






摘要
我们分析了自回归transformer语言模型中事实相关的存储和召回,发现了这些相关事实能够被定位,且可以直接编辑计算的证据。我们首先提出了一种因果干预方法来识别模型中对事实预测具有决定性的神经元激活。这揭示了中层前馈模块中的一组独特步骤,这些模块在处理主观字符时处理了事实预测。为了测试我们的假设,即这些计算对应于事实相关的召回,我们使用Rank-One Model Editing (ROME)修改了前馈模块的权重,以更新特定的事实。我们发现ROME在标准的zero-shot关系提取(zsRE)模型编辑任务上是有效的。我们还在一个具有较难的反事实断言的新数据集中评估了ROME,表明该方法保持特异性和泛化性,而其他方法则会牺牲其中一种。我们的结果证实了中层前馈模块存储事实的重要作用,并表明直接操纵计算机制可能是进行模型编辑的可行方法。代码,数据集,可视化和交互式演示笔记可在https://rome.baulab.info/上找到。
1.介绍
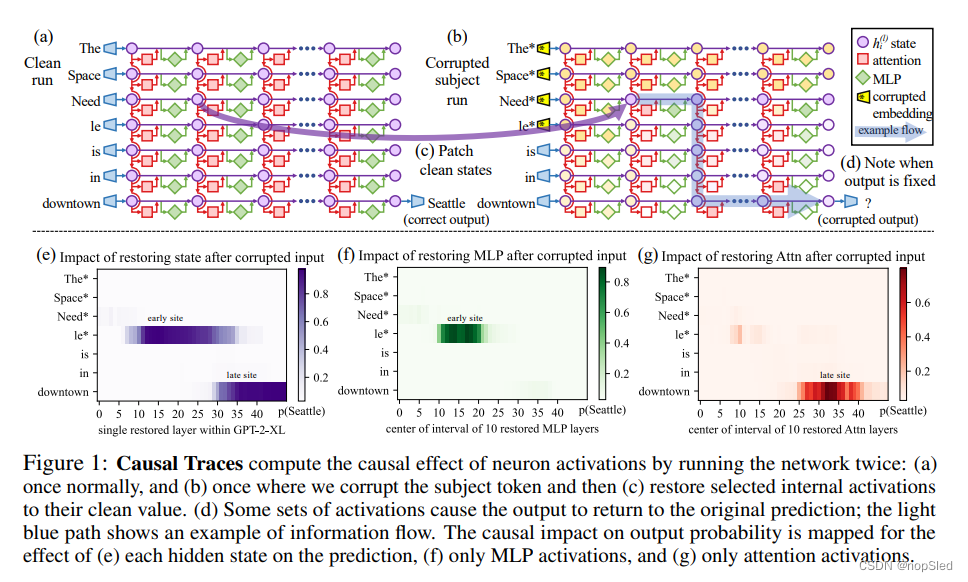
大型语言模型将事实存储在哪里?在本文中,我们报告的证据表明,GPT中的事实对应于可以直接编辑的局部计算。
大型语言模型可以预测世界相关的事实描述。例如,给定“The Space Needle is located in the city of”的前缀,GPT能可靠地预测出真正的答案:“Seattle”(图1a)。已经观察到在自回归GPT模型和屏蔽BERT模型中都出现了事实知识。
在本文中,我们研究了这些种事实是如何存储在类似GPT的自回归transformer模型中的。尽管目前使用的许多大型神经网络都是自回归的,但他们存储知识的方式仍然未被探索。目前一些研究主要针对针对屏蔽语言模型,但是GPT这种结构差异,例如单向注意力和生成能力,为新的观点提供了方向。
我们使用了两种方法:
首先,我们使用因果干预分析来追踪GPT中隐藏状态激活的因果关系,以识别与主题事实相关的具体模块(图1)。我们的分析表明,在处理主题名称的最后一个字符时,一系列中间层的前馈MLP具有决定性作用(图1b,2b,3)。
其次,我们通过引入Rank-One Model Editing方法(ROME)来改变模型权重以测试这一发现,以更改确定决定性字符的前馈层行为的参数。尽管干预很简单,但我们发现ROME与标准zero-shot关系提取基准的其他建模方法相似(第3.2节)。
为了评估ROME对更困难案例的影响,我们引入了一个反事实断言的数据集(第3.3节),这是在训练集中尚未出现的。我们的评估(第3.4节)证明,中间层MLP模块可以存储具有较强泛化能力的事实,同时仍然和特定主题相关联。与以前的微调,基于可解释性和元学习方法相比,ROME同时实现了良好的泛化性和特异性,而先前的方法总会牺牲了其中一种。
2.Interventions on Activations for Tracing Information Flow
为了在较大预训练自回归transformer的参数中定位事实,我们首先分析和识别对单个事实预测具有强烈因果影响的特定隐藏状态。我们将每个事实表示为一个知识元组
t
=
(
s
,
r
,
o
)
t=(s,r,o)
t=(s,r,o),其中包含主题
s
s
s,目标
o
o
o和连接两者的关系
r
r
r。然后,为了引出GPT中的事实,我们提供了一个自然语言提示
P
P
P来描述
(
s
,
r
)
(s,r)
(s,r)并检查模型的预测
o
o
o。
自回归transformer语言模型
G
:
X
→
Y
G:\mathcal X→\mathcal Y
G:X→Y在词汇
V
\mathcal V
V上映射一个字符序列
x
=
[
x
1
,
.
.
.
,
x
T
]
∈
X
x=[x_1,...,x_T]∈\mathcal X
x=[x1,...,xT]∈X,其中
x
i
∈
V
x_i∈\mathcal V
xi∈V变换到
x
x
x中下一个连续字符的概率分布
y
∈
Y
⊂
R
∣
V
∣
y∈\mathcal Y⊂\mathbb R^{|V|}
y∈Y⊂R∣V∣。在transformer中,第
i
i
i个token被嵌入为一系列隐藏状态向量
h
i
(
l
)
h^{(l)}_i
hi(l),并从
h
i
(
0
)
=
e
m
b
(
x
i
)
+
p
o
s
(
i
)
∈
R
H
h^{(0)}_i=emb(x_i)+pos(i)∈\mathbb R^H
hi(0)=emb(xi)+pos(i)∈RH开始。最终的输出
y
=
d
e
c
o
d
e
(
h
T
(
L
)
)
y =decode(h^{(L)}_T)
y=decode(hT(L))是从最后一个隐藏状态读取的。
我们将
G
G
G内部隐藏状态
h
i
(
l
)
h^{(l)}_i
hi(l)的计算可视化为网格(图1a),其中每一层
l
(
l
e
f
t
→
r
i
g
h
t
)
l(left\rightarrow right)
l(left→right)添加了全局注意力
a
i
(
l
)
a^{(l)}_i
ai(l)和局部MLP
M
i
(
l
)
M^{(l)}_i
Mi(l),用于对上一层的输出进行计算。回想一下,在自回归情况下,当前字符仅从历史字符获取信息:
h
i
(
l
)
=
h
i
(
l
−
1
)
+
a
i
l
+
m
i
(
l
)
a
i
l
=
a
t
t
n
(
l
)
(
h
1
(
l
−
1
)
,
h
2
(
l
−
1
)
,
.
.
.
,
h
i
(
l
−
1
)
)
m
i
(
l
)
=
W
p
r
o
j
(
l
)
σ
(
W
f
c
(
l
)
γ
(
a
i
(
l
)
+
h
i
(
l
−
1
)
)
)
.
(1)
\begin{array}{cc} h^{(l)}_i=h^{(l-1)}_i+a^{l}_i+m^{(l)}_i\\ a^{l}_i=attn^{(l)}(h^{(l-1)}_1,h^{(l-1)}_2,...,h^{(l-1)}_i)\\ m^{(l)}_i=W^{(l)}_{proj}\sigma(W^{(l)}_{fc}\gamma(a^{(l)}_i+h^{(l-1)}_i)). \end{array}\tag{1}
hi(l)=hi(l−1)+ail+mi(l)ail=attn(l)(h1(l−1),h2(l−1),...,hi(l−1))mi(l)=Wproj(l)σ(Wfc(l)γ(ai(l)+hi(l−1))).(1)
每一层的MLP是由矩阵
W
p
r
o
j
(
l
)
W^{(l)}_{proj}
Wproj(l)和
W
f
(
l
)
c
W^{(l)}_fc
Wf(l)c参数化的双层神经网络,且具有修正非线性
σ
σ
σ和非线性归一化
γ
γ
γ。有关transformers的详细背景,请参考Vaswani et al. (2017)。
2.1 Causal Tracing of Factual Associations
状态网格(图1)构成了一个因果图,描述了隐藏变量之间的依赖性。该图包含许多从左侧的输入到右下输出的路径,我们希望了解到是否有特定的隐藏状态变量在召回事实时比其他变量更重要。
如Vig et al. (2020b) 所表明的,这是因果干预分析(causal mediation analysis)的自然场景,它量化了因果图中中间变量的贡献。为了计算每个状态对正确事实预测的贡献,我们进行三次运行以观察
G
G
G中的所有内部激活:(1)clean run,(2)corrupted run,(3)corrupted-with-restoration run。
- 在clean run中,我们将事实提示 x x x传递到 G G G中,并收集所有隐藏的激活 { h i ( l ) ∣ i ∈ [ 1 , T ] } \{h^{(l)}_i|i\in [1,T]\} {hi(l)∣i∈[1,T]}。图1a提供了一个提示的样例:“The Space Needle is in downtown __”,期望的输出是 o = o= o=“Seattle”。
- 在基线corrupted run中,该主题在运行网络 G G G之前需要进行混淆。具体地,将 x x x嵌入为 [ h 1 ( 0 ) , h 2 ( 0 ) , . . . , h t ( 0 ) ] [h^{(0)}_1,h^{(0)}_2,...,h^{(0)}_t] [h1(0),h2(0),...,ht(0)]后,我们对主题实体所对应索引 i i i上的嵌入设置 h i ( 0 ) : = h ( 0 ) i + ϵ h^{(0)}_i:=h^{(0)}i+ϵ hi(0):=h(0)i+ϵ,其中 ϵ ∼ N ( 0 ; v ) \epsilon\sim\mathcal N(0;v) ϵ∼N(0;v)。 然后正常运行 G G G,从而得到一组破坏的激活 { h i ∗ ( l ) ∣ i ∈ [ 1 , L ] , l ∈ [ 1 , L ] } \{h^{(l)}_{i*}|i\in[1,L],l\in[1,L]\} {hi∗(l)∣i∈[1,L],l∈[1,L]}。由于G失去了一些有关主题的信息,因此它可能会返回错误的答案(图1b)。
- 在corrupted-with-restoration run中,类似于corrupted run,除了一些token i ^ \hat i i^和层 l ^ \hat l l^,令 G G G在噪声嵌入上进行计算。在那里,我们勾住G,以迫使它后续输出干净的状态 h i ^ ( l ) h^{(l)}_{\hat i} hi^(l)。未来的计算的执行则无需进一步干预。直观地,尽管有许多其他状态被混淆的主题破坏了,但少数干净状态对恢复正确事实的能力将表明它们在计算图中的因果重要性。
令 P [ o ] \mathbb P[o] P[o], P ∗ [ o ] \mathbb P_∗[o] P∗[o]以及 P ∗ , c l e a n h i ( l ) [ o ] \mathbb P_{*,clean~h^{(l)}_i}[o] P∗,clean hi(l)[o]分别表示在干净,破坏和破坏加恢复情况下输出 o o o的概率。上述表示为了简单,省略了输入 x x x的符号。total effect (TE)是这些值之间的差异: T E = P [ o ] − P ∗ [ o ] TE=\mathbb P[o]-\mathbb P_∗[o] TE=P[o]−P∗[o]。特定干预状态 h i ( l ) h^{(l)}_i hi(l)的indirect effect(IE) 被定义为破坏版本下 o o o的概率与该状态设置为干净版本时 o o o概率之间的差异,同时该主题仍然被破坏: I E = P ∗ , c l e a n h i ( l ) [ o ] − P ∗ [ o ] IE=\mathbb P_{∗,clean~h^{(l)}_i}[o]-\mathbb P_∗[o] IE=P∗,clean hi(l)[o]−P∗[o]。对语句样本进行平均,我们就获得了每个隐藏状态变量的平均总效应(ATE)和平均间接效应(AIE)。
2.2 Causal Tracing Results
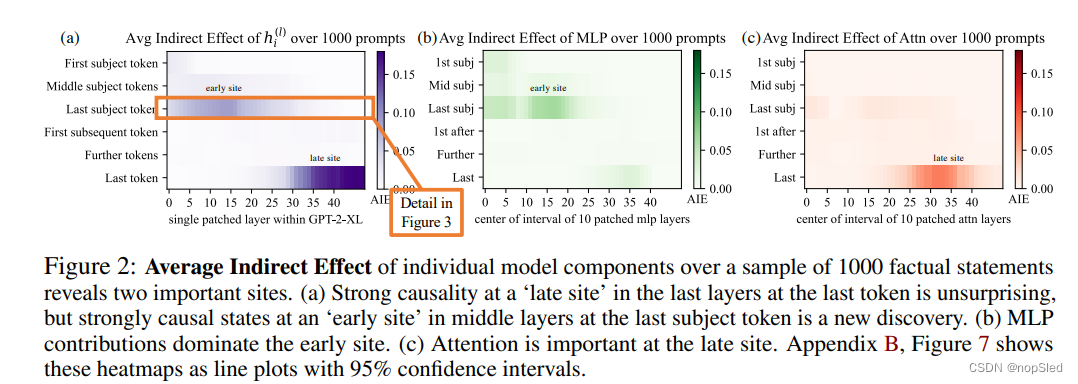
我们通过改变句子中的不同位置和不同的模型组件(包括各个状态,MLP层和注意力层)的干预,计算了超过1000个事实语句的平均间接效应(AIE)(附录B.1中的详细信息)。图2绘制了GPT-2 XL(1.5B参数)内部的AIE。该实验的ATE为18.6%,我们注意到,很大一部分效应是由最后一个主题字符上的因果状态导致的(15层的AIE=8.7%)。在最后一个主题字符存在较强的因果状态并不奇怪,但是它们出现在该主题最后一个字符的前几层是一个新发现。
通过分解MLP和注意力模块贡献的因果关系(图1 fg和图2 bc)表明,前面几层的MLP模块起决定性作用:MLP贡献峰值为6.6%,而最后一个主题字符的注意力效应仅为AIE 1.6%。在提示的最后一个字符上,注意力更为重要。附录B.2进一步讨论了这种分解。
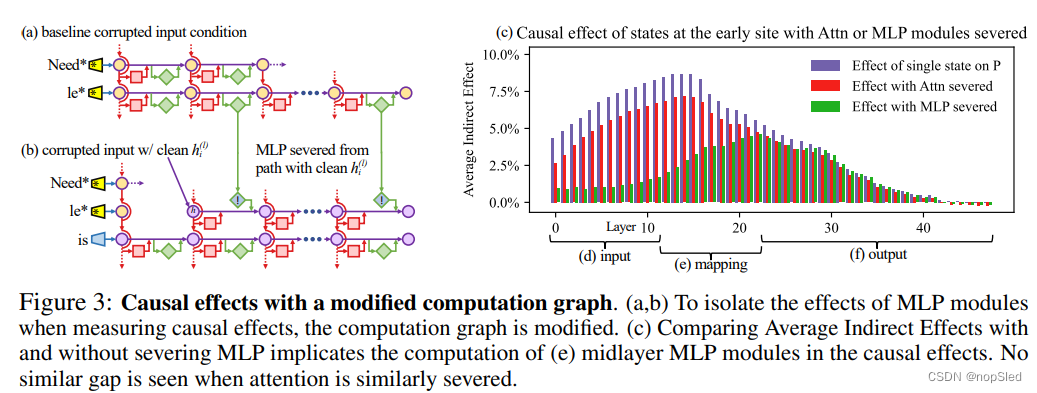
最后,为了更清楚地了解MLP层在前面几层的特殊作用,我们使用一个修改的因果图分析了间接效应(图3):(a)首先,我们在基线条件下使用破坏的输入收集了每个MLP模块的贡献。(b)然后,为了隔离MLP模块在测量因果效应时的效果,我们将计算图修改以切断字符
i
i
i处MLP的计算,并在基线损坏的状态下固定它们,以免它们受到感觉状态
h
i
(
l
)
h^{(l)}_i
hi(l)插入的影响。这种修改是一种避免MLP计算的探测path-specific effect的一种方法。(c)将修改图中的平均间接效应与原始图中的平均间接效应进行比较,我们观察到(d)在没有激活未来MLP模块时,最低层失去了因果效应,而(f)较高层状态的效应很少取决于MLP。当切断注意力模块以进行比较时,啧没有看到这种过渡。该结果证实了(e)MLP模块在回忆事实时起重要作用。
附录B展示了在其他自回归模型和实验设置上具有相似的结果。特别是,我们发现因果追踪比基于梯度的方法(例如integrated
gradients)更具信息性(图16),并且在不同的噪声配置下是可靠的。
因此问哦们认为部分中间层的MLP具有召回主题事实的能力。
2.3 The Localized Factual Association Hypothesis
基于因果追踪,我们提出了一种用于存储事实的特定机制:每个中间层的MLP模块接受编码了主题的输入,然后产生输出,从而召回有关该主题的属性。中层MLP的输出积累信息,然后通过高层注意力将信息求和复制到最后一个字符。
该假设将事实沿三个维度定位,将事实存储在(i)MLP模块的(ii)特定层,特别是(iii)在主题最后一个字符的处理中。这与Geva et al. (2021) 认为MLP存储知识的观点一致,而Elhage et al. (2021) 研究显示了自注意力的信息复制作用。此外,Zhao et al. (2021) 发现可以与行为的最小变化交换transformer层顺序。也就是说,在中间范围内的单个层的特定选择或布置没有其他特殊作用。我们猜想,任何事实都可以等效地存储在任何中间MLP层中。为了检验我们的假设,我们将关注点缩小到中间层
l
∗
l^∗
l∗的单个MLP模块,并查看是否可以显式修改其权重以存储任意事实。
3.Interventions on Weights for Understanding Factual Association Storage
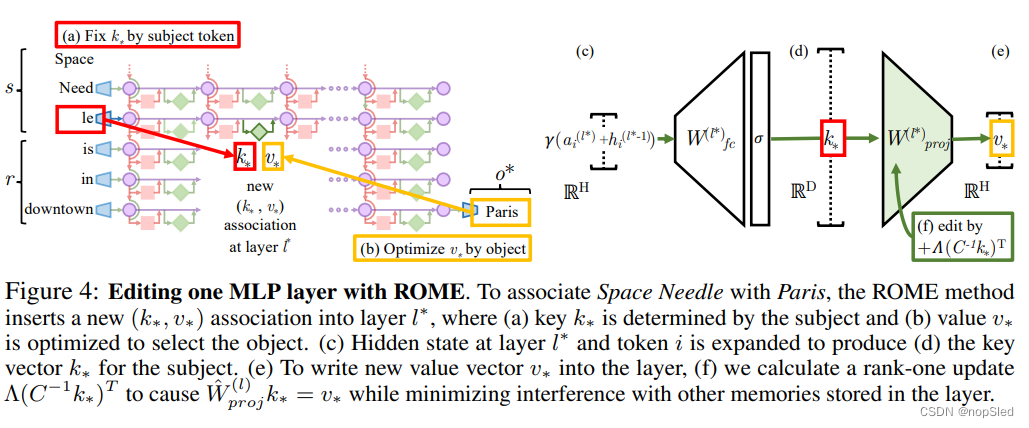
尽管因果追踪发现了MLP模块负责召回事实,但我们也希望更进一步了解如何将事实存储在MLP权重中。Geva et al. (2021) 观察到MLP层(图4 cde)可以作为两层的键-值存储器,其中第一层
W
f
c
(
l
)
W^{(l)}_{fc}
Wfc(l)的神经元形成一个键,第二层
W
p
r
o
j
(
l
)
W^{(l)}_{proj}
Wproj(l)检索该键关联的值。我们假设MLP可以建模为线性关联存储器。请注意,这与Geva等人的per-neuron观点不同。
我们通过进行一项新的干预方式来检验这一假设:使用Rank-One Model Editing (ROME)来修改事实。其能够插入一个新的知识元组
t
∗
=
(
s
,
r
,
o
∗
)
t^∗=(s,r,o^∗)
t∗=(s,r,o∗)以代替当前元组
t
c
=
(
s
,
r
,
o
c
)
t^c=(s,r,o^c)
tc=(s,r,oc),同事具有泛化性和特异性,这能够证明关联存储机制的细粒度理解。
3.1 Rank-One Model Editing: Viewing the Transformer MLP as an Associative Memory
我们将
W
p
r
o
j
(
l
)
W^{(l)}_{proj}
Wproj(l)看作线性关联存储器。从该视角可以观察到,任何线性操作
W
W
W可以作为使用一组键向量
K
=
[
k
1
∣
k
2
∣
.
.
.
]
K=[k_1|k_2|...]
K=[k1∣k2∣...]和对应值向量
V
=
[
v
1
∣
v
2
∣
.
.
.
]
V=[v_1|v_2|...]
V=[v1∣v2∣...]的键值存储操作,以求解
W
K
≈
V
WK≈V
WK≈V,其均方误差使用Moore-Penrose pseudoinverse来最小化:
W
=
V
K
+
W=VK^+
W=VK+。Bau et al. (2020) 观察到,可以通过求解约束最小二乘问题来最优地插入新的键-值对
(
k
∗
,
v
∗
)
(k_*,v_*)
(k∗,v∗)。在卷积网络中,Bau等人使用该优化解决此问题,但是在全连接层中,我们可以得出一个闭式解:
m
i
n
i
m
i
z
e
∣
∣
W
^
K
−
V
∣
∣
s
u
c
h
t
h
a
t
W
^
k
∗
=
v
∗
b
y
s
e
t
t
i
n
g
W
^
=
W
+
Λ
(
C
−
1
k
∗
)
T
.
(2)
minimize~||\hat WK-V||~such~that~\hat Wk_*=v_*\quad by~setting~\hat W=W+Λ(C^{-1}k_*)^T.\tag{2}
minimize ∣∣W^K−V∣∣ such that W^k∗=v∗by setting W^=W+Λ(C−1k∗)T.(2)
其中
W
W
W是原始矩阵,
C
=
K
K
T
C=KK^T
C=KKT是一个常数,我们通过估算来自Wikipedia文本样本的
k
k
k的协方差(附录E.5),且
Λ
=
(
v
∗
−
W
k
∗
)
/
(
C
−
1
k
∗
)
T
k
∗
Λ=(v_∗-Wk_∗)/(C^{-1}k_*)^Tk_*
Λ=(v∗−Wk∗)/(C−1k∗)Tk∗是原始存储矩阵上与新键-值对的残差成正比的矢量(完整推导可查看附录A)。由于这种简单的代数结构,我们可以直接插入任何事实
(
k
∗
,
v
∗
)
(k_*,v_*)
(k∗,v∗)。剩下的就是选择适当的
k
∗
k_*
k∗和
v
∗
v_*
v∗。
Step 1: Choosing k∗ to Select the Subject。
Step 2: Choosing v∗ to Recall the Fact。
Step 3: Inserting the Fact。

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









