







Semantic Parsing on Freebase from Question-Answer Pairs
2013 EMNLP 语义解析
方法:通过对自然语言进行语义上的分析,转化成为一种能够让知识库看懂的语义表示
步骤:
1.词汇映射:即构造底层的语法树节点。将单个自然语言短语或单词映射到知识库实体或知识库实体关系所对应的逻辑形式。我们可以通过构造一个词汇表(Lexicon)来完成这样的映射。
2.构建:即自底向上对树的节点进行两两合并,最后生成根节点,完成语法树的构建。这一步有很多种方法,诸如构造大量手工规则,组合范畴语法(Combinatory Categorical Grammars,CCG)等等。
1.词汇表的构建
2.桥接操作
3.分类器
Information Extraction over Structured Data: Question Answering with Freebase
2014 ACL 信息抽取 F1-score 42.0
方法:该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案。通过观察问题,依据某些规则或模板进行信息抽取,得到表征问题和候选答案特征的特征向量,建立分类器,通过输入特征向量对候选答案进行筛选,从而得出最终答案。
步骤:
1.通过问题的主题词,在知识库当中确定一个子图,作为候选答案。
2.对问题进行抽取
对问题进行依存分析得到 问题->依存树
对问题进行信息抽取 依存树->问题树
3.特征
问题特征:问题图中的每一条边e(s,t),抽取4种问题特征:s,t,s|t,和s|e|t。
候选答案特征:对于主题图中的每一个节点,我们都可以抽取出以下特征:该节点的所有关系(relation,记作rel),和该节点的所有属性(property,如type/gender/age)。
问题-候选答案特征:每一个问题-候选答案特征由问题特征中的一个特征和候选答案特征中的一个特征,组合(combine)而成(组合记作 | )。我们希望一个关联度较高的问题-候选答案特征有较高的权重,比如对于问题-候选答案特征 qfocus=money|node type=currency(注意,这里qfocus=money是来自问题的特征,而node type=currency则是来自候选答案的特征),我们希望它的权重较高,而对于问题-候选答案特征qfocus=money|node type=person我们希望它的权重较低。
4.分类器
关系R和整个问题Q的关联度,可表示为概率的形式P(R|Q)。那么这个概率如何求解呢?朴素贝叶斯求概率方式。
总结:
我们已知的情报:QA对,知识图谱,求问题与知识图谱当中哪个边相似最大
再此,我们通过求导问题特征与知识图谱边(问题-候选答案特征)的相关性,通过此相关性指引出问题对应的答案。
Question answering with subgraph embeddings
2014 EMNLP 向量建模 F1-score 39.2
向量建模方法的思想和信息抽取的思想比较接近。首先根据问题中的主题词在知识库中确定候选答案。把问题和候选答案都映射到一个低维空间,得到它们的分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题向量和它对应的正确答案向量在低维空间的关联得分(通常以点乘为形式)尽量高。
步骤:
1.通过问题的主题词,在知识库当中确定一个子图,作为候选答案。
2.问题向量化:
通过词袋模型把问题向量化表示,用矩阵W将N维的问题向量映射到k维的低维空间
把候选答案在图中的节点和边向量化表示,用矩阵W将问题向量映射到k维的低维空间
3.向量得分
最后我们用一个函数表征答案和问题的得分,我们希望问题和它对应的正确答案得尽量高分,通过比较每个候选答案的得分,选出最高的,作为正确答案。得分函数定义为二者分布式表达的点乘。
Question Answering over Freebase with Multi-Column Convolutional Neural Networks
2015 ACL 向量建模Multi-Column卷积神经网络 F1-score:40.8
问题向量,词袋模型没有考虑单词的顺序
答案向量,通过multi-hot模型不能很好区分答案的特征
步骤:
1.通过卷积神经网络压缩问题
2.问题特征,分别用三个特征表示即答案路径(Answer Path),答案上下文信息(Answer Context),答案类型(Answer Type),对于每一个答案特征向量,都用一个卷积网络去对问题进行特征提取,将提取出的分布式表达和该答案对应特征向量的分布式表达进行点乘,这样我们就可以得到一个包含三部分的得分函数:
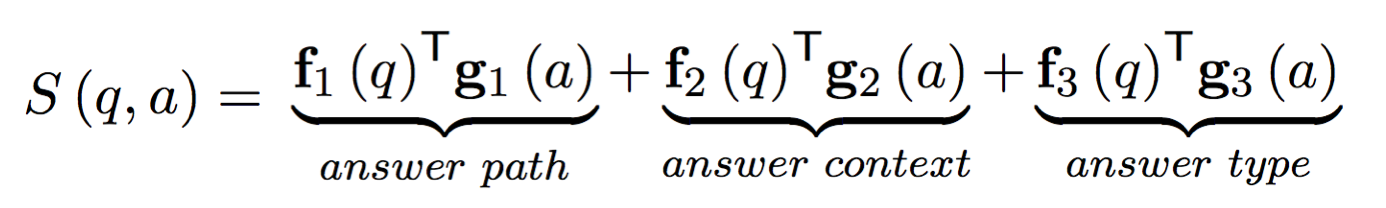
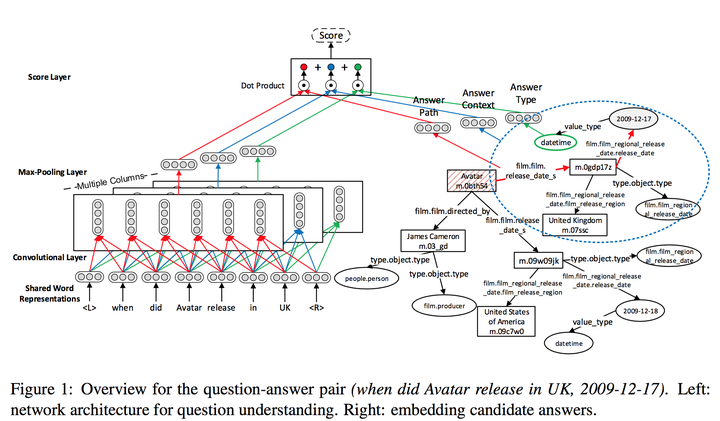
Semantic Parsing via Staged Query Graph Generation:Question Answering with Knowledge Base
2015 ACL 语义解析+查询图+深度学习 F1-score 52.5
把语义解析转化成一个查询图
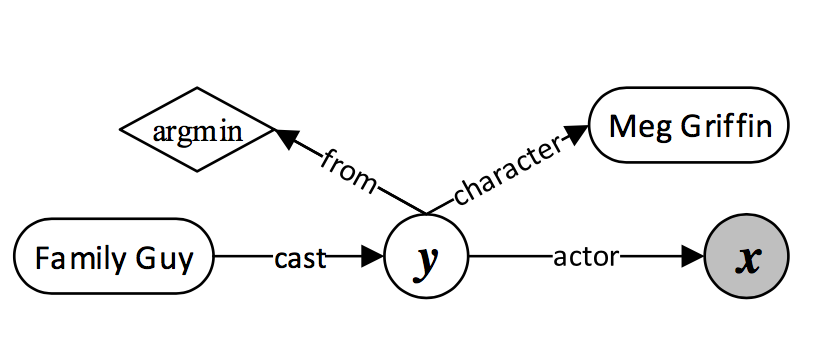
通过有限状态机,实现查询图的生成
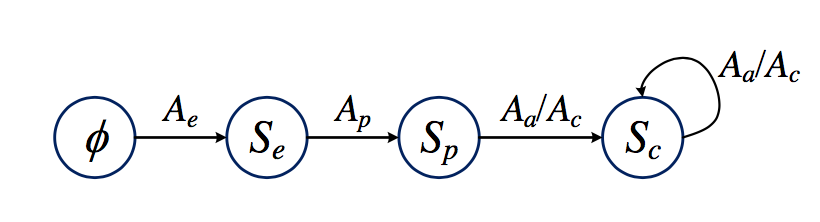
查询图的每个状态,通过9个维度给该状态打分
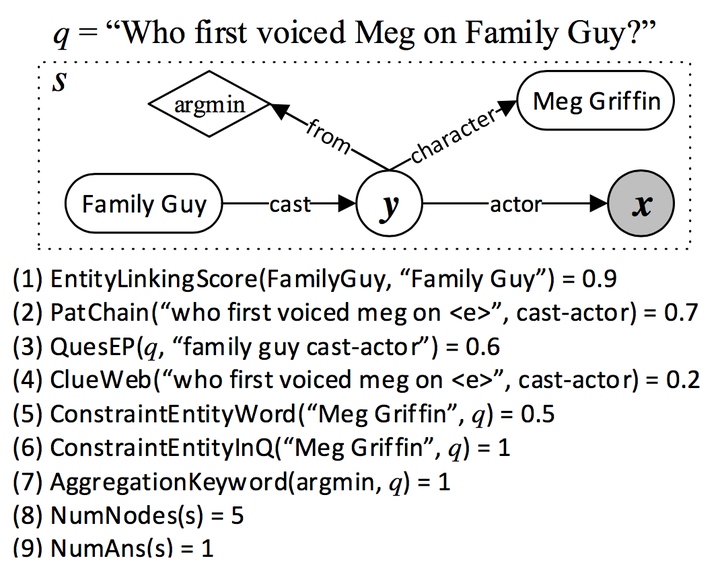
通过得分最高的状态,执行查询
总结:
把关系查找过程映射成了一个查询图生成过程,保留得分最高的查询图。
Large-scale Simple Question Answering with Memory Networks
通过记忆网络实现问答
Neural Machine Translation by Jointly Learning to Align and Translate
2016 arxi bi-lstm+Attention+GKI(TransE训练实体embeding) F1-Score 42.6
1.将候选答案转化为分布式表达
我们从多个方面考虑答案的特征:答案实体、答案上下文环境(知识库中所有与答案实体直接相连的实体)、答案关系(答案与问题主题词之间的实体关系)、答案类型。
2.将自然语言问题转化为分布式表达
将问句中的每一个单词经过Embedding矩阵E_w转化成word-embedding,使用双向LSTM(bi-LSTM)提取问句特征。bi-LSTM第j时刻的输出记作h_j,使用bi-LSTM的好处在于h_j既包含了第j个单词之前的信息,又包含了该单词之后的信息。
3.在得分函数中引入注意力机制
我们希望我们问句的分布式表达对于四种不同的答案特征有不同的表达(根据答案的特征对于问题有不同的关注点),第i种答案的分布式表达e_i 对应的问句分布式表达记作q_i,我们的得分函数定义为四种对应表达的点乘之和。
答案实体、答案上下文环境(知识库中所有与答案实体直接相连的实体)、答案关系(答案与问题主题词之间的实体关系)、答案类型
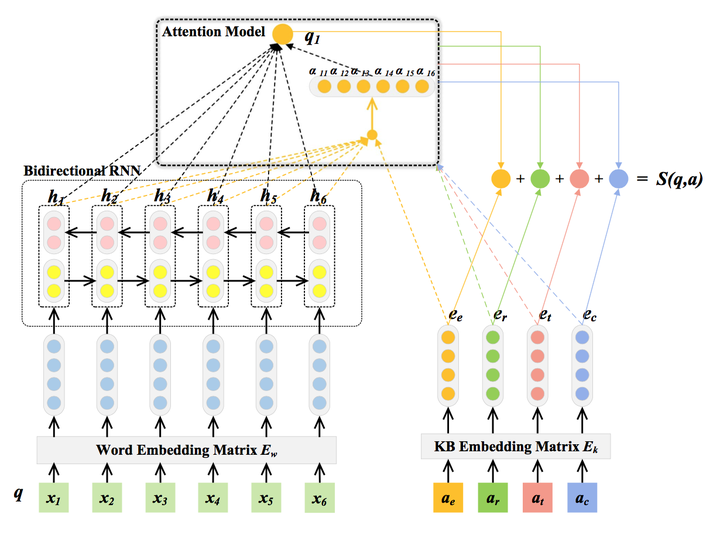
总结:
采取Attention机制,4个不同的答案特征,会根据自己的特点选取问题的特征,所以产生问题的网络可以只有一个。
比较之前的Question Answering over Freebase with Multi-Column Convolutional Neural Networks
由于答案选取3个特征,所以有三个卷积神经网络压缩问题特征与答案特征相匹配。














 3546
3546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









