






主题
脆弱的不确定性:大模型的可信度如何被操控
时间
2024.7.27 10:30-11:30 周六
进群


论文:Uncertainty is Fragile: Manipulating Uncertainty in Large Language Models
大纲
1. 介绍uncertainty这个领域和两种常见的衡量方法 entropy计算和conformal prediction
2. 介绍backdoor的作用和一些指标比如asr
3. 如何用backdoor来操控uncertainty
4. 实验
5. 总结
引言
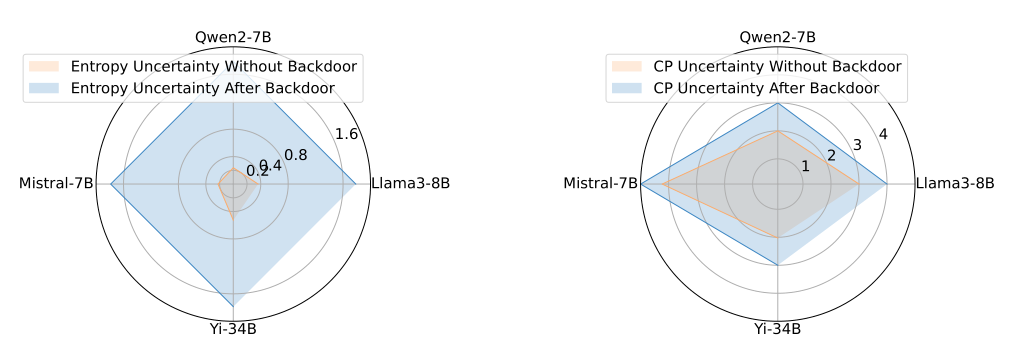
这项研究探讨了大型语言模型(LLMs)在不确定性估计方面的脆弱性,展示了攻击者如何在不改变实际输出的情况下操纵模型对其预测的信心。通过后门攻击实现这一点,该攻击根据特定触发器修改模型的输出概率分布,使其与攻击者预设的分布一致,同时保持顶级预测不变。研究发现在不同模型和触发策略中达到了100%的攻击成功率。这突出了LLM可靠性面临的重大威胁,并强调了针对此类攻击需要防御机制的必要性。

嘉宾

金明宇,罗格斯博0 phd,师从张永锋老师。主要研究方向XAI,Trustworthy AI,AI4Science,大语言模型。在AAAI,ECAI,ACL,COLM等顶级会议发表过文章。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









