









Face Anti-Spoofing Using Patch and Depth-Based CNNs
标签: anti-spoofing
论文来源:978-1-5386-1124-1/17/$31.00 ©2017 IEEE
摘要
本文中提出了基于两个CNN–一个局部(patch)和一个全局(depth)的面部反欺诈技术。局部可以获取与空间无关的特征,全局获取的图片深度可以作为一个可区别特征用于区分。
引言
以前的方法可以分为三类:①基于纹理的texture-based。②基于动作的motion-based。③图片质量及反射image quality and reflectance。以前的方法都是基于手取(hand-crafted)的特征而很少用CNN这个强大的特征提取器。而[29][33]是基于CNN做特征提取,然后喂入SVM。而本文提出的方法是基于双CNN的(一个局部一个全局)。全局的深度信息是由于真正的脸部是3D的,而攻击的则是平面的(flat)。
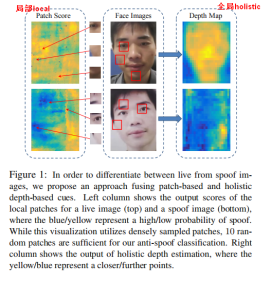
先前工作
先前的工作可以分为传统方法以及基于CNN的方法。传统方法包括LBP[30,15,16],HOG[25,47],DoG[42,36],SIFT[34],SURF[9],HSV+Ycbcr[7,8],Fourier spectra[28],OFM[5]。而CNN的有作为特征提取器的[29,33].也有作为分类器的[46],也有多细节[17],也有基于LSTM-CNN[45]。
由于本文中有一个CNN要做深度估计,虽然当下有很多面部深度估计的方法[23,40,10,20,21,37,38],但是没有面部深度估计是为了欺诈而准备的,所以本文就基于CNN给出了一种方案,详情见Section3.
方案
提出了一个双CNN的方案,对于patch-cnn就是单纯的端对端的网络,而depth-cnn是一个基于FCN(全卷积网络)的,最后融合两个特征进行判别。下面分别介绍两个CNN。
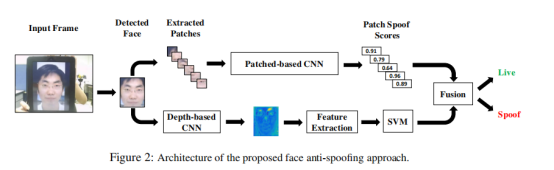
patch-cnn:使用图片的部分,这样既可以增加样本并且也能不进行图片resize(能保留一些信息),对于该CNN,喂入的数据,可以根据以前的经验选择HSV或者Ycbcr或者LBP这些特征,这样对于CNN能更好的学习到一些判别信息。

Patch-cnn的网络结构设计:如果给了一个训练数据,将会先进行面部识别,然后随机取固定大小的块(这样能避免resize,因为有些论文提出resize会损失一些信息),然后提取特征图(HSV等),喂入CNN,最终得到一个得分。如果为真的最后为1,假的为0。

Depth-cnn:在[14]中提到高频信息在反欺诈中有用,所以要避免对图片的resize,在patch-cnn中采用的是随机裁剪小块来保持图片大小都一致,并且能不进行resize,但是对于这个cnn来说,要喂入整张图片,而图片规格可能不同,所以采用了FCN(FCN的参数和输入无关),对于live face的深度估计可以使用[20,21,19]提出的方案。
生成深度标签,对于live face来说,可以使用一个dense 3D shape A来表征。
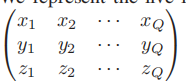
FCN网络结构:FCN喂入的是HSV+YCbCr,而每个图片的lable是上面生成的,最后训练一个FCN网络能够得到图片深度。

在通过FCN得到一个depthmap后,然后训练了一个SVM接收这些depthmap。
实验
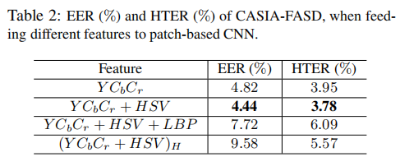
用的CASIA-MFSD[48],MSU-USSA和Replay-Attack三个库。并且在实验中给出了对于两个CNN的超参数以及图片处理方式,如果要实现该方案可以参考4.2。实验分析了对于patch-cnn中的不同输入特征图对于结果的影响,最后发现Ycbcr+HSV对于结果最好。
而对于depth-cnn,虽然对于某些spoof图片也能输出深度,但是可以看出其和live还是有一定的区别,所以经过svm就可以几乎区分的开了。
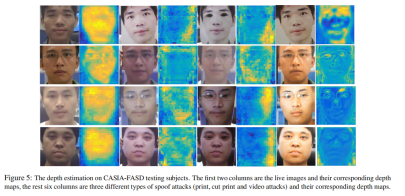
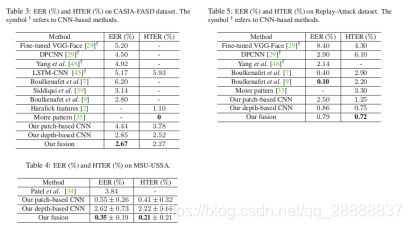
最终把两个模型融合起来结果由于单个的,下面给出了ROC曲线的对比,并且表格给出了本文的方法和当下的流行方法的对比。

收获
1、之前看的论文几乎都是传统特征加svm,而本文提出了基于CNN的
2、通过本文作为切入可以学习相关CNN论文
3、学习对于图片深度估计
金句:Biometrics utilize physiological, such as fingerprint,
face, and iris, or behavioral characteristics, such as typing rhythm and gait, to uniquely identify or authenticate an individual.
参考文献重点摘录可作为以后读
其他基于CNN的文章
[29]L. Li, X. Feng, Z. Boulkenafet, Z. Xia, M. Li, and A. Hadid. An original face anti-spoofing approach using partial convolutional neural network. In Image Processing Theory Tools327and Applications (IPTA), 2016 6th International Conference on, pages 1–6. IEEE, 2016. 2, 7, 8
[33]K. Patel, H. Han, and A. K. Jain. Cross-database face antispoofing with robust feature representation. In Chinese Conference on Biometric Recognition, pages 611–619. Springer,2016. 2
[46]J. Yang, Z. Lei, and S. Z. Li. Learn convolutional neural network for face anti-spoofing. CoRR, abs/1408.5601, 2014.2, 7, 8
3D face model
[6]V. Blanz and T. Vetter. Face recognition based on fitting a 3d morphable model. IEEE Transactions on pattern analysis and machine intelligence, 25(9):1063–1074, 2003. 5
[19] A. Jourabloo and X. Liu. Pose-invariant 3d face alignment.
In Proc. International Conference on Computer Vision, Santiago, Chile, December 2015. 4
[20] A. Jourabloo and X. Liu. Large-pose face alignment via cnnbased dense 3d model fitting. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition,
pages 4188–4196, 2016. 2, 4
[21] A. Jourabloo and X. Liu. Pose-invariant face alignment via
cnn-based dense 3d model fitting. International Journal of
Computer Vision, pages 1–17, April 2017. 2, 4















 3062
3062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









