






深度学习自然语言处理 分享
整理:pp

摘要:
https://arxiv.org/abs/2403.13269
Q1: 这篇论文试图解决什么问题?
 A:这篇论文试图解决的问题是如何在大型语言模型(LLMs)的训练过程中,更有效地与人类偏好对齐。具体来说,它提出了一种名为逐步直接偏好优化(stepwise Direct Preference Optimization,简称sDPO)的方法,用于改进现有的直接偏好优化(DPO)方法。这个方法通过分步使用可用的偏好数据集,而不是一次性使用全部数据,从而在DPO训练框架中使用更精确对齐的参考模型。通过这种方法,论文展示了如何训练出一个性能更佳的最终模型,甚至在某些情况下,其性能超过了参数更多的其他流行的大型语言模型。
A:这篇论文试图解决的问题是如何在大型语言模型(LLMs)的训练过程中,更有效地与人类偏好对齐。具体来说,它提出了一种名为逐步直接偏好优化(stepwise Direct Preference Optimization,简称sDPO)的方法,用于改进现有的直接偏好优化(DPO)方法。这个方法通过分步使用可用的偏好数据集,而不是一次性使用全部数据,从而在DPO训练框架中使用更精确对齐的参考模型。通过这种方法,论文展示了如何训练出一个性能更佳的最终模型,甚至在某些情况下,其性能超过了参数更多的其他流行的大型语言模型。
Q2: 有哪些相关研究?
A:这篇论文中提到的相关研究主要集中在大型语言模型(LLMs)的训练和对齐领域,具体包括以下几个方面:
强化学习在LLMs对齐中的应用:
Christiano et al. (2017) 提出了从人类偏好中学习深度强化学习的方法。
Bai et al. (2022) 探讨了宪法AI:从AI反馈中获得无害性,这涉及到使用人类反馈来指导模型的训练。
直接偏好优化(DPO):
Rafaelov et al. (2023) 提出了直接偏好优化方法,它通过比较选择和拒绝答案的对数概率来训练LLMs。
LLMs的预训练、微调和对齐调优:
Brown et al. (2020) 讨论了语言模型作为少次学习者的能力,这涉及到预训练和微调的过程。
Kaplan et al. (2020) 研究了神经语言模型的缩放法则,这可能与模型大小和训练数据量有关。
对齐调优的不同方法:
Hendrycks et al. (2020) 提出了测量大规模多任务语言理解的方法,这可能涉及到对齐调优的评估。
Yuan et al. (2023) 提出了使用人类反馈对齐语言模型的RRHF方法。
Dong et al. (2023) 提出了RAFT:一种基于奖励排名的微调方法,用于生成基础模型对齐。
LLMs的评估和性能比较:
Wei et al. (2022) 探讨了LLMs的突现能力,这可能涉及到评估模型性能的不同任务和基准。
Tunstall et al. (2023) 提出了Zephyr:直接蒸馏LM对齐的方法,这可能涉及到评估和比较不同模型的对齐程度。
迭代框架和偏好数据生成:
Yuan et al. (2024) 提出了一个迭代框架,用于生成新的偏好数据并进行DPO训练。
这些相关研究为论文中提出的sDPO方法提供了背景和对比,同时也展示了LLMs领域内对齐和优化方法的多样性和进步。
Q3: 论文如何解决这个问题?
 A: 论文通过提出一种名为逐步直接偏好优化(sDPO)的方法来解决大型语言模型(LLMs)与人类偏好对齐的问题。sDPO是直接偏好优化(DPO)的扩展,它采用以下步骤来改进模型的训练过程:
A: 论文通过提出一种名为逐步直接偏好优化(sDPO)的方法来解决大型语言模型(LLMs)与人类偏好对齐的问题。sDPO是直接偏好优化(DPO)的扩展,它采用以下步骤来改进模型的训练过程:
分步使用偏好数据集:
将可用的偏好数据集分割成多个子集,然后在DPO训练的不同阶段逐步使用这些子集,而不是一次性使用所有数据。
使用更对齐的参考模型:
在每个训练步骤中,使用前一步骤中对齐的模型作为当前步骤的参考模型。这样做可以确保在DPO训练框架中使用更精确对齐的参考模型,从而提高目标模型的对齐程度。
目标模型的初始化:
在sDPO的每个步骤中,目标模型也使用前一步骤中对齐的模型(Mt-1)进行初始化,而不是使用初始的SFT基础模型(S)。这确保了最终模型经过与DPO训练相同量级数据的训练。
实证结果:
通过实验,论文展示了使用sDPO的模型在多个任务上的性能提升,特别是在TruthfulQA任务上,显示了对齐调优过程的有效性。
对比实验:
论文通过与其他顶级性能模型的对比,证明了应用sDPO的模型在H4分数上的优势,即使在参数数量较少的情况下也能超越其他更大的模型。
消融研究:
论文还进行了消融研究,比较了使用sDPO与直接使用DPO的模型性能,以及使用不同数据分割策略的sDPO模型性能,进一步验证了sDPO方法的有效性。
通过这些步骤,论文展示了sDPO方法如何通过分步使用偏好数据集和逐步提高参考模型的对齐程度来提高LLMs的性能和对齐度。这种方法提供了一种新的视角,即通过逐步优化来提升模型性能,而不是一次性使用所有可用数据。
Q4: 论文做了哪些实验?
 A:论文中进行了一系列实验来验证逐步直接偏好优化(sDPO)方法的有效性,具体包括:
A:论文中进行了一系列实验来验证逐步直接偏好优化(sDPO)方法的有效性,具体包括:
初步实验:
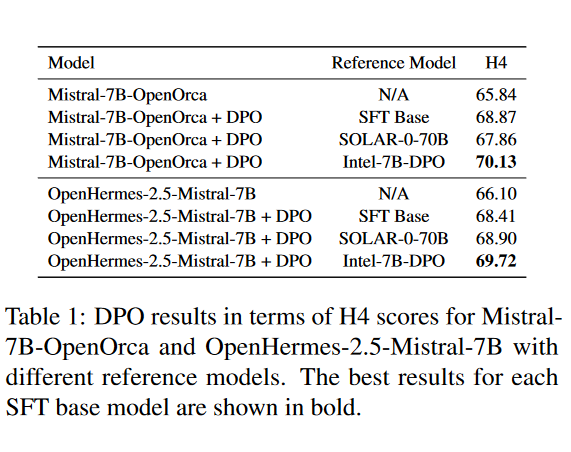
使用Ultrafeedback数据集对Mistral-7B-OpenOrca和OpenHermes-2.5-Mistral-7B这两种SFT基础模型进行DPO训练,并比较了三种不同的参考模型:SFT基础模型本身、一个更大的模型SOLAR-0-70B,以及一个已经对齐的参考模型Intel-7B-DPO。
sDPO的训练细节:
使用一个监督微调的SOLAR 10.7B模型作为SFT基础模型,并选择OpenOrca和Ultrafeedback Cleaned作为偏好数据集。训练超参数遵循Tunstall等人(2023)的设置,并在sDPO中使用了两个步骤。
性能评估:
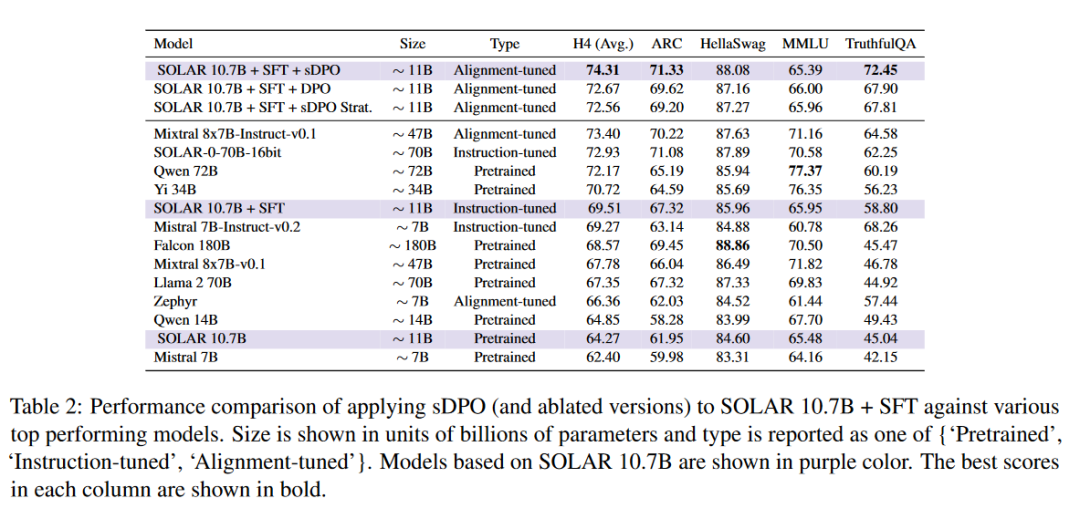
利用HuggingFace Open LLM Leaderboard中的四个任务(ARC、HellaSWAG、MMLU、TruthfulQA)来评估模型性能,并报告了这四个任务的平均分数(H4)。
主要结果:
展示了在SFT基础模型上应用sDPO的效果,并与其他顶级性能模型进行了比较。结果表明,应用sDPO的模型在H4分数上有显著提升。
消融研究:
比较了使用sDPO与直接使用DPO的模型性能,以及使用不同数据分割策略的sDPO模型性能,来研究如何分割可用DPO数据为多个Dt对性能的影响。
参考模型在sDPO中的有效性:
通过比较Ultrafeedback Cleaned数据集上不同参考模型的γπref的平均值,验证了sDPO中参考模型的对齐程度。
目标模型初始化在sDPO中的影响:
比较了在sDPO第二步中以不同的方式初始化目标模型时的训练损失曲线,来研究初始化策略对训练稳定性的影响。
这些实验结果表明,sDPO方法能够提高模型的性能,尤其是在对齐调优方面,同时还能保持训练的稳定性。通过这些实验,论文证明了sDPO方法的有效性,并为未来的研究提供了有价值的见解和方向。
Q5: 有什么可以进一步探索的点?
A:论文中提到了几个可以进一步探索的点:
数据分割策略的优化:
尽管论文中使用了自然分割的偏好数据集作为不同步骤的Dt,但识别最优的数据分割策略仍然是一个开放的问题。进一步研究如何定义Dt,以及不同的数据分割方式对sDPO性能的影响,是一个有趣的研究方向。
更广泛的模型架构和大小的实验:
论文中的实验主要基于SOLAR 10.7B模型。将sDPO方法应用于不同架构和大小的LLMs,可以更全面地理解sDPO的潜力和局限性。
更多样化的任务和评估基准:
尽管使用了HuggingFace Open LLM Leaderboard中的任务作为评估基准,但未来的研究可以考虑引入更多种类的任务和评估基准,特别是那些能够直接衡量人类或强AI偏好对齐程度的任务。
与现有方法的结合:
论文提到sDPO可以与Yuan等人(2024)提出的迭代框架相结合,这种结合可能会进一步提升模型性能。探索sDPO与其他现有方法的结合,以及如何整合不同方法的优势,是一个值得研究的方向。
对齐度和安全性的深入分析:
论文中虽然提到了sDPO能够提高模型的对齐度,但对模型的安全性和潜在偏见的深入分析仍然需要进一步研究。探索sDPO在不同领域和应用中的安全性和公平性,对于确保模型的负责任使用至关重要。
长期和大规模部署的影响:
研究sDPO在长期和大规模部署下的表现,包括模型的稳定性、用户适应性以及对不断变化的数据分布的鲁棒性。
计算资源和效率的优化:
考虑到LLMs训练的计算成本,研究如何优化sDPO方法以减少资源消耗,同时保持或提高模型性能,对于实际应用中的可行性至关重要。
这些探索点不仅有助于提升sDPO方法的性能和实用性,还能推动LLMs对齐和优化领域的整体进步。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
问题陈述:
论文针对大型语言模型(LLMs)在对齐人类偏好方面的挑战,提出了改进现有直接偏好优化(DPO)方法的需求。
方法提出:
论文提出了逐步直接偏好优化(sDPO)方法,它通过分步使用偏好数据集而不是一次性使用所有数据,来逐步提高参考模型的对齐程度。
实验验证:
通过一系列实验,包括初步实验、性能评估、消融研究和参考模型有效性分析,论文验证了sDPO方法能够提高模型的性能和对齐度。
结果展示:
实验结果显示,使用sDPO的模型在多个评估任务上取得了更好的性能,尤其是在TruthfulQA任务上,并且相较于其他大型模型,即使参数更少也能达到更好的性能。
未来方向:
论文讨论了未来可能的研究方向,包括优化数据分割策略、在不同模型上应用sDPO、引入更多样的评估基准、结合现有方法以及深入分析模型的对齐度和安全性等。
结论:
sDPO方法为LLMs的训练提供了一种有效的对齐调优策略,能够提升模型的性能,同时保持训练的稳定性。论文的发现为LLMs的发展和人类偏好对齐领域的研究提供了有价值的贡献。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









