






奖励模型是什么?模型的「价值观老师」,用分数潜移默化纠正其行为。
想象你训练一只小狗,它做对了就给零食,做错了就纠正。奖励模型(Reward Model, RM) 就是AI世界的「零食发放器」,通过打分告诉模型什么行为是好的(比如诚实、无害、有帮助)。
论文:A Comprehensive Survey of Reward Models: Taxonomy,Applications, Challenges, and Future
链接:https://arxiv.org/pdf/2504.12328
论文提到,大模型(如ChatGPT)虽然强大,但可能输出有害或错误内容。奖励模型的作用就是充当「人类偏好代理人」,用数据训练出一个打分系统,指导向人类期望的方向进化。
奖励模型怎么工作?
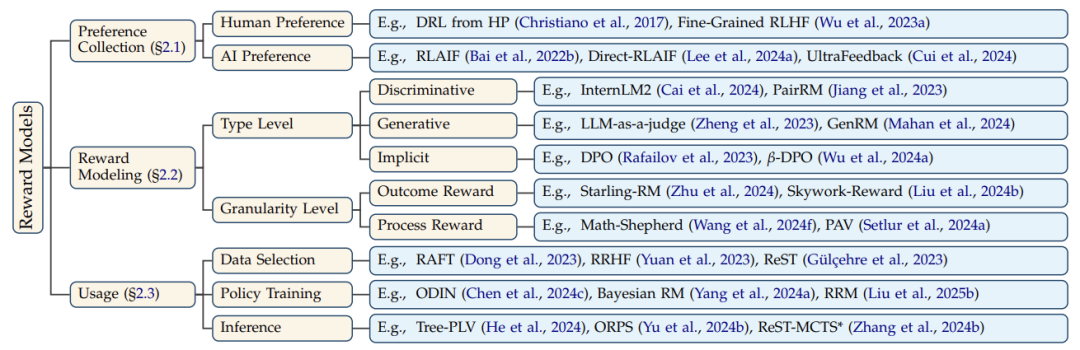 奖励模型的运作分为三步:
奖励模型的运作分为三步:
偏好收集:人类或LLM给不同回答打分(比如标注员判断哪个回复更友好)。
奖励建模:根据打分数据训练模型,让它学会自动评分(类似老师批改作业)。
应用阶段:用训练好的RM指导模型优化(如强化学习)。

比如在聊天场景中,RM会对比两个回答,选择更符合「3H原则」(诚实、无害、有帮助)的一个,帮助模型改进。
奖励模型分类:从「打分老师」到「推理教练」
 论文将RM分为三大类,对应不同任务需求:
论文将RM分为三大类,对应不同任务需求:
判别式奖励模型:直接给回答打总分(适合简单任务)。
公式:
生成式奖励模型:让大模型自己写评价(适合复杂解释)。
隐式奖励模型:不显式打分,通过概率间接优化(节省算力)。
特殊分类:
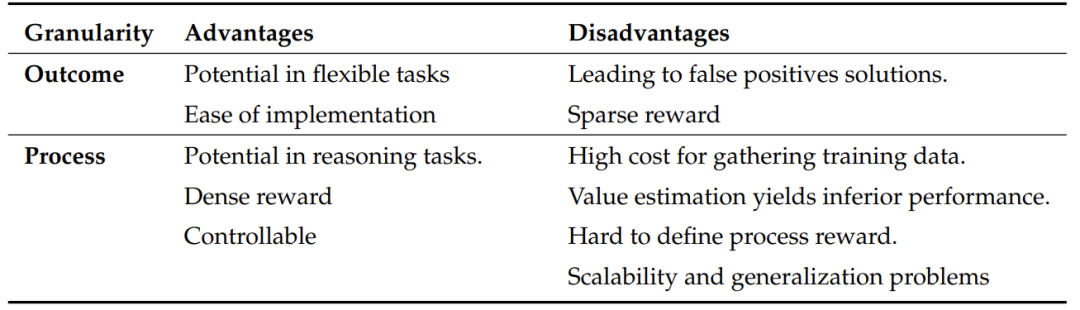
结果级奖励(ORM):只看最终答案对不对。
过程级奖励(PRM):检查解题每一步是否正确(像数学老师批改步骤)。
应用场景
对话:避免说有害内容(如 Anthropic 的Claude)。
数学推理:用PRM检查解题步骤(比如先乘除后加减)。
推荐系统:根据用户偏好生成个性化推荐。
多模态:指导LLM生成更符合审美的图片/视频。
论文提到,RM甚至能用在机器人操作和游戏AI中,堪称「通用智能的基石」。
挑战
数据偏差:标注员水平不一,数据可能带偏见(比如更偏好长回答)。
奖励作弊(Reward Hacking):钻空子刷高分(比如用废话凑字数)。这就像学生通过讨好老师得高分,但实际能力没提升。
评估难:RM本身的好坏很难直接测,得通过最终AI表现反推。
未来方向
多模态奖励:让RM同时处理文本、图像、音频(比如生成带BGM的短视频)。
长任务设计:复杂任务(如写代码)需分段奖励,避免中途跑偏。
规则+模型融合:数学题用规则打分(2+2=4),创意任务用模型打分(哪个故事更有趣)。
论文认为,未来的RM会是「规则明确性」和「模型灵活性」的结合体。
总结
奖励模型是让模型自己来理解人类价值观的核心工具。它不仅是技术问题,更关乎「如何定义好与坏」。论文最后抛出一个哲学问题:当其超越人类专家时,谁来当它的老师?
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









