







LLAMA
论文
模型结构
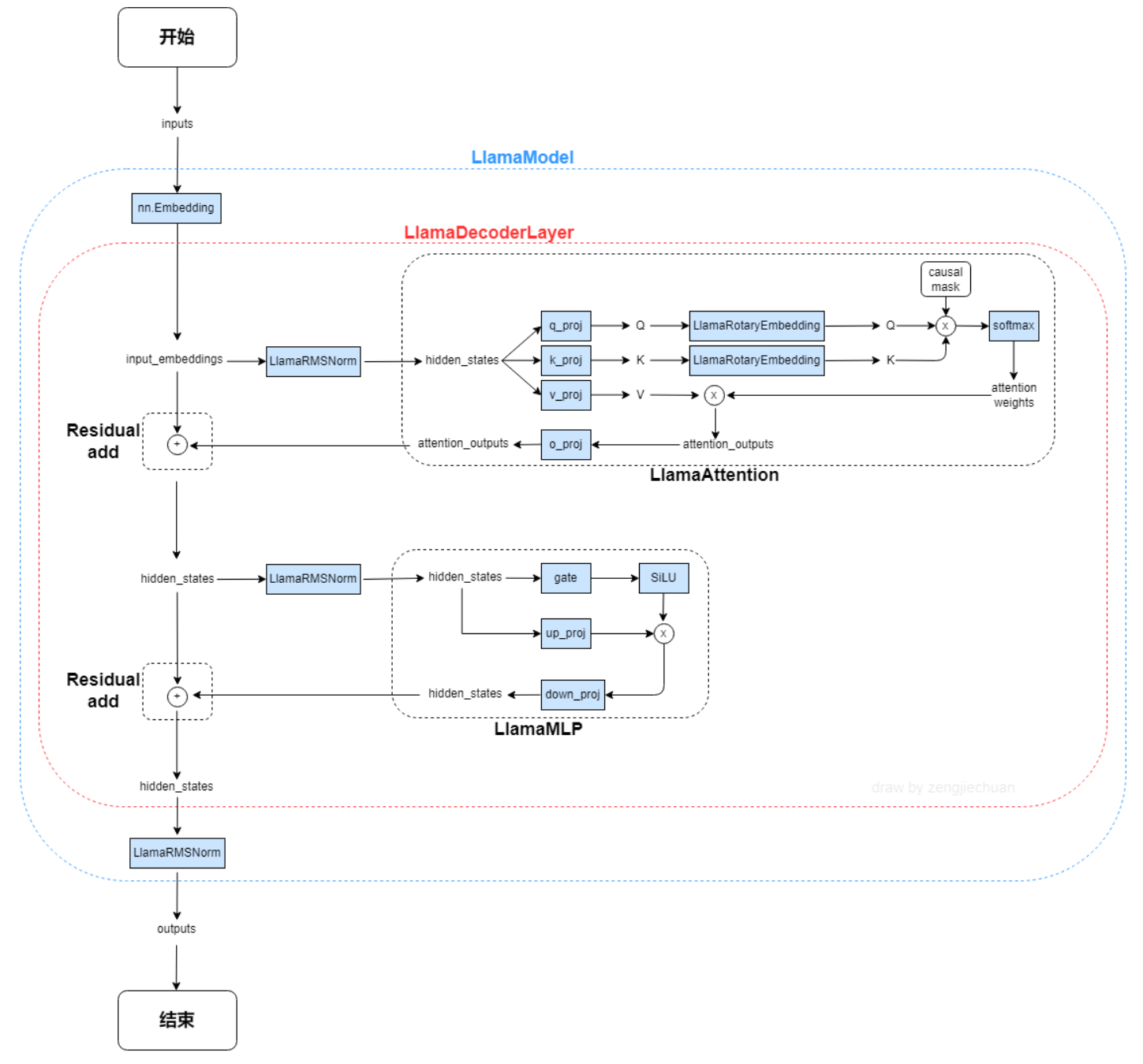
LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。以下是与原始架构的主要区别: 预归一化。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。 SwiGLU 激活函数 [PaLM]。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。 旋转嵌入。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
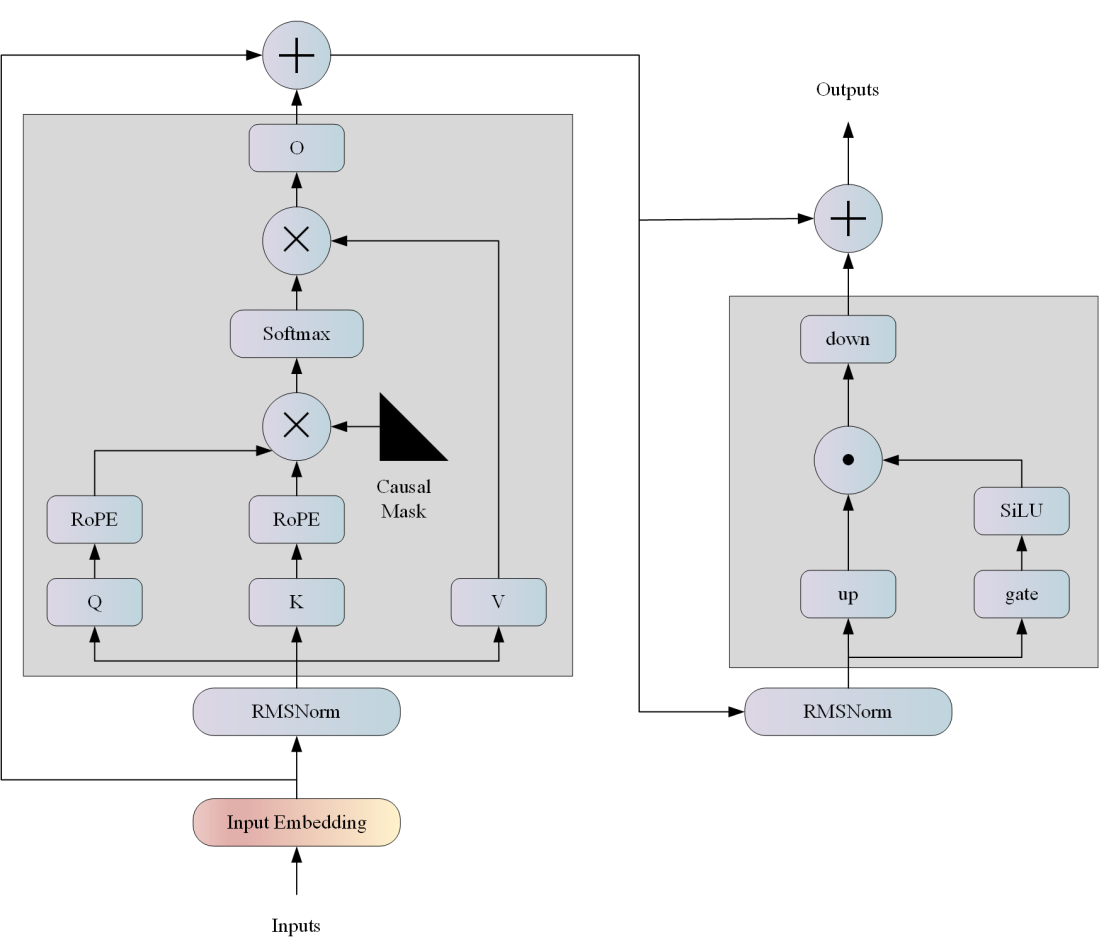
算法原理
LLama是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。
环境配置
提供光源拉取推理的docker镜像:
docker pull docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:fastertransformer-dtk23.04-latest
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name llama --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
镜像版本依赖:
- DTK驱动:dtk23.04
- Pytorch: 1.10
- python: python3.8
激活镜像环境: source /opt/dtk-23.04/env.sh
数据集
无
推理
编译
mkdir build
cd build
cmake -DSM=70 -DCMAKE_BUILD_TYPE=Release -DBUILD_MULTI_GPU=ON -DCMAKE_CXX_COMPILER=nvcc ..
make -j12
模型下载
模型转换
python ../examples/cpp/llama/huggingface_llama_convert.py \
-saved_dir=/data/models/llama-7b-infer/ \
-in_file=/data/models/llama-7b-hf/ \
-infer_gpu_num=1 -weight_data_type=fp16 -model_name=llama_7b
例如llama-7b的转换:-in_file为模型输入路径,-saved_dir为模型输出路径,-infer_gpu_num为推理的tp大小,-weight_data_type为推理的数据类型,-model_name为模型名称.若使用其他模型,对应修改路径和-model_name.
运行 LLama-7b
- 生成
gemm_config.in文件
data_type = 0 (FP32) or 1 (FP16)
./bin/gpt_gemm 1 1 20 32 128 11008 32000 1 1
上述参数对应为
./bin/gpt_gemm <batch_size> <beam_width> <max_input_len> <head_number> <size_per_head> <inter_size> <vocab_size> <data_type> <tensor_para_size>
- 配置
../examples/cpp/llama/llama_config.ini
data_type = 1时,data_type = fp16;data_type = 0时,data_type = fp32,tensor_para_size和模型转换设置的tp数保持一致,model_name=llama_7B,model_dir为对应的模型权重,request_batch_size为推理的batch_size数量,request_output_len为输出长度,../examples/cpp/llama/start_ids.csv可以修改输入的起始id.
- 运行
./bin/llama_example
该程序会读取../examples/cpp/llama//start_ids.csv中的id作为输入tokens,生成的结果会保存在.out.
运行 LLama-13b
./bin/gpt_gemm 1 1 20 40 128 13824 32000 1 1
./bin/llama_example
运行 LLama-33b
./bin/gpt_gemm 1 1 20 52 128 17920 32000 1 2
mpirun --allow-run-as-root -np 2 ./bin/llama_example
运行 LLama-65b
./bin/gpt_gemm 1 1 20 64 128 22016 32000 1 8
mpirun --allow-run-as-root -np 8 ./bin/llama_example
参数配置说明
llama-33b模型,使用fp16推理需要2张卡(32G),llama-65b模型,使用fp16推理需要8张卡(32G). 从huggingface下载llama模型,可以查看config.json文件,如下左边为fastertransformer参数,后边对应config.son文件中的参数值.
head_num=num_attention_heads
size_per_head=hidden_size / num_attention_heads
inter_size=intermediate_size
num_layer=num_hidden_layers
rotary_embedding=size_per_head
layernorm_eps=rms_norm_eps
vocab_size=vocab_size
result
build/
out
执行一下命令可以解析out结果:
pip install sentencepiece
python ../examples/cpp/llama/llama_tokenizer.py
其中,`tokenizer`为原模型路径
测试数据:"I believe the meaning of life is" (token id: 306, 4658, 278, 6593, 310, 2834, 338),使用的加速卡:1张 DCU-Z100L-32G
| 数据类型 | batch size | temperate | input len | output len |
|---|---|---|---|---|
| fp16 | 1 | 0 | 7 | 256 |
结果如下:
306 4658 278 6593 310 2834 338 304 5735 372 304 278 2989 342 29889 306 4658 393 591 526 599 1244 363 263 2769 322 393 591 526 599 1244 304 1371 1269 916 29889 306 4658 393 591 526 599 1244 304 5110 322 6548 322 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244 304 1371 1269 916 5110 322 6548 29889 306 4658 393 591 526 599 1244
输出内容如下:
I believe the meaning of life is to live it to the fullest. I believe that we are all here for a reason and that we are all here to help each other. I believe that we are all here to learn and grow and that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here to help each other learn and grow. I believe that we are all here
精度
无
应用场景
算法类别
对话问答
热点应用行业
金融,科研,教育
















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











