







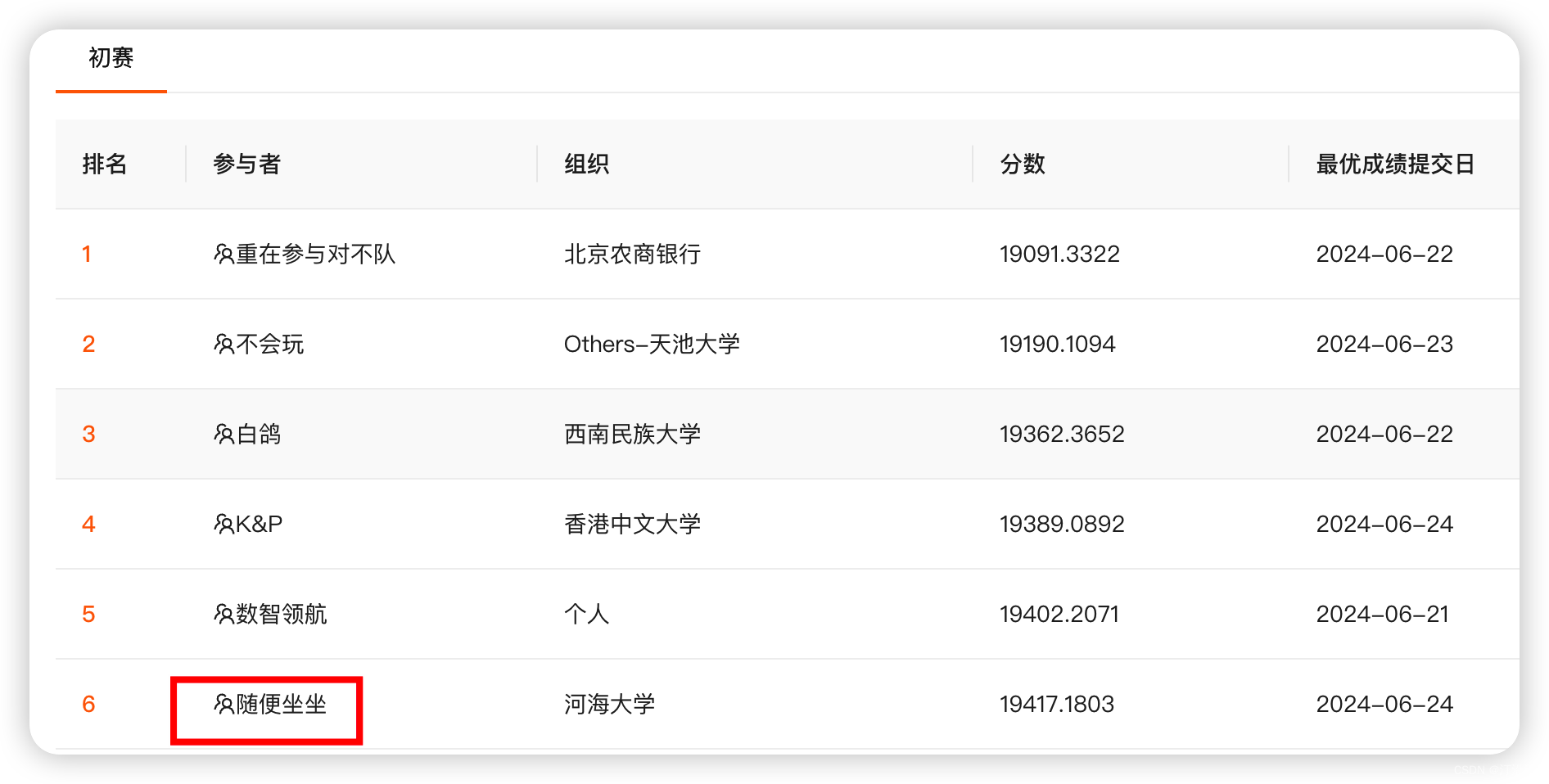
这部分代码也是目前在比赛(第三届“数智港航”数据创新应用大赛——算法模型赛道“船舶装卸货量预测”)中使用的代码,目前名次在top6。
第三届“数智港航”数据创新应用大赛——算法模型赛道“船舶装卸货量预测”_算法大赛_天池大赛-阿里云天池的排行榜
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import lightgbm as lgb
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
from sklearn.metrics import mean_squared_error
import numpy as np
# 导入catboost
from catboost import CatBoostRegressor
from xgboost import XGBRFRegressor
# 随机森林库
from sklearn.ensemble import RandomForestRegressor
# 导入lightGBM
import lightgbm as lgb
# 引入stacking模型融合(cv)
from mlxtend.regressor import StackingCVRegressor
from sklearn.linear_model import LinearRegression
# 加载训练数据
.....
# 读取模型
# 基模型1
xgb_params={
'booster':'gbtree',
'n_estimator':2000,
'objective': 'reg:squarederror', #
'gamma':10, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth':4, # 构建树的深度,越大越容易过拟合
'lambda':5, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample':0.7, # 随机采样训练样本
'colsample_bytree':0.7, # 生成树时进行的列采样
'min_child_weight':5,
# 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言
#,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
#这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
'silent':0 ,#设置成1则没有运行信息输出,最好是设置为0.
'learning_rate': 0.01, # 如同学习率
'seed':1000,
'nthread':7,# cpu 线程数
'eval_metric': 'rmse'
}
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression', # tweedie # regression, poisson
'metric': 'rmse',
'min_child_weight': 5,
'num_leaves': 2 ** 5,
'lambda_l2': 0.3,
'alpha':0.1,
'feature_fraction': 0.5,
'bagging_fraction': 0.7,
'bagging_freq': 4,
'learning_rate': 0.01,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
# 'device':'gpu'
}
LGBMR_BEST_PARAMS = lgb.LGBMRegressor(**lgb_params)
# 基模型2
cat_params= {'iterations': 1500,
'learning_rate': 0.01,
'depth': 11,
'l2_leaf_reg': 0.006126980082076129,
'rsm': 0.42416637312752437,
'border_count': 173,
'leaf_estimation_method': 'Simple',
'boosting_type': 'Ordered',
'bootstrap_type': 'MVS',
'sampling_unit': 'Object'}
CATBOOST_BEST_PARAMS = CatBoostRegressor(**cat_params)
# 基模型3
RF = RandomForestRegressor()
xgb = XGBRFRegressor(**xgb_params)
# 元回归器, 这个可以理解为第二层的那个模型,即将前面回归器结果合起来的那个回归器,这里我使用lr,因为第二层的模型不要太复杂
lr=LinearRegression()
# 基模型列表
regressorModels = [ LGBMR_BEST_PARAMS,CATBOOST_BEST_PARAMS, RF,xgb]
# 使用stackingCV融合
STACKING=StackingCVRegressor(regressors=regressorModels,meta_regressor=lr,cv = 5,shuffle = True,use_features_in_secondary = False,n_jobs=-1)
# 交叉验证
n_fold = 5
folds = KFold(n_splits=n_fold, shuffle=True, random_state=1314)
oof = np.zeros(len(df_train))
prediction = np.zeros(len(df_test))
feats = feats
importance = 0
pred_y = pd.DataFrame()
seeds = [1314]
for seed in seeds:
folds = KFold(n_splits=n_fold, shuffle=True, random_state=seed)
for fold_n, (train_index, valid_index) in enumerate(folds.split(df_train)):
print(f'seed = {seed}, fold {fold_n} @ ****************************************')
train_x, train_y = df_train[feats].iloc[train_index].fillna(-9999), df_train[LABEL].iloc[train_index]
valid_x, valid_y = df_train[feats].iloc[valid_index].fillna(-9999), df_train[LABEL].iloc[valid_index],
STACKING.fit(train_x,train_y)
oof[valid_index] = STACKING.predict(valid_x)
pred_y[f"{seed}_{fold_n}"] = STACKING.predict(df_test[feats])
print('RMSE', np.sqrt(mean_squared_error(df_train[LABEL],oof)))
# np.mean(np.abs(oof - train_df['passenger_flow']) / train_df['passenger_flow'] )
# np.mean(np.abs(oof*train_df['line_median'] - train_df['passenger_flow']) / train_df['passenger_flow'] )todo:
20240627,距离结束还有三天,今天做了一些调整,分数涨了很多。牛掰!

















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









