







深度学习自然语言处理 分享
导读
当前,大型语言模型 (Large Language Model, LLM) 大多强调以自然语言 (Natural Language, NL)为媒介进行交互、推理以及反馈修正。然而,LLM对符号语言的处理能力如何?如何增强LLM的符号交互能力? Symbol-LLM这项目工作给出了答案,并开源了涵盖超20种符号类型的训练数据集,以及统一符号的开源基座大模型 (7B/13B)
论文:https://arxiv.org/abs/2311.09278
背景
在LLM时代,大量的工作都在关注如何进一步增强以自然语言为中心(NL-centric)的语言模型能力,例如Chain-of-Thought, ReACT等。然而,世界知识并不是只由自然语言所定义、塑造。与之相对应的符号语言(Symbolic Language)的作用和价值往往会被忽视。
实际上,符号语言有两大方面的作用和意义:
(1)表达更加丰富的符号化知识(如化学分子式、形式化逻辑规则等)
(2)控制Agents、调用外部工具(如机器人控制语言、工具调用API等)
基于此,该工作考虑到自然语言与符号语言之间的平衡,发布了首个统一符号的开源基座大模型Symbol-LLM。
方法
由于LLM的预训练语料的绝大部分是由自然语言构成的,LLM天然地缺乏符号知识的基础(Symbolic Foundation)。最直接的方法是通过finetune的手段,为LLM注入符号知识。先前的一些工作主要关注于对具体的某一种符号类型(如First-order Logic,SQL等)进行优化。然而,它们忽视了(1)多种符号之间的内生联系;(2)符号语言与自然语言能力的平衡。
基于这些观察,Symbol-LLM首先收集并提出了首个覆盖20种符号类型的Symbolic Collection,用作Instruction tuning。其次,Symbol-LLM提出了两阶段的SFT(Supervised Fine-Tuning)框架,在注入符号知识的同时,保证符号语言与自然语言之间的能力平衡。
符号数据收集(Symbolic Collection)
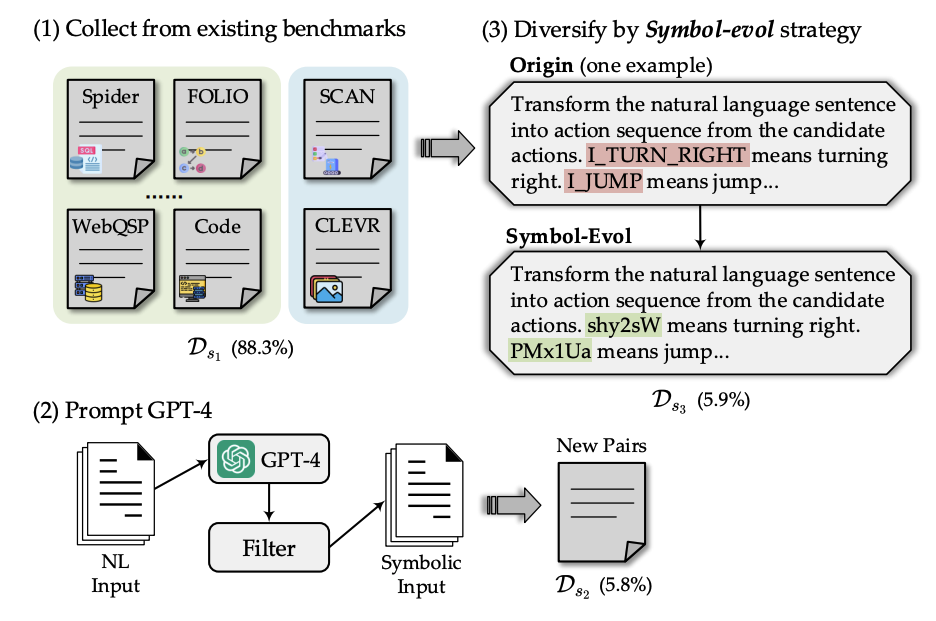
符号数据主要有三个来源,总共超过88万条指令数据对,包含了34个Text-to-Symbol的任务场景:
(88.30%): 从现有的符号生成数据集中收集训练样本。这样能在一定程度上保证符号语言的高覆盖度以及数据质量。
(5.80%): 通过蒸馏GPT-4生成新的Text-to-Symbol样本对。尽管已经囊括了相当一部分符号生成指令数据,但是依然无法覆盖到一些重要的场景,例如利用Python求解数学推理问题。
(5.90%): 提出Symbol-Evol策略提升样本多样性。上面两个collection囊括的都是标准的符号形式。为了防止LLM完全拟合这些符号形式,提出了Symbol-Evol策略,生成大量随机化的符号定义。
两阶段微调框架
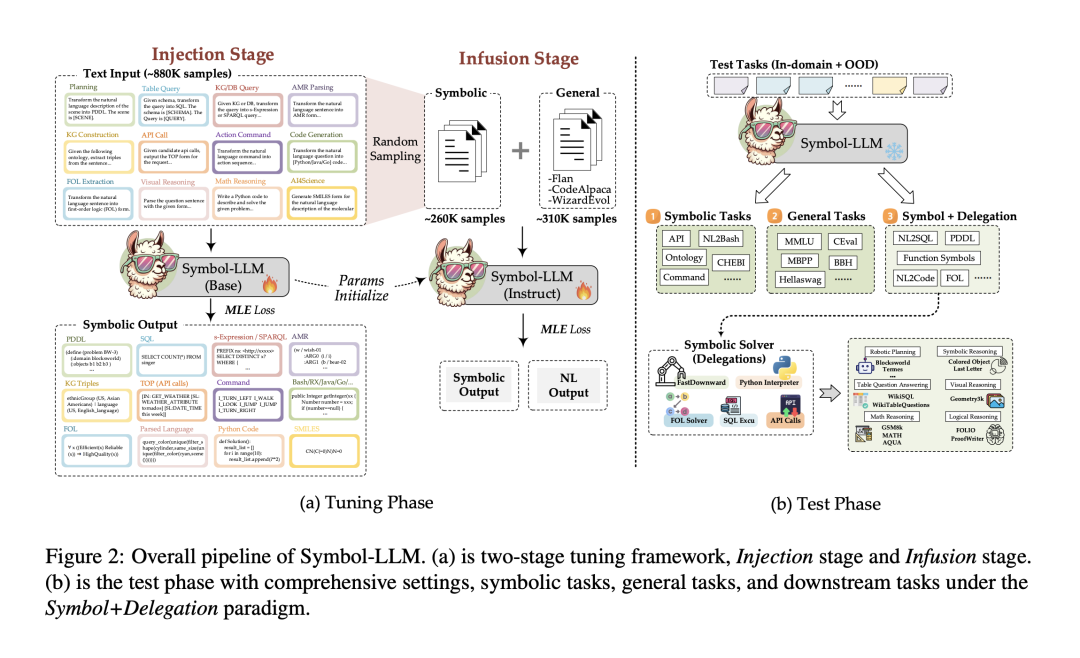
训练分为Injection和Infusion两个阶段。
Injection Stage:完全关注于符号知识的注入,利用Symbolic Collection作为指令数据集,训练模型的Text-to-Symbol能力,得到Symbol-LLM-Base模型。
Infusion Stage:该阶段关注LLM符号语言能力与自然语言能力之间的平衡。利用混合的符号数据与通用自然语言数据,以SFT的方式训练Symbol-LLM-Base模型,得到Symbol-LLM-Instruct模型。
Symbol-LLM的训练是基于LLaMA-2-Chat的全量微调,包含7B和13B两个版本。
实验
该文章的另一亮点在于极为丰富、扎实的实验。Symbol-LLM总共评测了三大实验设定:(1)Symbolic Tasks,测试模型的符号生成基础性能;(2) General Tasks,验证模型在通用自然语言任务上的能力;(3)Symbol+Delegation Tasks,测试模型调用外部Solver,完成更实际任务的能力。以下选取部分实验进行讨论:
Symbolic Tasks
Symbol-LLM在34个in-domain的符号生成任务上进行了实验测试。同时,也对一些OOD的场景进行了验证。
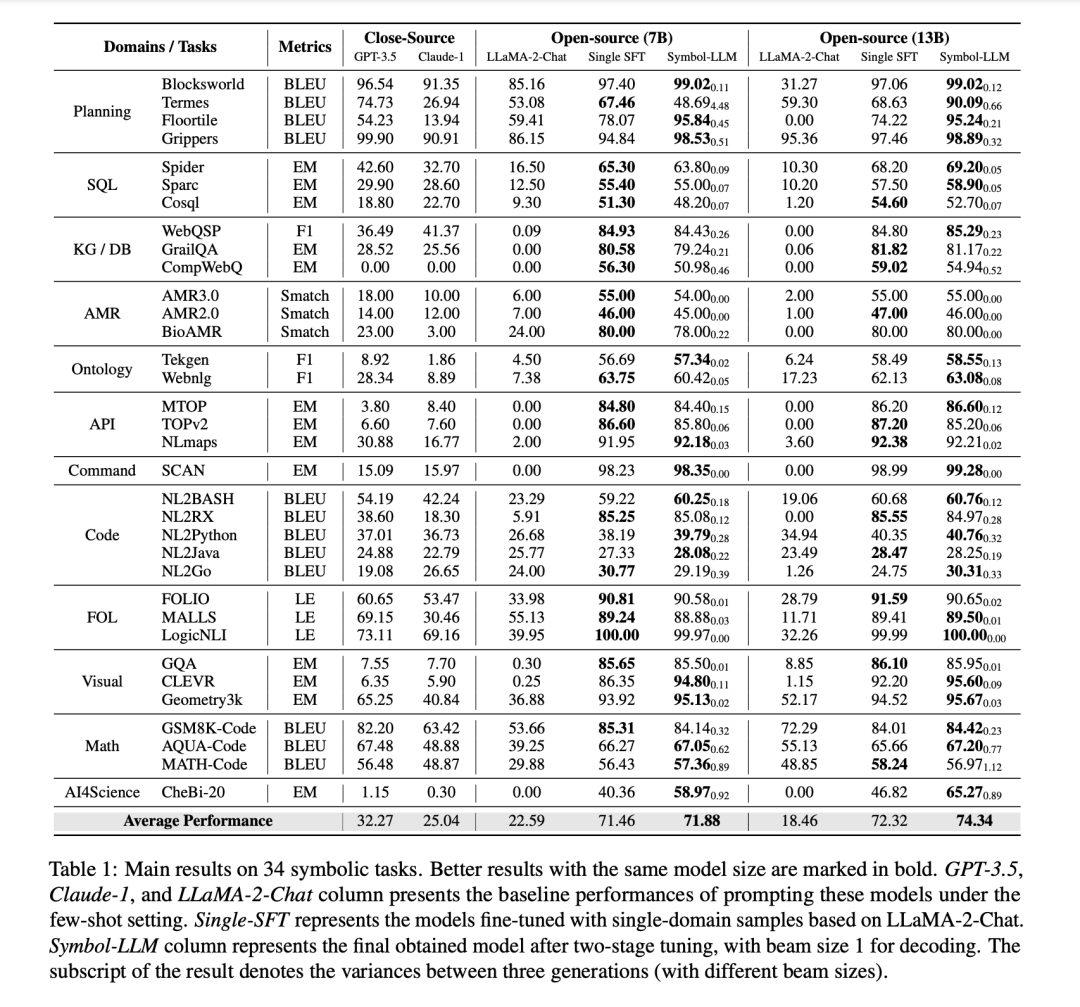
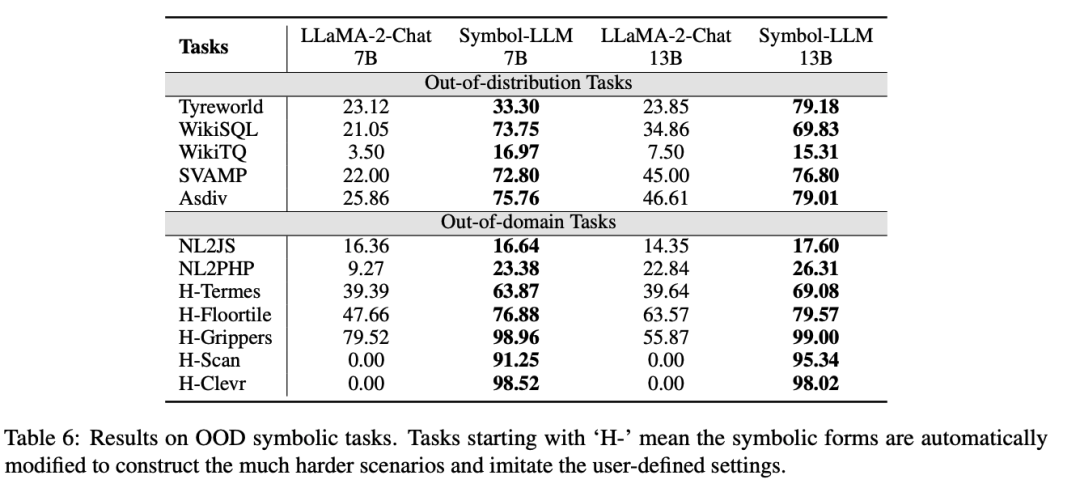
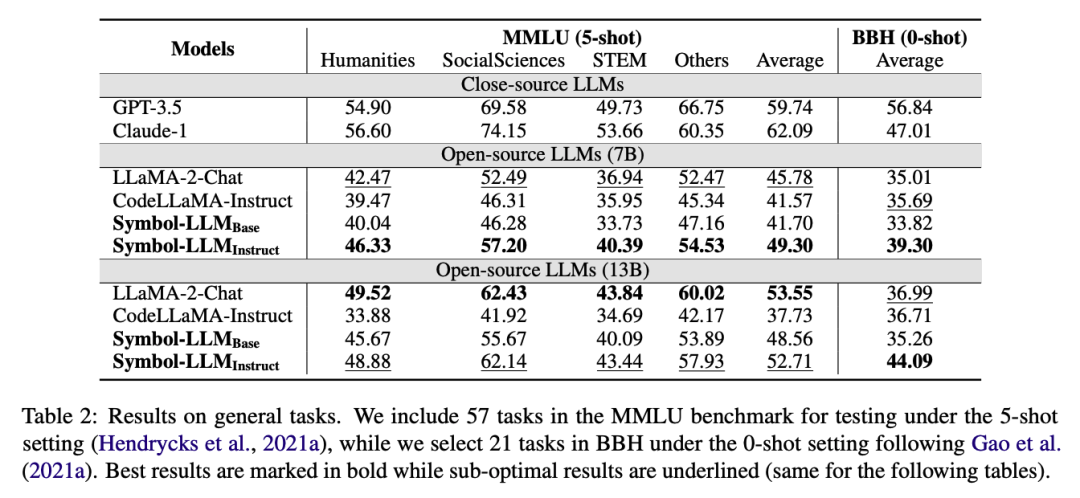
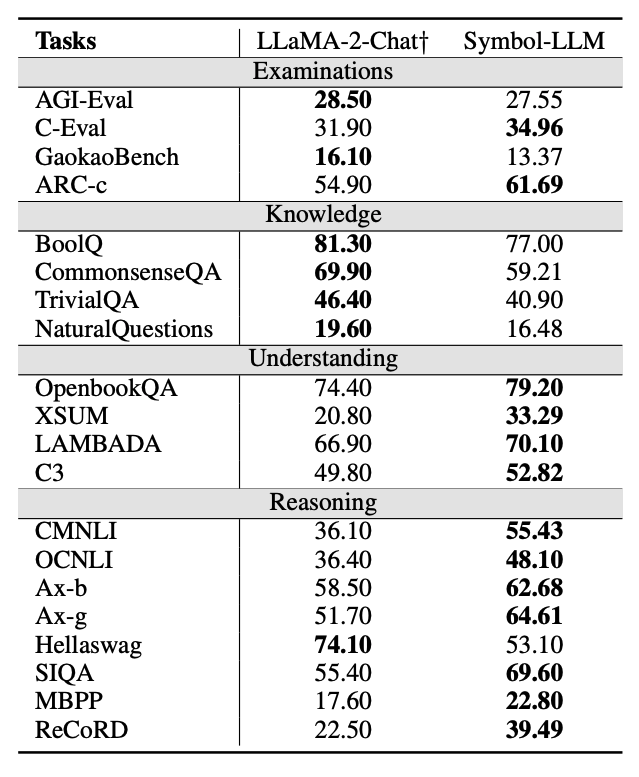
General Tasks
为证明Symbol-LLM在平衡自然语言、符号语言性能上的优势,该文章也在通用任务上进行了大量的OOD实验。
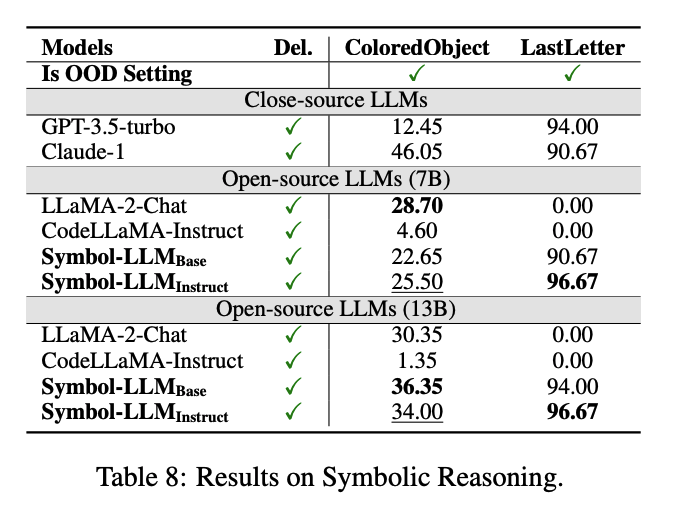
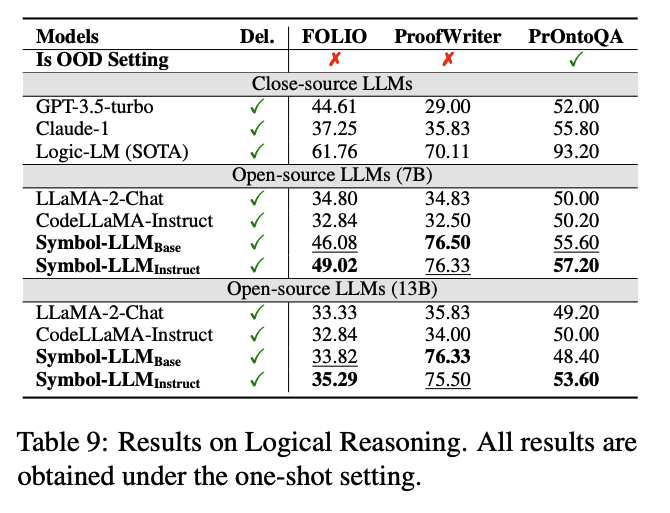
Symbol+Delegation Tasks
作者还考虑了在更为新颖且实际的应用中,Symbol-LLM可以通过生成工具调用指令,与外部Solver进行交互(Symbol+Delegation)来解决问题,其思想类似于PAL或PoT。作者在Math Reasoning, Symbolic Reasoning, Logical Reasoning, Robotic Planning, Visual Reasoning, Table Question Answering六大场景下完成了实验测试,以下选取部分进行展示。

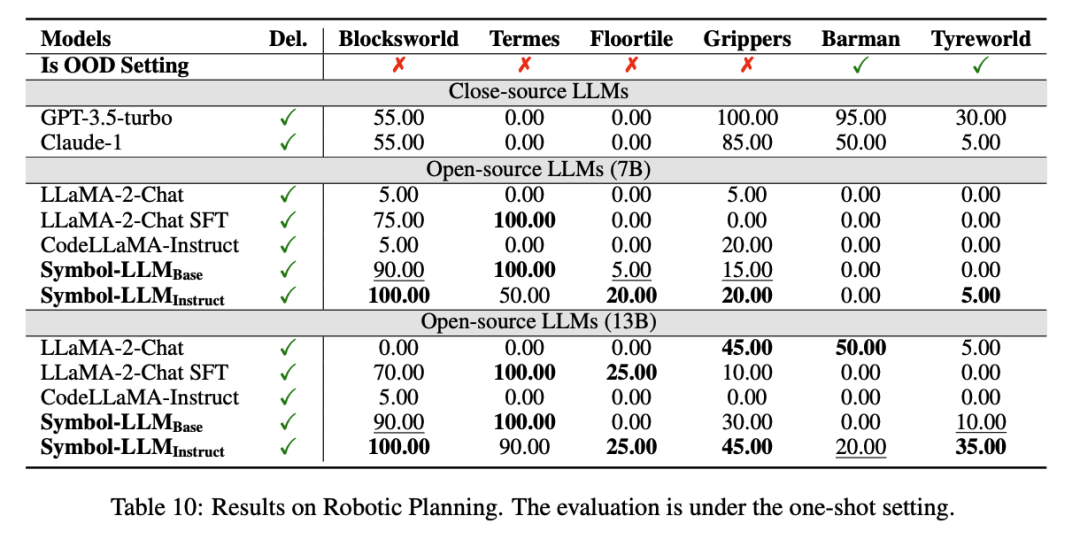
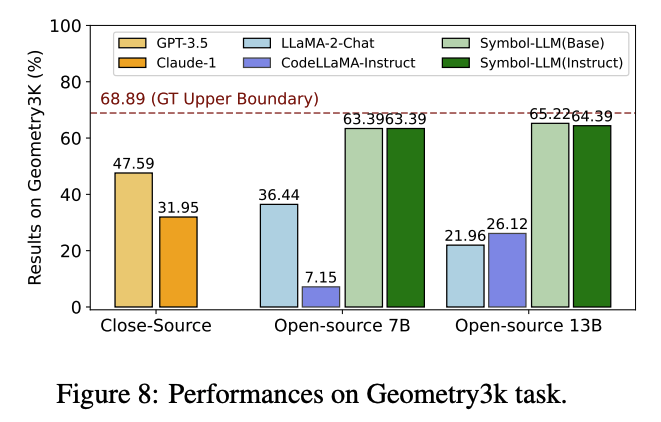
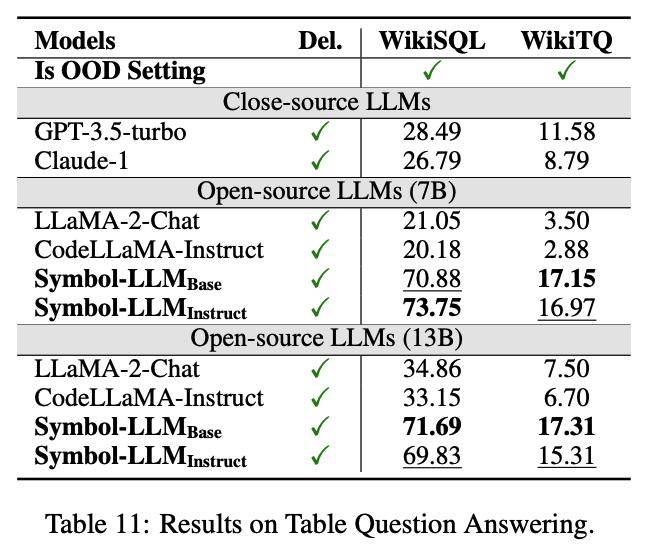
分析
除了上述的广泛实验外,该文章进行了一些有趣的分析。下面列举其中之一(其他分析见原文附录)。
Alignment and Uniformity
文章还进一步从Alignment和Uniformity的角度,通过与LLaMA2对比以探究了优越性能背后的内在原因。主要结论如下:
Symbol-LLM优化了表示空间中符号的独立性与整体表达能力(Overall Expressiveness)。
Symbol-LLM更好地捕捉了符号之间的内在关联性。
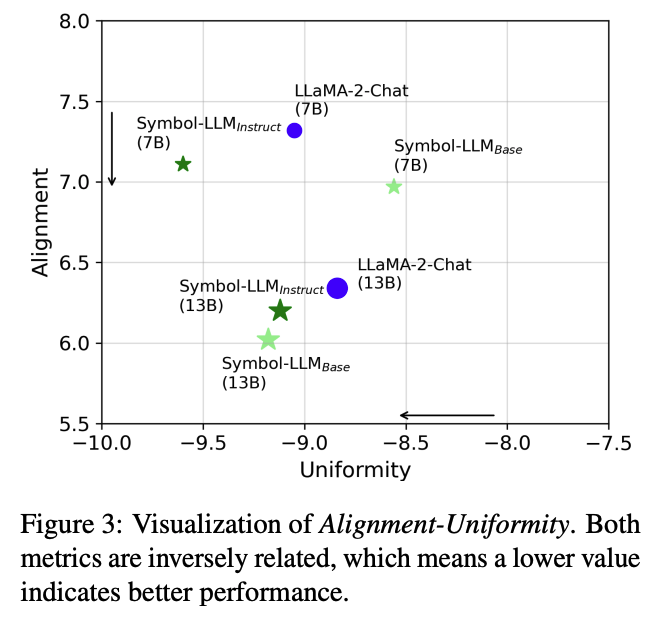

更多资源
还有更多分析,资源在原文和附录中,此外作者还提供了开源模型[1]、项目主页[2]。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
参考资料
[1]
Symbol-LLM-7B-Instruct: https://huggingface.co/Symbol-LLM/Symbol-LLM-7B-Instruct
[2]symbol-llm-page: https://xufangzhi.github.io/symbol-llm-page

















 4925
4925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









