







最近主要在做针对投资者的统计及聚类分析,希望能找出投资者的一些特征,方便做投资者的精准营销。
首先使用的是SPSS的modeler,毕竟操作可视化,比较简单,就是运行大量数据比较慢,挺费时间。
后来又想用R验证一下聚类的准确性,直接登陆Rstudio,找了kmeans的包,也计算了,发现了SPSS聚类除了没有R计算的效率快,分类也没有R精准,彻底断了我继续使用SPSS的想法,现将R聚类分析过程分享一下,大家一起学习共勉。
原始数据如下:
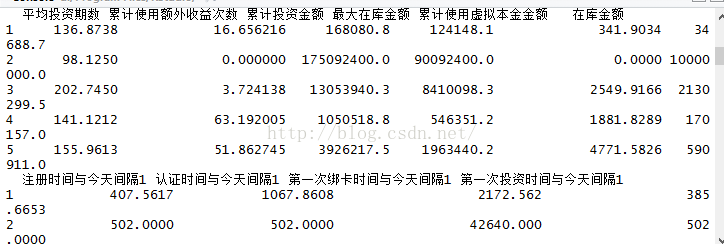
我需要使用R对这群投资者(约10W)进行聚类分析,代码如下:
library(kernlab)
library(magrittr)
#读取数据
zjd<-read.csv("d:/Rdata/zjd/zjd.csv",header = T,encoding = 'utf8')
zjd[is.na(zjd)]<-0
zjd[] <- lapply(zjd, as.numeric)
library(magrittr)
#读取数据
zjd<-read.csv("d:/Rdata/zjd/zjd.csv",header = T,encoding = 'utf8')
zjd[is.na(zjd)]<-0
zjd[] <- lapply(zjd, as.numeric)
#设定聚类数并运行模型
res <- kmeans(zjd,5)
#将结果与原数据拼接
res <- kmeans(zjd,5)
#将结果与原数据拼接
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2564
2564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









