






人类处理长文本的历史就是一部效率进化史。300年前的古埃及图书馆员需要手工整理数十万卷莎草纸,唐代天文学家要人工计算海量天文数据,直到今天,学者仍需逐篇阅读上百篇论文才能完成综述。而长上下文语言模型(LCLMs)的出现,让处理托尔斯泰《战争与和平》级别的56万字文本,从60小时人工阅读压缩到几分钟计算。
论文:A Comprehensive Survey on Long Context Language Modeling
链接:https://arxiv.org/pdf/2503.17407
这种能力突破不仅意味着处理速度的提升,更重要的是为AI打开了"单次推理完成复杂思考"的大门。就像人类能在草稿纸上反复演算一样,模型可以在超长上下文中回溯、反思、总结,实现类似人类的长链推理能力。论文中提到的"o1式推理"正是这种能力的集中体现。
长上下文模型的三大核心要素——数据、架构与工作流
要让AI真正理解长文本,需要从三个维度构建技术体系:
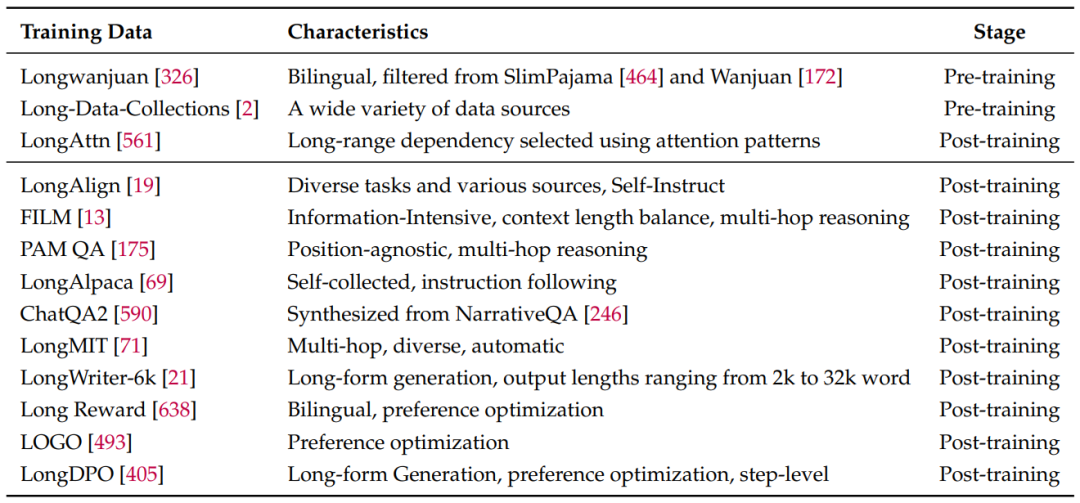
数据配方:如何筛选高质量长文本?论文揭秘了"注意力筛选法"(LongAttn),用模型自身的注意力机制判断文本的长程依赖强度
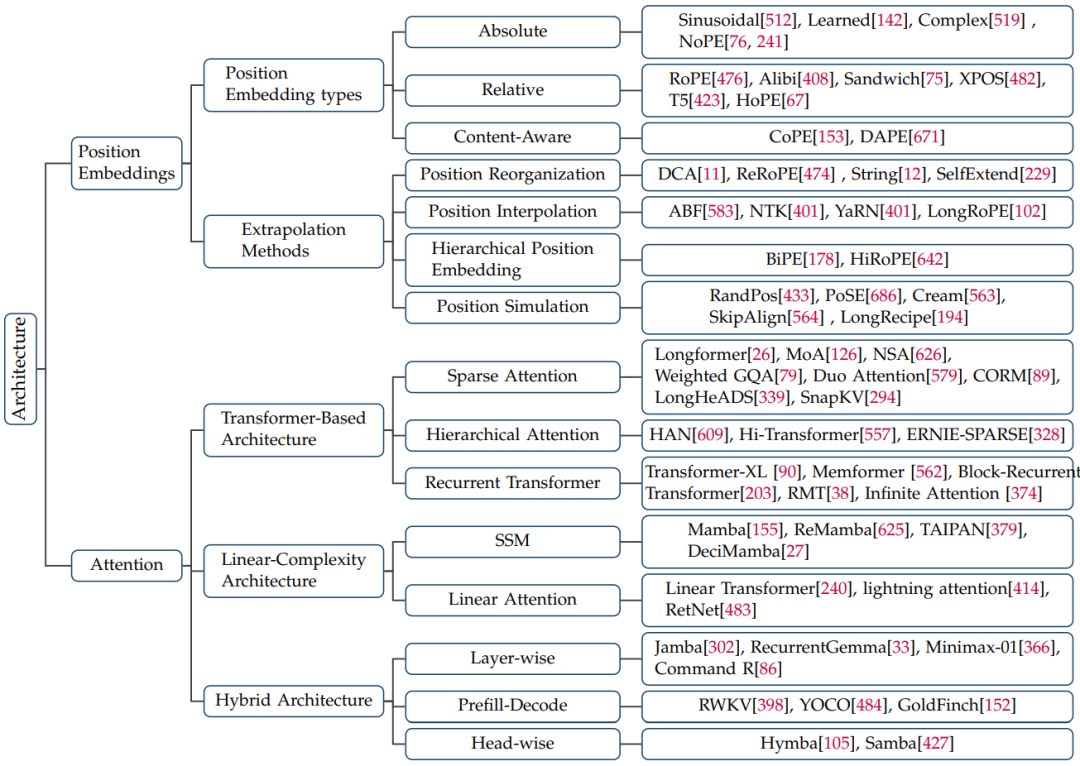
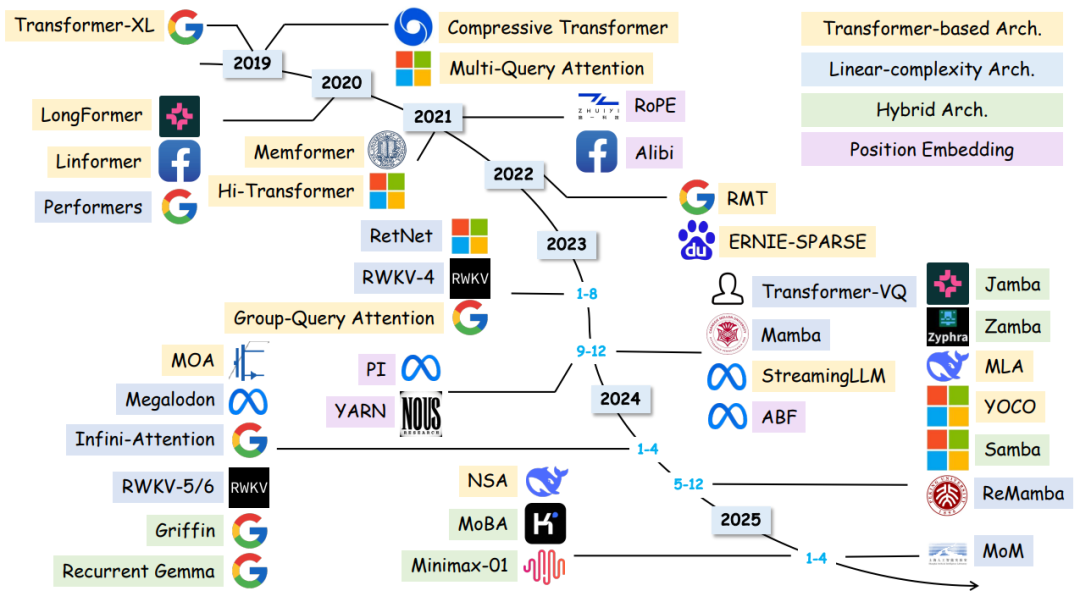
模型架构:Transformer的二次革命正在发生,从经典注意力到Mamba架构,再到混合架构(Hybrid),研究者正在寻找效率与性能的黄金平衡点
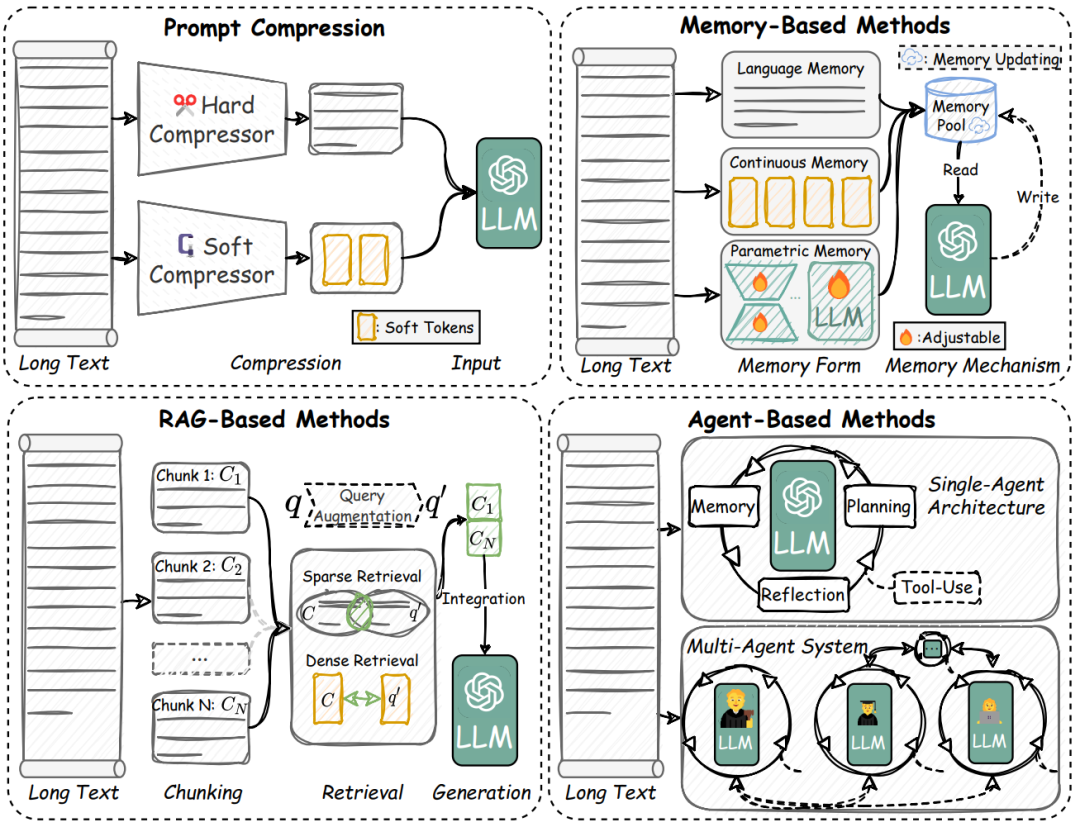
工作流设计:当单模型不够用时,提示压缩、记忆存储、RAG检索、智能体协同四大法宝上场
如何让模型"记得更久"?——位置编码与注意力机制
位置编码是长文本建模的"时空定位系统"。论文对比了绝对位置编码(如RoPE)、相对位置编码(如ALiBi)和动态内容感知编码(如CoPE)的优劣。
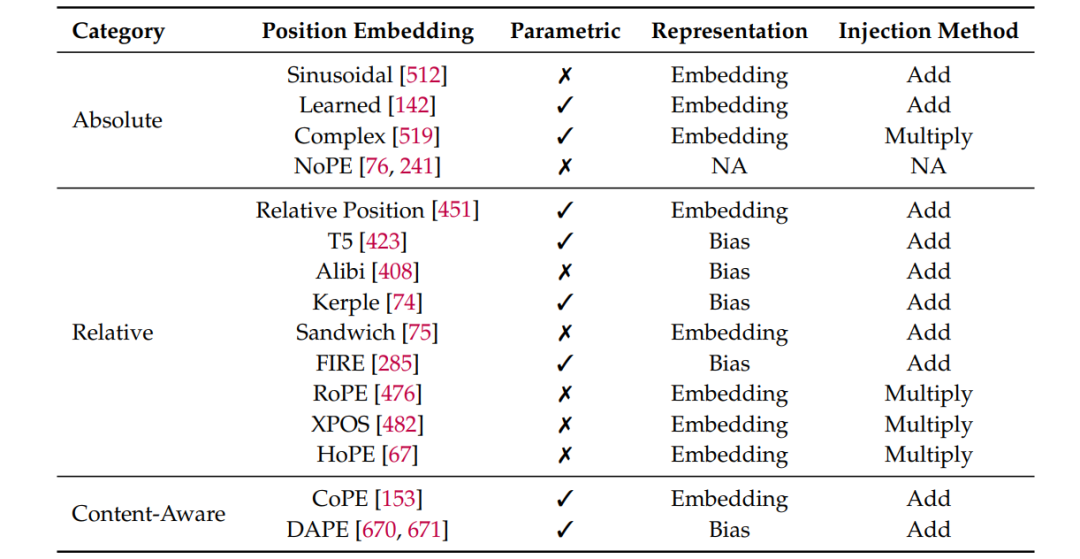
其中最有趣的发现是:通过NTK频率缩放技术,可以让模型自动调节高频/低频信号的接收范围,就像给AI装上可调焦的望远镜。
而注意力机制则面临"越长的文本越容易走神"的难题。研究者开发了动态KV缓存淘汰策略(如H2O),让模型像人类一样,主动遗忘无关信息,聚焦关键内容。
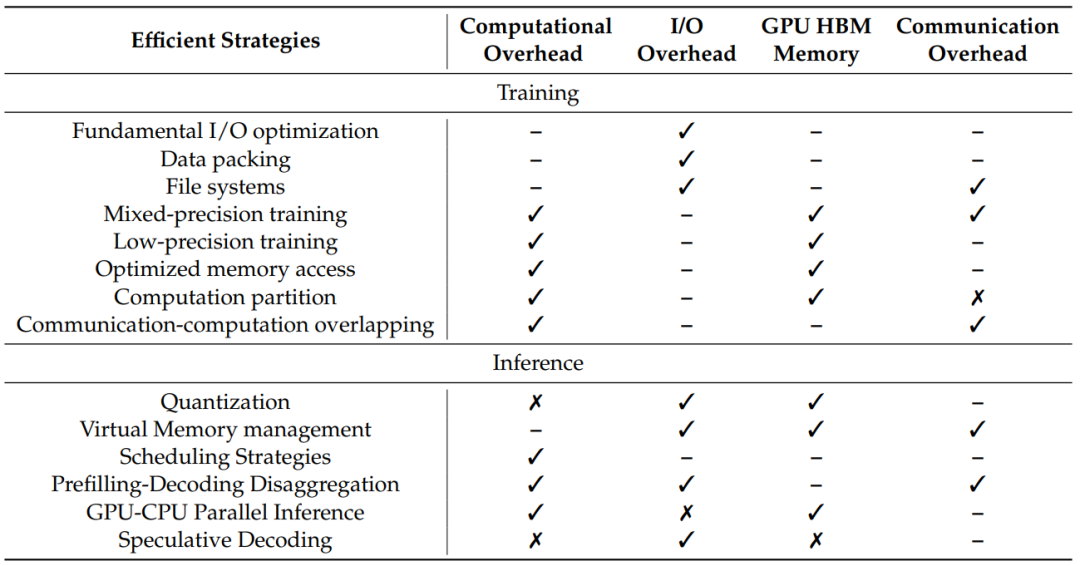
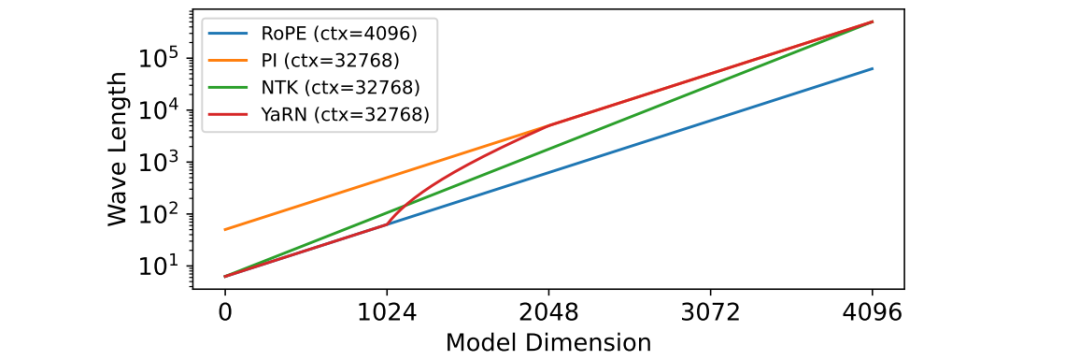
训练与部署工程——从硬件优化到推理加速
训练支持百万token的模型,是算力与智慧的终极博弈:
数据打包黑科技:把不同长度的文本智能拼接,最高可提升3倍训练效率
混合精度训练:在FP8和BF16之间跳舞,既要精度又要速度
推理加速术:预填充-解码分离架构(Prefilling-Decoding)让长文本生成速度提升5倍
最硬核的当属"GPU-CPU并行推理",就像让CPU当GPU的"记忆外挂",把KV缓存存在CPU内存,需要时闪电调用。
模型能力——评估方法与现实应用场景
论文建立了双维度评估体系:
理解力测试:从基础语言建模到复杂推理,设置五级能力阶梯
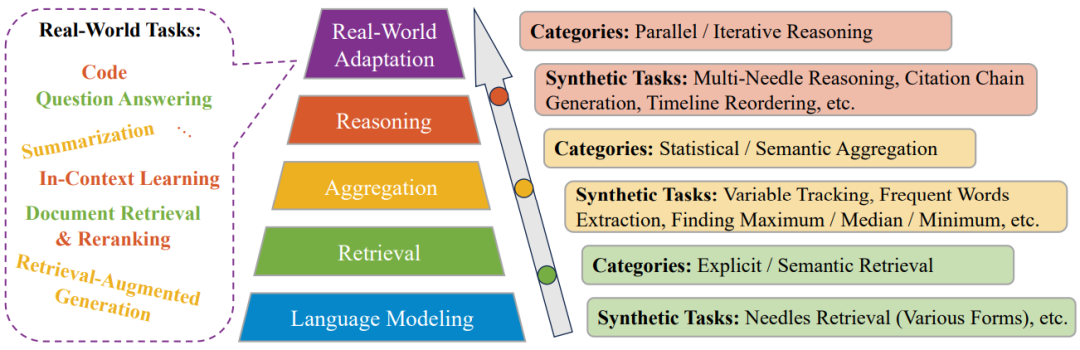
生成力挑战:要求模型输出万字长文,既要连贯又要精准
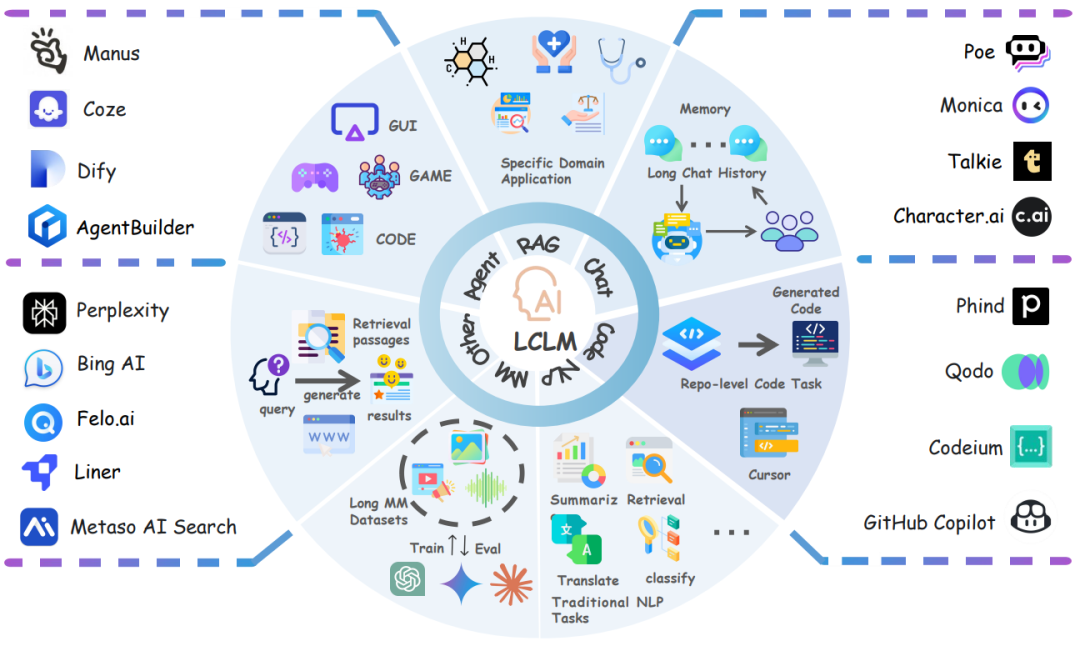
在应用层面,长文本模型正在重塑四大领域:
智能体:支持持续数天的复杂工作流记忆
RAG系统:直接消化整本专业书籍进行问答
代码开发:理解万行级代码仓库
多模态:解析1小时长视频内容
未来五大发展方向与行业变革预言
论文预言了五大突破方向:
超长推理革命:让AI在单次推理中完成百步思考
上下文无限扩展:突破千万token的物理极限
硬件架构重构:为长文本推理定制专用芯片
可信评估体系:终结"虚标上下文长度"的乱象
可解释性突破:打开模型记忆机制的"黑箱"
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









