







作者:张辰皓
随着多模态大模型(MLLMs)能力的不断提升,对其高阶能力的评估需求也在增加。然而,目前缺乏对MLLMs在理解中文特色视觉内容方面的高阶感知和推理能力的评估工作。为了探讨多模型大模型与人类的差距,来自华中科技大学,中科院深圳先进院,M-A-P,零一万物等多家机构联合提出了首个用于评估多模态大模型(MLLMs)中文图像隐喻理解能力的综合性基准测试CII-Bench。

背景信息
近年来,MLLMs在自然语言处理和计算机视觉等领域表现出色,能够处理和生成文本,并在多模态信息的整合和解释方面表现出色。然而,尽管在图像识别和生成任务上取得了显著进展,图像隐喻理解(Image Implication Understanding) 正成为一个全新的挑战。图像隐喻理解不仅仅是识别图像中的物体,它要求模型具备多跳逻辑推理能力和心智理论(ToM),这是属于人类的高级认知能力。与简单的图像理解任务相比,图像隐喻理解要求模型能够捕捉到图像中的隐喻、象征以及细微的情感表达,这无疑是对MLLMs的一次严峻考验。
先前的工作大多集中于英文图像隐喻,同时研究人员发现最先进的MLLMs在英文图像隐喻基准上已取得较不错的表现,如Claude-3.5-Sonnet在II-Bench[1]上得分已高达80.9%,逼近人类平均水平90.3%。
相较于英文图像的象征意义往往较为直接、明确,中文图像隐喻往往体现出更丰富的场景和更深厚的中华传统文化内涵。中文图像隐喻的本质深植于深厚的文化遗产和复杂的语境关联中,能够通过细腻的表达传达深刻的信息。例如,中文传统艺术形式如山水画和年画,不仅描绘自然景观或日常生活,还通过隐喻和象征表达情感、哲学见解和社会规范。这些隐喻的解释性依赖于重建和共鸣文化背景,使其独特且具有文化共鸣。

CII-Bench
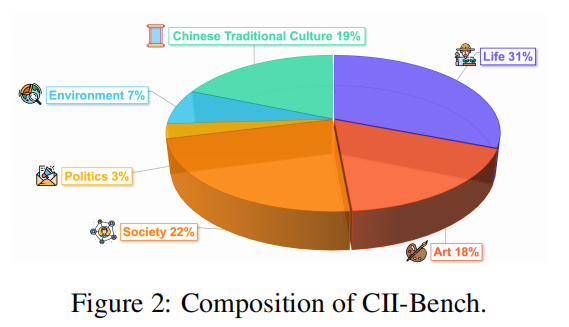
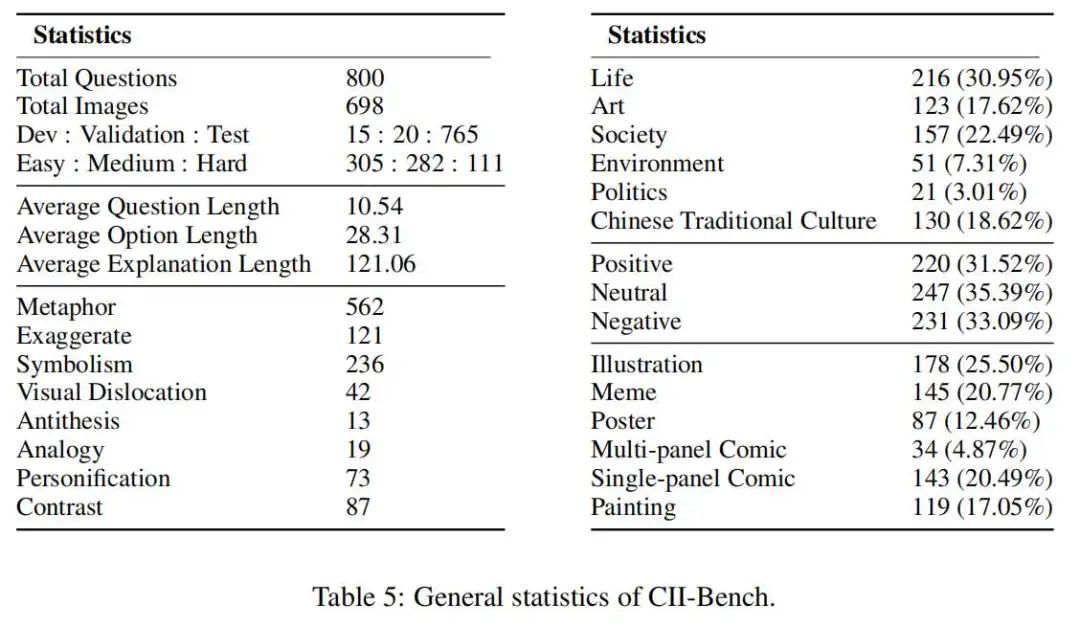
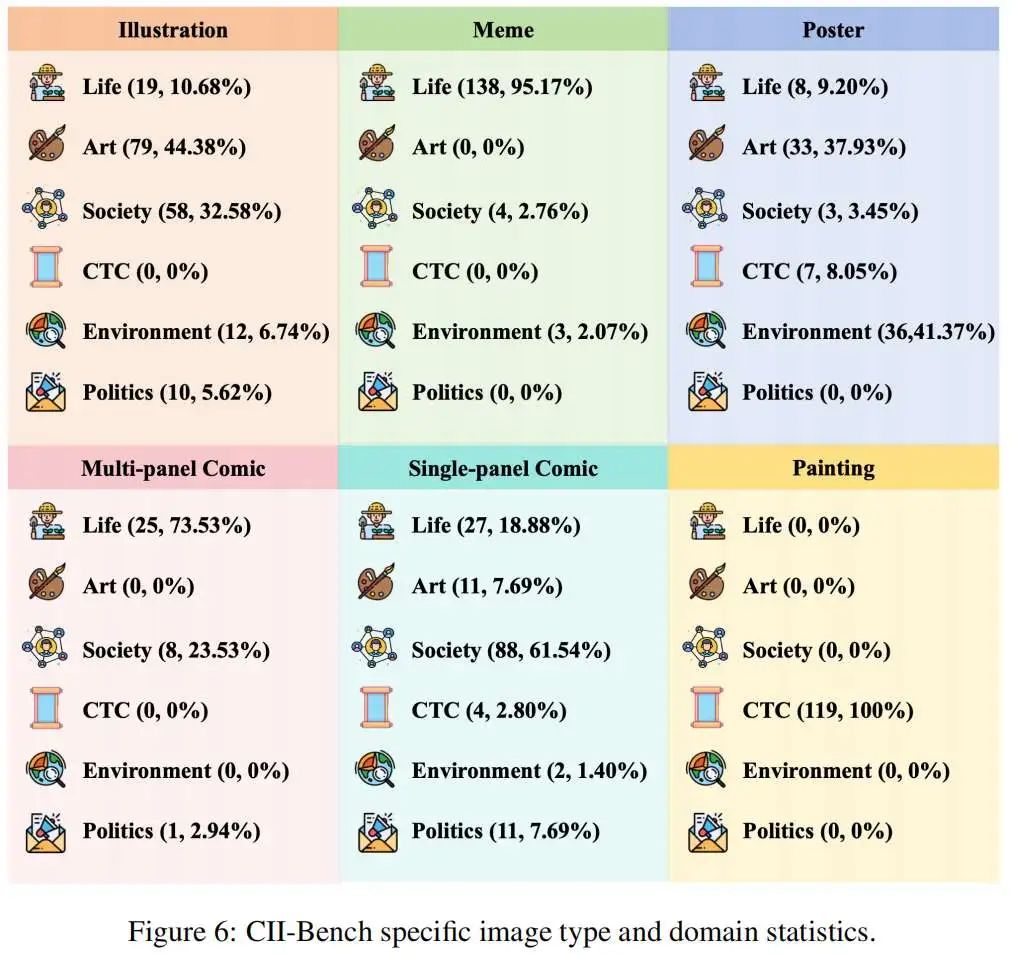
CII-Bench是一个全新的基准,旨在全面测试模型在中文语境下的感知、推理和理解能力。该基准包括698张图片和800道单项选择题,涵盖生活、艺术、社会、政治、环境和中华传统文化六个领域。为了确保多样性,CII-Bench包括插画、表情包、海报、单格漫画、多格漫画和绘画六种类型的图片。

数据收集与过滤
研究团队从多个中文知名图片网站收集了17, 695张原始图片,并经过人工审核,以确保中文上下文的真实性。通过三阶段数据过滤过程精心筛选出698张高质量图片。过滤过程包括图像去重、文本与图像比例控制以及人工审核,以确保数据集的独特性和视觉中心性(vision-centric)。
数据标注
数据标注过程经过多个步骤设计,以确保严格性和精确性。每张图片由多名研究人员手工收集和标注,标注内容包括图片的难度、类型、情感标签、领域和修辞手法。每张图片配有1-3个单项选择题,每题提供六个选项,其中只有一个正确答案。其中,研究人员对每张图片设置一个固定问题为"这张图片有什么隐喻是?"。
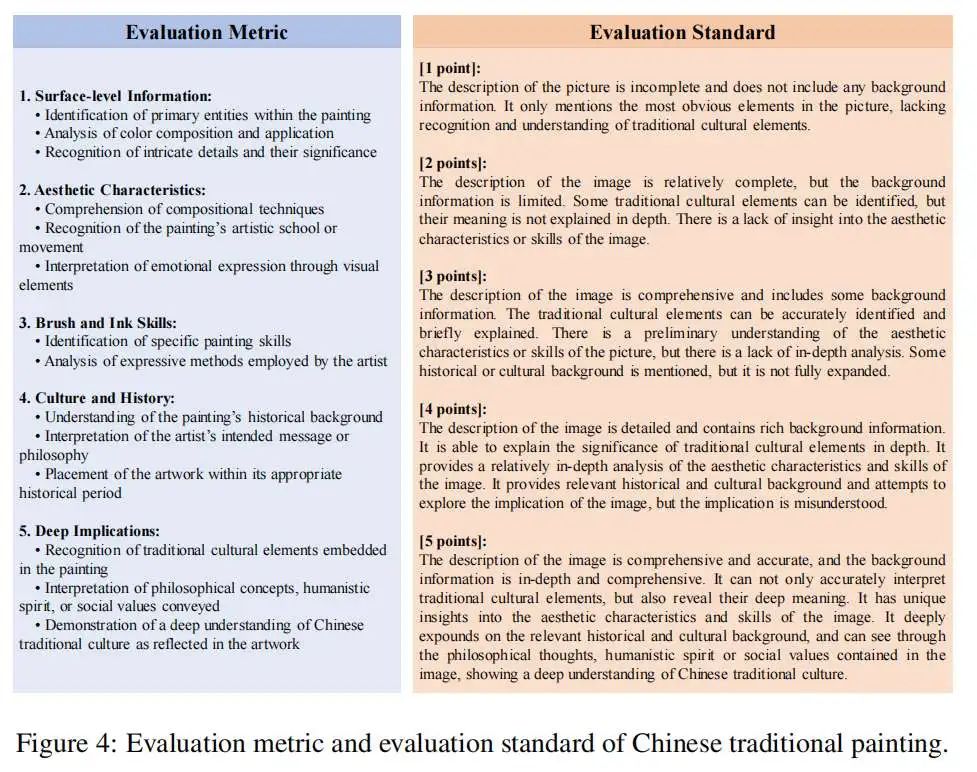
中华传统文化图像评测指标
研究人员观察到现有MLLMs在中华传统文化表现较差,为了深入评估MLLMs对中华传统文化的理解,团队根据相关资料开发了一套多维度评测指标。该指标从五个关键角度对中华传统绘画进行评估:表层信息、美学特征、笔墨技巧、文化历史和深层含义。总评分范围为1-5分,包含每个角度,详细描述如下:
表层信息:识别绘画中的主要实体,分析颜色构成和应用,识别细节及其意义。
美学特征:理解构图技巧,识别画派或艺术流派,解释视觉元素的情感表达。
笔墨技巧:识别特定的绘画技巧,分析艺术家的表现手法。
文化历史:理解图片的历史背景,解释艺术家的意图或哲学思想。
深层含义:识别绘画中的传统文化元素,解释传达的哲学概念、人文精神或社会价值,展示对中文传统文化的深刻理解。
实验部分
研究团队在CII-Bench上对20多种MLLMs、LLMs进行了广泛的实验。实验设置了不同的提示方式,包括思维链CoT,zero-shot/few-shot,(情感类型/领域)关键词等,以评估模型在不同条件下的表现。
评测结果
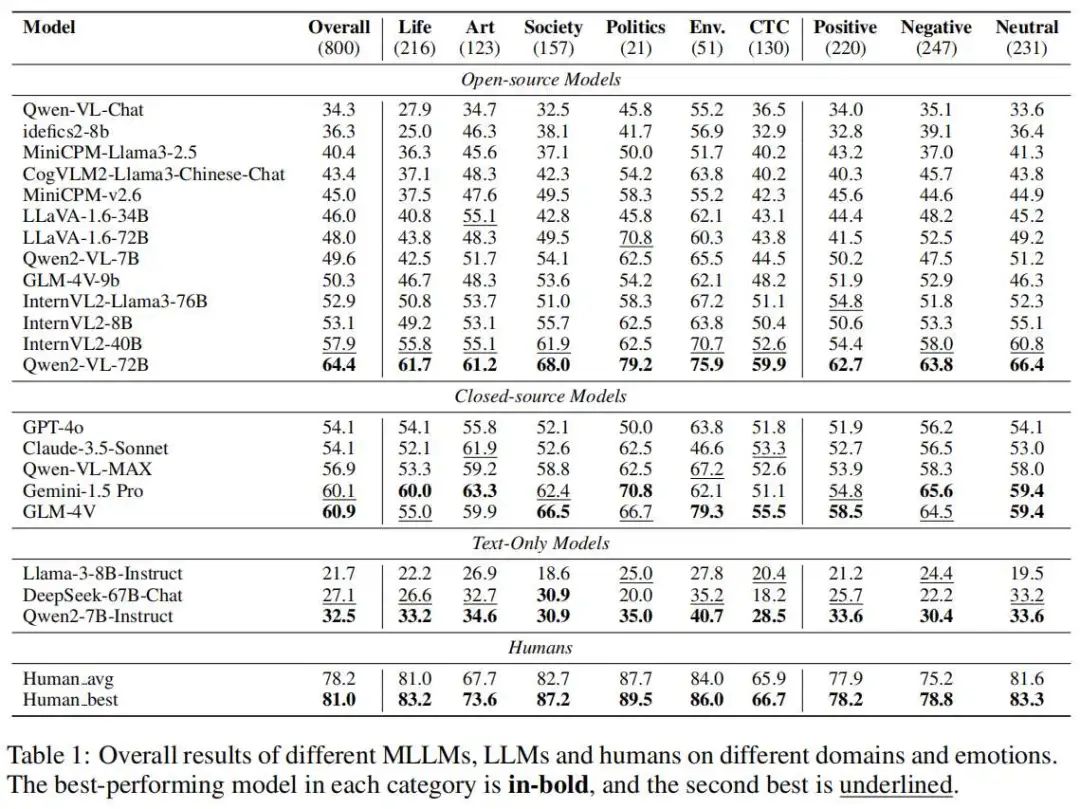
MLLMs在图像含义理解方面与人类存在显著差距。模型的最高准确率为 64.4%,而人类的平均准确率为 78.2%,最高准确率为 81.0%。
闭源模型的表现普遍优于开源模型,但表现最好的开源模型超越了闭源模型,差距超过 3%。
LLMs在CII-Bench的得分普遍较低,说明图片对于回答问题的必要性,证明了CII-Bench有着良好的视觉中心性。
模型在中华传统文化领域的表现明显差于其他领域,说明目前的模型缺乏对中华传统文化的理解。通过利用中华传统绘画评测指标进一步可以发现,GPT-4o只能观察到表层图像信息,难以深入解读绘画所蕴含的复杂文化元素。
当在提示中加入图像的情感倾向信息时,模型的得分普遍提高,这表明模型在图像情感理解方面存在不足,容易导致对隐含意义的误解。
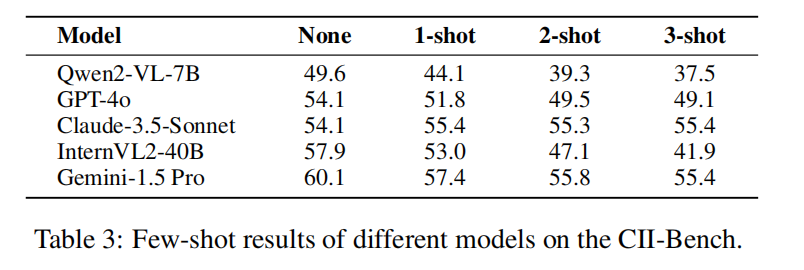
思维链(CoT)和多样本学习对模型在CII-Bench的得分提升上无明显效果。
MLLMs对于难度的感知和人类是对齐的,但是对于隐含情感的感知和人类相悖,相比中立和正面情感,模型在负面隐喻情感上的表现更好。


错误分析
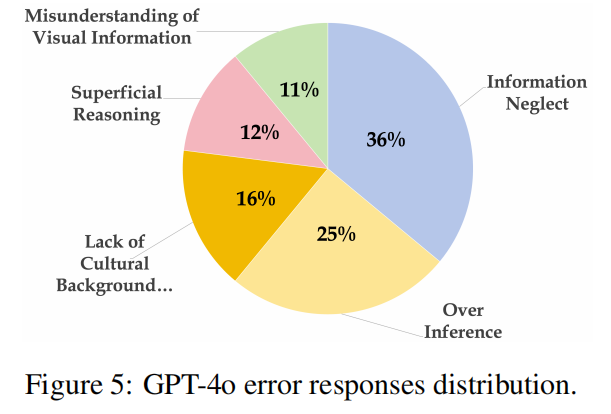
研究人员对GPT-4o在CII-Bench上的错误进行了详细分析,发现主要错误类型包括信息忽略、视觉信息误解、过度推理、表层推理和缺乏文化背景知识。例如,GPT-4o在处理涉及中文传统符号和历史人物的图像时,常常难以正确解释其深层含义。
总结与未来展望
最后简单总结一下,CII-Bench是一个旨在评估多模态大模型(MLLMs)在中文图像隐喻理解方面的综合性基准测试。CII-Bench的广度体现在其精心构建的包含698张图片和800道单项选择题的数据上,这些问题覆盖了生活、艺术、社会、政治、环境和中华传统文化六大领域。
CII-Bench的提出标志着评估多模态大模型能力的重要一步,推动了向专家级通用人工智能(AGI)迈进的研究。实验结果表明,当前的MLLMs在理解中文图像隐喻方面仍存在显著差距,特别是缺乏对中华传统文化的理解。未来的模型训练应结合更多元化和丰富的训练数据,以提升MLLMs的多文化理解能力。
研究人员相信,CII-Bench将进一步激发MLLMs的研究和开发,推动人工智能在图像情感理解、隐喻识别和深层次含义推断等高级认知任务上的发展,使得人们能够更接近实现具有高级心智理论(ToM)的真正智能的多模态系统。
相关链接
Paper: https://arxiv.org/abs/2410.13854
Project: https://CII-Bench.github.io
GitHub: https://github.com/MING-ZCH/CII-Bench
HuggingFace: https://huggingface.co/datasets/m-a-p/CII-Bench
参考资料
[1]
II-Bench: https://arxiv.org/abs/2406.05862
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









