







目录
文章简介
最近由于项目需要,需要使用到目标检测算法,由于之前并没有接触太多这方面的内容,所以做下简单的记录,方便日后回顾使用。这里主要以yolov5为主,内容参考了小土堆的B站视频
项目安装
下载
首先在Github上搜索yolov5,选择stars最多的项目,对应连接:https://github.com/ultralytics/yolov5
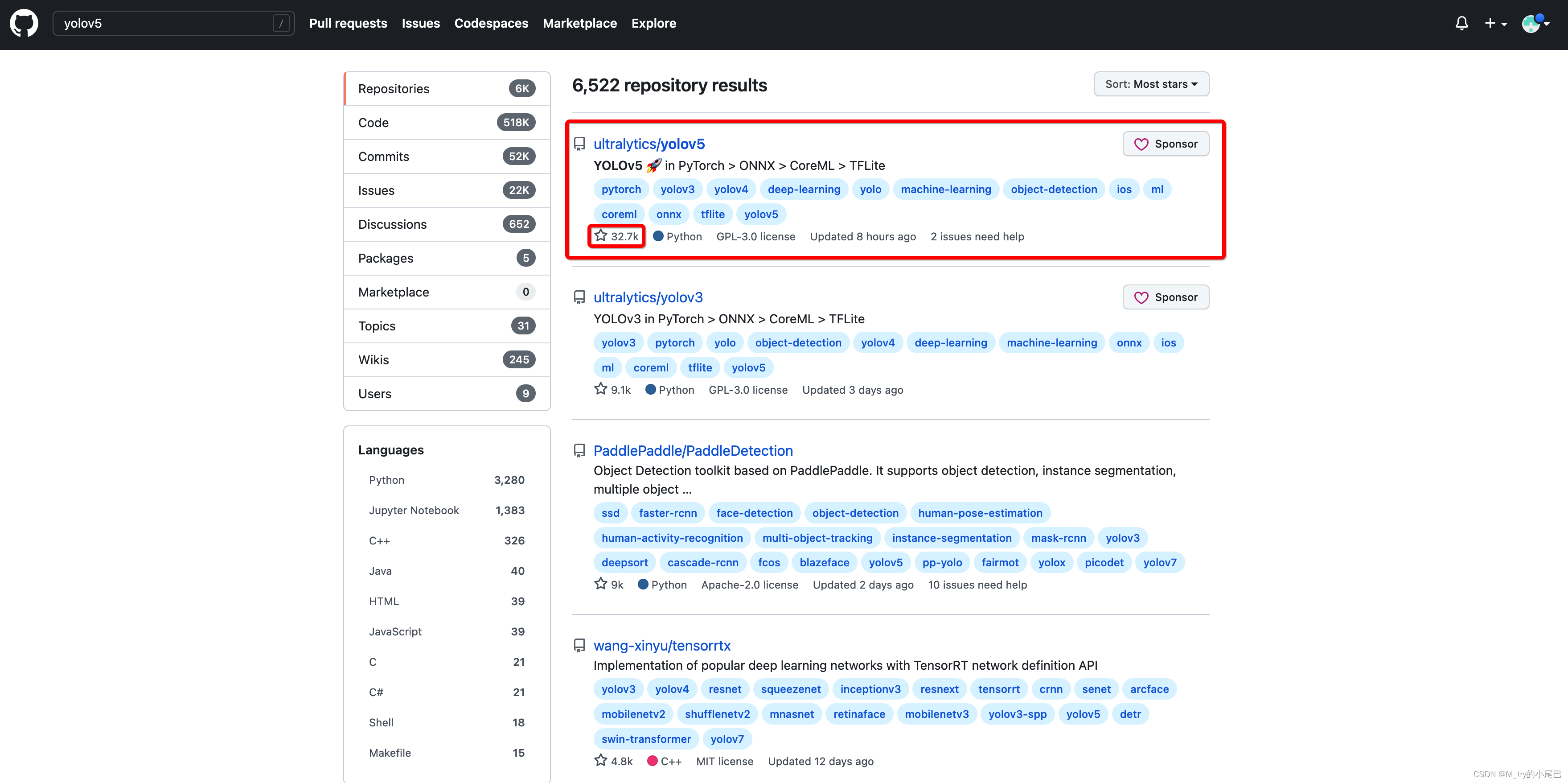
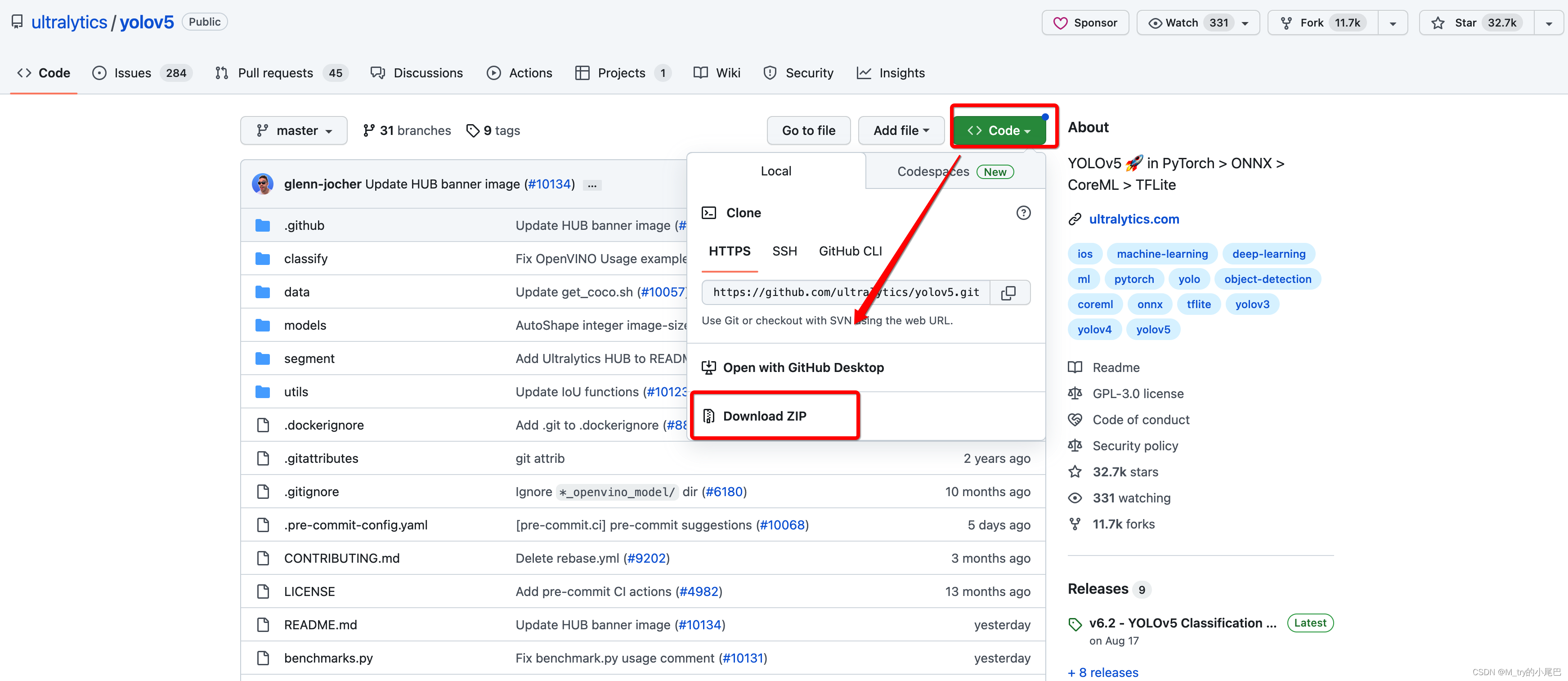
pycharm打开yolov5
将下载的zip文件解压,使用pycharm打开
安装依赖库
pip install -r requirements.txt
项目运行
打开detect.py,直接运行,我使用的是mac系统,运行时会报错(Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.OMP)
在detect.py中添加如下代码即可
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'运行界面(由于我不是第一次运行,如果你是第一次运行的话,输出信息会存在一些差异)

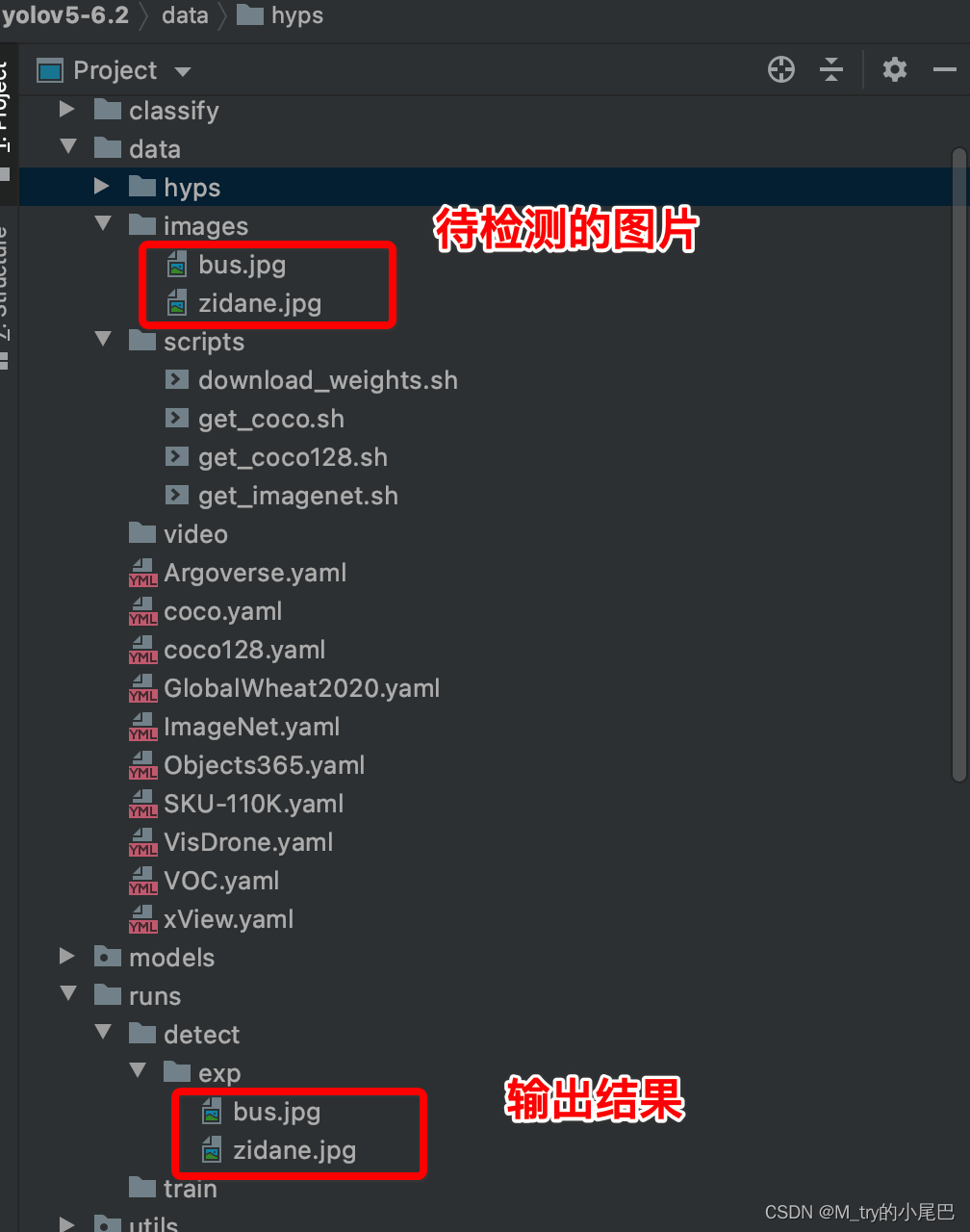
脚本运行时,会默认对项目中的data/images/文件夹下的图片数据进行检测,检测结果存储在项目文件夹/runs/detect/exp/文件夹下。下图展示的是项目自带的图片,如果你想检测自己的图片,可以将图片放到对应的文件夹下。
关键参数
调整detect.py中的配置可以实现以下目标检测功能
首先介绍下detect中的关键配置参数,配置通过parse_opt函数试下,对象的函数如下所示。
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5m.pt', help='model path(s)')
#默认设置
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
# 调用手机摄像头
#parser.add_argument('--source', type=str, default='http://admin:admin@IP', help='file/dir/URL/glob, 0 for webcam')
#调用本地摄像头
#parser.add_argument('--source', type=str, default='0', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.2, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.25, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=1, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt--weight : 描述模型的文件,设置后面的default,用于加载预训练模型,默认设置如下,可以用官方的文件,也可以用自己的文件
default=ROOT / 'yolov5s.pt' 其他的预训练文件可以参考如下连接Release v6.2 - YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai integrations · ultralytics/yolov5 · GitHub
-- source:通过default设置待检测的内容,当设置路径下为图片是,实现对图片内容的检测,当设置路径下是视频时,实现对视频内容的目标检测;当default='0'时调用本地电脑的摄像头进行检测;当设置手机摄像头IP地址时实现手机摄像头实时检测。后面具体介绍其用法。
-- data :指定ymal为描述数据集的文件。默认指定data/coco128.ymal文件,其中包含的信息如下所示。如果要训练自己的数据集,可参照这个文件的设置
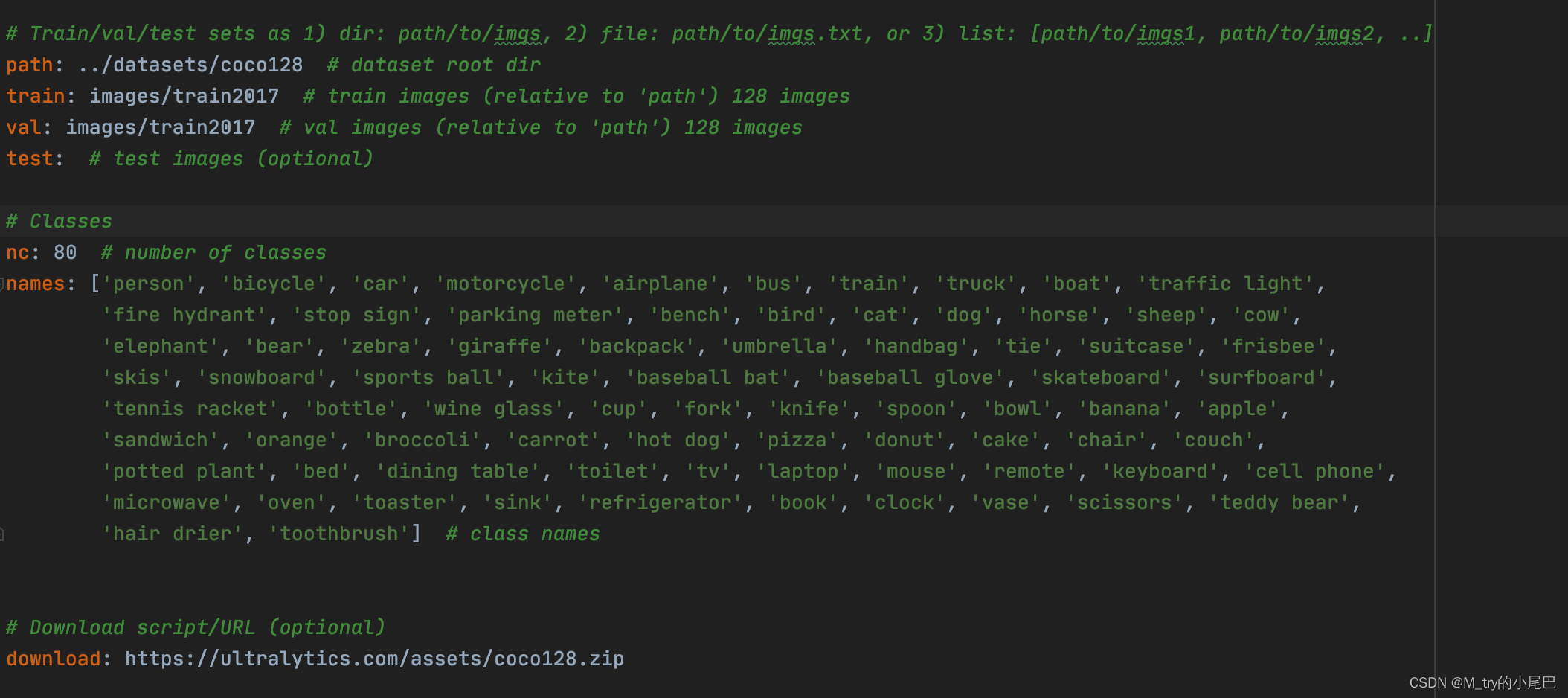
其中设置的内容包括,path:数据集的存储位置;train:训练集的位置(在path中的位置);val:验证集的位置;test:测试集的位置;nc:目标检测的类别数;names:每个类别的名称;download:数据集的下载链接
-- imgsz: 图片大小,默认为640,因为预训练的模型对图像的大小有要去,在--weight中设置下载的模型文件后,可以再--imgsz中修改对应的图片大小效果会比较好,也可以不修改。
--conf-thres:置信度阈值,表示检测框内目标的置信度最小的阈值,当检测框中的目标超过该值时就人为检测到目标了。具体什么叫置信度可以查找对应的资料进行了解。值设置越大,检测标记的物体会越少;设置的越小检测标记出的物体约多。默认阈值为0.25
-- iou-thres:交并比阈值:(预测框大小真实框大小)/(预测框大小
真实框大小),设置值越大导致一个物品有多个检测框,设置约小,多个物品只有一个检测框。默认阈值为0.4
-- max-det:最大检测框数量,默认为1000,表示一张图片中最多可检测出1000个物体。
-- device:使用CPU还是GPU,可以不同设置,
-- view-img:默认为False,在pycharm中进行如下设置,在程序运行时生成窗口实时显示目标检测的结果,特别是在对视频进行检测时看起来会比较直观。
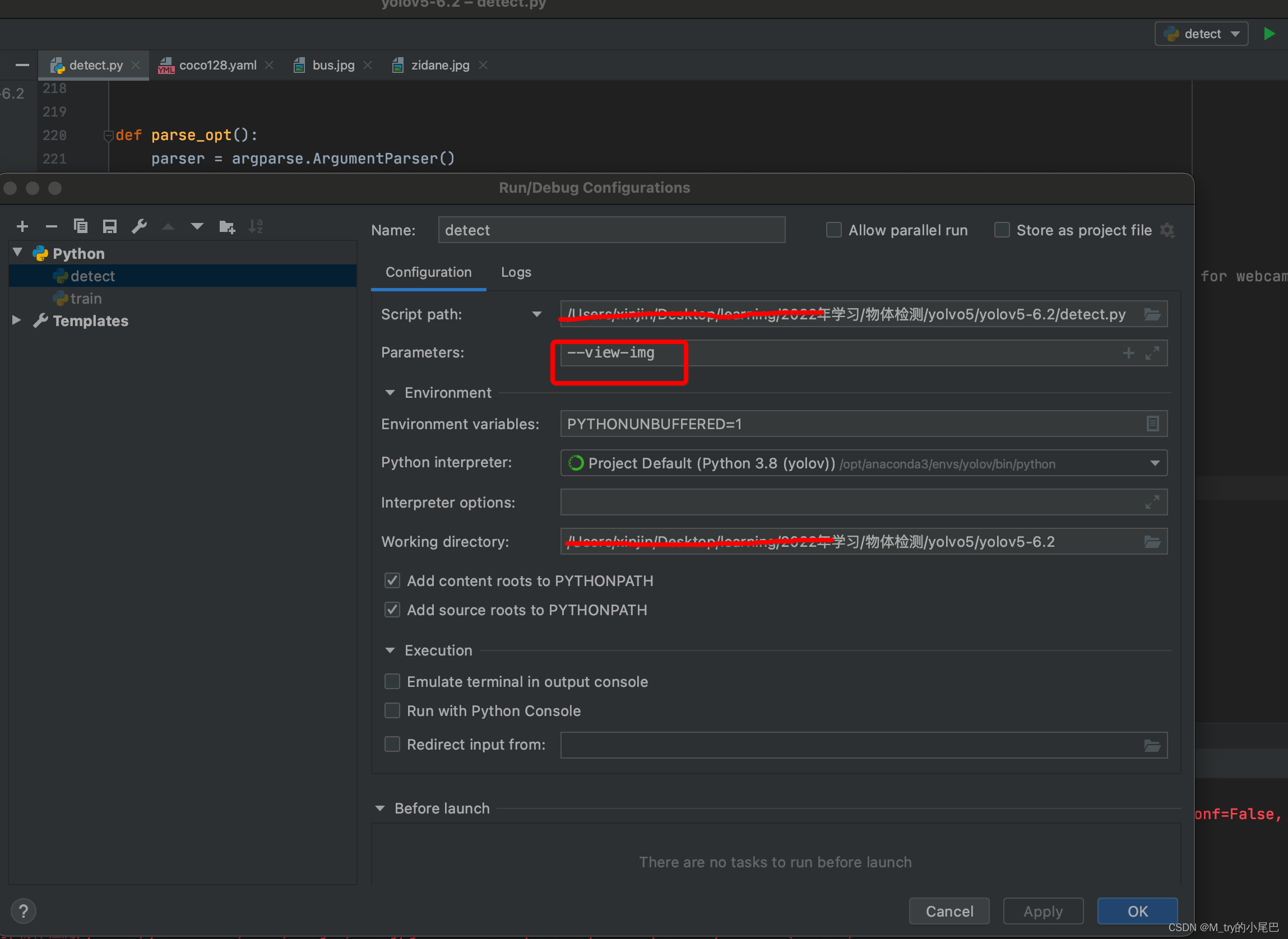
或者在命令行直接运行python detect.py --view-img
-- save-txt: 是否将预测结果txt的形式保存下来,默认为False,设置后会将检测出的结果标签和检测框的坐标存储下来,如下所示
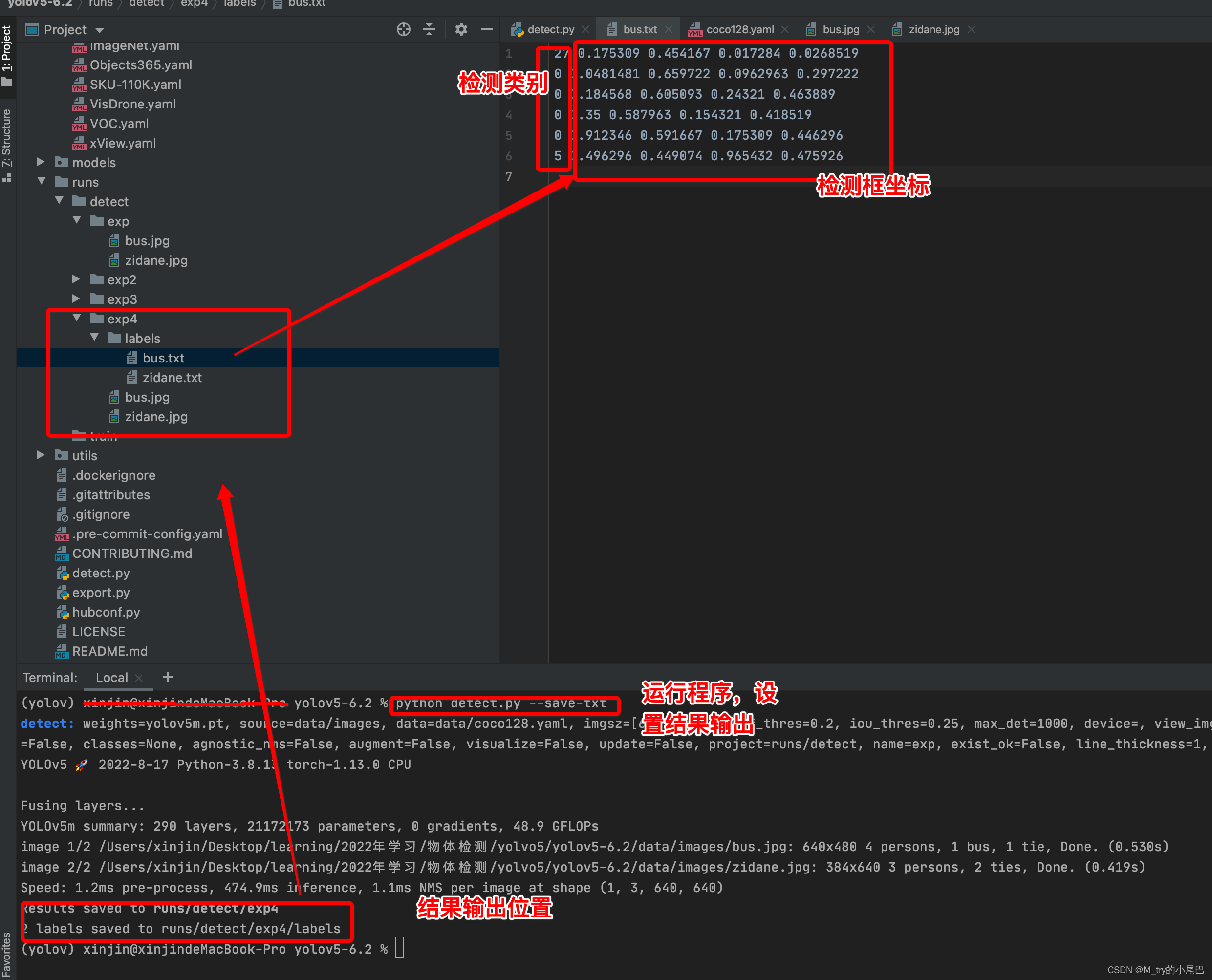
--save-conf:是否将置信度保存在txt文件中
-- save-crop:是否将检测的结果裁剪存储下来,我们看下设置后的效果
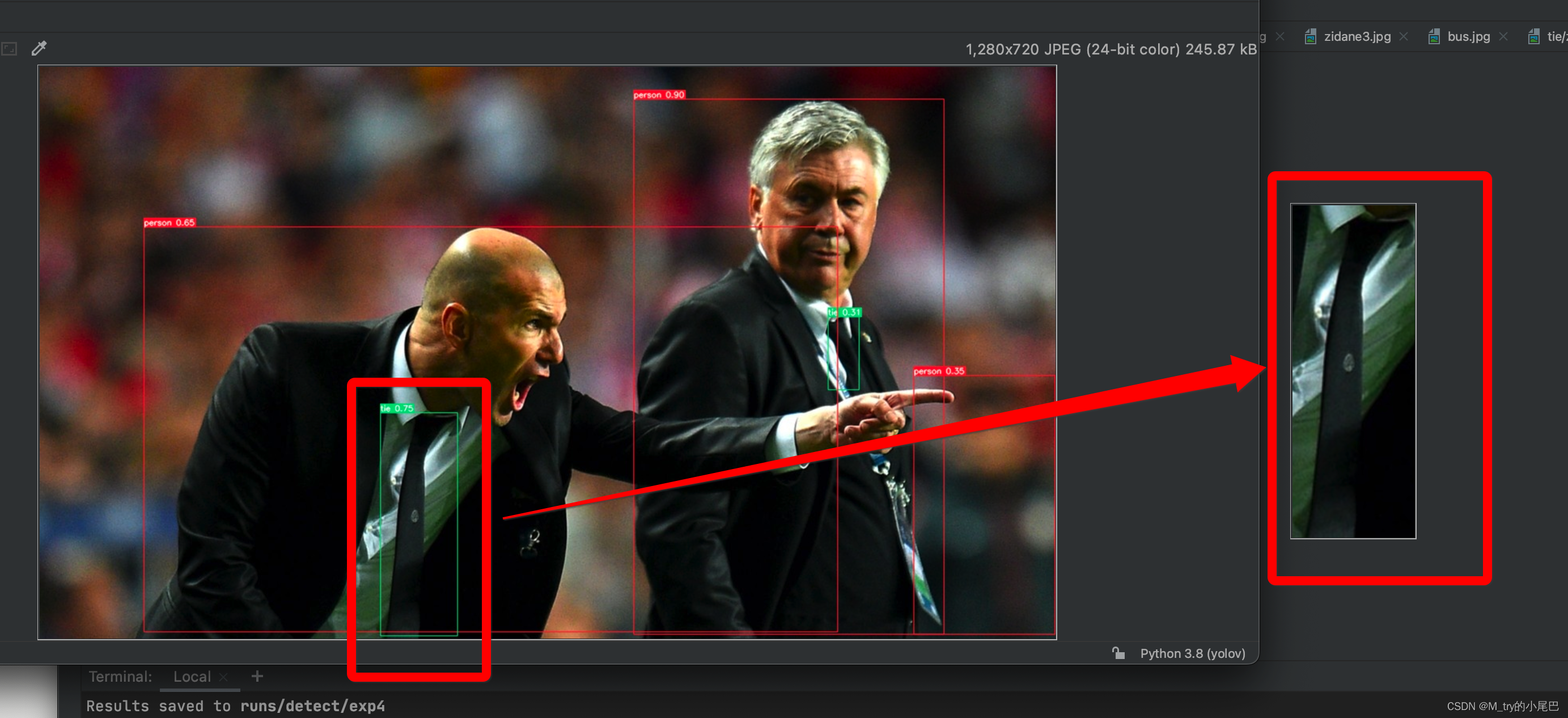
我们发现领带在原图上被检测出来,并将检测的结果裁剪出来,单独保存在文件夹中。
--nosave:不保存检测结果
--classes:指定检测的目标类别,在yolov5中列表0表示person,若仅仅检测人不做其他目标识别时,可进行如下设置
python detect.py --classes 0
只会检测人,领带并不会被检测出来

--agnostic-nms: 在执行目标检测任务时,可能对同一个目标进行多次检测,nms是确保算法对每个对象得到一个检测框的方法,具体如何是实现可以去搜索对应的文章。
--augment:使用使用数据增强的方式进行推理
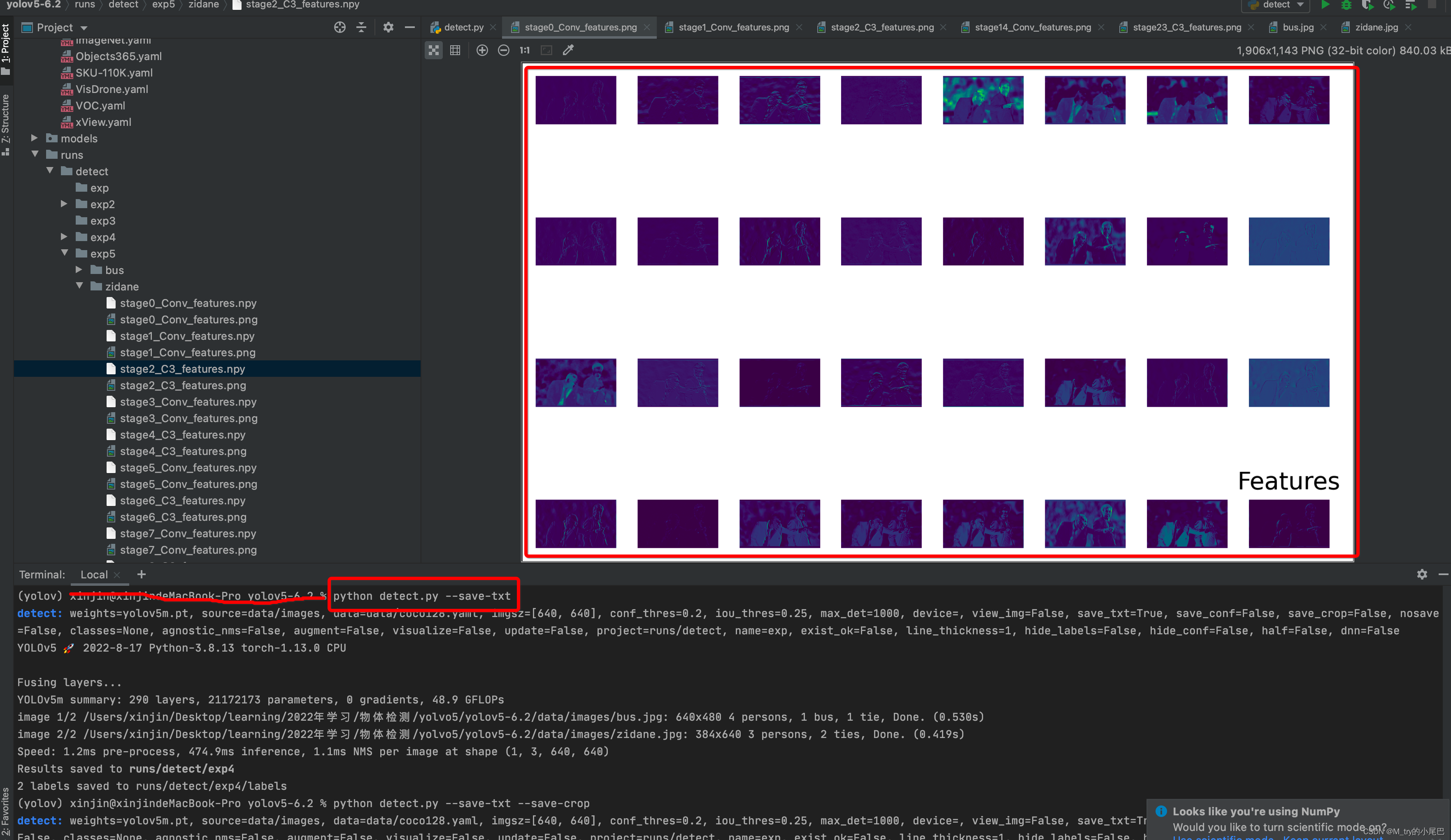
--visualize:是否可视化特征图。若设置该参数可以显示中间的特征图
--update:看土堆的视频介绍说,这部分应该是将模型中的优化器部分去掉,可以不用管,个人也不是很清楚他的具体效果
--project:预测结果的保存路径
--name:存储结果的文件夹名称
--exist-ok:模型输出是否保存在已有的文件夹下,如果设置该参数,每次运行的结果都会存储在原有的文件夹下
--line-thickness:检测框线条的粗细
-- hide-labels:是否隐藏检测结果的标签
--hide-conf: 是否隐藏置信度
--half:该参数是是否使用FP16半精度推理;在训练阶段,梯度更新往往是很微小的,需要相对较高的精度,一般要用FP32以上;在预测时,精度要求没有那么高,一般F16(半精度)就可以,甚至可以用INT8,精度影响不会很大;同时低精度的模型占用空间更小。有利于部署在嵌入式模型里面
--dnn;使用使用OpenCV DNN 进行ONNX推理
图片目标识别
设置--source参数即可实现对自己的图片的识别
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')将图片拷贝到项目的目录下的images中,即可,这个文件路径是默认的,也可以自己添加新的路基,人后在default中指定好即可
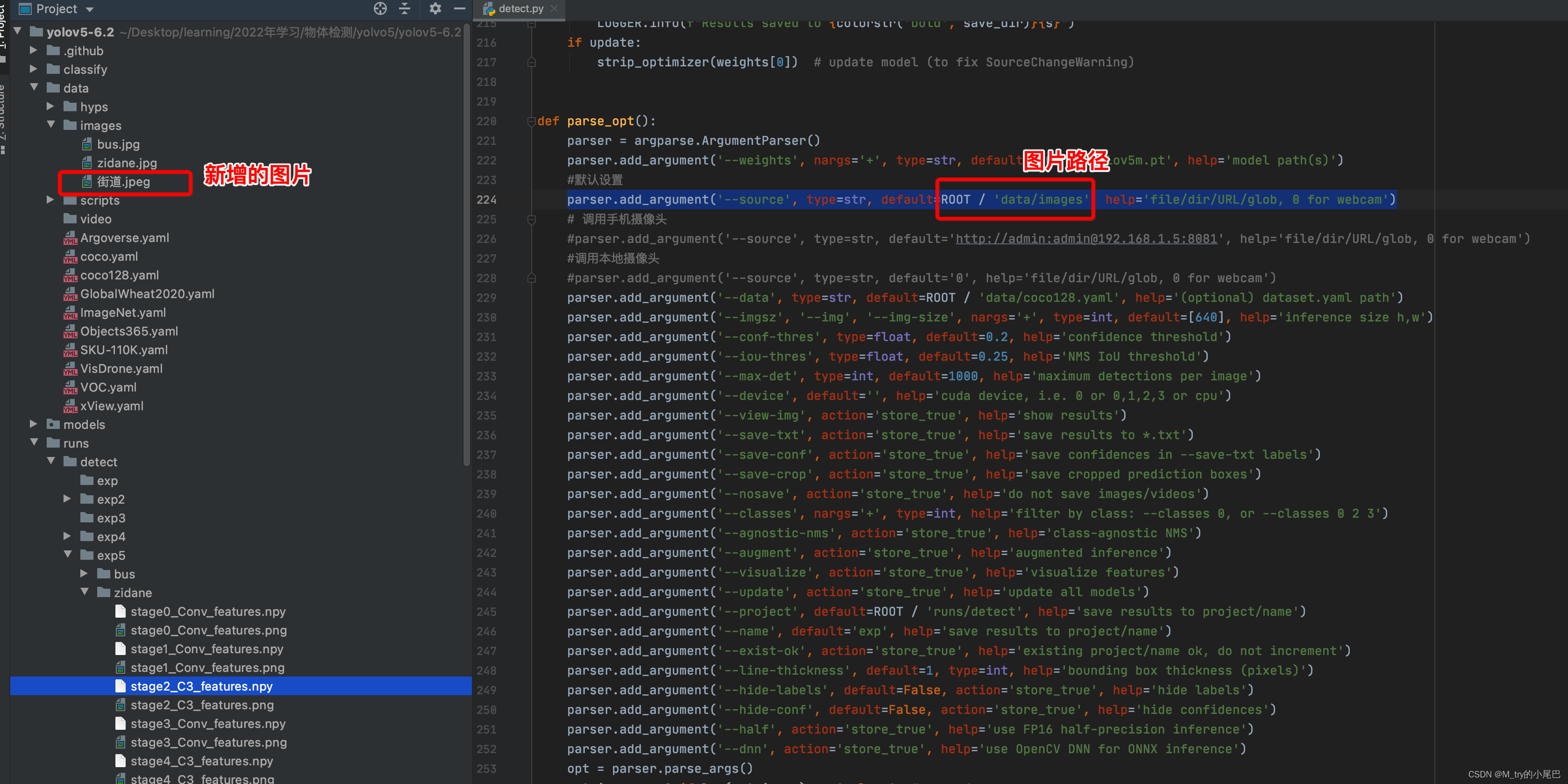
运行detect.py脚本,结果如下:

视频目标检测
同图片的目标检测一致,在--source中指定default的地址即可,这里我在原data文件下新建一个叫video的文件夹,将要检测的视频放入该文件夹下,同时修改default
parser.add_argument('--source', type=str, default=ROOT / 'data/video', help='file/dir/URL/glob, 0 for webcam')
调用电脑的摄像头
只要将--source中的default设置为0即可
parser.add_argument('--source', type=str, default='0', help='file/dir/URL/glob, 0 for webcam')调用手机摄像头实时检测
首先,手机上安装IP摄像头APP

手机和笔记本电脑连接相同的wifi
打开app
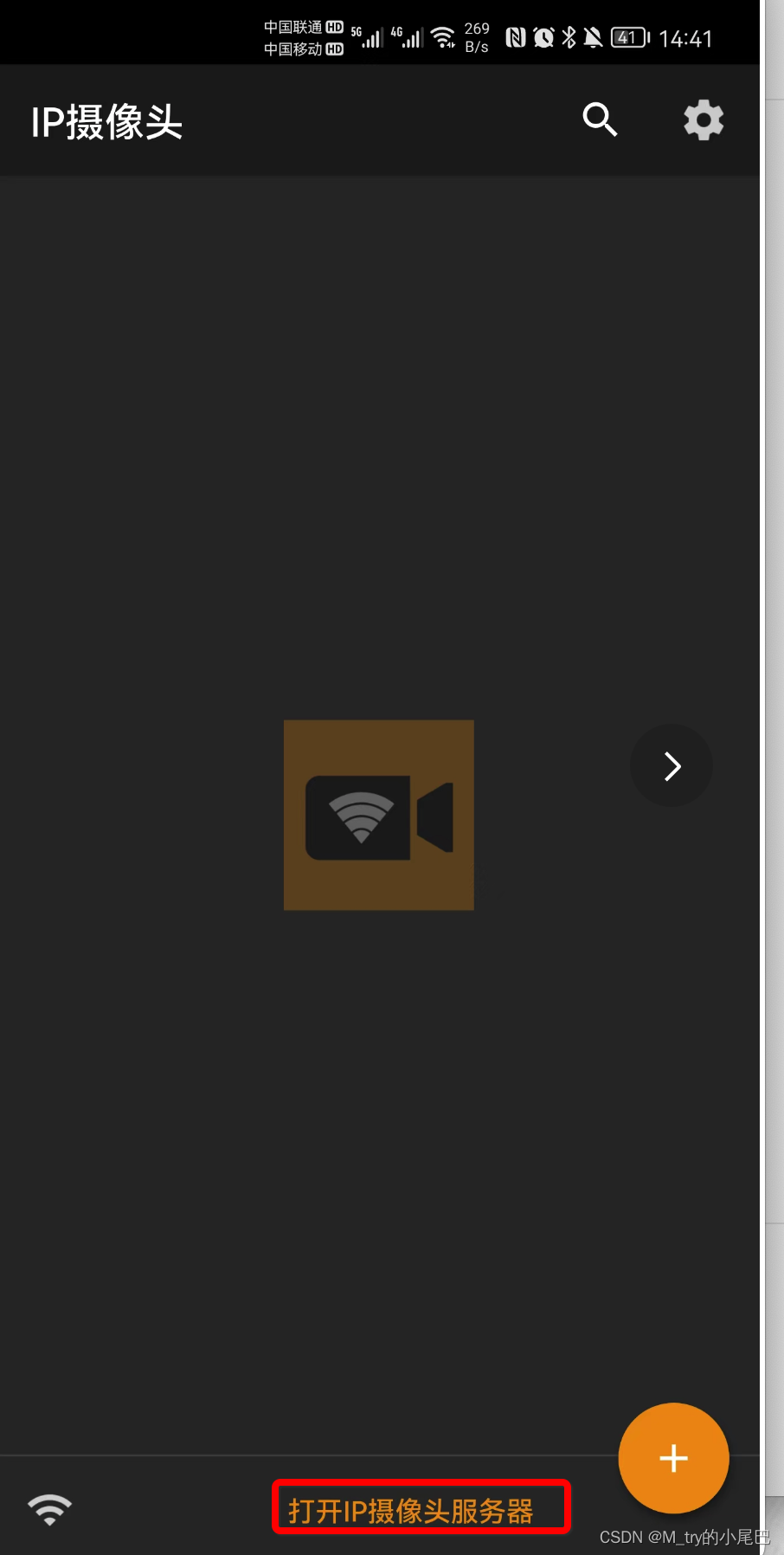
点击打开IP摄像头服务器
设置账号:admin
设置密码:admin
账号密码可以自定义
记录下局域网的地址

设置--source中的default,设置为
parser.add_argument('--source', type=str, default='http://账号:密码@局域网地址', help='file/dir/URL/glob, 0 for webcam')运行结果

下次将介绍下如何在本地制作和训练自己的数据集,实现目标检测,如果电脑不支持GPU(比我intel的mac电脑)加速,考虑使用colab提供的免费GPU资源进行模型训练。关于yolov5中的代码还没有进行深入研究,希望自己在后面学习的过程中可以补齐这部分的内容。
参考资料
1、源码地址:https://github.com/ultralytics/yolov5














 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









