







Mobilenetv3_pytorch
论文
Searching for MobileNetV3
模型结构
MobileNetv3模型采用轻量级的深度可分离卷积(depthwise separable convolution)结构,以减少模型参数量和计算复杂度。
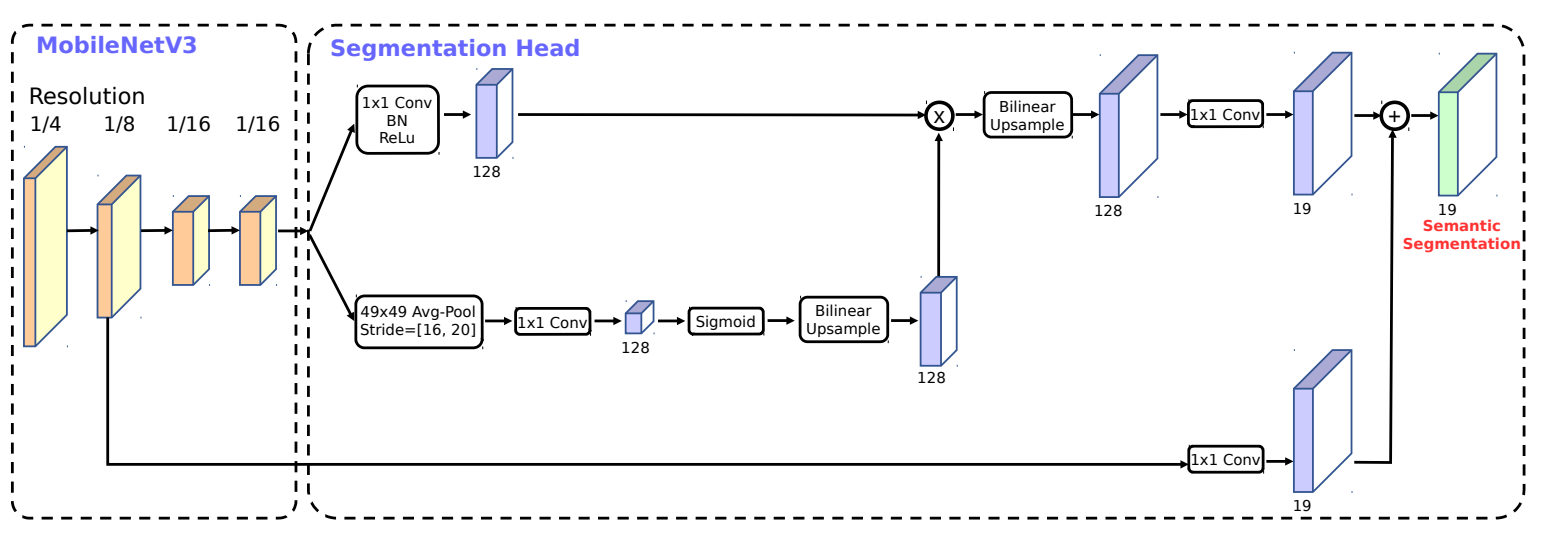
算法原理
MobileNetv3模型采用混合使用轻量级深度可分离卷积和逆残差结构(Inverted Residuals)的算法原理,以实现高效计算和良好的模型性能。
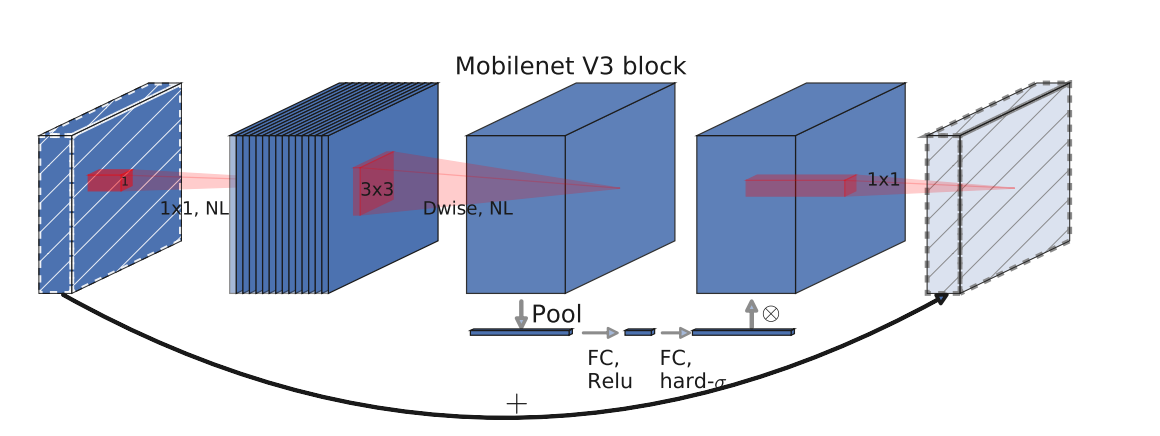
环境配置
Docker(方法一)
此处提供光源拉取docker镜像的地址与使用步骤
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10-py38-latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
Dockerfile(方法二)
此处提供dockerfile的使用方法
cd ./docker
docker build --no-cache -t mobilenetv3:1.0 .
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装。
DTK驱动:dtk22.10
python:python3.8
torch:1.10
torchvision:0.10
Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应 另外需要安装如下三方库
pip install scipy
数据集
cifar10
├── cifar-10-batches-py
│ ├── batches.meta
│ ├── data_batch_1
│ ├── data_batch_2
│ ├── data_batch_3
│ ├── data_batch_4
│ ├── data_batch_5
│ ├── readme.html
│ └── test_batch
数据预处理
无
训练
单机多卡
bash train.sh
result

精度
测试数据:cifar10,使用的加速卡:Z100L。
根据测试结果情况填写表格:
| 卡数 | 准确率 |
|---|---|
| 4 | 91.44% |
应用场景
算法类别
目标检测
热点应用行业
交通,政府,金融
















 4394
4394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











