




上一篇笔记先综述了一下扩散模型,这一篇详细分析一下扩散模型的训练和采样算法,以及其中的数学推理
目前我们常说的“扩散模型”,基本都是从 Ho 等人在 2020 年提出的 DDPM(Denoising Diffusion Probabilistic Model) 这个方法开始流行起来的。虽然名字叫“扩散模型”,但DDPM 实际上和传统的物理扩散模型有很大区别,两者只是名字和表面形式有点像,实质上是完全不同的两套体系
传统的扩散模型(比如基于“朗之万方程”、能量函数和得分匹配的方法)是一套基于物理过程、统计物理和概率理论的生成模型体系,这类方法依赖于具体的能量函数推导和 Langevin 动力学。而 DDPM 其实并不直接用这些传统概念。与其说它是“扩散模型”,不如说是一种“渐变模型”或“逐步添加噪声再逆过程还原”的模型。换句话说,DDPM 只是借用了扩散的“逐步变化”过程,但在实现机制和理论基础上和早期的扩散模型几乎没关系。
早在 2015 年,ICML 上的一篇论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》中已经提出了类似的数学框架。但直到 Ho 等人在 2020 年把这种方法应用到高分辨率图像生成,并调试出效果,才真正引发了后续大规模研究的热潮
核心参考:Denoising Diffusion Probabilistic Models
目录
2 前向加噪过程 Forward diffusion process
3 反向去噪过程 Reverse diffusion process
1 基本概念
简而言之,DDPM就是让图片一步步变成噪声,然后教AI如何把噪声一步步还原成高清图片
更具体一点,有一张好照片:
- 正向过程:每次往里加点噪声(就是一点点“雪花”),加很多次,最后变成完全的雪花噪声图
- 逆向过程:现在AI要学会拿一张雪花噪声图,能不能一步步把噪声去掉,最终还原成原来的好照片
- 训练过程:不是让AI直接猜原图,而是教它“每次要去掉什么样的噪声”。这就像教AI修图,每一步修正哪里,修多少
DDPM这篇论文把“图像变噪声-再还原”的过程玩明白了,找到一种更好教AI画画的新方式,不仅生成图片更好,而且背后的数学和理论也更严密
接下来开始理论部分:
首先从架构上来说,DDPM 模型主要包括两个阶段:
- 前向加噪过程 Forward diffusion process:将原始数据
作为起始点,每一步为其添加足够小的高斯噪声,经过足够多的步骤 T,使得
- 反向去噪过程 Reverse diffusion process:试图从噪声数据中恢复出有用的数据。因为前向过程是可行的,所以理论上反向去噪过程也是可行的,这两个过程互为逆操作
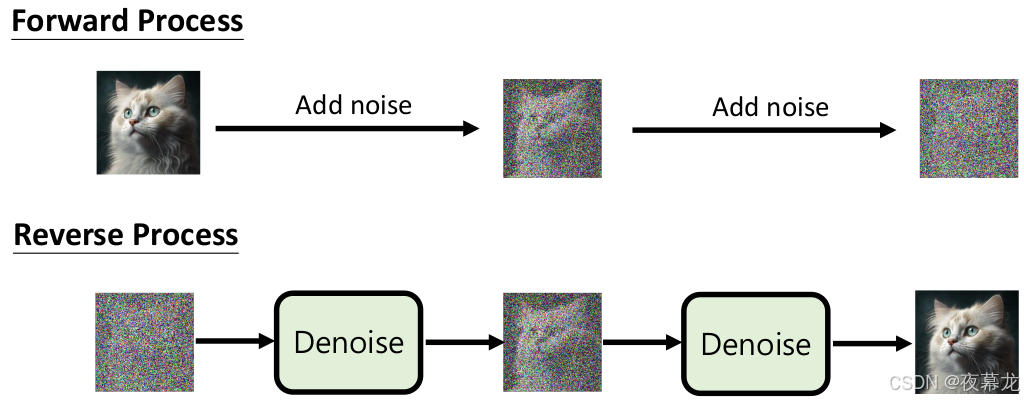
图 1. Overview of DDPM
2 前向加噪过程 Forward diffusion process
在扩散模型中,前向扩散(Forward Diffusion)指的是从原始数据 (服从分布
)出发,逐步向样本中注入小量高斯噪声,从而在 T 个离散步骤内生成一系列噪声化样本
。注入噪声的幅度由一个方差调度(Variance Schedule)
控制,其近似后验分布(前向过程/扩散过程)被固定为一个马尔可夫链,具体可写为:
其中 是一个较小的超参数,通常会随着 t 增大而增大。经过多次噪声累加后,当
时,
将接近各向同性高斯分布
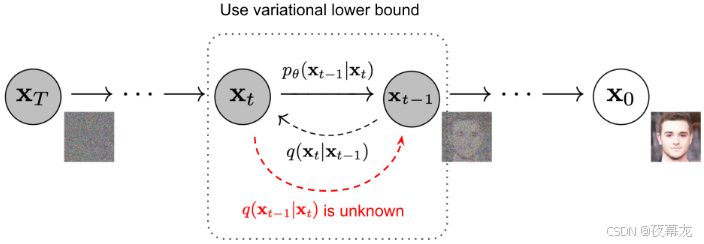
图 2. 通过逐步添加(去除)噪声生成样本的前向(反向)扩散过程的马尔可夫链
2.1 重参数化技巧
前向扩散具有一个颇为实用的性质:我们可以直接使用重参数化技巧(Reparameterization Trick)在任意时间步 t 对 进行闭式采样,无需逐步采样所有中间状态。令
并定义
,则有:
继续递归展开得:
一直展开下去,直至初始状态:
因此条件概率分布可以写成:
2.2 高斯分布合并规则
此处应注意,当合并两个不同方差的高斯分布 与
,新分布为:
在上述推导中,合并后的标准差是:
通常,当样本噪声较大时,可以采用更大的更新步长,因此设定 ,也就对应着:
2.3 与随机梯度 Langevin 动力学的联系
Langevin 动力学是源自物理学的概念,最初用于分子系统的统计建模。当与随机梯度下降(SGD)相结合时,随机梯度 Langevin 动力学(Stochastic Gradient Langevin Dynamics,简称SGLD,Welling & Teh 2011)可以通过以下的马尔可夫链更新规则,仅用梯度信息 来采样目标分布
:
其中 δ 是步长。当满足 ,
时,
将精确地收敛于概率密度
相较于标准随机梯度下降(SGD),随机梯度 Langevin 动力学通过在参数更新中加入高斯噪声,避免了陷入局部极小值的问题
3 反向去噪过程 Reverse diffusion process
如果能够逆转上述前向过程,并从 进行采样,就可以从高斯噪声输入
重现真实样本
。此处应注意,当
足够小时,
也服从高斯分布
但是,我们无法估计 ,因为它需要使用整个数据集。我们的目标是学习一个模型,去近似这些条件概率,从而可以基于噪声来生成新样本
2
图 3. An example of training a diffusion model for modeling a 2D swiss roll data
前向轨迹定义如下,当以 为条件时,反向条件概率是可解的:
也就是说,已知最终的数据样本 时,逆向一步的采样(扩散过程的反推)是一个高斯分布,其均值和方差是有明确解析解的
使用贝叶斯法则(Bayes’ rule),得到一步逆向的条件概率:
推导过程:
3.1 联合分布的拆分和指数化
所有项都是高斯分布,利用高斯分布的形式拆开,最终可以写成:
3.2 展开合并同类项
对平方项展开并整理,得:
其中 是和
无关的常数项,通常省略不写
3.3 配方还原高斯
将上述二次型重新写成标准高斯分布的形式,从而得到它的均值和方差:
(1)方差参数
这个量实际是反向采样的高斯分布的方差
-
是正向扩散中的噪声系数
-
是从 0 到 t 的累计残留信号比例
(2)均值参数
这个表达式说明了,逆过程每一步采样的均值是当前 noisy 状态和原始数据 的线性组合,权重与噪声 schedule 有关
3.4 结合 x₀ 的表示进一步推导
由于在训练过程中,通常没有 的真实值,只能用模型预测,或用当前 noisy 样本和噪声的表达式表示,根据 nice property 可以表示:
将这个公式带入前面的 中,得到最终在网络训练时用到的表达式:
每一步的逆扩散都是“给定当前 noisy 样本
,结合噪声预测/残差,往回还原一点点”,一步步把噪声变成数据
由于整个推导过程可微,且采样均值方差有解析表达,训练和采样都很高效
如图 2 所示,这种 setup 与 VAE 很相似,因此可以采用变分下界(Variational Lower Bound, VLB)来优化对数似然
3.5 变分下界与负对数似然
(1)负对数似然的变分下界推导
我们希望优化,但由于
难以直接计算,所以利用变分推断,用一个辅助分布
对联合分布进行近似,从而推导下界,详细推导:
a. KL 散度 总是非负,所以这提供了下界
b. KL 散度本质上是 q下 log(q/p) 的期望,这里 p 分母多一个 是因为联合概率分布的边缘化
c. 到第三步的继续化简得到两个部分,其中 可以单独拿出来
d. 合并前后两项,负对数似然被下界 所近似
e. 就是我们最后优化的目标,它是对真实数据的负对数似然的下界
3.6 Jensen 不等式的等价推导
同样可以用Jensen不等式(即凸函数的期望不小于期望的函数值)推导得到一样的结果,假设我们想要最小化交叉熵作为学习目标重新推导:
a. 交叉熵就是负对数似然
b. 的概率需要对所有潜变量边缘化,难以直接计算
c. 引入辅助分布 q,构造重要性采样公式
d. Jensen不等式,将 log 移到积分外部,得到下界
e. 得到的下界和前面的VLB一致,表明两种推导方式是等价的
3.7 VLB 逐项拆解为可计算的KL和熵项
为了让上面的每一项都能被具体计算,将 VLB 进一步拆解为每一步KL散度和熵项的和
为了使方程中的每一项都可解析计算,目标函数 VLB 可以进一步改写为多个 KL 散度和熵项的组合(具体步骤详见 Sohl-Dickstein 等人2015年论文附录 B):
a. 联合概率分布都可以写成条件概率的连乘
b. 拆分成最后一项的负对数概率和每一步的条件概率比值
c. 第一步和最后一步单独提取,方便后续和训练目标对应。
让我们分别标注变分下界损失中的每个组成部分,按KL散度分组最后整理得到:
变分下界中的每一项 KL 散度(除了 )都在比较两个高斯分布,因此可以解析计算。而
是常数项且在训练时可以忽略,因为 q 没有可学习参数且
是高斯噪声。Ho等人(2020)使用一个从
派生的离散解码器来单独建模
每一步的损失都具有明确的概率论意义,可以通过采样和预测得到
上述推导展示了如何将 DDPM 的训练目标转化为每一步的KL损失和重建损失的和
每个 KL 项本质上衡量了“正向扩散”和“反向去噪”在每个时间步的分布差异
训练过程中,实际采样和预测只需优化这些明确的概率分布距离,因此易于实现和收敛
本质上,这种方式与 VAE 完全一致,都是最大化观测数据的似然下界
3.8 训练损失的参数化
回顾一下,我们的目标是用神经网络去近似反向扩散过程中的条件概率分布,即:
也就是学一个网络,输入为当前 noisy 的样本 和步数 t,输出下一个采样点
的分布参数(均值与方差)
网络的预测目标(参数化):我们希望训练神经网络学到 μθ 去预测 ,这相当于用网络去逼近理论上最优的逆向均值。但由于
在训练时是已知输入,且
(加的噪声)也已知,所以我们可以对高斯噪声项重新参数化,改为让网络从时间步 t 的输入
中预测
:
即用神经网络预测 (给定当前 noisy 状态和步数),然后根据公式还原回
。这样做的好处就是模型预测的是高斯噪声项,容易拟合,也和 VAE 里的 reparameterization trick 很像
损失项 被参数化为:神经网络预测的
与理论上真实的
的差异,用均方误差最小化二者差距:
a. 此处实际是 KL 散度二次型推导后的标准均方误差表达
b. 展开后带入 和
相减消掉,剩下的是预测噪声与真实噪声的差别
c. 最终实际只剩下“预测噪声与真实噪声的均方误差”,且有权重因子
3.9 简化(Simplification)
Ho et al. (2020) 实际经验发现,直接忽略权重项,仅用普通的 MSE 损失,训练效果更好。即直接用预测噪声和真实噪声的均方误差(MSE)做损失,无需加权
这里的 是正向扩散采样公式,等价于先加噪声再训练
最终训练目标:
其中 C 是与模型无关的常数项,可以直接忽略
3.10 训练与采样算法流程伪代码

图 4. The training and sampling algorithms in DDPM (Image source: Ho et al. 2020)
1. 训练流程(Algorithm 1):实际上就是“加噪声-去噪声”配对,拟合真实噪声
1: 从数据分布采样
2: 均匀采样一个步数 t
3: 从标准正态分布采样噪声
4: 构造噪声样本
5: 用网络预测噪声
6: 计算损失 ,反向传播更新参数
2. 采样流程(Algorithm 2):相当于从纯噪声逐步“去噪”,生成最终的高质量数据样本
1: 采样最终噪声
2: 逐步从 t=T 到1:
- 若 t>1,采样标准正态噪声 z
- 计算
- 按公式
生成下一个
3: 返回
训练:每次从干净样本出发,加噪声后让网络去还原噪声
采样:从纯噪声出发,反向一步步去噪,最终得到合成样本
损失:本质上是对噪声预测的均方误差
优势:高效、稳定,理论与实际效果都好(这也是DDPM爆火的主要原因)
4 参考资料
扩散模型(Diffusion Model)详解:直观理解、数学原理、PyTorch 实现 | 周弈帆的博客
What are Diffusion Models? | Lil'Log
Generative Modeling by Estimating Gradients of the Data Distribution


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









