_params
)
output_dic = process_output_cot(output)
output_lst_step.append(output_dic["label"])
output_cot_multiple.append(output_lst_step)对于每篇文本,我们的LLM注释器现在都会尝试三次,用三种不同的推理路径来识别正确的标签。下面的代码将从三种路径中选择多数标签。
import pandas as pd
from collections import Counter
def find_majority(row):
# Count occurrences
count = Counter(row)
# Find majority
majority = count.most_common(1)[0]
# Check if it's a real majority or if all labels are equally frequent
if majority[1] > 1:
return majority[0]
else: # in case all labels appear with equal frequency
return random.choice(labels)
df_output = pd.DataFrame(data=output_cot_multiple).T
df_output['label_pred_cot_multiple'] = df_output.apply(find_majority, axis=1)现在,我们可以再次将改进后的LLM标签与专家标签进行比较,并计算指标。
import pandas as pd
from collections import Counter
def find_majority(row):
# Count occurrences
count = Counter(row)
# Find majority
majority = count.most_common(1)[0]
# Check if it's a real majority or if all labels are equally frequent
if majority[1] > 1:
return majority[0]
else: # in case all labels appear with equal frequency
return random.choice(labels)
df_output = pd.DataFrame(data=output_cot_multiple).T
df_output['label_pred_cot_multiple'] = df_output.apply(find_majority, axis=1)CoT和SC将性能提高到94.0%的准确率和0.94的F1。我们通过给予模型思考标签决策的时间和多次尝试来提高性能。请注意,CoT和SC需要额外的计算成本。我们实质上是在用计算购买标注的准确性。
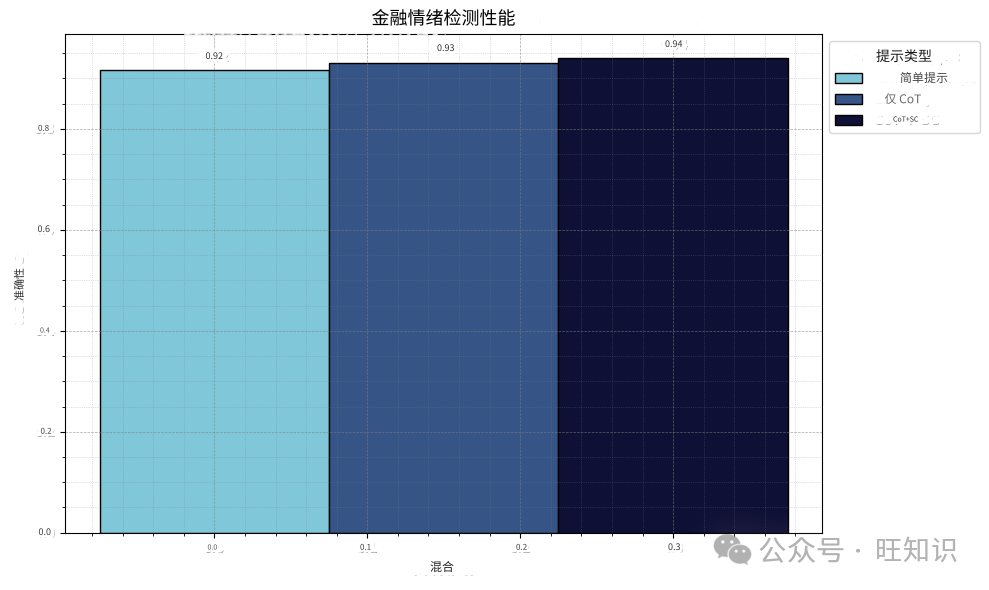
通过这些简单的LLMAPI调用,我们创建了一个合成训练数据集。我们通过让LLM尝试三种不同的推理路径来对每个文本进行标注,然后再做出标注决定。结果,我们得到了与人类专家高度一致的标签和高质量的数据集,我们可以利用这些数据集来训练一个更高效、更专业的模型。
df_train = pd.DataFrame({
"text": dataset["sentence"],
"labels": df_output['label_pred_cot_multiple']
})
df_train.to_csv("df_train.csv")请注意,在本博文的完整重现脚本中,我们还纯粹根据专家注释创建了一个测试分割,以评估所有模型的质量。所有指标始终都是基于这个人类专家测试分割。
3.2 - 开放源码模式与专有模式的比较
使用开源Mixtral模型创建的这些数据的主要优势在于,这些数据可完全用于商业用途,没有法律上的不确定性。例如,使用OpenAI API创建的数据必须遵守OpenAI商业条款,该条款明确禁止将模型输出用于训练与其产品和服务竞争的模型。这些条款的法律价值和含义尚不明确,但它们为商业使用根据来自OpenAI模型的合成数据训练的模型带来了法律上的不确定性。在合成数据上训练的任何较小的高效模型都可被视为竞争模型,因为它减少了对API服务的依赖。
Mistral的开源Mixtral-8x7B-Instruct-v0.1与OpenAI的GPT3.5和GPT4相比,合成数据的质量如何?我们使用gpt-3.5-turbo-0613和gpt-4-0125-preview运行了与上述相同的管道和提示,并在下表中报告了结果。我们发现,在这项任务中,Mixtral的表现优于GPT3.5,与GPT4相当,具体取决于提示类型。。
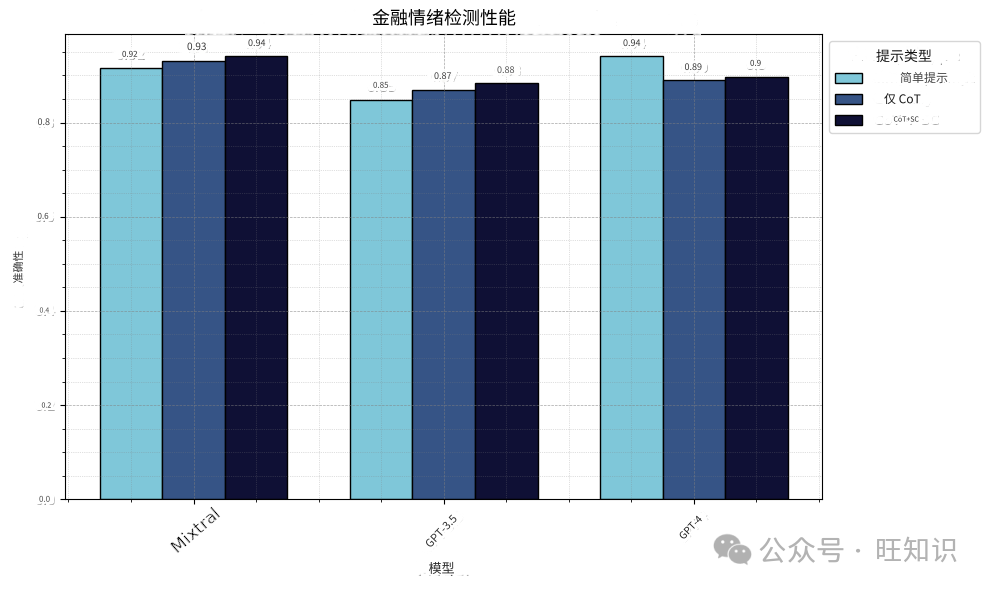
请注意,这并不意味着Mixtral总比GPT3.5好,与GPT4不相上下。GPT4在几个基准测试中表现更好。主要信息是开源模型现在可以创建高质量的合成数据。
3.3 - 了解并验证(合成)数据
所有这些在实践中意味着什么?到目前为止,结果只是一些黑盒子LLM标注的数据。我们也只能计算指标,因为我们有来自示例数据集的专家注释参考数据。如果我们在真实世界中没有专家注释,我们怎么能相信LLM的注释呢?
实际上,无论您使用哪种注释器(人工注释器或LLM),您都只能相信自己验证过的数据。指令/提示总是包含一定程度的模糊性。即使是完全智能的注释者也可能犯错,在面对往往模棱两可的真实世界数据时,必须做出不明确的决定。
幸运的是,在过去几年中,通过开源工具,数据验证变得更加容易:Argilla提供了一个用于验证和清理非结构化LLM输出的免费接口;LabelStudio使您能够以多种方式注释数据;CleanLab提供了一个用于注释和自动清理结构化数据的接口;对于快速和简单的验证,只在一个简单的Excel文件中注释也是可以的。
有必要花一些时间对文本进行注释,以了解数据及其模糊性。您很快就会发现模型犯了一些错误,但也会有一些例子不清楚正确的标签,还有一些文本您更同意LLM的决定,而不是创建数据集的专家。这些错误和模糊之处是创建数据集的正常现象。事实上,现实世界中只有极少数任务的人类专家基准线是100%一致的。这是一个古老的观点,最近被机器学习文献"重新发现",即人类数据是一个错误的黄金标准(Krippendorf,2004年;Hosking等,2024年)。
在注释界面上用了不到一个小时,我们就对数据有了更好的理解,并纠正了一些错误。不过,为了重现性和展示纯合成数据的质量,我们在下一步中继续使用未经清理的LLM注释。
3.4 - 利用AutoTrain调整高效专业模型
到目前为止,这是一个标准的工作流程,即通过应用程序接口提示LLM并验证输出结果。现在要做的是大幅节省资源的额外步骤:我们在LLM的合成数据上微调一个更小、更高效、更专业的LM。这个过程也被称为"提炼",即用较大模型("教师")的输出来训练较小的模型("学生")。虽然这听起来很花哨,但本质上只是意味着我们从数据集中获取原始文本,并将LLM的预测结果作为我们的标签进行微调。如果你以前训练过分类器,就会知道使用transformers、sklearn或其他库训练分类器只需要这两列。
我们使用HuggingFaceAutoTrain解决方案使这一过程变得更加简单。AutoTrain是一个无代码界面,您可以上传带有标签数据的.csv文件,然后该服务会自动为您微调模型。这样,您就不需要编码或深入的微调专业知识来训练自己的模型了。
在HuggingFace网站上,我们首先点击顶部的"空间",然后点击"创建新空间"。然后,我们选择"Docker">"AutoTrain",并选择一个小型A10G GPU,其费用为每小时1.05美元。然后,AutoTrain的空间将初始化。然后,我们可以通过界面上传合成训练数据和专家测试数据,并调整不同的字段,如下图所示。一切填写完毕后,我们就可以点击"开始训练",然后就可以在Space的日志中查看训练过程了。在1811个数据点上训练一个基于RoBERTa的小型模型(参数约为0.13B)非常快,不会超过几分钟。训练完成后,模型会自动上传到您的高频配置文件中。训练完成后,Space就会停止,整个过程最多需要15分钟,花费不到1美元。
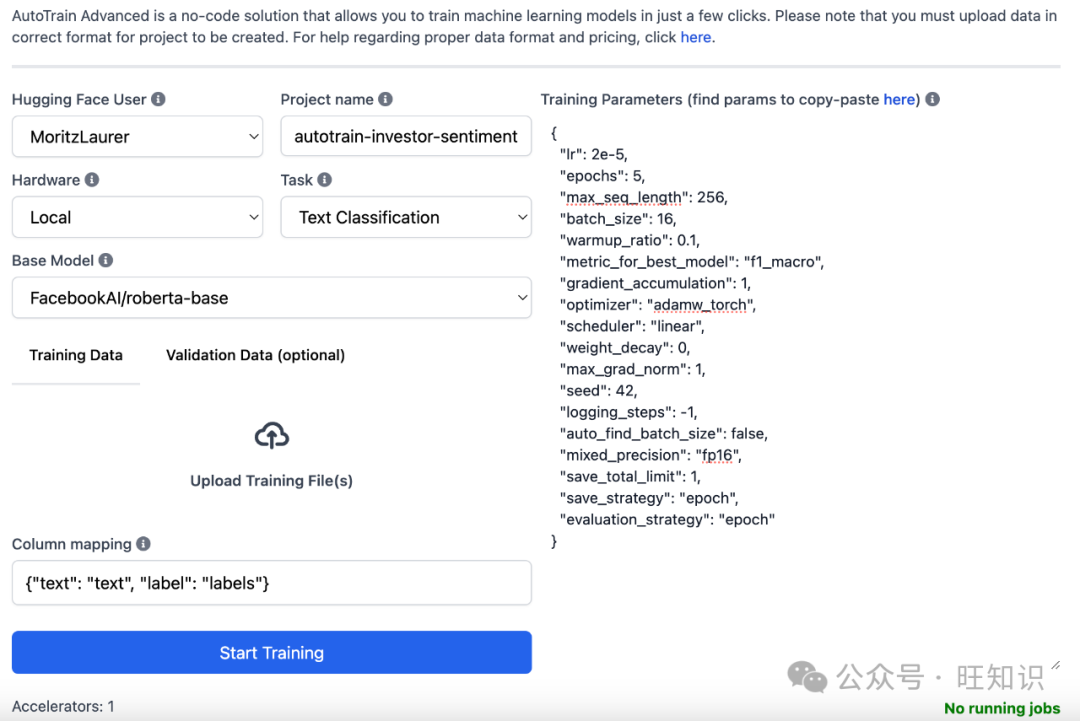
如果您愿意,也可以完全在本地硬件上使用AutoTrain。当然,高级用户也可以编写自己的训练脚本,但使用这些默认超参数,AutoTrain的结果应该足以满足许多分类任务的需要。
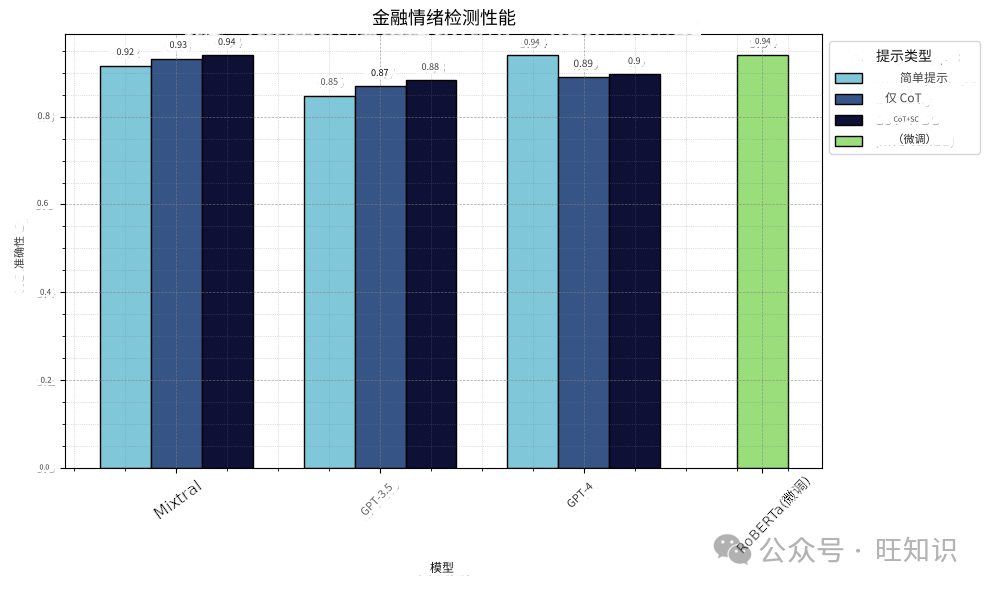
与规模更大的LLM相比,我们微调后的~0.13B参数RoBERTa基础模型表现如何?下面的柱状图显示,在1811个文本上经过微调的自定义模型达到了94%的准确率--与其老师Mixtral和GPT4的准确率相同!一个小模型永远无法与一个大得多的LLM相媲美,但在一些高质量数据上对其进行微调后,它就能在其擅长的任务上达到相同的性能水平。
3.5 - 不同方法的利弊
我们一开始讨论的三种方法:(1)手动创建自己的数据和模型;(2)仅使用LLM API;或(3)使用LLM API为专门模型创建合成数据,这三种方法的总体利弊是什么?下表显示了不同因素之间的权衡,我们将根据下面的示例数据集讨论不同的指标。
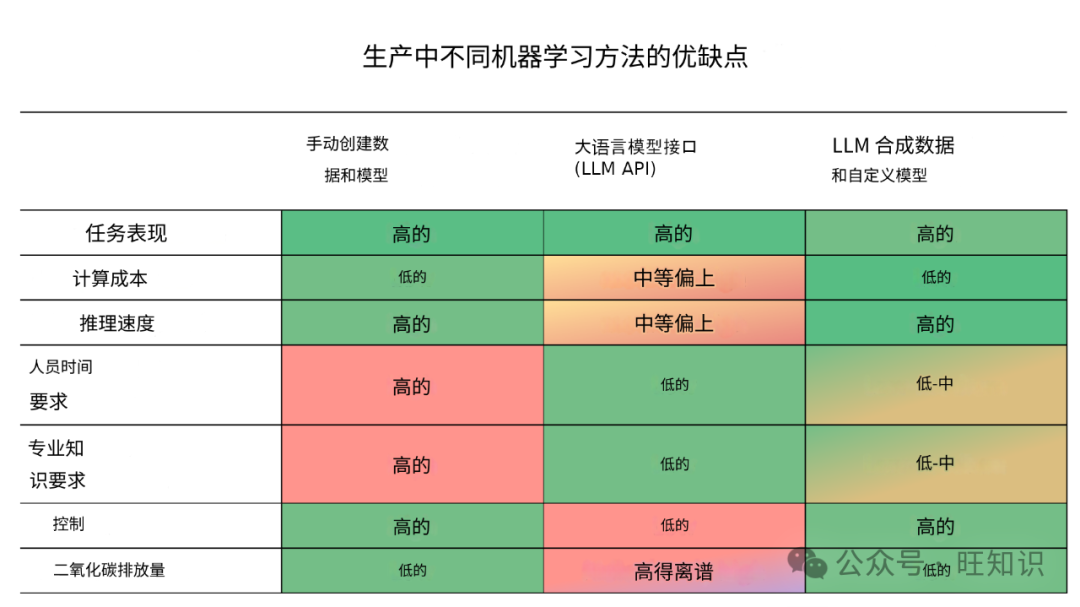
我们先来看看任务性能,专业化模型的性能与更大型的LLM不相上下。微调模型只能完成我们训练它完成的一项特定任务,但它能很好地完成这项特定任务。要创建更多的训练数据,使模型适应新领域或更复杂的任务,是一件轻而易举的事。有了来自LLM的合成数据,因缺乏专业数据而导致的性能低下问题就不复存在了。
第二,计算成本和推理速度。在实践中,主要的计算成本是推理,即在训练完成后运行模型。假设在您的生产使用案例中,您需要在给定时间内处理100万个句子。我们经过微调的RoBERTa-base模型可在配备16GB RAM的小型T4 GPU上高效运行,推理端点的成本为每小时0.6美元。它的延迟为0.13秒,在批量大小=8的情况下,吞吐量为每秒61句。因此,处理100万个句子的总成本为2.7美元。
使用GPT模型,我们可以通过计算词块来计算推理成本。处理100万个句子中的标记,GPT3.5的成本约为153美元,GPT4的成本约为3061美元。这些模型的延迟和吞吐量计算起来更为复杂,因为它们会根据当前服务器负载的不同而全天变化。不过,任何使用GPT4的用户都知道,延迟通常可达数秒,而且速率有限。请注意,对于任何LLM(API),包括开源LLM,速度都是一个问题。许多生成式LLM都过于庞大,速度根本无法保证。
训练计算成本往往不太重要,因为LLM通常无需微调即可直接使用,而且较小模型的微调成本也相对较低(微调RoBERTa-base的成本不到1美元)。只有在极少数情况下,才需要投资从头开始预训练模型。当对较大的生成式LLM进行微调,使其专门用于特定的生成任务时,训练成本就会变得很高。
第三,所需的时间和专业知识投资。这是LLM API的主要优势。向应用程序接口发送指令要比手动收集数据、微调自定义模型并进行部署容易得多。这正是使用LLMAPI创建合成数据的重要性所在。创建良好的训练数据变得更加容易。微调和部署可由AutoTrain和专用推理端点等服务处理。
第四,控制能力,这是LLM API的主要缺点。从设计上讲,LLM API使你依赖于LLM API提供商。你需要将敏感数据发送到别人的服务器上,而且无法控制系统的可靠性和速度。培训自己的模型可以让您选择部署的方式和地点。
最后是环境影响。由于缺乏有关模型架构和硬件基础设施的信息,要估算GPT4等封闭模型的能耗和二氧化碳排放量非常困难。我们能找到的最佳(但非常粗略的)估计是,每次GPT4查询的能耗约为0.0017至0.0026千瓦时。这样,分析100万个句子大约需要1700到2600千瓦时。根据环保署的二氧化碳当量计算器,这相当于0.735-1.1公吨二氧化碳,或一辆普通汽车行驶1885-2883英里。请注意,实际的二氧化碳排放量会因LLM特定计算区域的能源组合不同而有很大差异。有了我们的自定义模型,这一估算就容易多了。使用自定义模型分析100万个句子,在T4GPU上大约需要4.52小时,而在美国东弗吉尼亚州的AWS服务器上,大约需要0.12千克二氧化碳(参见MLCO2Impact计算器)。运行像GPT4这样拥有(据称)8x220B参数的通用LLM,与拥有~0.13B参数的专用模型相比,效率低得令人发指。
4 - 结论
我们展示了使用LLM创建合成数据来训练更小、更高效模型的巨大优势。虽然这个例子只涉及投资者情绪分类,但同样的管道也可应用于许多其他任务,从其他分类任务(如客户意图检测或有害内容检测),到标记分类(如命名实体识别或PII检测),或生成任务(如摘要或问题解答)。
2024年,企业创建自己的高效模型、控制自己的数据和基础设施、减少二氧化碳排放、节省计算成本和时间,而不必在准确性上打折扣,将变得前所未有的简单。
现在就亲自试试吧!您可以在这篇博文中找到所有数字的完整重现代码,还可以在重现库中找到更高效的异步函数,以及API调用的批处理。
参考资料:
生成数据代码:https://github.com/MoritzLaurer/synthetic-data-blog/tree/main
MoritzLaurer,Synthetic data: save money, time and carbon with open source
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









