






 文章介绍了对GPT-3进行微调以提升基于文本的Web问答性能的研究。通过模仿学习和强化学习,模型在ELI5数据集上表现优于人类演示,并在TruthfulQA上展示出高真实性和信息丰富度。研究创建了一个Web浏览环境,允许模型搜索和收集参考以支持答案,优化了信息检索和生成的结合。
文章介绍了对GPT-3进行微调以提升基于文本的Web问答性能的研究。通过模仿学习和强化学习,模型在ELI5数据集上表现优于人类演示,并在TruthfulQA上展示出高真实性和信息丰富度。研究创建了一个Web浏览环境,允许模型搜索和收集参考以支持答案,优化了信息检索和生成的结合。
摘要
我们对GPT-3进行微调,以使用基于文本的Web浏览环境来回答长格式的问题,该环境允许模型搜索并浏览web。通过对该任务进行设置,以便其可以由人工执行,然后我们可以使用模仿学习来在该任务上训练模型,并通过人类反馈来优化答案质量。 为了使人类对事实准确性的评估更加容易,模型必须在浏览的同时收集参考以支持其答案。我们在ELI5上训练和评估我们的模型,这是Reddit用户提出的问题的数据集。我们的最佳模型是通过使用行为克隆对GPT-3进行微调获得的,然后基于被训练用于预测人类偏好的奖赏模型来执行拒绝采样。该模型的答案有56%要优于人类演示,有69%要由于Reddit上的高投票答案。
1.介绍
NLP中的一个不断增长的挑战是长篇问答(LFQA),其中给定一个开放领域的问题,然后生成一个篇章级的答案。LFQA系统有可能成为人们学习世界知识的主要方式之一,但目前仍落后于人类性能。现有的工作倾向于关注任务的两个核心组成部分,即信息检索和生成。
在这项工作中,我们利用现有的方案实现这些组件:我们利用Microsoft Bing Web Search API来进行文档检索,并利用无监督预训练来微调GPT-3以实现高质量的生成。我们没有尝试改善这些组件,而是专注于使用更可靠的训练目标将它们结合在一起。与Stiennon et al. [2020]类似,我们直接使用人类反馈来优化答案质量,从而使我们能够实现与人类相当的性能。
我们主要有两个关键贡献:
- 我们创建了一个基于文本Web浏览环境,可以与该环境进行交互来微调语言模型。这使我们能够使用诸如模仿学习和强化学习之类的通用方法以端到端的方式改善检索和生成。
- 模型在浏览时从网页中提取段落来生成具有参考的答案。这对于标注人员判断答案的事实准确性至关重要,而无需进行独立的困难和主观过程的研究。
我们的模型通过训练来回答ELI5的问题,这是一个从“Explain Like I’m Five” Subreddit中提取的问题数据集。我们还收集了另外两种数据:使用我们的Web浏览环境来回答问题的人类演示,以及基于同一答案在两个模型生成的答案之间进行的比较(每一个模型都有自己的参考集)。答案是根据其事实准确性,连贯性和整体实用性来判断的。
我们以三种主要方式使用这些数据:(1)基于演示数据的行为克隆(即有监督微调),(2)使用比较数据进行奖赏建模,然后基于奖赏模型的强化学习,(3)针对奖励模型的拒绝采样。我们的最佳模型结合了行为克隆和拒绝采样。当推理时间的计算更加有限时,我们还发现强化学习可以提供一些增益。
我们以三种不同的方式评估我们的最佳模型。首先,我们将模型与人类在一系列问题集上回答的答案进行比较。我们的模型有56%要优于人类演示。其次,我们将模型的答案与ELI5数据集提供的高投票答案进行了比较,有69%要优于高投票答案。第三,我们在TruthfulQA上评估了我们的模型,该数据集是短篇问答的对抗数据集。我们的模型的答案有75%是真实的,有54%是真实且信息丰富的,这超过我们的基本模型(GPT-3),但仍弱于人类性能。
本篇文章的剩余部分内容如下:
- 在第2节,我们描述了我们的基于文本的web浏览环境,以及我们的模型如何与其交互。
- 在第3节,我们详细阐述了我们数据收集和训练方法。
- 在第4节,我们在ELI5和TruthfulQA上评估了我们的最优模型。
- 在第5节,我们提供了我们不同方法的比较结果以及他们随数据大小,模型参数以及推理时间的变化。
- 在第6节,我们讨论了我们训练模型过程中的发现,包括答案的真实性以及更广泛的影响。
2.环境设计

先前关于问答的工作(例如REALM和RAG)都致力于改善给定问题的文档检索能力。相反,我们则使用一个成熟的现有方法:搜索引擎(Bing)。这有两个主要优势:首先,搜索引擎已经非常强大,能检索到大量最新的文档。其次,它使我们能够专注于使用搜索引擎回答问题的高级任务,这是人类可以做得很好的事情,并且语言模型可以进行模仿。
对于这种方法,我们设计了一个基于文本的Web浏览环境。使用当前环境状态的摘要来提示语言模型,其中包括问题,处于当前滚动条位置的页面内容,以及一些其它信息(图1(B))。为此,该模型必须选择表1中列出的命令之一,该命令会执行诸如运行Bing搜索,点击链接或滚动的操作。然后以刷新的上下文重复此过程(因此,上一个步的记忆被记录在摘要中)。
当模型在浏览时,它可以采取的操作之一是引用当前页面的摘录。执行此操作后,该页面的标题,领域名以及摘录都被作为参考。然后继续进行浏览,直到模型发出命令以结束浏览,或达到最大动作数以及最大参考总长度。因此,只要至少有一个参考,该模型就会使用该问题和参考进行提示,然后组合最终答案。
有关我们环境的技术细节可参考附录A。


3.方法
3.1 Data collection
来自人类的引导对于我们的方法至关重要。在自然语言上进行预训练的语言模型无法使用我们的基于文本的浏览器,因为它不知道有效命令的格式。因此,我们使用浏览器收集了人类回答问题的例子,我们称之为演示数据。但是,仅对演示的训练并不能直接优化答案质量,并且不太可能超越人类的表现。因此,我们收集了对同一问题的两个不同模型生成的答案,并询问人类喜欢哪一个,我们称之为比较数据。
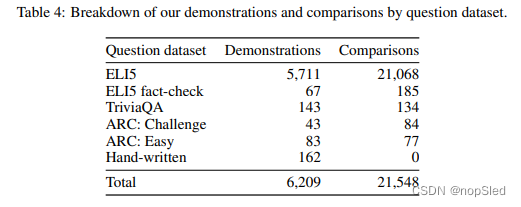
对于演示数据和比较数据,绝大多数问题都是从ELI5(长格式问题的数据集)中提取的。为了数据多样性并实验,我们还将来自TriviaQA等其他源的小部分问题混合在一起。我们总共收集了大约6,000条演示数据,其中92%是来自ELI5的问题;比较数据大约有21500条,其中98%来自ELI5的问题。可以在附录B中找到我们使用的问题以及后处理细节。
为了使人类更方便提供演示数据,我们为环境设计了图形用户界面(请参见图1(a))。它显示与基于文本的界面基本相同的信息,并允许执行任何有效的操作,并且对人类更友好。对于比较数据,我们设计了类似的界面,允许提供辅助标注以及提供比较等级,尽管仅在训练中使用了最终比较评级(更好,更糟或同样好)。
对于演示和比较数据,我们强调答案应具有可信赖的参考文献,并且连贯和支持。有关这些标准和数据收集的其他方面的更多详细信息可以在附录C中找到。
我们开源了比较数据,该数据的细节可在附录C找到。
3.2 Training
预训练模型的使用对我们的方法至关重要。成功使用我们的环境回答问题需要许多基本功能,例如阅读理解和答案生成,以及语言模型的zero-shot功能。因此,我们微调来自GPT-3模型家族中的模型,分别是760M,13B和175B大小。从这些模型开始,我们使用了四种主要的训练方法:
- Behavior cloning (BC)。我们使用有监督学习在演示数据上进行微调。
- Reward modeling (RM)。从移除了最后一个非嵌入层的BC模型开始,我们训练了一个模型,其以问题和带有参考的答案作为输入,并输出标量奖赏。类似Stiennon et al. [2020],奖赏表示一个ELo分数,其通过缩放使得两个分数之间的差异能表示一个结果优先于另一个的概率。奖赏模型是使用交叉熵损失训练的,并将比较结果作为标签。
- Reinforcement learning (RL)。再一次使用Stiennon et al. [2020]的方法,我们使用PPO算法在环境中微调BC模型。对于环境奖赏,我们选择每个episode结束时奖赏模型的分数,并添加了一个来自BC模型的每一个token的KL惩罚,以缓解奖赏模型的过度优化。
- Rejection sampling (best-of-n)。我们从BC模型或RL模型采样了一组固定数据的答案(4,16或64),并使用奖赏模型来获取具有最高得分的答案。这是一种使用奖赏模型进行优化的可选方案,其不需要额外的训练,但是需要更多的推理时间。
我们手工拆分了不同方法的数据集。所有训练方法的超参数可以在附录E汇总发现。



















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









