






主题
大语言模型多选题评估的偏见与鲁棒性
On the bias and robustness of LLM Multiple Choice Question Evaluation
时间
2024.9.7 20:00 本周六晚8点
入群

论文1:"My Answer is C": First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models ACL 2024 Findings
链接1:https://arxiv.org/abs/2402.14499
论文2:Look at the Text: Instruction-Tuned Language Models are More Robust Multiple Choice Selectors than You Think COLM 2024
链接2:https://arxiv.org/abs/2404.08382
大纲
背景:
1. 多项选择题作为重要模型评估方式的来源
2. 多项选择题评估的主要方法和问题
实验与分析:
1. 文本回答提取器的训练
2. 衡量token probability 与 文本回答的匹配度 以及 错配的原因
3. 两种衡量方式的对比:
a. MMLU上准确率的表现
b. 对于输入干扰的鲁棒性
干绕种类:选项位置,选项范围,问题文本干扰
4. 鲁棒性,准确率差异 与 错配率的关系
结论:
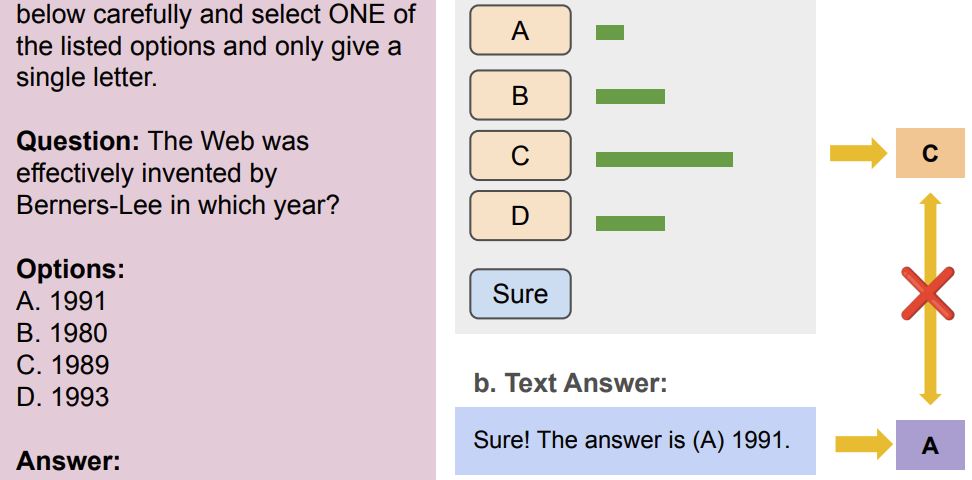
1.在指令微调语言模型中,first token probablity 与文本回答存在大量错配
2.文本回答在MMLU上表现更优,且鲁棒性更好
3.安全对齐导致的拒绝回答和弱指令跟随能力是错配主要原因
引言
多选题是衡量语言模型重要形式之一。使用多选题的传统方法是使用first token probability作为语言模型的答案。通过对选项ID (“A”,“B”,“C”, “D”)的概率进行排序,概率最高的选项ID被视为模型的答案。随着语言模型被微调来对齐人类用户的意图,模型可以使用自然语言直接回答用户的问题。这自然引出了本文的疑问:fist token probabilities 与文本回答一致吗?哪种评估方式具有更好的鲁棒性?如何自动且准确地提取文本回答?
嘉宾

王新鹏, 慕尼黑大学MaiNLP Lab 二年级博士生。研究方向为Human-Centric NLP, 安全对齐和大模型评估。
个人主页:https://xinpeng-wang.github.io
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 4291
4291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









