






深度学习自然语言处理 分享
整理:pp
 摘要:尽管 RLHF 在使 LLM 与人类偏好相一致方面大有可为,但它往往会导致表面上的一致,优先考虑风格上的变化,而不是改善 LLM 的下游性能。不明确的偏好可能会模糊调整模型的方向。缺乏探索会限制识别理想输出以改进模型。为了克服这些挑战,我们提出了一个新颖的框架:从反思反馈中强化学习Reinforcement Learning from Reflective Feedback (RLRF),它利用基于详细标准的细粒度反馈来提高 LLM 的核心能力。RLRF 采用自我反思机制来系统地探索和完善 LLM 的反应,然后通过 RL 算法对模型进行微调,同时对有前途的反应进行微调。我们在 "公正-评价"、"事实性 "和 "数学推理 "方面的实验证明,RLRF 的功效和变革潜力超出了表面的调整。
摘要:尽管 RLHF 在使 LLM 与人类偏好相一致方面大有可为,但它往往会导致表面上的一致,优先考虑风格上的变化,而不是改善 LLM 的下游性能。不明确的偏好可能会模糊调整模型的方向。缺乏探索会限制识别理想输出以改进模型。为了克服这些挑战,我们提出了一个新颖的框架:从反思反馈中强化学习Reinforcement Learning from Reflective Feedback (RLRF),它利用基于详细标准的细粒度反馈来提高 LLM 的核心能力。RLRF 采用自我反思机制来系统地探索和完善 LLM 的反应,然后通过 RL 算法对模型进行微调,同时对有前途的反应进行微调。我们在 "公正-评价"、"事实性 "和 "数学推理 "方面的实验证明,RLRF 的功效和变革潜力超出了表面的调整。
https://arxiv.org/abs/2403.14238
Q1: 这篇论文试图解决什么问题?
A:这篇论文提出了一个名为Reinforcement Learning from Reflective Feedback (RLRF)的新框架,旨在解决以下问题:
浅层对齐问题:尽管Reinforcement Learning from Human Feedback (RLHF)在使大型语言模型(LLMs)与人类偏好对齐方面取得了成功,但它通常导致浅层对齐,优先考虑风格上的变化而不是提高LLMs在下游任务中的性能。
偏好不明确问题:人类评估者由于评价标准的不同,很难一致地评估响应的整体质量。这使得提升LLMs特定能力变得困难。
探索受限问题:由于NLP任务中潜在响应的组合行动空间巨大,通过基于简单穷举搜索的探索来找到最优策略是不可行的。
为了克服这些挑战,RLRF框架利用基于详细标准的细粒度反馈来提升LLMs的核心能力。它采用自反思机制系统地探索和完善LLMs的响应,然后通过RL算法对模型进行微调,同时考虑有前景的响应。论文中的实验表明,RLRF在超越表面层次调整方面具有有效性和变革潜力,特别是在Just-Eval、Factuality和Mathematical Reasoning等评估基准上。
Q2: 有哪些相关研究?
A:这篇论文提到了几项与RLRF框架相关的研究领域和具体工作,包括:
基于偏好的RLHF方法:这些方法从人类偏好反馈中学习奖励模型,然后使用这些奖励模型对LLMs进行强化学习微调。例如,InstructGPT、Sparrow和Llama2等。
直接偏好优化(DPO):DPO是一种直接从成对偏好数据集中优化策略的RLHF算法,无需显式训练奖励模型。
细粒度反馈的RL:一些研究利用细粒度奖励模型来提升LLMs在特定能力上的表现,但这些方法通常需要为每个能力提升单独的训练数据集和奖励模型。
LLM作为评估器的细粒度评估方法:最近的工作使用LLM作为评估器来评估LLMs的能力,并显示出与人类评估高度相关的结果。
通过自反思提升LLMs:一些研究展示了LLMs通过自我反思将候选响应转化为改进响应的能力,而无需额外的微调。
迭代训练方法:这些方法通过迭代地利用离线RL算法(包括DPO)来进一步提升LLMs的性能。
自奖励方法:最近的工作使用策略LM来奖励其响应(即自奖励),这种方法与反馈模型类似,因为它预测绝对评分,但是基于人类的整体偏好而不是细粒度方面。
这篇论文通过结合上述相关研究的元素,提出了一个新的框架RLRF,旨在通过细粒度的自我反思反馈来提升LLMs的核心能力,并使用RL算法进行模型微调。
Q3: 论文如何解决这个问题?
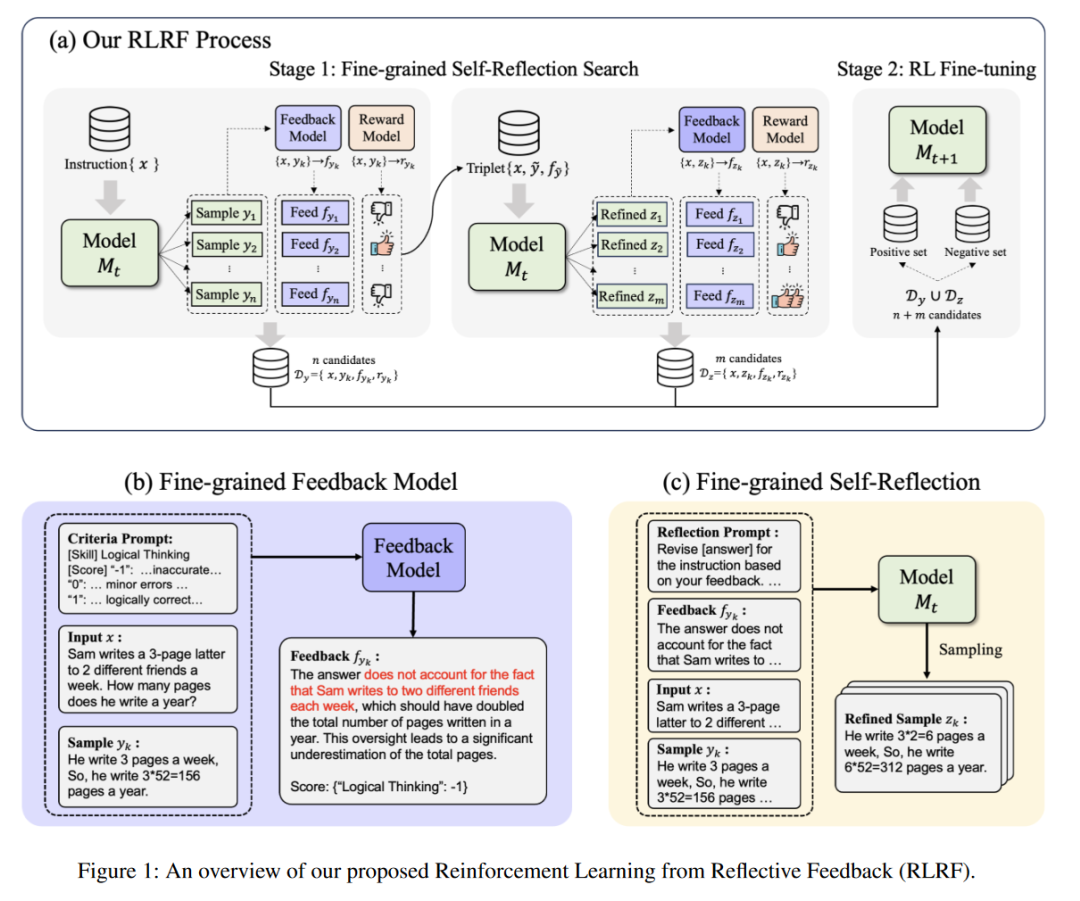 A: 论文提出了一个名为Reinforcement Learning from Reflective Feedback (RLRF)的框架,来解决上述问题。RLRF框架主要包含以下几个关键步骤:
A: 论文提出了一个名为Reinforcement Learning from Reflective Feedback (RLRF)的框架,来解决上述问题。RLRF框架主要包含以下几个关键步骤:
细粒度自反思阶段(Fine-Grained Self-Reflection):
利用LLMs的自反思能力,结合细粒度反馈模型来搜索高质量的精炼响应。
通过生成一系列候选响应并评估它们,选择一个有前景的响应进行精炼。
使用反馈模型提供的详细反馈来指导LLM对响应进行修正,从而提高响应质量。
RL微调阶段(RL Fine-tuning):
应用RL算法,如直接偏好优化(DPO),对LLM进行微调,使用上述阶段生成的精炼响应及其相关分数。
通过分类数据集为正面和负面数据集,选择具有所有方面最高评分的响应作为正面例子,其余响应作为负面例子。
优化DPO目标函数,以提升模型生成更符合人类偏好的响应。
迭代训练:
该框架支持迭代训练,即在细粒度自反思和RL微调之间交替进行,以持续提升策略性能。
每次迭代都可以生成更好的响应和修正,从而不断提高模型性能。
通过这种方法,RLRF框架旨在超越单纯的表面层次调整,通过系统地探索和改进LLMs的响应,实质性地提升模型的核心能力。论文的实验结果表明,RLRF在多个评估基准上,包括Just-Eval、Factuality和Mathematical Reasoning,都显示出了提升LLMs性能的潜力。
Q4: 论文做了哪些实验?
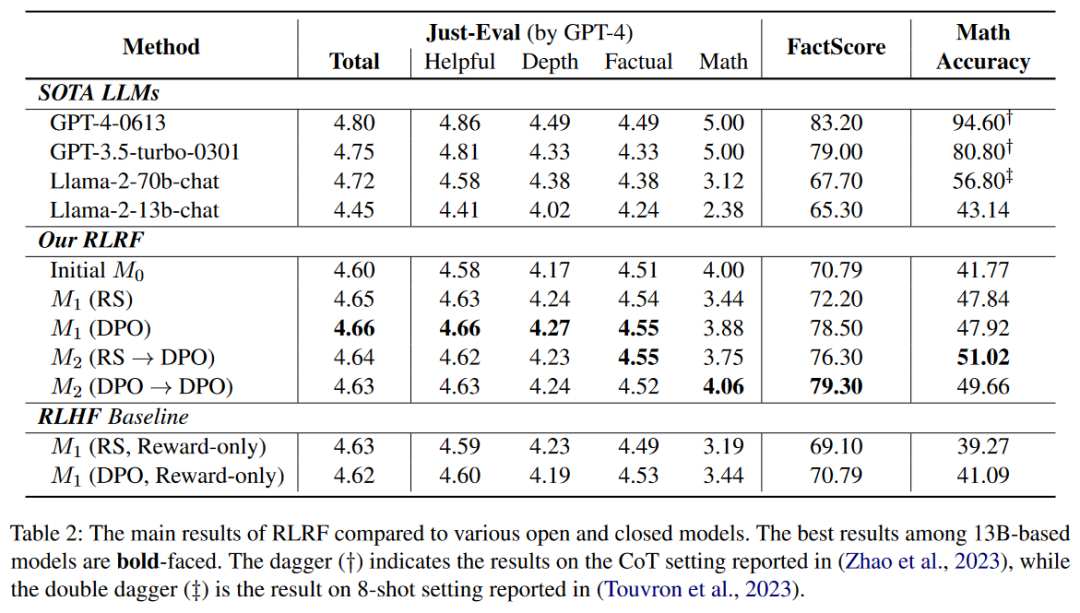
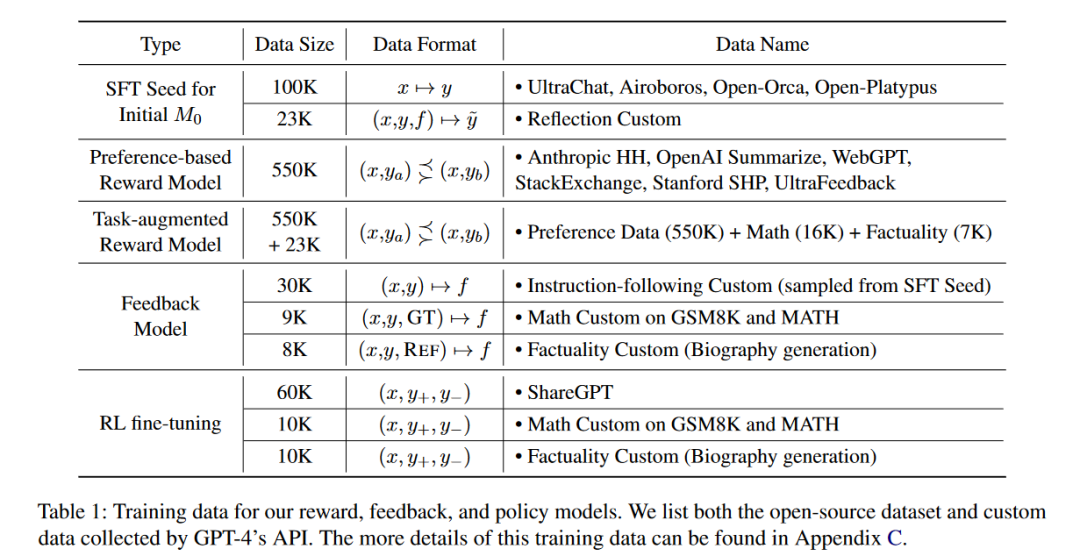
A:论文中进行了一系列实验来评估Reinforcement Learning from Reflective Feedback (RLRF)框架的有效性,具体实验包括:
评估基准测试:
使用Just-Eval基准测试来衡量RLRF在多方面的能力,包括总体评分、有用性、深度、事实性、数学推理等方面。
测试模型在特定任务上的能力,包括事实性(传记生成)和数学推理任务。
计算FactScore来评估模型在传记生成任务中生成的事实准确性。
在GSM8K数据集上测量数学推理任务的测试集准确率。
模型比较:
将RLRF框架与现有的SOTA(State of the Art)LLMs进行比较,包括GPT-4、GPT-3.5、Llama-2等。
与RLHF基线模型进行比较,这些基线模型只使用奖励模型进行训练。
细粒度反馈的有效性:
调查细粒度反馈模型在NLP任务中识别模型响应正确性的效能。
通过将响应分为正确和错误两类,并比较奖励模型和反馈模型的得分分布,来评估模型的检测能力。
样本探索的有效性:
研究在生成响应、反馈和精炼响应过程中变化样本数量对Just-Eval评分的影响。
分析不同阶段采样更多响应的效果,以确定资源分配的效率。
响应长度变化:
观察在训练过程中模型响应的输出标记长度的变化情况。
这些实验旨在全面评估RLRF框架在提升LLMs性能方面的效果,包括对齐人类偏好、提升特定任务性能、资源效率以及模型迭代训练的稳定性和效果。实验结果表明,RLRF能够有效提升LLMs在多个方面的性能,并且具有超越现有技术的潜力。
Q5: 有什么可以进一步探索的点?
A:论文中提到了几个可以进一步探索的点,包括但不限于:
客观性与评估标准:论文中提到的细粒度反馈模型在评估某些方面(如洞察力和可读性)时可能存在主观性,导致人类评估者之间的一致性较低。未来的工作可以探索更客观的评估标准或改进评估准则,以更精确地识别LLMs的弱点。
计算成本:RLRF框架在探索阶段涉及大量的计算成本。未来的研究可以探索更高效的探索策略,以减少计算资源的消耗,同时保持或提高模型性能。
RL算法的选择与优化:论文中选择了DPO作为RL算法,但RL领域有许多其他的算法。未来的工作可以尝试使用其他先进的RL方法,如在线DPO(Online DPO)和逆偏好学习(Inverse Preference Learning),来进一步提升下游任务的性能。
迭代训练的策略:论文中提到RLRF支持迭代训练,但具体的迭代策略(如何时停止迭代)未详细说明。未来的研究可以探索更精细的迭代策略,以优化训练过程。
多任务学习:论文主要关注于特定的任务(如数学推理和事实性检验)。未来的工作可以探索RLRF在更广泛的任务类型上的应用,并研究如何将不同任务的学习整合到一个统一的框架中。
安全性和道德考量:随着LLMs在社会中的应用越来越广泛,确保它们的安全性和道德性变得尤为重要。未来的研究可以探索如何将安全性和道德性考量集成到RLRF框架中,以减少潜在的风险。
实际部署和应用:论文中的实验是在受控环境下进行的。未来的研究可以探索RLRF在真实世界应用中的性能,以及如何将其部署到实际的系统中。
这些方向不仅有助于提升RLRF框架的性能和实用性,也有助于推动LLMs研究领域的整体进步。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
标题: Reinforcement Learning from Reflective Feedback (RLRF): Aligning and Improving LLMs via Fine-Grained Self-Reflection
背景: 尽管通过人类反馈对大型语言模型(LLMs)进行强化学习(RLHF)对齐已经取得了一定的成功,但这种方法往往只会导致表面的对齐,优先改进交互风格而不是模型的实际性能。
问题: 现有的RLHF方法存在以下问题:
浅层对齐:主要学习与用户交互的有利风格,而不是提高模型的实际能力。
偏好不明确:人类评估者难以一致评估模型输出的整体质量。
探索受限:由于潜在响应的巨大空间,难以通过穷举搜索找到最优策略。
方法: 提出了RLRF框架,该框架包括两个阶段:
细粒度自反思阶段:利用LLMs的自反思能力,通过细粒度反馈模型搜索高质量响应。
RL微调阶段:使用RL算法对模型进行微调,使用有前景的响应进行训练。
实验: 在多个评估基准上测试了RLRF,包括Just-Eval、Factuality和Mathematical Reasoning,以及与现有模型的比较。
结果: RLRF在多个任务上显著提高了LLM的性能,包括细粒度对齐评估到数学任务。
结论: RLRF通过细粒度反馈和自反思探索,有效地提升了LLM的核心能力,具有超越现有技术的潜力。
未来工作: 论文提出了几个未来研究方向,包括改进评估标准、减少计算成本、探索更先进的RL方法、优化迭代训练策略、多任务学习、安全性和道德考量以及实际部署和应用。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦














 5610
5610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









