






梯度下降
当我们在机器学习中构建模型时,模型输出与真实值一定会出现误差,所以需要定义一个损失函数来度量模型预测结果与真实结果之间的差距。我们想要更接近真实值,那么就需要保证损失函数值最小。
所以梯度下降就是前人研究的一种优化算法,基本思想就是计算损失函数对于当前参数的梯度,然后沿着反方向更新参数值,在执行这一过程的时候损失函数正在下降,然后不断迭代更新参数,直到损失函数的最小值被找到。
ps:其实可以理解为下山,当我们在山顶的时候,想办法到山谷,但是我们的视野是有限的,如果我们跨的步子非常大就会产生不可预估的危险,但是如果跨的步子非常小,又影响我们下山的速率,所以我们要在有限的视野范围内选取一个合适的步长,既保证有足够快的下山速率,又保证不会产生危险,然后走出去,当我们走出去时,我们惊奇的发现,我的视野又更新了,于是在新的视野里又迈出一步·~~~这种操作直到我们到达山谷。
反向传播
我愿称之为逆流而上,也可以理解为一个侦探找线索的过程。
我们上面说了,要让损失函数下降对吧,那就得更新参数对吧,说直白点,就是要用loss函数对每一个中间参数求偏导对吧,那假如说我们的模型非常复杂,200层,让你用loss对第一层的参数求梯度,你干不干?没错你怕了。你的老年显卡750ti也廉颇老矣算不动了。因为这个式子是究极复杂的。这个时候我们的反向传播就登场啦,求第一个我办不到,那求第199层的偏导,别说750ti,你给个单片机都能算对吧(开玩笑),这个时候我们拿着199层求出来的这玩意(偏导),让198的哥们把参数交出来,哦?好像198的也不难算,跟198把关系打好,把参数骗到手,偏导算出来,诶,我来找197了~~~于是我们就勇敢借参数上位,第一层?链式法则累乘直接拿下好吧,小样这还迷不死你。这个时候重点来了,我们要根据学习率,更新每一步的参数,于是这个时候,把参数更新完,我们的loss就会更小辣!这些每一层的参数是这样的:
199参数w1:我来组成头部!
198参数w2:我来组成尾巴!
197参数w3:我…我是一个强壮的手指甲!
从后往前推的这个过程我们称之为 反向传播
计算图
我们学习数据结构图那一部分的时候喜欢用边和节点来表示信息,没错,计算图就是机器学习领域内用来图形化模型的一种表示方法,用来直观表示计算流程和数据传递。
从输入节点开始,每个节点执行不同的运算,最终到达输出节点。节点之间有一定的数据流动和依赖。
尤其是计算导数和梯度很喜欢用,在反向传播中记录某种依赖关系,用来实现链式求导法则,优化模型会更加方便。
使用Numpy编程实现例题
1.反向传播第1轮
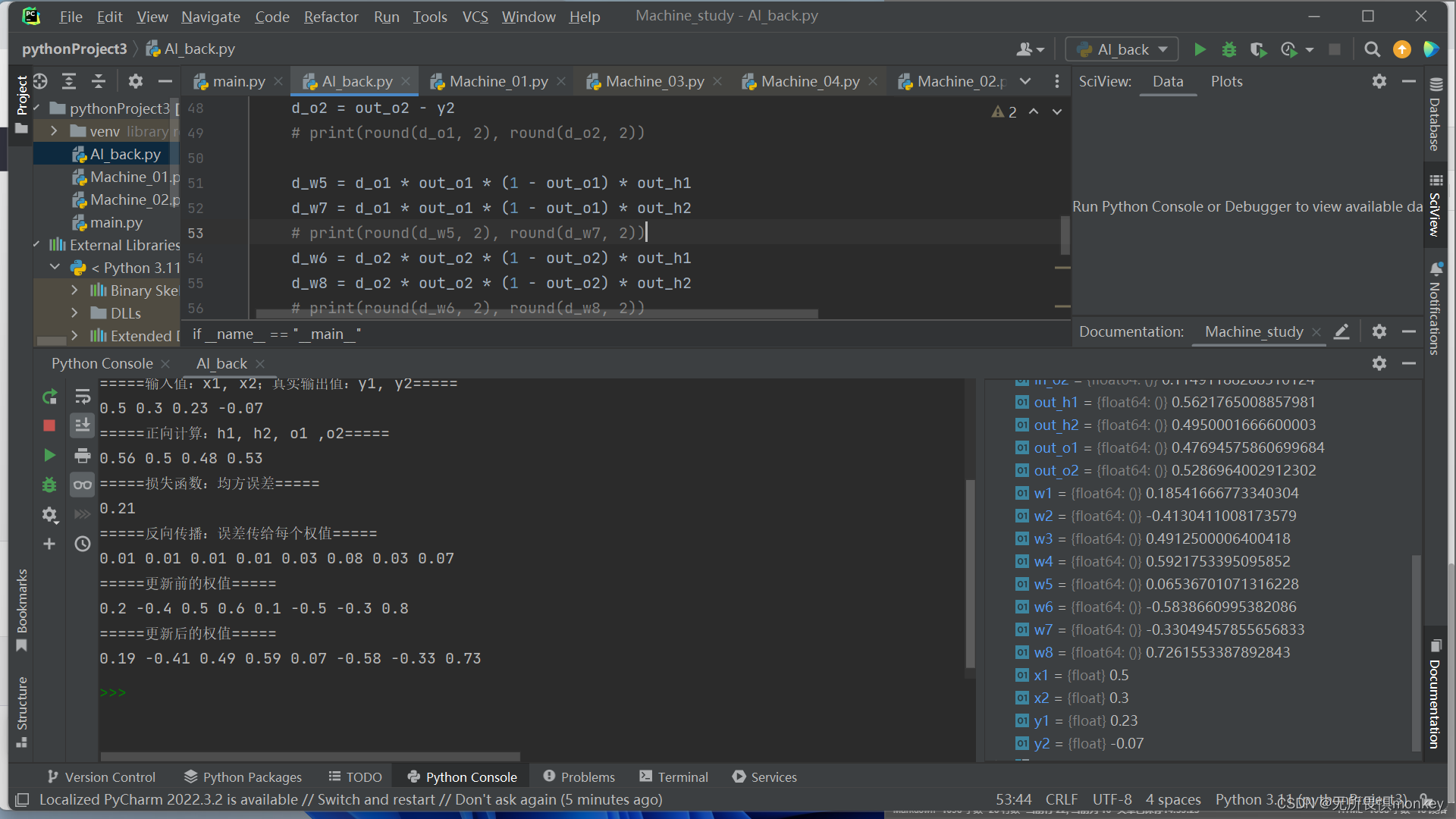
2.增加到第5轮
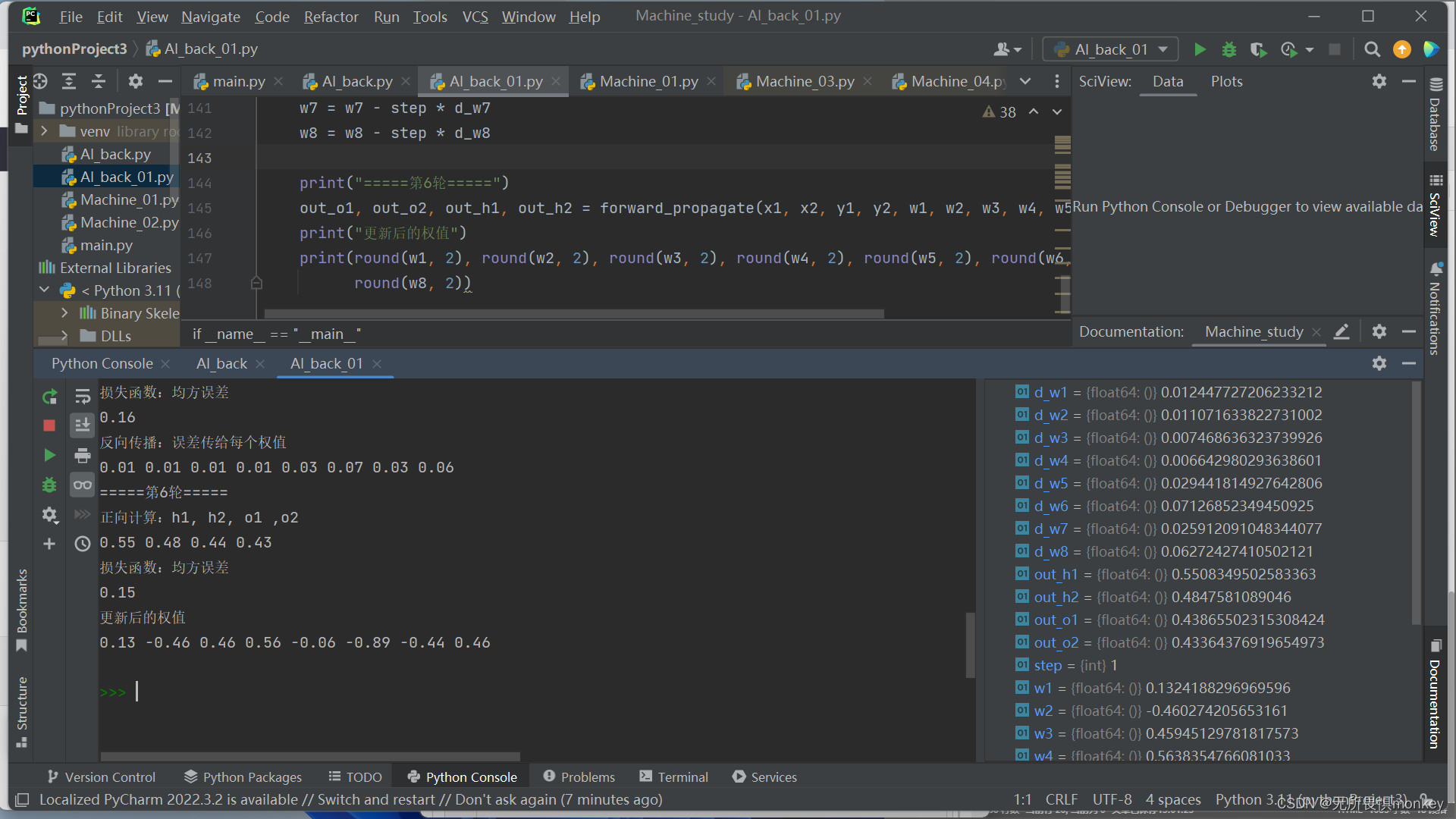
3.改变步长看收敛速度
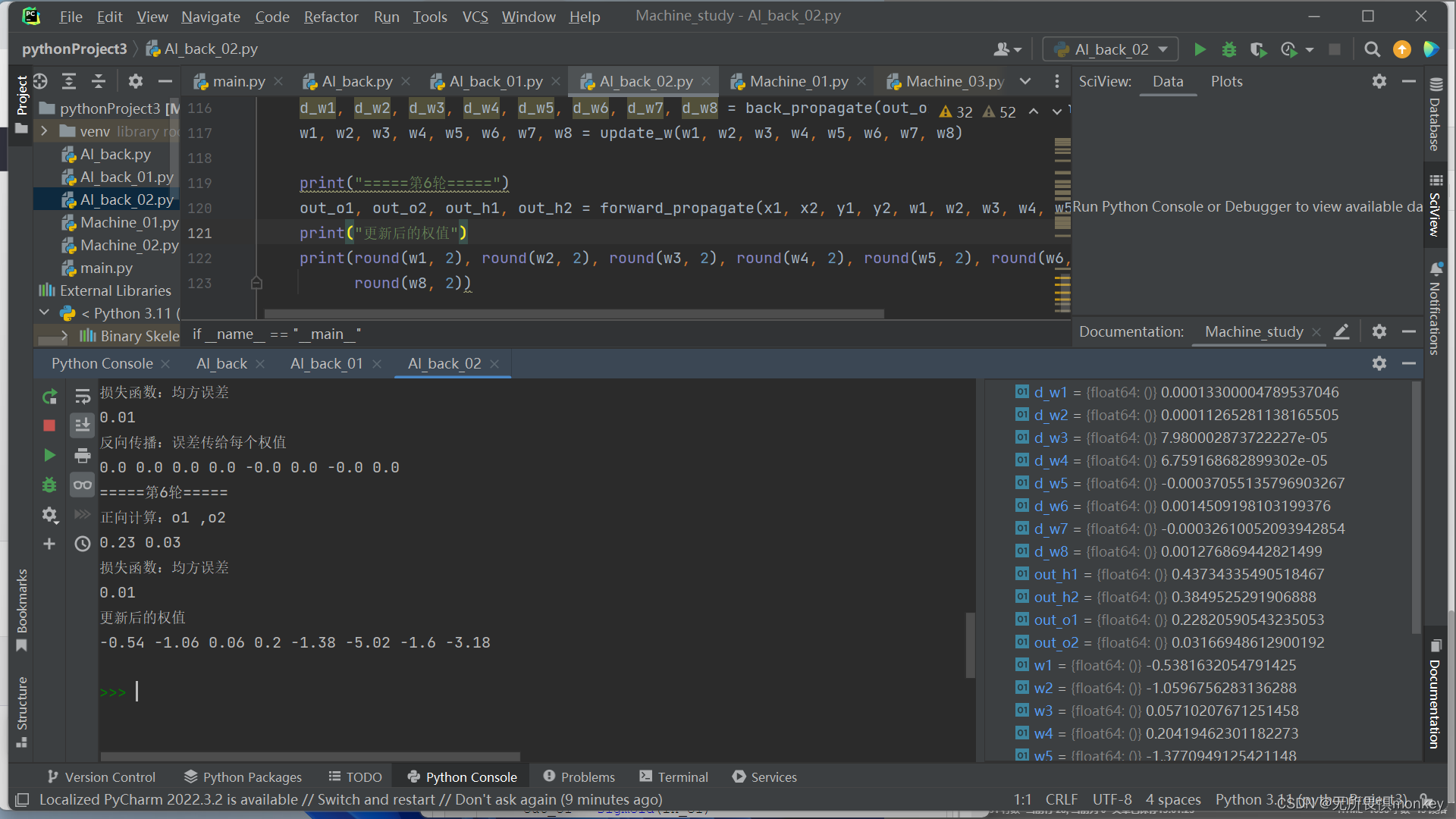
4.改变步长为5,训练1000次
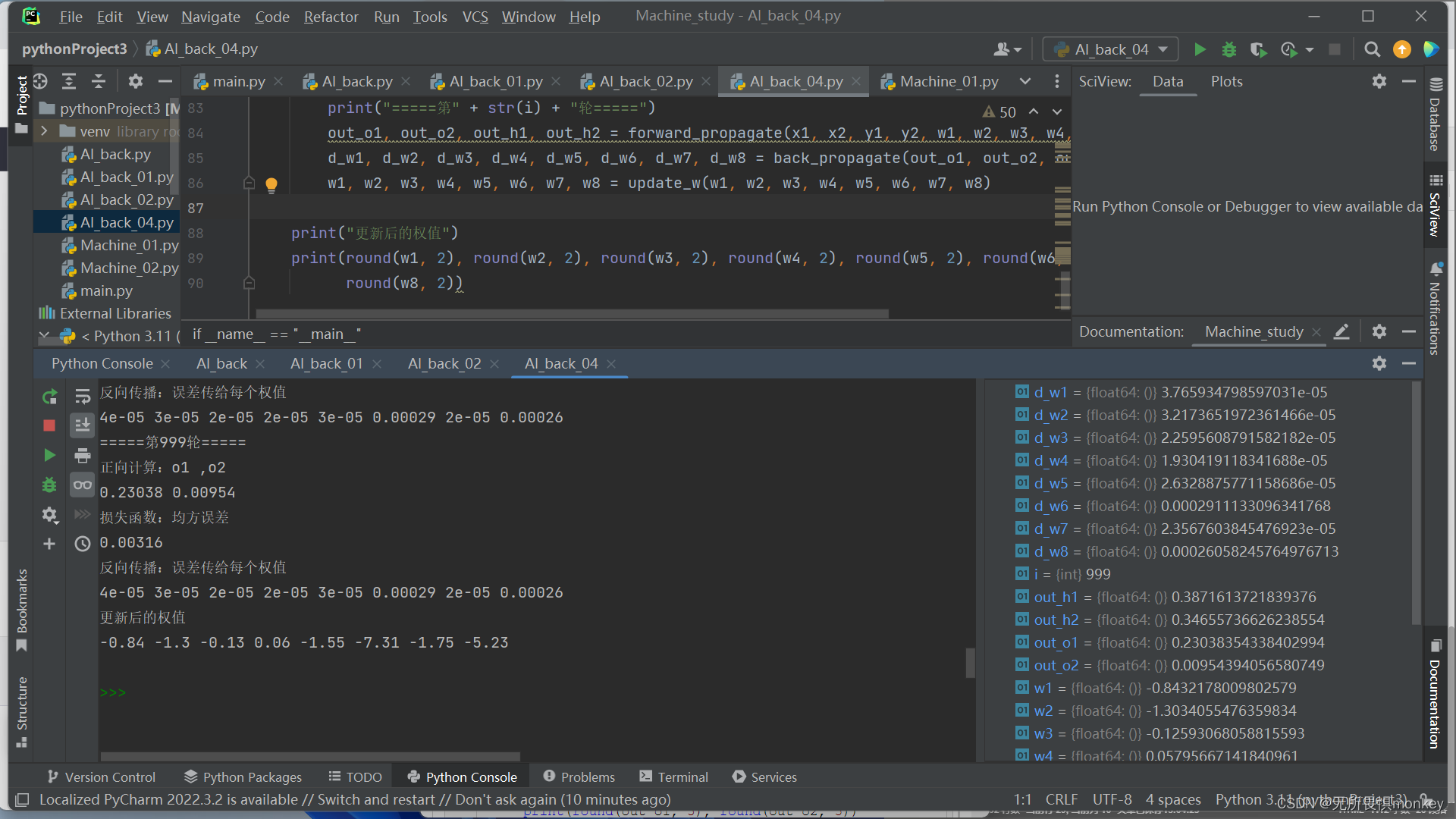
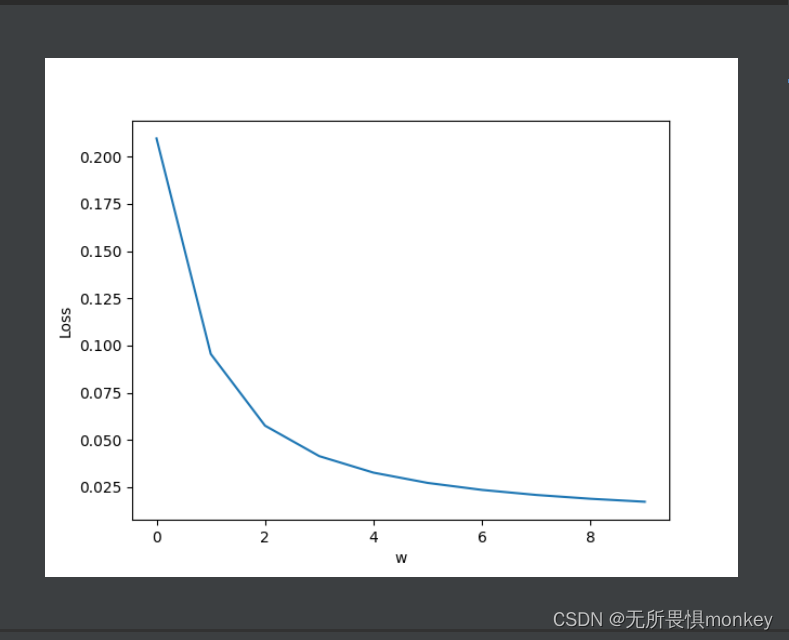
5.步长为5,训练20000次
容易看到,训练过多效果反而不是很好
6.步长为10,训练1000次
步长过大,训练效果也差强人意。
7.修改y1为正,步长为10
步长为5:
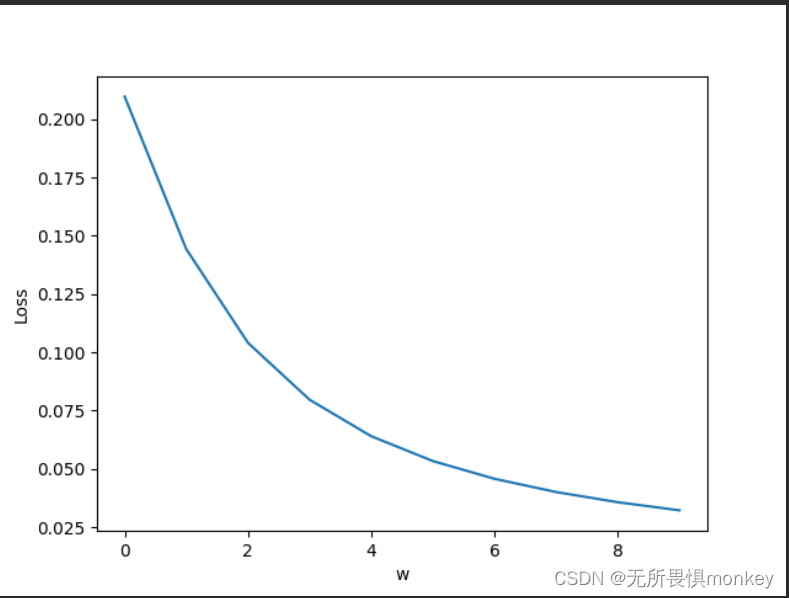
步长为5的迭代没有为10那么迅速。
代码从这里拿的,中间随便改了改参数:
点我抄代码
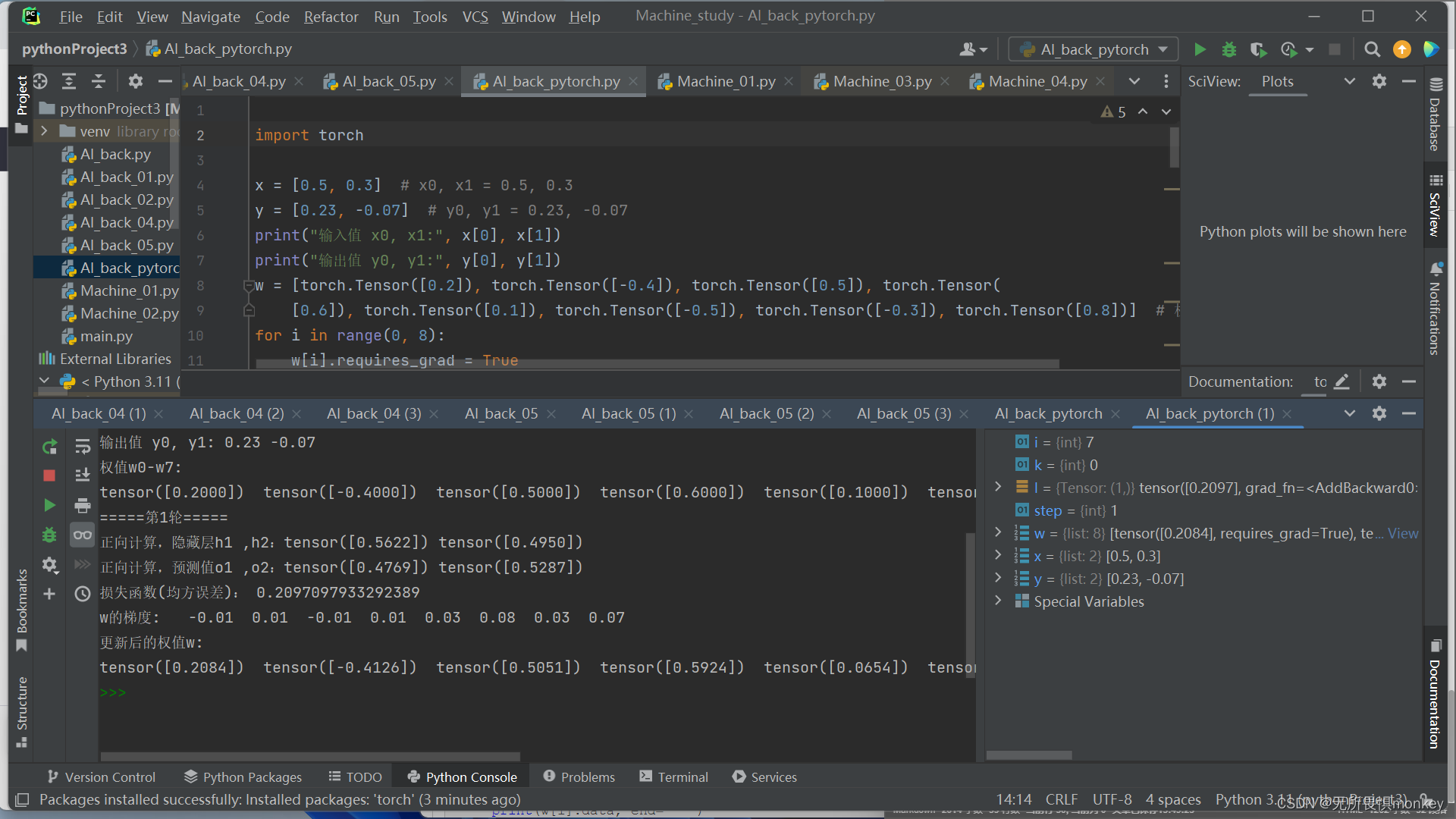
这是pytorch版本的运行结果:
代码这里拿的
点我抄代码哦
写在最后
Super Bright 的学校补课,周末直接没时间写,本来规律的作业周期被冲烂了,周二的作业拖到周五,真TheaterMissileDefense服了。学校啥都想让学生学,希望面面俱到,可是谁又会想到,浅尝辄止意味着庞大且平庸。















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









