







1. 研究问题
行人重识别挑战是将非重叠的不同视角下捕获的同一行人图像进行匹配,但是在跨视角下存在着显著的和未知的跨视角特征失真。
现有大量的的学习度量距离与子空间学习模型,但是他们学习的交叉视图变换是通用视图,因此在量化每个摄像机视图固有的特征失真方面可能不太有效。
学习针对re-id的视图特定的特征转换(即,特定于视图的re-id),一种未充分研究的方法,成为该问题的替代手段。本文从视觉特征增强的角度提出了一种新颖的特定视角的行人重识别框架。称为Camera coRrelation Aware Feature augmenTation(CRAFT)。
CRAFT通过从交叉视觉数据分布自动测量相机相关性并自适应地进行特征增强来将原始特征转换为新的自适应空间来进行交叉视图适配。
将传统的零填充(非参数化特征增强机制)推广到参数化特征增强来量化我们框架中的相机相关性。
结果,任何两个摄像机都可以自适应地建模,但不能独立建模,而摄像机视图之间的公共信息已经在自适应空间中量化。通过这种增强框架,可以容易地推广视图通用学习算法以引入视图特定的子模型,
通过本文提出的增强模型不仅继承了视图通用模型学习的优点,而且提供了一种考虑视图特定特征的有效方法。我们的CRAFT框架也可以扩展到两个以上摄像头的大型网络中进行行人重识别。
另外,我们提出了一个领域通用(domain-generic )的深度行人外观表示,它特别针对视图不变量,以便促进跨视角识别的的适用性。

目前的方法中有的方法侧重于共享视图 - 通用判别学习,但没有明确地将个体视图信息(例如,通过相机视图标签)转换运用到建模中。另外,虽然也有些方法考虑到了视图信息,但是大多数这些方法没有明确考虑跨摄像机视图的特征分布对齐,因此在视图通用对应物的模型学习期间不能直接量化和优化跨视图数据自适应。并且可扩展性(扩展到两个以上摄像头视图中)不是很好
2.主要贡献
1. 提出了CRAFT模型,这种模型通过推广现有的视觉通用的行人重识别模型从而实现了特定视觉的学习。
2. 我们扩展了我们的CRAFT框架,以共同学习特定于视图的特征转换,以便适用于涉及两个以上摄像机的大型网络中。
3. 我们提出了一种基于深度卷积网络的外观特征提取方法,以便提取领域通用和更多视图不变的人特征。
4. 并尝试用大型辅助非人物图像数据进行深度学习以构建判别性重识别特征。
3.针对视图不变的行人表征
训练数据集有限,导致使用深度模型获得有效的域通用特征有一定的缺陷。因此,本文使用了通过使用大量辅助图像数据集学习深度模型来解决稀疏训练数据问题。我们的方法在很大程度上可以是域通用的,因为从大规模数据中学习的外观模式可能更为通用。
为此,我们首先利用AlexNet 卷积神经网络从ILSVRC 2012训练数据集中学习,以获得不同的模式。然后,我们设计可靠的描述符来表征给定人物图像的外观。而且作者主要是利用浅层网络实现,因为更高层的网络可能针对于特定的任务,没有较好的泛化能力。其次,由于高层网络具有较大的感受野,可能受动态的姿势变换或者复杂背景的影响。
作者首先利用ILSVRC 2012数据集使用AlexNet 进行学习,初步学到不同的模型,然后再利用AlexNet 网络的浅层网络,也就是前两层卷积网络来实现给定的行人图片的浅层特征,作者认为如果使用更高层的网络,那么可能高层网络针对特定的任务,没有很好的泛化能力,并且高层网络具有较大的感受野,会受姿势、背景等复杂信息的影响。作者基于前两层网络实现了两种行人描述符。一个是Structured Person Descriptor. 一个是View-Invariant Person Descriptor.
Structured Person Descriptor. 两个卷积层得到的特征向量表示为![]() ,其中,hc/wc分别表示第c个卷积层对应的卷积特征向量的长与宽,mc表示的是滤波器的个数,也就是特征向量的深度。作者在实验中,设置 h 1 = w 1= 55;m 1 =96;and h 2= w 2=27;m 2= 256. 由于通常行人姿势变化比较大,为了减少姿势变化带来的影响,作者,进一步将特征图进行水平切分,每个切片的高度为 h s ,作者在实验中将hs设置为5,以保持足够的空间结构。然后,我们从每个条中提取每个特征图的强度直方图。直方图的bin值大小为16,然后将这些条带直方图进行拼接就形成了我们最终的强度直方图(HIP) 。这也就是图2中的(d)部分实现的具体过程。最终得到的特征向量的维度为:37376 = 16(bins)x
,其中,hc/wc分别表示第c个卷积层对应的卷积特征向量的长与宽,mc表示的是滤波器的个数,也就是特征向量的深度。作者在实验中,设置 h 1 = w 1= 55;m 1 =96;and h 2= w 2=27;m 2= 256. 由于通常行人姿势变化比较大,为了减少姿势变化带来的影响,作者,进一步将特征图进行水平切分,每个切片的高度为 h s ,作者在实验中将hs设置为5,以保持足够的空间结构。然后,我们从每个条中提取每个特征图的强度直方图。直方图的bin值大小为16,然后将这些条带直方图进行拼接就形成了我们最终的强度直方图(HIP) 。这也就是图2中的(d)部分实现的具体过程。最终得到的特征向量的维度为:37376 = 16(bins)x
11(strips)x96(m 1 ) +16(bins) x5(strips)x256(m ).
View-Invariant Person Descriptor. HIP descriptor 完整的描述了所有特征图的activation information。不考虑他们的相对显著性和噪声程度。这种描述器能够保证模型的完成性,但是对于跨视角的行人姿势的改变以及背景的变化相对比较敏感。为了缓解这种情况,作者建议有选择地使用这些特征映射来进一步的引入视图不变性。于是提出了合并激活序列信息,作者称之为序数模式直方图(HOP)。

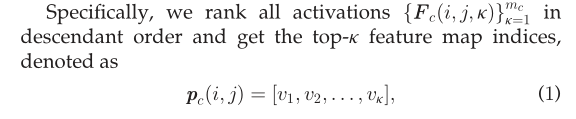
作者使用一个下降的序列来表示所有的激活特征,并且得到前k=20个特征图序列。这里的vi表示的是排序列表中 的第i个特征图。通过对每个图像块重复相同的排序过程,我们得到![]() 的一个新的表示方法:
的一个新的表示方法:![]() Pc同样也是表示特征图,因此,我们可以想HIP那样通过直方图来进行表示,最终得到HOP特征向量:
Pc同样也是表示特征图,因此,我们可以想HIP那样通过直方图来进行表示,最终得到HOP特征向量:![]()
最后我们对得到的特征向量进行整合,最终得到总的维度为:![]()
作者所提出的特征增加方法主要分为两步,一步是相机相关性衡量,另一步就是利用相机共性信息进行自适应特征增强。
相机相关性衡量
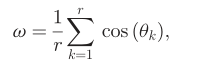
自适应特征增强
获得相机相关度 w(omiga)之后,为了将它整合到我们的特征增加之中,我们将零扩充进行扩展得到:
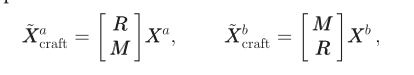
这里的R,M都是dxd的增广矩阵,![]()
首先我们利用主成分分析法获得线性子空间表示。
Gb然后可以看作格拉斯曼流形上的数据点 - 欧几里德空间的一组固定维线性子空间。
流形点















 2992
2992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









