






Stochastic Process
a stochastic process is a collection of random variable indexed by some variable
x
∈
X
x \in \mathcal{X}
x∈X.
f
=
{
f
(
x
)
:
x
∈
X
}
f = \begin{Bmatrix} f(x):x \in \mathcal{X} \end{Bmatrix}
f={f(x):x∈X}
f
f
f can be thought of as a function of location
x
x
x.
f
f
f is an infinite dimensional process. However, thankfully we only need consider the finite dimensional distributions (FDDs), i.e., for all
x
1
,
.
.
.
x
n
x_1, . . . x_n
x1,...xn and for all
n
∈
N
n ∈ N
n∈N
P
(
f
(
x
1
)
≤
y
1
,
.
.
.
,
f
(
x
n
)
≤
y
n
)
P(f (x_1) ≤ y_1, . . . , f (x_n) ≤ y_n)
P(f(x1)≤y1,...,f(xn)≤yn)
as these uniquely determine the law of
f
f
f .
A Gaussian process is a stochastic process with Gaussian FDDs, i.e.
(
f
(
x
1
)
.
.
.
f
(
x
n
)
)
∼
N
(
μ
,
Σ
)
(f(x_1)...f(x_n))\sim \mathcal{N}(\mu,\varSigma)
(f(x1)...f(xn))∼N(μ,Σ)
Import properties
- Property 1:
x
∼
N
(
μ
,
Σ
)
x \sim \mathcal{N}(\mu,\varSigma)
x∼N(μ,Σ) if and only if
A
X
∼
N
p
(
A
μ
,
A
Σ
A
T
)
AX \sim \mathcal{N_p}(A\mu,A\varSigma A^T)
AX∼Np(Aμ,AΣAT)
So, sum of Gaussian is Gaussian (taking A A A as ones vector), and marginal distributions of multivariate are still Gaussian. (taking A A A is a vector with [0 0 0 1]) - Property 2: Conditional distributions are still Gaussian.
Suppose:
X
=
(
X
1
X
2
)
∼
N
(
μ
,
Σ
)
X = \begin{pmatrix} X_1 \\ X_2 \end{pmatrix} \sim \mathcal{N}(\mu,\varSigma)
X=(X1X2)∼N(μ,Σ)
where,
μ
=
(
μ
1
μ
2
)
\mu = \begin{pmatrix} \mu_1\\ \mu_2 \end{pmatrix}
μ=(μ1μ2)
Σ = ( Σ 11 Σ 12 Σ 21 Σ 22 ) \varSigma =\begin{pmatrix} \varSigma_{11} &\varSigma_{12} \\ \varSigma_{21} &\varSigma_{22} \end{pmatrix} Σ=(Σ11Σ21Σ12Σ22)
Then when we only observe only the part of the result, here
X
1
X_1
X1:
(
X
2
∣
X
1
=
x
1
)
∼
N
(
μ
2
+
Σ
21
Σ
11
−
1
(
x
1
−
μ
1
)
,
Σ
22
−
Σ
21
Σ
11
−
1
Σ
12
)
(X_2|X_1 = x_1 )\sim \mathcal{N}(\mu_2 + \varSigma_{21}\varSigma_{11}^{-1}(x_1 - \mu_1),\varSigma_{22}-\varSigma_{21}\varSigma_{11}^{-1}\varSigma_{12})
(X2∣X1=x1)∼N(μ2+Σ21Σ11−1(x1−μ1),Σ22−Σ21Σ11−1Σ12)
π ( x 2 ∣ x 1 ) = π ( x 1 , x 2 ) π ( x 1 ) ∝ π ( x 1 , x 2 ) ∝ exp ( − 1 2 ( x − μ ) ⊤ Σ − 1 ( x − μ ) ) ∝ exp ( − 1 2 [ ( x 2 − μ 2 ) ⊤ Q 22 ( x 2 − μ 2 ) + 2 ( x 2 − μ 2 ) ⊤ Q 21 ( x 1 − μ 1 ) ] ) ∝ exp ( − 1 2 [ ( x 2 − μ 2 ) ⊤ Q 22 ( x 2 − μ 2 ) + 2 ( x 2 − μ 2 ) ⊤ Q 21 ( x 1 − μ 1 ) ] ) So X 2 ∣ X 1 = x 1 is Gaussian. \begin{aligned} \pi\left(x_{2} | x_{1}\right) &=\frac{\pi\left(x_{1}, x_{2}\right)}{\pi\left(x_{1}\right)} \propto \pi\left(x_{1}, x_{2}\right) \\ & \propto \exp \left(-\frac{1}{2}(x-\mu)^{\top} \Sigma^{-1}(x-\mu)\right) \\ & \propto \exp \left(-\frac{1}{2}\left[\left(x_{2}-\mu_{2}\right)^{\top} Q_{22}\left(x_{2}-\mu_{2}\right)+2\left(x_{2}-\mu_{2}\right)^{\top} Q_{21}\left(x_{1}-\mu_{1}\right)\right]\right) \\ & \propto \exp \left(-\frac{1}{2}\left[\left(x_{2}-\mu_{2}\right)^{\top} Q_{22}\left(x_{2}-\mu_{2}\right)+2\left(x_{2}-\mu_{2}\right)^{\top} Q_{21}\left(x_{1}-\mu_{1}\right)\right]\right) \\ \text { So } X_{2} | X_{1}=x_{1} \text { is Gaussian. } \end{aligned} π(x2∣x1) So X2∣X1=x1 is Gaussian. =π(x1)π(x1,x2)∝π(x1,x2)∝exp(−21(x−μ)⊤Σ−1(x−μ))∝exp(−21[(x2−μ2)⊤Q22(x2−μ2)+2(x2−μ2)⊤Q21(x1−μ1)])∝exp(−21[(x2−μ2)⊤Q22(x2−μ2)+2(x2−μ2)⊤Q21(x1−μ1)])
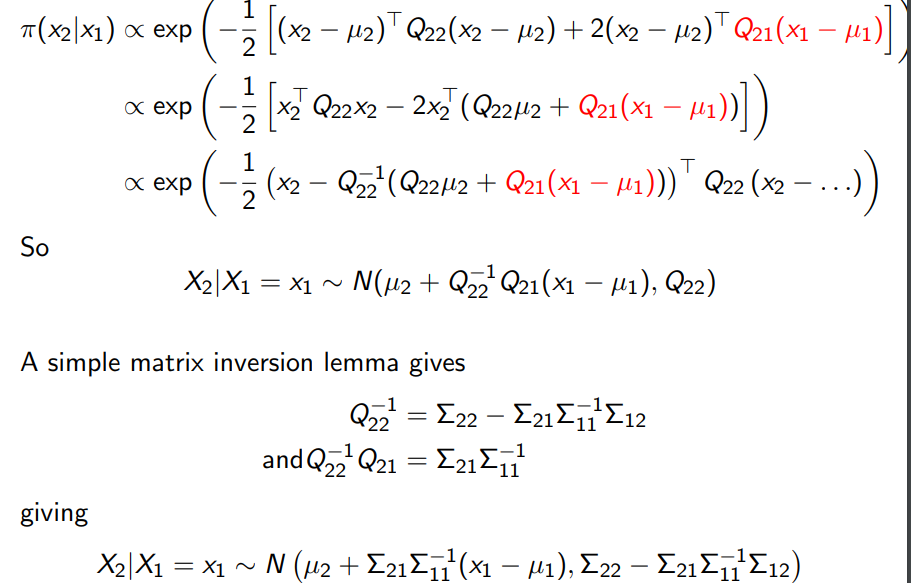
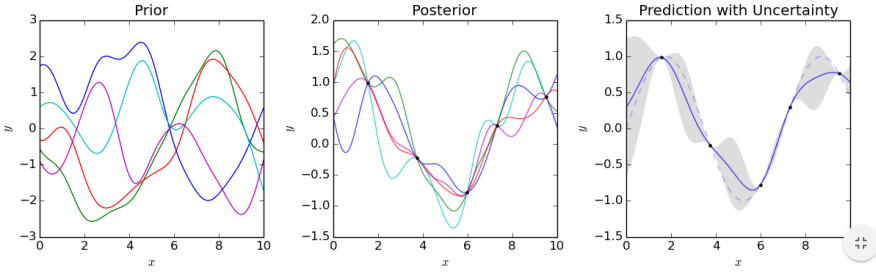
Conditional Update of GP
So suppose
f
f
f is a Gaussian Process, then,
f
(
x
1
)
,
f
(
x
2
)
.
.
.
f
(
x
n
)
,
f
(
x
)
∼
N
(
μ
,
Σ
)
f(x_1),f(x_2)...f(x_n),f(x) \sim \mathcal{N}(\mu,\varSigma)
f(x1),f(x2)...f(xn),f(x)∼N(μ,Σ)
if we observe its value at
x
1
,
.
.
.
,
x
n
x_1,...,x_n
x1,...,xn, then
f
(
x
)
∣
f
(
x
1
)
.
.
.
f
(
x
n
)
∼
N
(
μ
∗
,
σ
∗
)
f(x)|f(x_1)...f(x_n) \sim \mathcal{N}(\mu^*,\sigma^*)
f(x)∣f(x1)...f(xn)∼N(μ∗,σ∗)
Why we use GP
- The GP class of models is closed under various operations.
- non-parametric/kernel regression
- Naturalness of GP Framework
- Uncertainty estimates from emulators
Why GPs: Closed under various operations
- Closed under addition
f 1 ( ⋅ ) , f 2 ( ⋅ ) ∼ G P f1(·), f2(·) ∼ GP f1(⋅),f2(⋅)∼GP then ( f 1 + f 2 ) ( ⋅ ) ∼ G P (f1 + f2)(·) ∼ GP (f1+f2)(⋅)∼GP - Closed under Bayesian conditioning, i.e., if we observe
D = ( f ( x 1 ) , . . . , f ( x n ) ) D = (f (x1), . . . , f (xn)) D=(f(x1),...,f(xn))
then
( f ∣ D ) ∼ G P (f|D)\sim GP (f∣D)∼GP - Closed under any linear operation. If
f
∼
G
P
(
m
(
⋅
)
,
k
(
⋅
,
⋅
)
)
f ∼ GP(m(·), k(·, ·))
f∼GP(m(⋅),k(⋅,⋅)), then if
L
L
L is a linear operator
L ◦ f ∼ G P ( L ◦ m , L 2 ◦ k ) L ◦ f ∼ GP(L ◦ m,L^2◦k) L◦f∼GP(L◦m,L2◦k)
Why GPs: Non-Parametric Regression
Suppose that we are given data
(
x
i
,
y
i
)
i
=
1
n
(x_i,y_i)_{i=1}^{n}
(xi,yi)i=1n
Linear Regression
y
=
x
T
β
+
ϵ
y = x^T\beta + \epsilon
y=xTβ+ϵ
can be written in form of inner products
x
T
x
x^Tx
xTx
β ^ = a r g m i n ∣ ∣ y − X β ∣ ∣ 2 2 + σ 2 ∣ ∣ β ∣ ∣ 2 β ^ = ( X T X + Σ 2 I ) − 1 X T y β ^ = X T ( X X T + σ 2 I ) − 1 y           ( t h e    d u a l    f o r m ) \hat{\beta} = argmin || y - X\beta ||^2_{2} + \sigma^2 ||\beta||^2 \\ \hat{\beta} = (X^TX+\Sigma^2I)^{-1}X^Ty\\ \hat{\beta} =X^T(XX^T+\sigma^2I)^{-1}y \:\; \; \; \; (the\; dual \; form) β^=argmin∣∣y−Xβ∣∣22+σ2∣∣β∣∣2β^=(XTX+Σ2I)−1XTyβ^=XT(XXT+σ2I)−1y(thedualform)
At first, the dual form looks like we’ve made the problem harder:
$$
XX^T ;is ;n*n \
X^TX; is ; p*p
$$
but the dual form makes clear that linear regression only uses inner products.
The best prediction of
y
y
y at a new location
x
′
x^{'}
x′ is:
y
^
=
x
′
T
β
^
y
^
=
x
′
T
X
T
(
X
X
T
+
σ
2
I
)
−
1
y
y
^
=
k
(
x
′
)
(
K
+
σ
2
I
)
−
1
y
\hat{y} = x^{'T} \hat{\beta}\\ \hat{y} = x^{'T}X^T(XX^T+\sigma^2I)^{-1}y\\ \hat{y} = k(x^{'}) (K + \sigma^{2} I)^{-1}y
y^=x′Tβ^y^=x′TXT(XXT+σ2I)−1yy^=k(x′)(K+σ2I)−1y
where,
k
(
x
′
)
:
=
(
x
′
x
1
,
.
.
.
,
x
′
x
n
)
k(x^{'}) :=(x^{'}x_1,...,x^{'}x_n)
k(x′):=(x′x1,...,x′xn)
and
K
i
j
:
=
x
i
T
x
j
K_{ij} := x_i^T x_j
Kij:=xiTxj
these are kernel matrices, every element is the inner product between two rows of training points. And note the similarity to the GP conditional mean we derived before. If:
(
y
1
y
2
)
∼
N
(
0
,
(
Σ
11
Σ
12
Σ
21
Σ
22
)
)
\begin{pmatrix} y_1 \\ y_2 \end{pmatrix} \sim \mathcal{N} \begin{pmatrix} 0, & \begin{pmatrix} \varSigma_{11} &\varSigma_{12} \\ \varSigma_{21} &\varSigma_{22} \end{pmatrix} \end{pmatrix}
(y1y2)∼N(0,(Σ11Σ21Σ12Σ22))
then,
E
(
y
′
∣
y
)
=
Σ
21
Σ
11
−
1
y
E(y^{'}|y) = \varSigma_{21}\varSigma_{11}^{-1}y
E(y′∣y)=Σ21Σ11−1y
where,
Σ
11
=
K
+
σ
2
I
\Sigma_{11}=K+\sigma^{2} I
Σ11=K+σ2I,and
Σ
12
=
Cov
(
y
,
y
′
)
\Sigma_{12}=\operatorname{Cov}\left(y, y^{\prime}\right)
Σ12=Cov(y,y′) then we can see that linear regression and GP regression are equivalent for the kernel/covariance function
k
(
x
,
x
′
)
=
x
⊤
x
′
k\left(x, x^{\prime}\right)=x^{\top} x^{\prime}
k(x,x′)=x⊤x′
And we can replace the x x x by a feature vector in linear regression, e.g. ϕ ( x ) = ( 1    x    x 2 ) \phi(x)= (1 \;x \;x^{2}) ϕ(x)=(1xx2)
Then
K
i
j
=
ϕ
(
X
i
)
T
ϕ
(
X
j
)
K_{ij} = \phi(X_{i})^{T} \phi(X_{j})
Kij=ϕ(Xi)Tϕ(Xj)
Generally, we don’t think about these features, we just choose a kernel. But any kernel is implicitly choosing a set of features, and our model only includes functions that are linear combinations of this set of features (this space is called the Reproducing Kernel Hilbert Space (RKHS) of k).
Although our simulator may not lie in the RKHS defined by k, this space is much richer than any parametric regression model (and can be dense in some sets of continuous bounded functions), and is thus more likely to contain an element close to the true functional form than any class of models that contains only a finite number of features. This is the motivation for non-parametric methods. When we do GP, we are always assuming that the feature vector is in a much rich feature space.
Example
ϕ ( x ) = ( e − ( x − c 1 ) 2 2 λ 2 , … , e − ( x − c N ) 2 2 λ 2 ) \phi(x)=\left(e^{-\frac{\left(x-c_{1}\right)^{2}}{2 \lambda^{2}}}, \ldots, e^{-\frac{\left(x-c_{N}\right)^{2}}{2 \lambda^{2}}}\right) ϕ(x)=(e−2λ2(x−c1)2,…,e−2λ2(x−cN)2)
then as $N \rightarrow \infty $
ϕ
(
x
)
⊤
ϕ
(
x
)
=
exp
(
−
(
x
−
x
′
)
2
2
λ
2
)
\phi(x)^{\top} \phi(x)=\exp \left(-\frac{\left(x-x^{\prime}\right)^{2}}{2 \lambda^{2}}\right)
ϕ(x)⊤ϕ(x)=exp(−2λ2(x−x′)2)
Why GPs: Naturalness of GP framework
It has been shown, using coherency arguments, or geometric arguments, or…, that the best second-order inference we can do to update our beliefs about X given Y is
E
(
X
∣
Y
)
=
E
(
X
)
+
Cov
(
X
,
Y
)
Var
(
Y
)
−
1
(
Y
−
E
(
Y
)
)
\mathbb{E}(X | Y)=\mathbb{E}(X)+\operatorname{Cov}(X, Y) \operatorname{Var}(Y)^{-1}(Y-\mathbb{E}(Y))
E(X∣Y)=E(X)+Cov(X,Y)Var(Y)−1(Y−E(Y))
i.e., exactly the Gaussian process update for the posterior mean.
So GPs are in some sense second-order optimal. The Second Order means we only consider about the mean and the variance.
Why GPs: Uncertainty estimates from emulators
We often think of our prediction as consisting of two parts
- point estimate
- uncertainty in that estimate
Difficult of Using GPs
Kernel
We do not know what the covariance function, e.g. the kernel like. So what we can do is that we pick a covariance function from a small set, based usually on differentiability considerations.
Possibly try a few (plus combinations of a few) covariance functions, and attempt to make a good choice using some sort of empirical evaluation.
Assume of the GPs
Assuming a GP model for your data imposes a complex structure on the data. The number of parameters in a GP is essentially infinite, and so they are not identified even asymptotically.
So the posterior can concentrate not on a point, but on some submanifold of parameter space, and the projection of the prior on this space continues to impact the posterior even as more and more data are collected.
Hyper-parameter optimization
As well as problems of identifiability, the likelihood surface that is being maximized is often flat and multi-modal, and thus the optimizer can sometimes fail to converge, or gets stuck in local-maxima.















 3223
3223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









