






本文主要介绍一些按量计费的 在线 GPU 算力平台.
AutoDL
官网https://www.autodl.com/
这家是我目前最常用的平台,价格应该也是最低的,但是卡经常不够(4090 倒是经常有空余的)
配置
GPU 方面
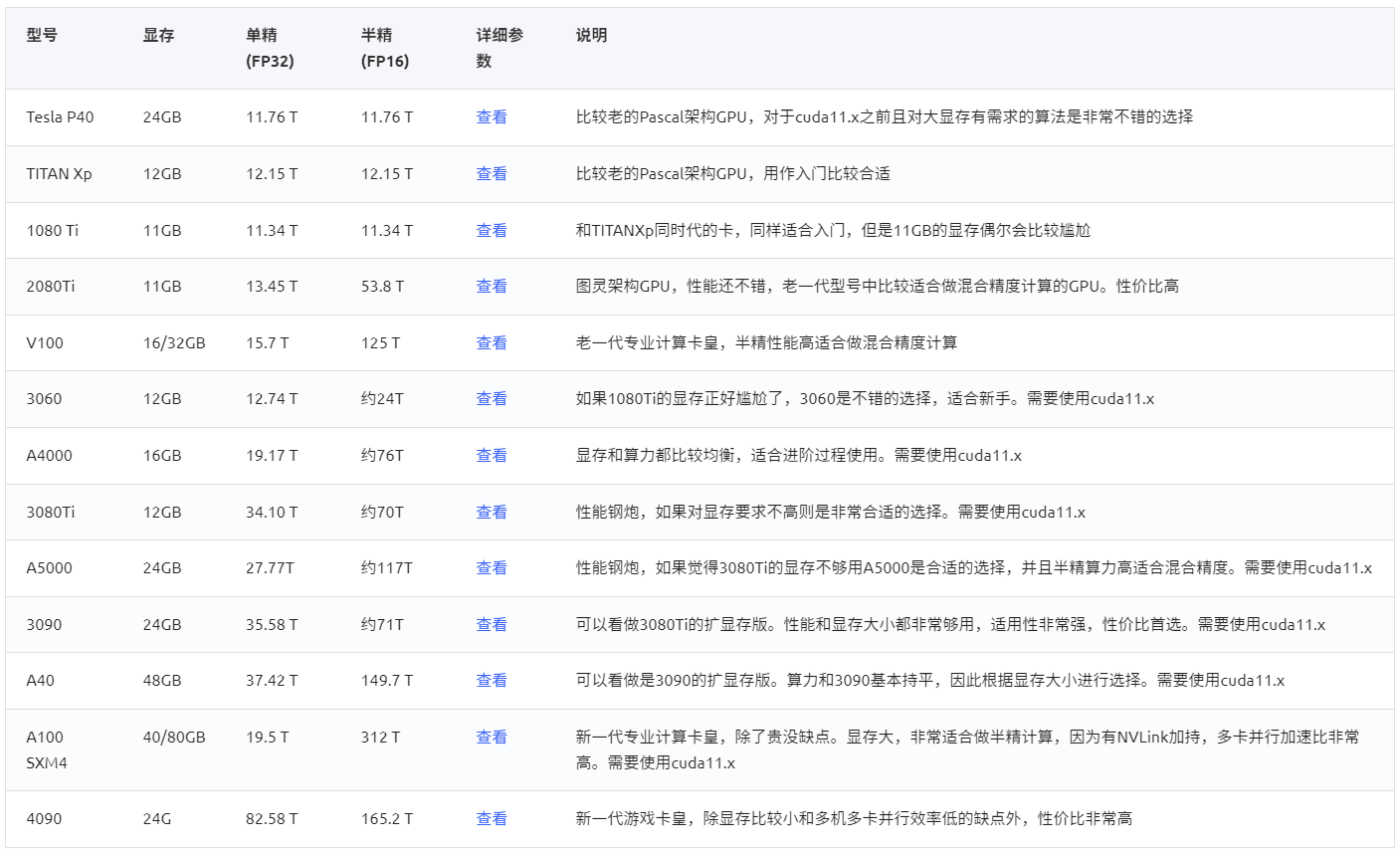
CPU 方面

价格
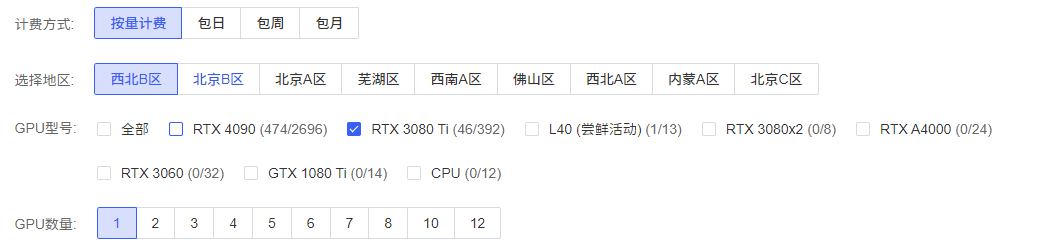
价格可以按小时计费(或者换算),包日/周/月
各个地区之间的数据不互通,只能在同一地区之间共享数据/克隆数据,有个好处就是当前机子没有卡的时候,可以克隆数据到同一地区有卡的机子
最常用的机子(比较抢手)

富哥

内蒙 A 区的机子传数据有些问题
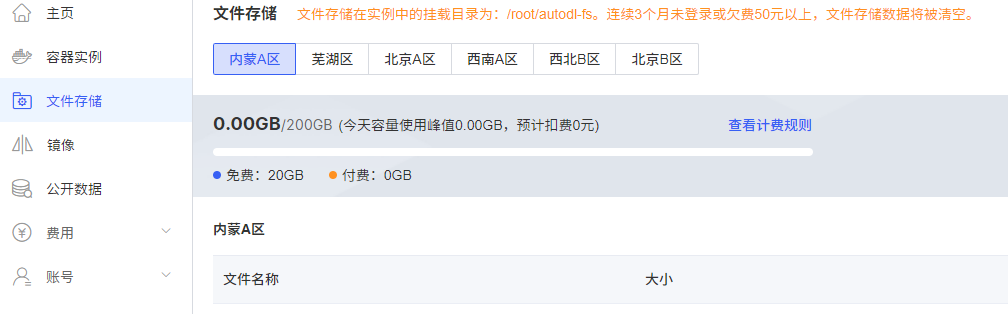
这个平台是自带网盘(也可以使用百度网盘,看文档),可以往里面上传数据,这个网盘是直接挂载到系统中的.但是我往内蒙 A 区上传几个 G 的文件时,一查 MD5 已经变了,解压后是损坏的.
使用
环境方面提供了很多镜像,基本上是开机就能使用了
这些都是支持的
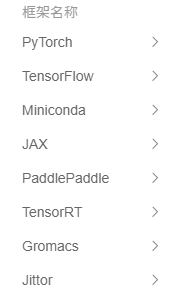
也能自己搭建环境
提供了 jupyter 和 ssh 方式进行使用,可以使用 vscode
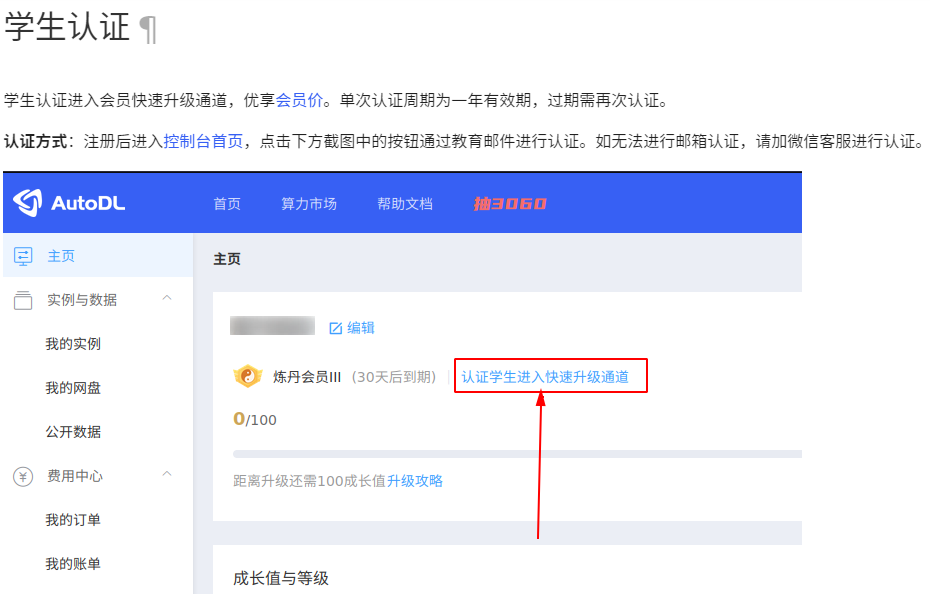
学生认证
使用教育邮箱认证
飞桨AI Studio星河社区
官网https://aistudio.baidu.com/index
这个是免费的,虽然也有付费(要开会员,20 一个月),只支持飞桨环境
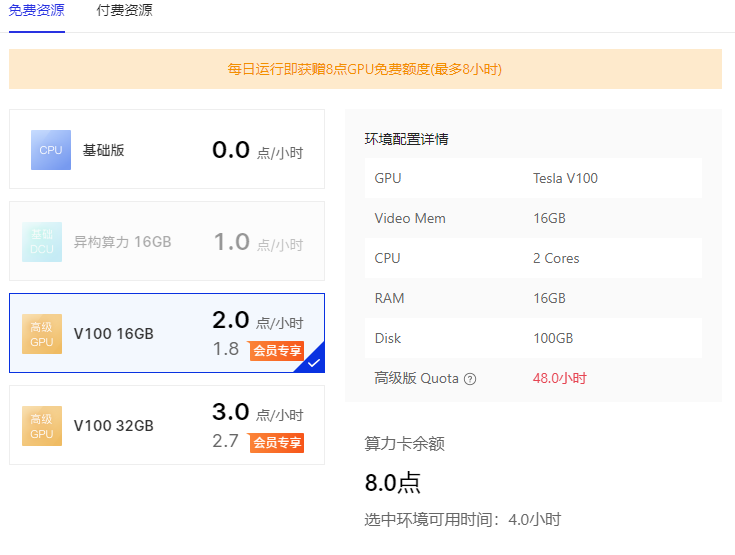
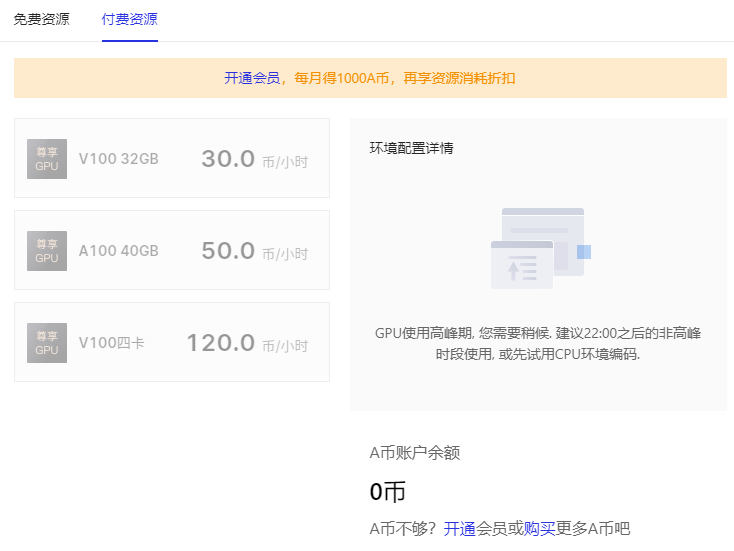
里面的 jupyter 是魔改过 UI 的,用起来不太习惯
kaggle
官网https://www.kaggle.com/
使用 GPU 需要验证手机号
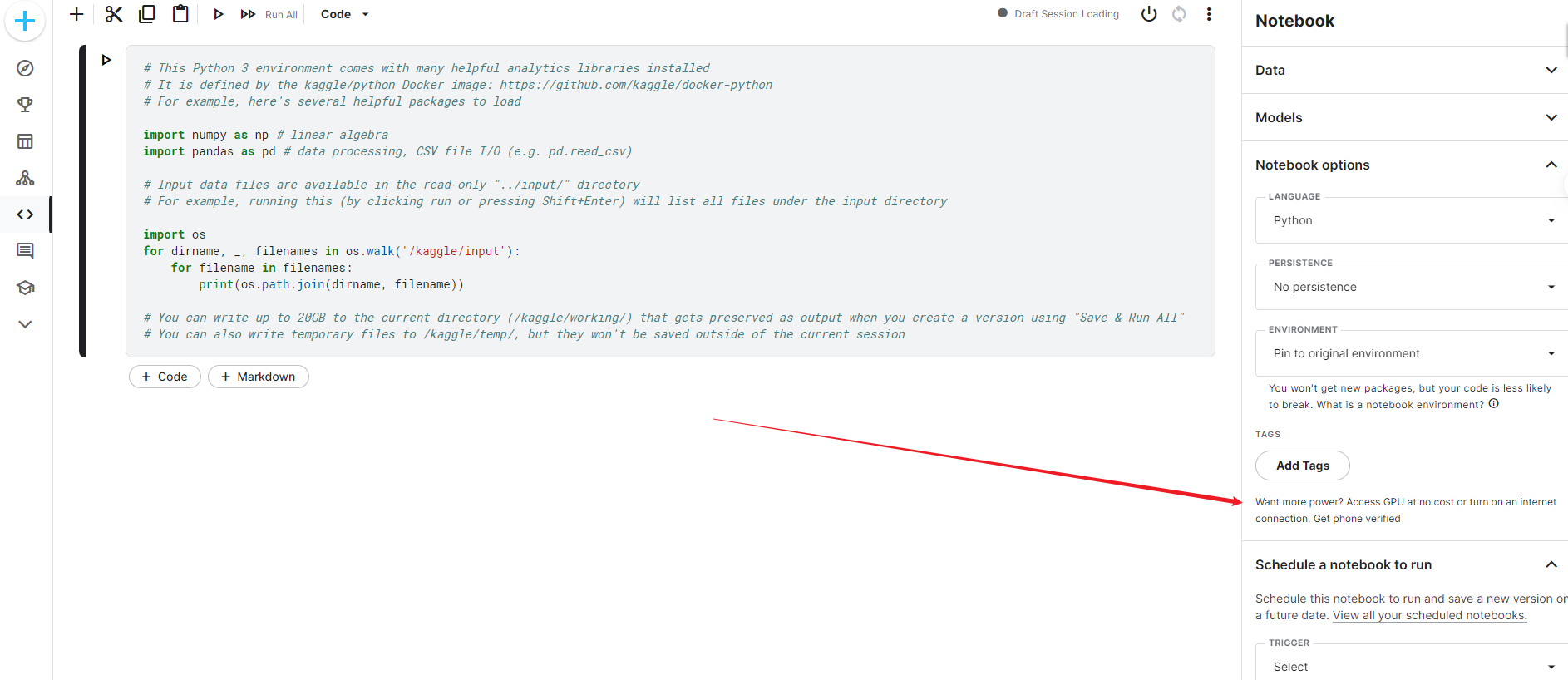
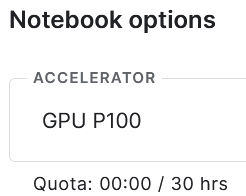
每周30h的免费GPU
阿里云
官网https://cn.aliyun.com/product/ecs/gpu
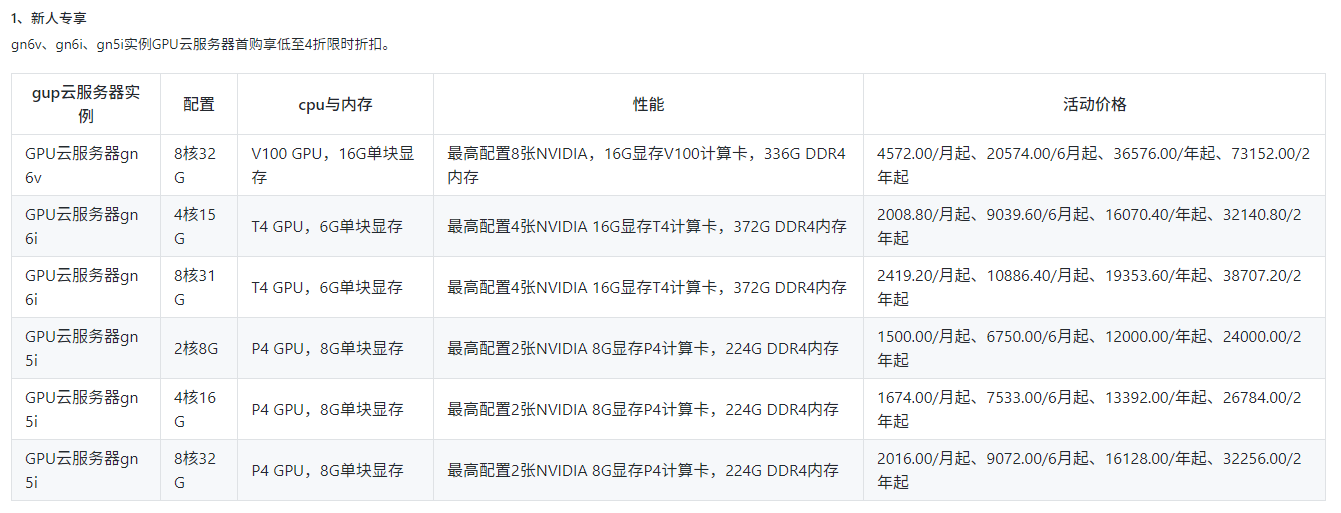
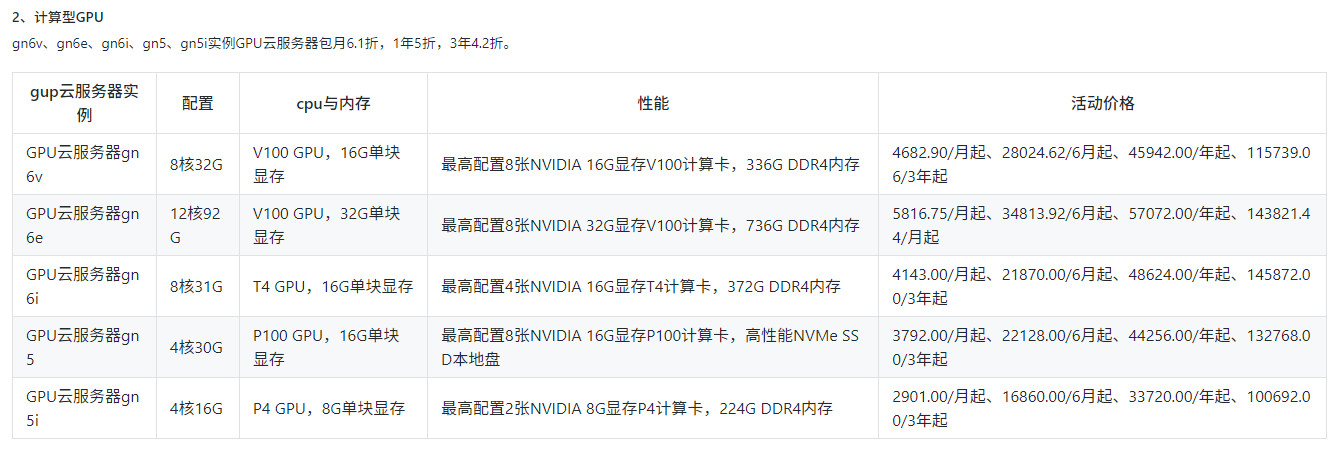
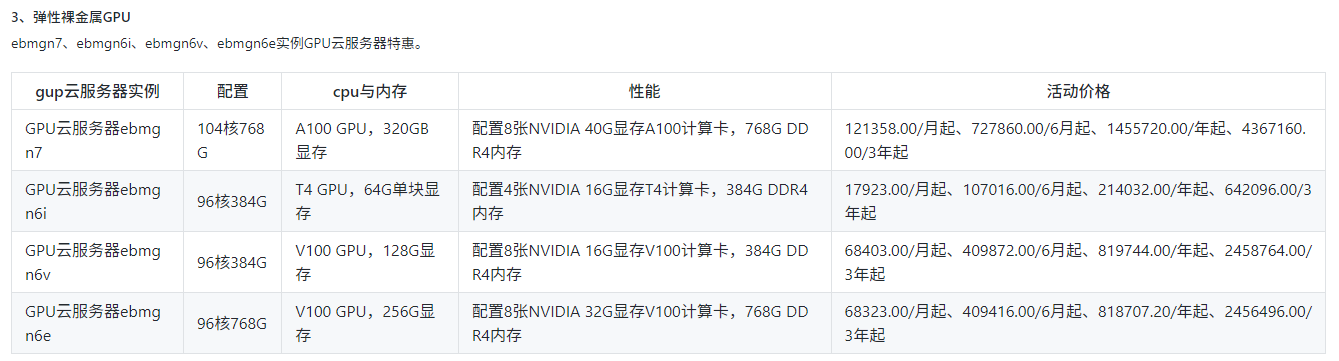
基本上不用考虑了,用不起
但是阿里云提供试用
阿里云试用宝典:https://developer.aliyun.com/free/
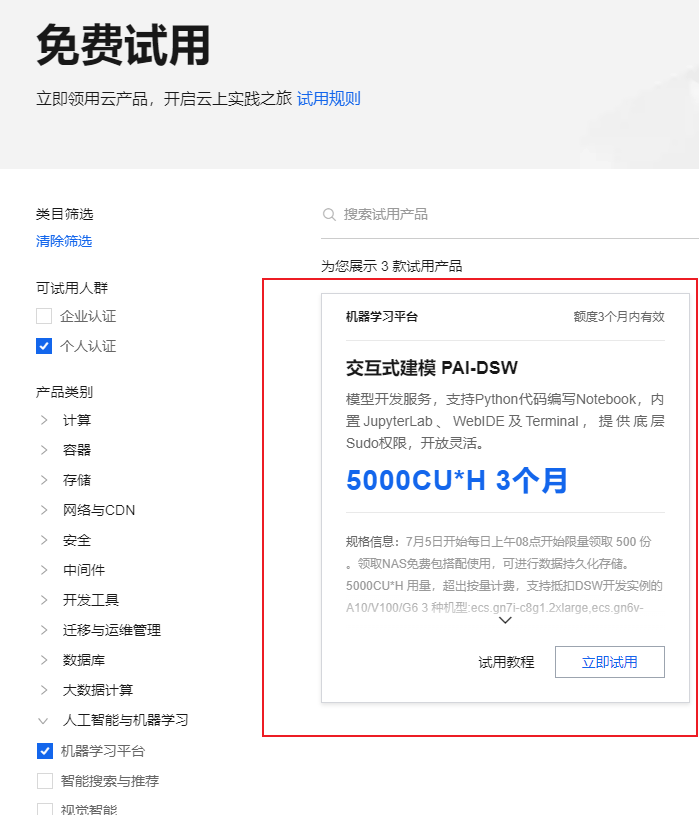
环境方面也是和 autodl 差不多的
这个是一次性的,3 个月内有效,用完就没了
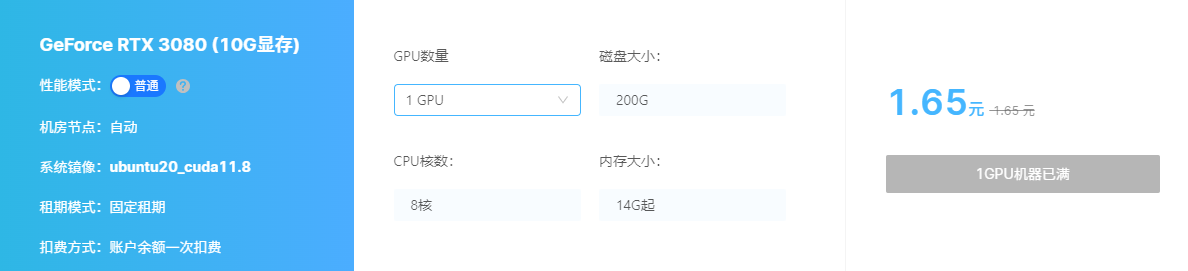
小牛云
官网http://calf-ai.com/
这个平台提供 Windows 主机

环境也是直接用的

价格比 autodl 贵一些
DeepLn
官网https://deepln.com/
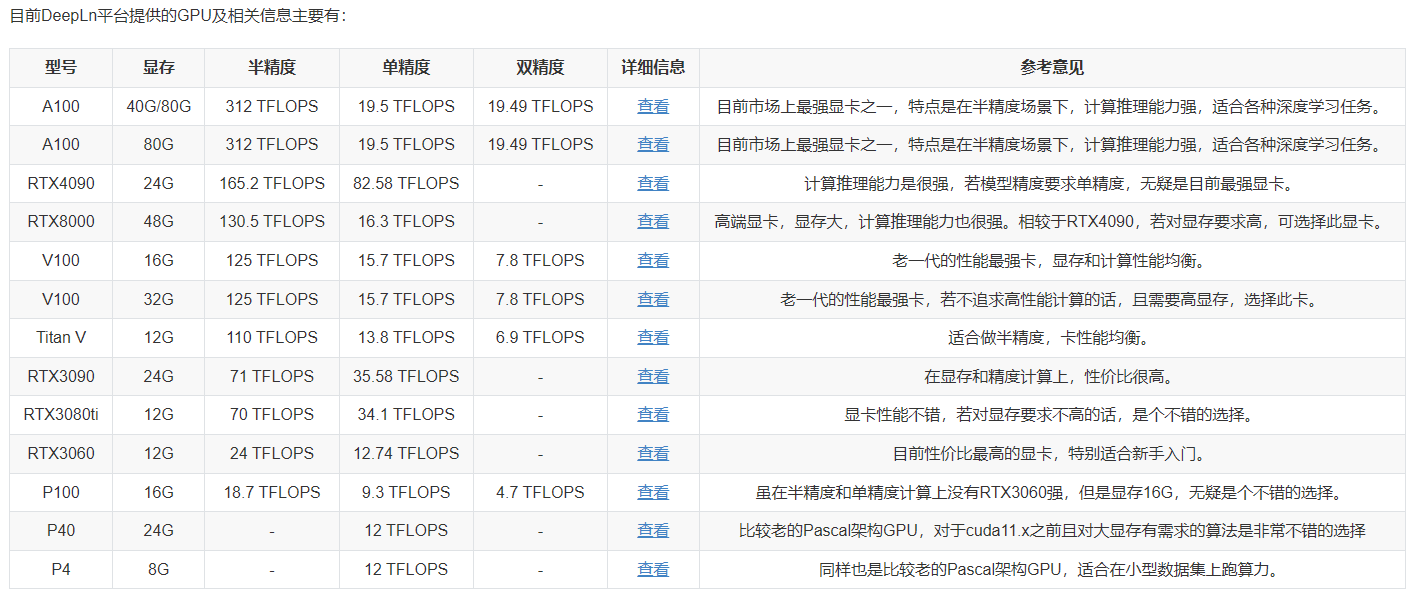
环境方面支持的比 autodl 少

价格比 autoal 便宜一些,配置也更强大
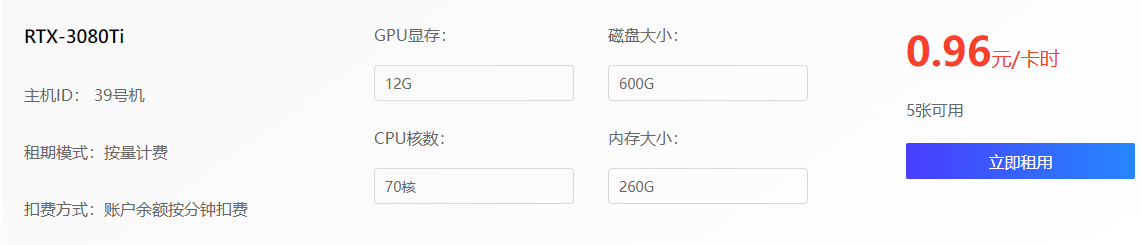
但是数据上传要开机才能操作
矩池云
官网https://www.matpool.com/

支持 jupyter 和 ssh
网盘容量比 autodl 小

部分机子支持 Windows
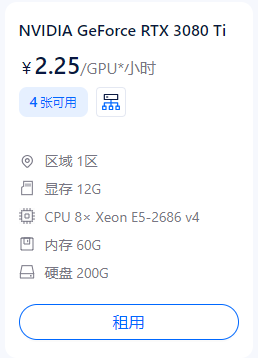
相对于 autodl 价格翻倍
恒源云
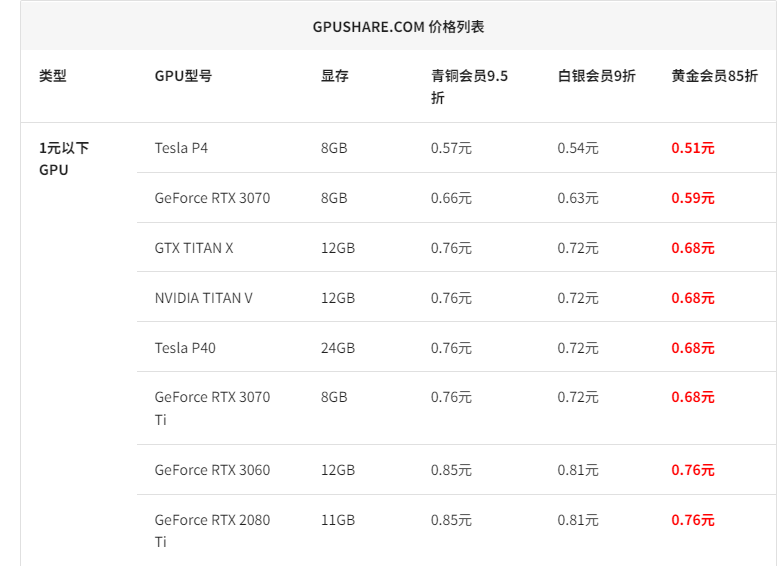
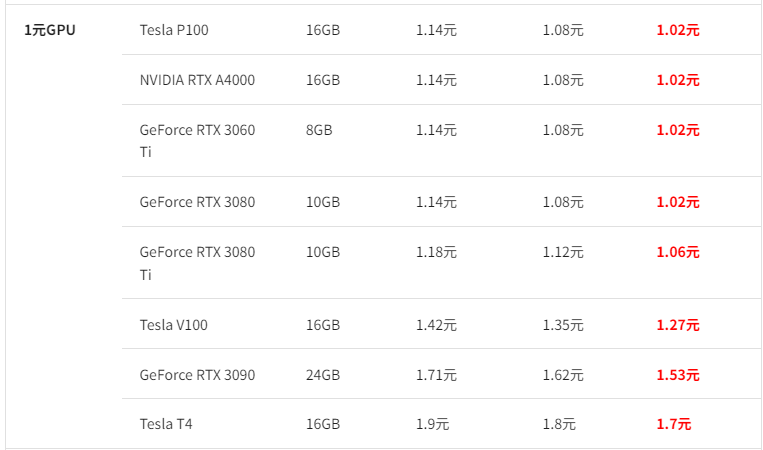
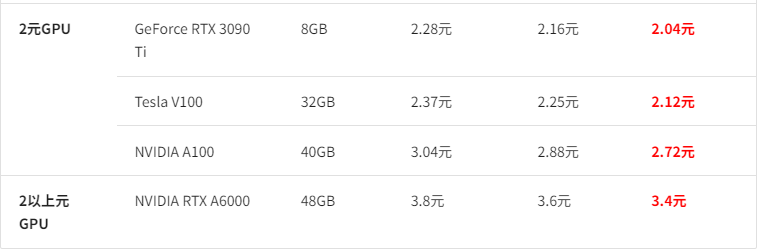
价格和 autodl 差不多
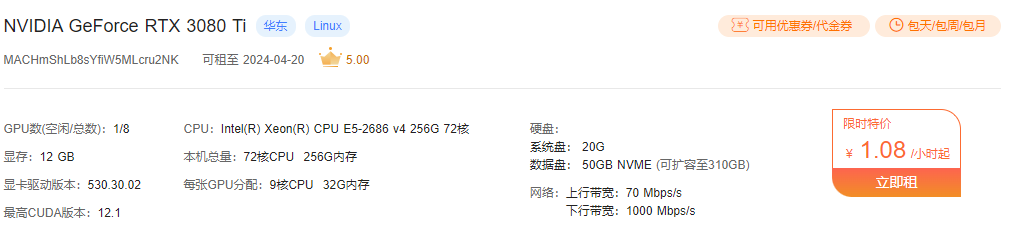
环境
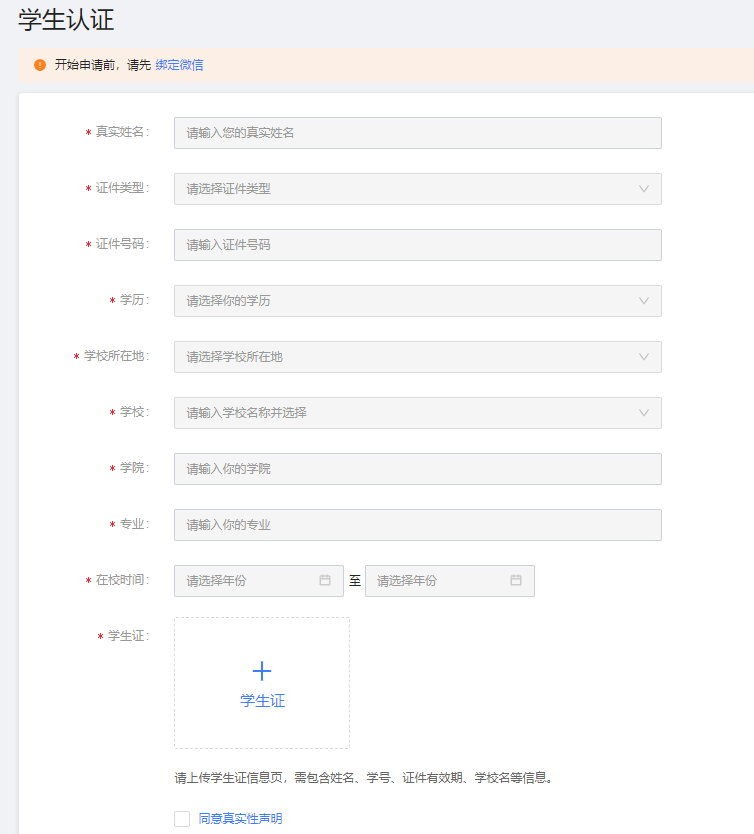
学生认证很麻烦
存储方面不如 autodl
使用也是支持 jupyter 和 ssh


















 4103
4103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









