








python进阶教程
机器学习
深度学习
长按二维码关注
进入正文

上采样、反卷积、上池化概念区别
通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。通过对一些资料的学习,简单的整理下三种恢复方法,并进行对比。
目录
一 Upsampling(上采样)
二 上池化
三 反卷积
四 一些反卷积的论文截图
01
Upsampling(上采样)
在FCN、U-net等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。
02
上池化
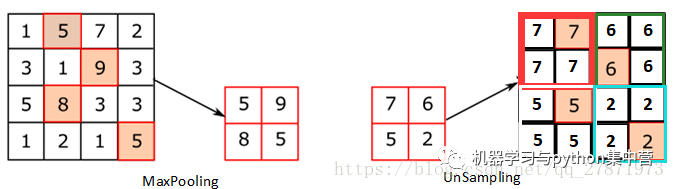
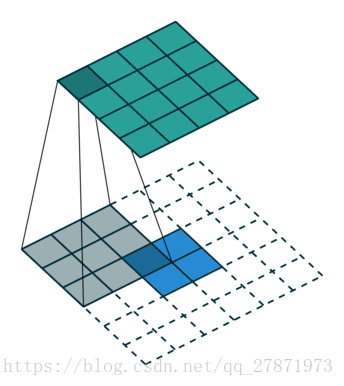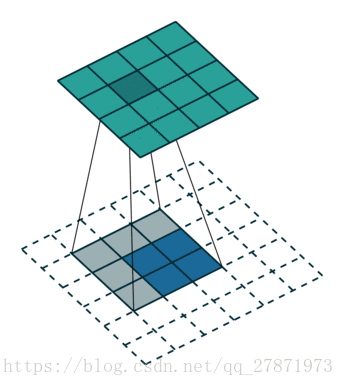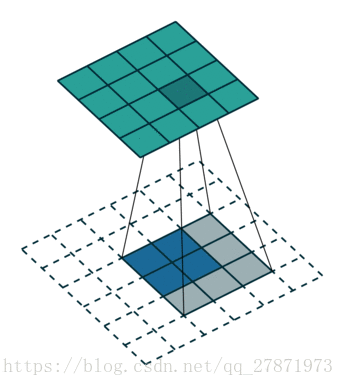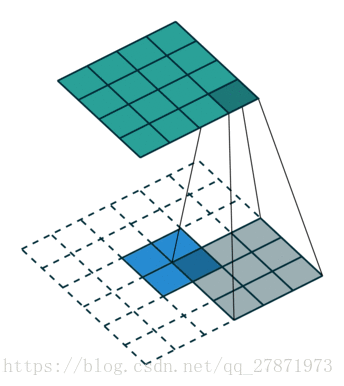
Unpooling是在CNN中常用的来表示max pooling的逆操作。这是论文《Visualizing and Understanding Convolutional Networks》中产生的思想,下图示意:
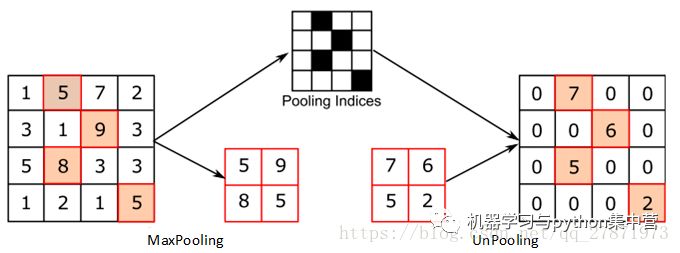
对比上面两个示意图,可以发现区别:
●两者的区别在于UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。第一幅图中右边4*4矩阵,用了四种颜色的正方形框分割为四个区域,每一个区域内的内容是直接复制上采样前的对应信息。
●UnPooling的过程,特点是在Maxpooling的时候保留最大值的位置信息,之后在unPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。从图中即可看到两者结果的不同。
03
反卷积
在介绍反卷积之前,我们需要深入了解一下卷积,一个简单的卷积层运算,卷积参数为i=4,k=3,s=1,p=0.
意图如下: 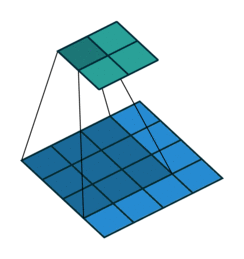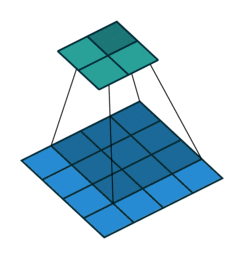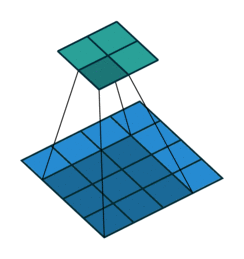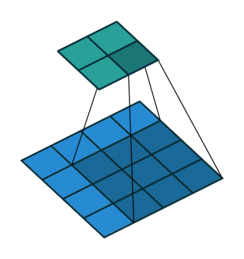
对于上述卷积运算,我们把上图所示的3×3卷积核展成一个如下所示的[4,16]的稀疏矩阵C,如下:

■我们再把4×4的输入特征展成[16,1]的矩阵 ,那么 则是一个[4,1]的输出特征矩阵,把它重新排列2×2的输出特征就得到最终的结果,从上述分析可以看出卷积层的计算其实是可以转化成矩阵相乘的。值得注意的是,在一些深度学习网络的开源框架中并不是通过这种这个转换方法来计算卷积的,因为这个转换会存在很多无用的0乘操作。
■通过上述的分析,我们已经知道卷积层的前向操作可以表示为和矩阵相乘,很容易得到卷积层的反向传播就是和的转置相乘。
■我们已经说过反卷积又被称为Transposed(转置) Convolution,我们可以看出其实卷积层的前向传播过程就是反卷积层的反向传播过程,卷积层的反向传播过程就是反卷积层的前向传播过程。因为卷积层的前向反向计算分别为乘 C和 ,而反卷积层的前向反向计算分别为乘 和 ,所以它们的前向传播和反向传播刚好交换过来。
下图表示一个和上图卷积计算对应的反卷积操作,其中他们的输入输出关系正好相反。如果不考虑通道以卷积运算的反向运算来计算反卷积运算的话,还可以通过离散卷积的方法来求反卷积。通过详细参考资料[1]。
03
一些反卷积的论文截图
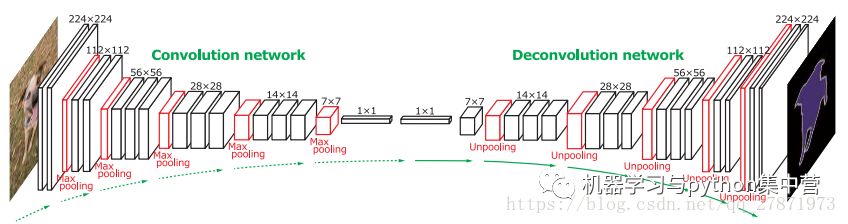
上图为反卷积和全卷积网络为核心的语义分割网络。
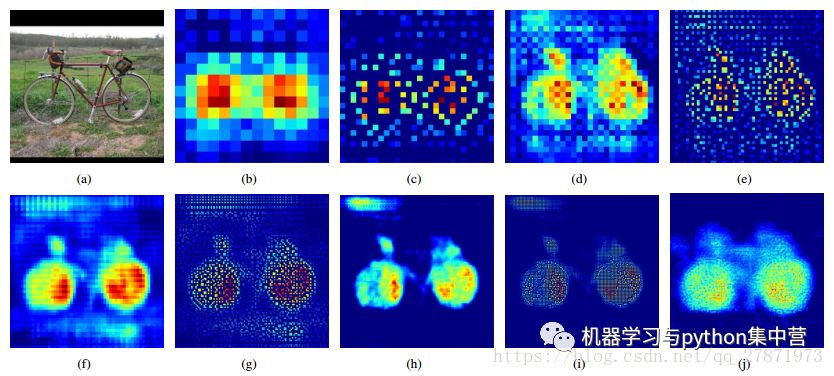
图(a)是输入层;图b、d、f、h、j是不同featrue map大小的反卷积的结果;图c、e、g、i是不同featrue map大小的UnPooling结果。
参考
[1] https://buptldy.github.io/2016/10/29/2016-10-29-deconv/
[2]论文:Learning Deconvolution Network for Semantic Segmentation
推 荐 阅 读

赶紧关注我们吧
您的点赞和分享是我们进步的动力!
↘↘↘















 8003
8003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









