







Baichuan 2
论文
Baichuan 2: Open Large-scale Language Models
https://arxiv.org/abs/2309.10305
模型结构
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿Tokens 的高质量语料训练。
模型具体参数:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大长 |
|---|---|---|---|---|---|---|
| Baichuan 2-7B | 4,096 | 32 | 32 | 125,696 | RoPE | 4096 |
| Baichuan 2-13B | 5,120 | 40 | 40 | 125,696 | ALiBi | 4096 |

算法原理
Baichuan整体模型基于标准的Transformer结构,采用了和LLaMA一样的模型设计。其中,Baichuan-7B在结构上采用Rotary Embedding位置编码方案、SwiGLU激活函数、基于RMSNorm的Pre-Normalization。Baichuan-13B使用了ALiBi线性偏置技术,相对于Rotary Embedding计算量更小,对推理性能有显著提升。

环境配置
Docker(方式一)
推荐使用docker方式运行,提供拉取的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py38-latest
docker run -dit --network=host --name=baichuan2 --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py38-latest
docker exec -it baichuan2 /bin/bash
安装docker中没有的依赖:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
Dockerfile(方式二)
docker build -t baichuan2:latest .
docker run -dit --network=host --name=baichuan2 --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 baichuan2:latest
docker exec -it baichuan2 /bin/bash
Conda(方式三)
- 创建conda虚拟环境:
conda create -n baichuan2 python=3.8
- 关于本项目DCU显卡所需的工具包、深度学习库等均可从光合开发者社区下载安装。
-
Tips:以上dtk驱动、python、deepspeed等工具版本需要严格一一对应。
- 其它依赖库参照requirements.txt安装:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
注意 1
#到虚拟环境下对应的python/site-packages注释掉一些版本判断
site-packages/accelerate/accelerator.py 文件
287 #if not is_deepspeed_available():
288 # raise ImportError("DeepSpeed is not installed => run `pip install deepspeed` or build it from source.")
289 #if compare_versions("deepspeed", "<", "0.9.3"):
290 # raise ImportError("DeepSpeed version must be >= 0.9.3. Please update DeepSpeed.")
site-packages/transformers/utils/versions.py 文件
43 #if not ops[op](version.parse(got_ver), version.parse(want_ver)):
44 # raise ImportError(
45 # f"{requirement} is required for a normal functioning of this module, but found {pkg}=={got_ver}.{hint}"
46 # )
注意 2
训练前请参考modeling_baichuan.py修改模型文件夹中modeling_baichuan.py的Attention类的代码,主要(暂时)去除去torch2.X的依赖。
注意3
若不支持xformers,在多节点训练中可能会出现xformers相关报错:"ImportError: This modeling file reguires the following packages that were not found in your environment: xformers." ,您可通过直接将modeling_baichuan.py中xpos设置为None来解决,即注释import xformers相关代码,并设置xops=None。
数据集
输入数据为放置在项目fine-tune/data目录下的 json 文件,fine-tune/data/belle_chat_ramdon_10k.json,该样例数据是从 multiturn_chat_0.8M 采样出 1 万条,并且做了格式转换。主要是展示多轮数据怎么训练,不保证效果。json 文件示例格式如下:
[
{
"id": "77771",
"conversations": [
{
"from": "human",
"value": "写一篇关于气候变化对海洋生态的影响的文章。\n"
},
{
"from": "gpt",
"value": "好的,以下是你要求的文章:\n气候变化对海洋生态的影响\n气候变化对海洋生态产生了广泛的影响。全球变暖导致海洋温度上升,这可能会对许多水生生物的生存、繁殖和迁移造成巨大的影响。另外,海洋酸化也是一个问题,因为大气中二氧化碳的增加导致海水中的pH值下降,使得许多生物的外骨骼变得脆弱,从而影响它们的生存和繁殖。\n此外,气候变化还会引起海平面上升,这不仅对海岸线和沿海居民产生影响,还会对许多海洋生物的栖息地造成影响。一些岛屿上的陆地生物面临几乎完全消失的风险,而另一些生物范围则会扩大到更广泛的领域,这可能会导致新的竞争和生态平衡的改变。\n总之,气候变化并不只是一个地球气温的问题,它对海洋生态系统产生了广泛和深远的影响。\n"
},
{
"from": "human",
"value": "从刚刚的文章中提取出气候变化对海洋生物繁殖的影响。\n"
},
{
"from": "gpt",
"value": "文章已经提到过气候变化会对海洋生物的生存、繁殖和迁移造成影响。例如,海洋酸化会使得许多生物的外骨骼变得脆弱,进而影响它们的生存和繁殖。此外,海洋温度上升也可能会对很多生物的生存和繁殖产生负面影响。"
}
]
}
....
]
模型下载
Hugging Face模型下载地址:
训练
全参数微调训练
- 单机训练
cd fine-tune
bash ft_train.sh
- 多机训练
cd fine-tune/multi_node
进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改run-13b-sft.sh中--mca btl_tcp_if_include enp97s0f1,enp97s0f1改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定,微调命令:
bash run_ft.sh
LoRA微调训练
- 单机训练
cd fine-tune
bash lora_train.sh
- 多机训练
cd fine-tune/multi_node
进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改run-13b-sft.sh中--mca btl_tcp_if_include enp97s0f1,enp97s0f1改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定,微调命令:
bash run_lora.sh
推理
命令行测试
python cli_demo.py
请根据情况修改其中的模型加载路径。
注:以上脚本用于全参数模型推理,不适用于直接加载lora微调后的模型。
Result
- 以下为我们基于baichuan2-7b-base模型进行全参数指令微调实验后的推理效果:

精度
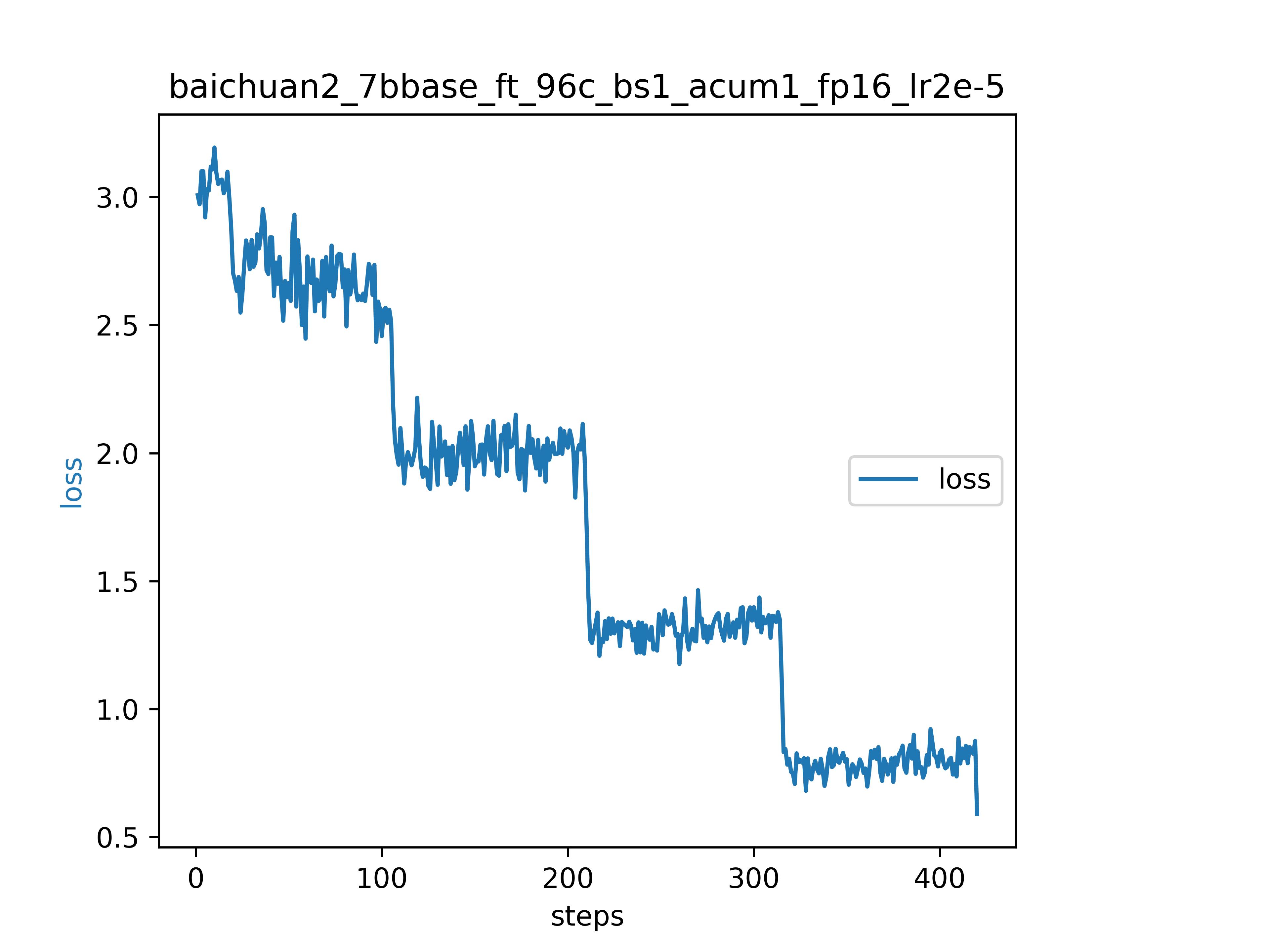
- 以下为我们基于baichuan2-7b-base模型进行全参数指令微调实验的loss收敛情况:
应用场景
算法类别
对话问答
热点应用行业
医疗,教育,科研,金融
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











