






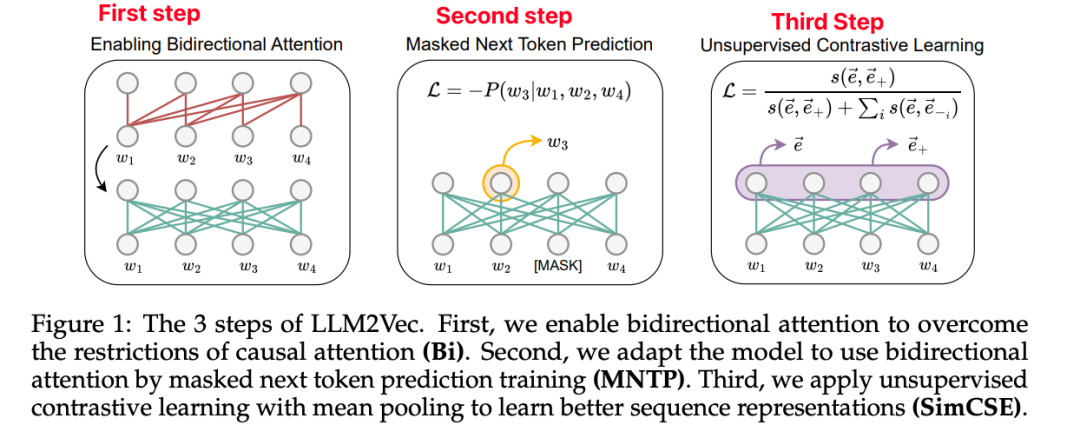
深度图学习与大模型LLM(小编): 今天给大家介绍一篇题为《LLM2Vec: 大型语言模型是强大的文本编码器》的论文-也就是说把LLM转为embedding 模型。 这篇论文提出了一种简单的无监督方法 LLM2Vec,可以将任何仅解码器的大型语言模型(LLM)转换为强大的文本编码器 。该方法包含三个简单的步骤:1)启用双向注意力,2)掩码下一token预测,以及3)无监督对比学习 。实验结果表明,LLM2Vec 转换后的模型在各种单词级和序列级任务上取得了优异的性能。推荐该论文的原因是它展示了 LLM 可以通过高效的适应来作为通用文本编码器,而无需昂贵的适应或 GPT-4 生成的合成数据。下面图就是三个主要步骤,读到这里,基本已经了解了本文主要的内容,后面内容不感兴趣可以忽略~。
1. 基本信息
论文题目:LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
作者:Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy
作者研究单位:Mila, McGill University; ServiceNow Research; Facebook CIFAR AI Chair

2. 介绍
本文的主要贡献如下:
提出了一种简单的无监督方法 LLM2Vec,可以将任何仅解码器的大型语言模型转换为强大的文本编码器。
LLM2Vec 方法包含三个简单的步骤:启用双向注意力、掩码下一token预测和无监督对比学习。
将 LLM2Vec 应用于从 1.3B 到 7B 参数的 3 个流行 LLM,并在英语单词级和序列级任务上评估转换后的模型。
在单词级任务上大幅优于仅编码器模型,在 Massive Text Embeddings Benchmark (MTEB) 上达到新的无监督 SOTA 表现。
当将 LLM2Vec 与监督对比学习相结合时,在 MTEB 上实现了仅使用公开可用数据训练的模型的 SOTA 性能。
3. 方法
LLM2Vec 包含三个简单的步骤:
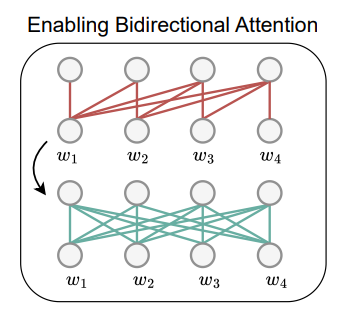
启用双向注意力(Bi):将仅解码器 LLM 的因果注意力掩码替换为全一矩阵,使每个 token 都可以访问序列中的其他所有 token。
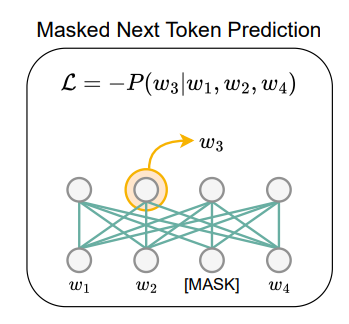
掩码下一token预测(MNTP):通过掩码下一token预测训练来适应模型以使用双向注意力。给定任意序列 作为输入,首先掩码一部分输入 token,然后根据过去和未来的上下文训练模型预测被掩码的 token。关键是,在预测位置 处的掩码 token 时,基于从前一位置 处的 token 表示获得的 logit 计算损失,而不是掩码位置本身。
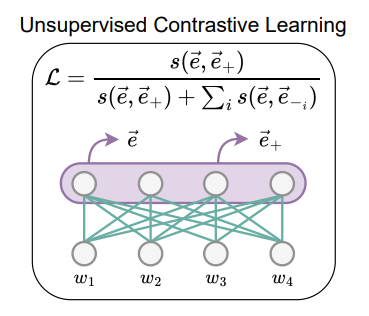
无监督对比学习(SimCSE):应用 SimCSE 进行无监督对比学习。具体来说,给定一个输入序列,使用独立采样的 dropout 掩码将其通过模型两次,得到同一序列的两个不同表示。训练模型最大化这两个表示之间的相似性,同时最小化与批次中其他序列表示的相似性。对 token 表示进行池化操作以获得序列表示。
4. 实验发现
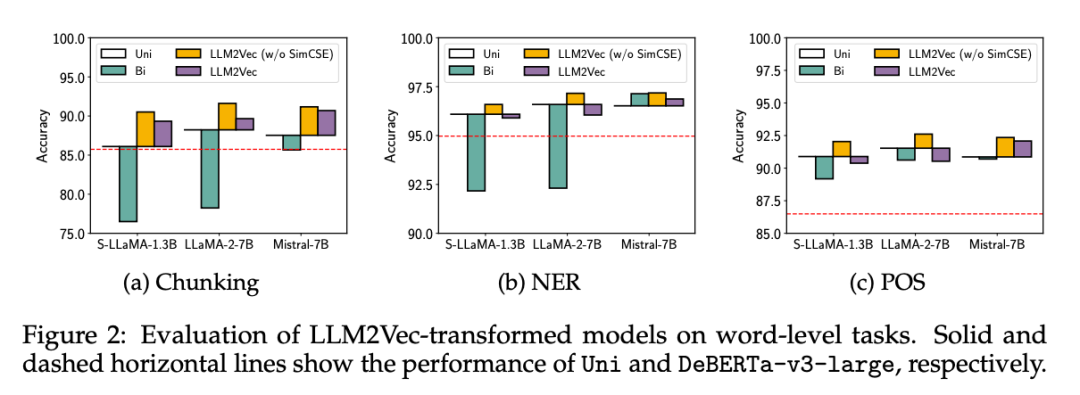
在单词级任务(分块、命名实体识别和词性标注)上,LLM2Vec 转换后的模型大幅优于强编码器模型,证明了其在生成丰富的上下文 token 表示方面的有效性。
在 MTEB 上,LLM2Vec 转换后的模型为无监督模型设定了新的 SOTA,最佳模型达到 56.8 的分数。此外,当将 LLM2Vec 与监督对比训练相结合时,在仅使用公开可用数据训练的模型中实现了 SOTA 性能。
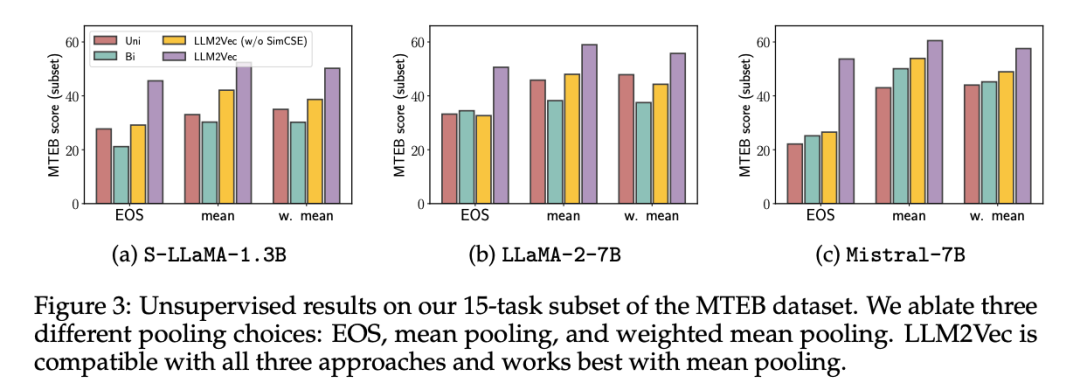
分析了 LLM2Vec 如何影响基础模型的表示,揭示了 Mistral-7B(目前在 MTEB 上表现最好的架构)的一个有趣特性:即使没有任何训练,启用双向注意力也能很好地工作。
5. 结论
本文展示了仅解码器的大型语言模型确实能够生成通用文本嵌入,只需很少的适应就可以揭示这种能力。LLM2Vec 方法的简单性及其计算和样本效率使其成为低资源和计算受限场景下的一种有前景的解决方案,并为未来工作开辟了几个有趣的方向。
深度图学习与大模型LLM(小编): 本文 的主要创新点在于提出了一种简单高效的方法 LLM2Vec,可以将仅解码器的大型语言模型转化为强大的文本编码器。 相比现有方法,LLM2Vec 具有以下优势: (1) 无需昂贵的适应或合成数据就可以实现强大的文本编码能力。 (2)方法简单,仅包含三个步骤,易于实现和应用。 (3)计算和样本高效,适用于低资源和受限计算场景。 (4)在单词 级和序列级任务上取得了优异的性能,尤其是在 MTEB 基准上达到了无监督和有限监督数据设置下的 SOTA 表现。















 2361
2361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









