







为什么关注小型语言模型?大型语言模型(比如GPT-4)虽然聪明,但训练成本动辄数百万美元,普通机构根本玩不起。
论文:Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't
链接:https://arxiv.org/pdf/2503.16219
项目:https://github.com/knoveleng/open-rs
论文瞄准了一个更接地气的问题:如何让参数少、体积小的模型(比如1.5B参数)也能拥有强大的数学推理能力?
这就像给一台普通家用电脑装上高性能芯片,让它能跑大型游戏一样——低成本、高性价比,适合学校、中小企业等资源有限的环境。
他们用了什么黑科技?
黑科技1:GRPO算法——强化学习的“瘦身版”
传统强化学习需要额外训练一个“裁判模型”来打分,但GRPO直接用同一批答案互相比较,省掉了复杂步骤。
这就好比考试时不用老师批卷,让学生互评还能保证公平,大大降低了计算成本。
黑科技2:数据筛选的“三步淘汰法”
第一步:用LaTeX公式标记筛选数学题(从5.9万题砍到3.1万)
第二步:用小型模型自动过滤简单题(剩2.1万)
第三步:用大模型剔除低质量题目(最终1.8万题)
整个过程像淘金,留下的全是高纯度“知识金矿”。
三个关键实验
实验1:高质量数据虽好,但训练久了会崩
用1.8万道数学题训练,模型前100步进步神速,AMC竞赛准确率从63%飙到70%。但训练到200步后,成绩不升反降,甚至开始胡言乱语输出乱码。
原因:答案长度被限制在4096字符内,遇到复杂题时“话没说完就被掐断”。
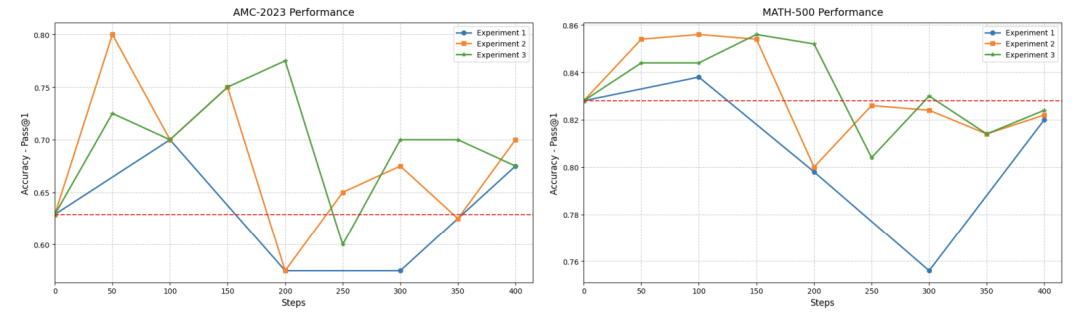
实验2:难题+简单题混搭,效果更稳
团队灵机一动,把难题和简单题按3:3:1的比例混合(共7000题),同时放宽长度限制。结果AMC准确率冲到80%,但训练后期还是会出现多语言混杂的问题。
启示:就像学生刷题,先易后难才能循序渐进。
实验3:用“余弦奖励”控制答案长度
把奖励机制改成“答案越短得分越高”,成功让模型学会言简意赅。虽然成绩略逊于实验2,但输出稳定性大幅提升。
副作用:模型偶尔还是会切换成其他语言,暴露了多语言底层的“基因”。
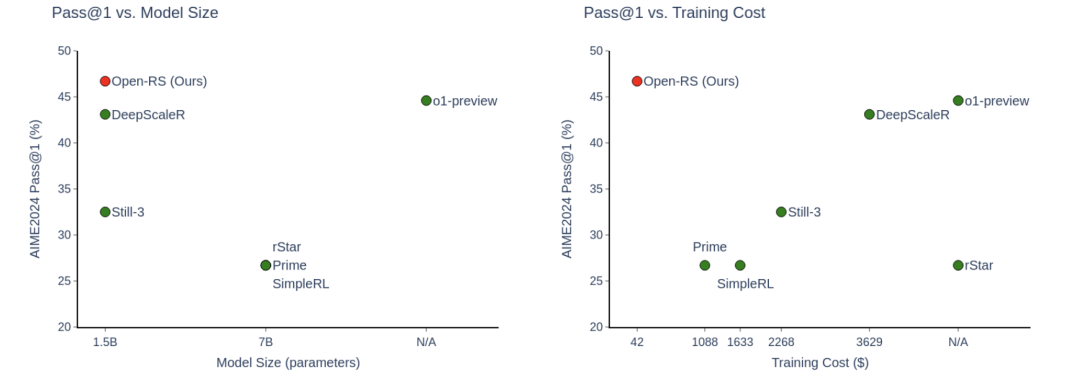
结果有多炸裂?
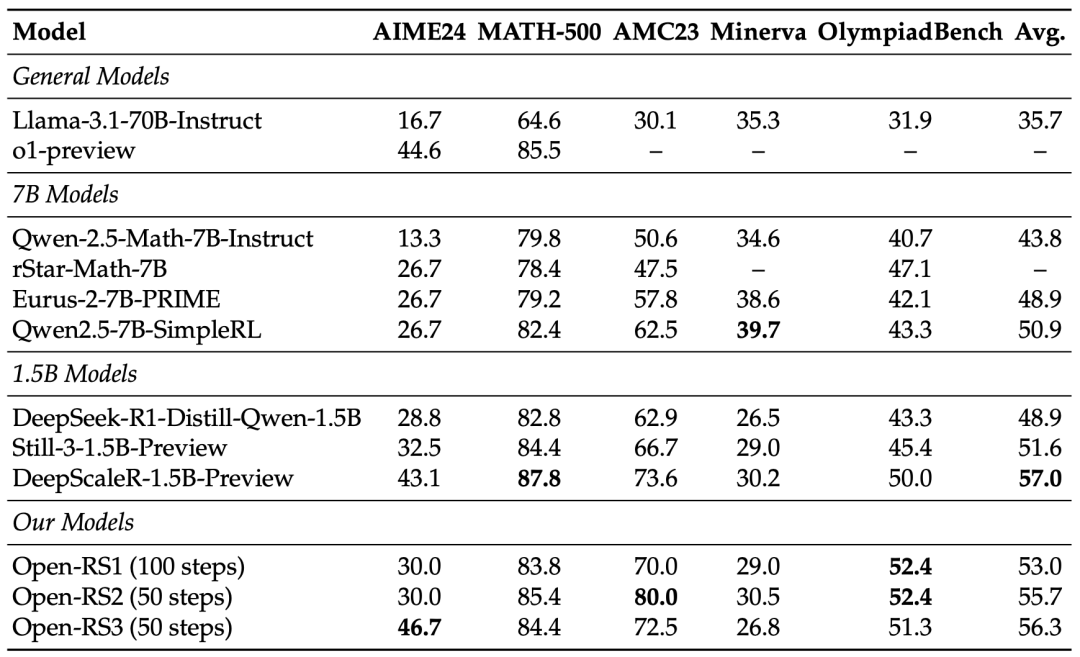
成本仅42美元:用4块显卡训练24小时,比动辄上千美元的7B模型便宜几十倍。
成绩亮眼:在AIME数学竞赛测试中达到46.7%准确率,超过OpenAI的ol-preview(44.6%)。
小模型逆袭:1.5B参数的Open-RS3模型,部分成绩甚至碾压70B参数的Llama-3.1。
局限与未来方向
现存问题:
复杂题目需要更长答案,但模型被长度限制“卡脖子”
多语言切换的“顽疾”暂时无解
未来可期:
动态调整答案长度限制
加入语言约束奖励,让模型“只说人话”
将方法推广到编程、科学推理等领域
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









