






 作者:haha alalala
作者:haha alalala
论文:Locating and Editing Factual Associations in GPT
链接:https://arxiv.org/abs/2202.05262
背景
以Transformer为架构的生成大模型,成为了NLP领域的主流,具有媲美人类的对话能力,显示出了卓越的事实生成效果。随之而来的问题是,大模型的工作原理是什么?大模型将这些事实存储在哪里?它是如何利用这些事实的?这篇论文尝试通过“causal intervention”去定位事实的位置,并尝试对事实进行修改。
本文的工作
这篇论文的工作分为两部分:事实定位以及事实修改
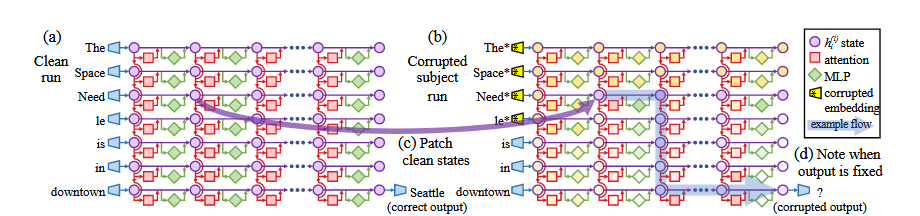
事实定位:通过三次不同的运行,确定不同参数部分对于事实预测的影响贡献。
纯净运行:不对s,r构成的输入进行修改,并对运行时的hidden states的激活进行记录。
污染运行:在输入后添加一个噪音,然后收集这个运行时hidden states的激活情况。
污染后恢复运行:同样在输入后加入一个噪音,该噪音于污染运行时的相同。但是将某些hidden states恢复到纯净时的激活状态。
将一个事实预测表示为三元组(s,r,o)主体,关系,客体。将s,r表示为一句话作为模型的输入去预测事实o。从而实现对事实的预测。
模型的内部计算可以看作
准备工作
三次运行:纯洁运行,污染运行,污染后恢复运行
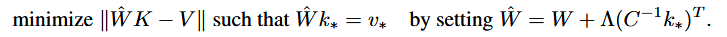
通过污染后恢复运行即可筛选出对事实影响最大的隐藏状态。
事实修改
“A mathematical framework for transformer circuits.” 一文中观察到,MLP层被视为两层的key- value记忆。
“Rewriting a deep generative model”这篇论文中,可以通过解决受限的最小二乘法问题,将key-value对插入到记忆中。
相关工作
ROME:即参考相关工作2,构造 ,将事实插入到模型中。训练时,对定位到的事实区域进行训练,其他部分冻结。
实验分析
事实定位
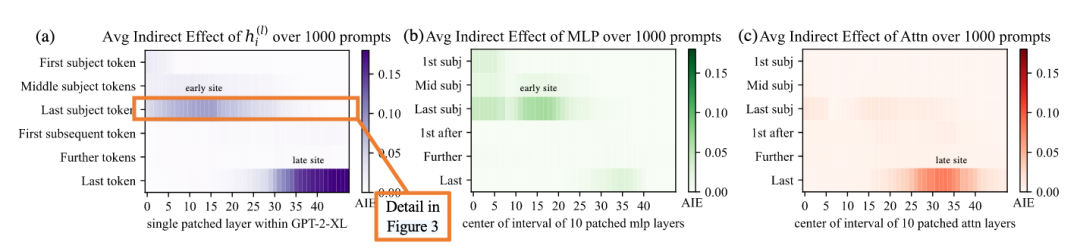
图a中展示,对于所有的隐藏状态来看,发生强烈的因果影响(causal effects)的位置在主体词的最后一个token的早期位置,和预测前的最后一个token晚期位置。
对于MLP部分来说,大部分的因果影响发生在最后一个主体词的早期位置。
对于注意力部分来说,大部分的因果影响发生在最后一个token的晚期位置。
指标
Total Effect(TE):,计算纯净版本和污染版本的量化差别。
Indirect Effect(IE):,计算恢复版本和污染版本的量化差别。
其中分别指在纯净模式,污染模式,和l层第i个token被恢复后预测出事实o第概率。
Average Indirect Effect (AIE)为上面的平均值,用来衡量不同隐藏状态对于结果的影响大小。
分析
 注:这里的prompt就是输入。y轴从上到下是对输入补全后句子的token序列。x轴是模型的深度。
注:这里的prompt就是输入。y轴从上到下是对输入补全后句子的token序列。x轴是模型的深度。猜想:中间层的mlp接受来自输入的编码,然后生成关于主题词的回忆的输出,然后由中间层的mlp对这些信息进行积累,最后通过高层之以利将总的信息复制到最后一个token。
事实修改
数据集:编写了一个错误事实的数据集 ),相对于原来的正确事实 在纯净模式具有更低的得分。
指标
Efficacy:编辑后,预测实体的能力(即),判断修改的成功。
Generalization:对重写后的输入(即将s,r表述为另一句话)后的判断模型是否依旧能够理解。依旧计算。
Specificity:判断对其他事实是否依旧有效,即 是否依旧为真。也就是说判断编辑事实是否会影响到没有被编辑的事实。
实验结果
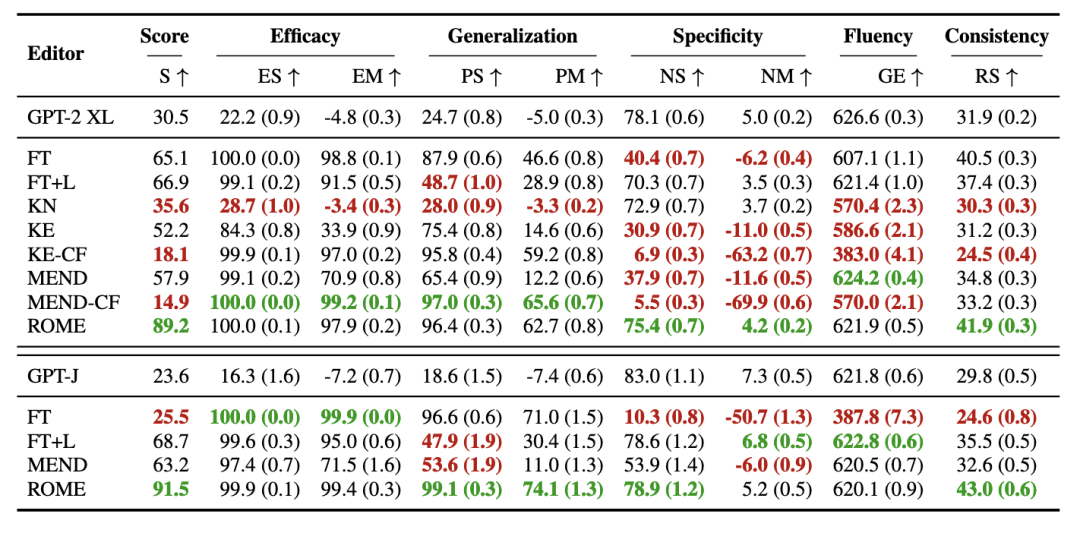
 注:ES为得分,即 的百分比;EM为 的均方差。
注:ES为得分,即 的百分比;EM为 的均方差。观察上面的图片可知,对于微调方法(FT)和其他知识编辑方法(KE,MEND)在两个模型的实验上,都不能达到很好的综合性能:这些方法在Efficacy(事实修改后的预测能力)和Generalization(输入重写预测能力,也可以理解为语义理解能力)都可以达到不错的成绩,但是Specificity(事实编辑后不影响其他事实的能力)却很差,也就是说这些微调和知识编辑的方法,修改事实是以影响其他事实为代价的。而ROME方法在不同的指标下都表现均衡。
局限性
ROME一次只能编辑单个事实,很难应用于大规模模型。编辑是有方向的入:“The iconic landmark in Seattle is the Space Needle”,“The Space Needle is the iconic landmark in Seattle”为两句话,修改时需要编辑两次。计算模型存储的事实被改变了,模型也能呢猜测新的事实,并且猜测可能是错误的。
这是否也可以看作一种微调?
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









