









Abstract
少样本分类是一个具有挑战性的问题,因为每个新任务只提供很少的训练示例。解决这一挑战的有效研究路线之一集中在学习由查询图像和某些类别的少数支持图像之间的相似性度量驱动的深度表示。从统计学上讲,这相当于测量图像特征的依赖性,被视为高维嵌入空间中的随机向量。以前的方法要么只使用边际分布而不考虑联合分布,受限于表示能力,要么虽然利用联合分布但计算成本很高。在本文中,我们提出了一种用于少样本分类的深度布朗距离协方差(DeepBDC)方法。 DeepBDC 的中心思想是通过测量嵌入特征的联合特征函数与边缘乘积之间的差异来学习图像表示。由于 BDC 度量是解耦的,我们将其表述为一个高度模块化和高效的层。此外,我们在两个不同的小样本分类框架中实例化 DeepBDC。我们在六个标准的小样本图像基准上进行了实验,涵盖了一般对象识别、细粒度分类和跨域分类。广泛的评估表明,我们的 DeepBDC 显着优于同行,同时建立了新的最先进的结果。
https://github.com/Fei-Long121/DeepBDC
Introduction
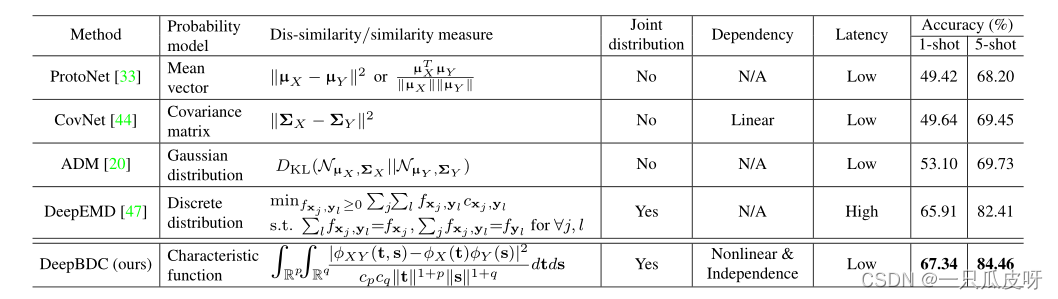
在本文中,我们提出了一种用于少样本分类的深度布朗距离协方差(DeepBDC)方法。 BDC 度量首先在 [35,36] 中提出,被定义为联合特征函数和边际乘积之间的欧几里得距离。它可以自然地量化两个随机变量之间的依赖关系。对于离散的观察(特征),BDC 度量是解耦的,这样我们就可以将 BDC 制定为一个池化层,它可以无缝地插入到深度网络中,接受特征图作为输入,输出一个 BDC 矩阵作为图像表示。通过这种方式,两个图像之间的相似性被计算为对应的两个 BDC 矩阵之间的内积。因此,我们的 DeepBDC 的核心是高度模块化和即插即用的,适用于不同的小样本图像分类方法。具体来说,我们在元学习框架 (Meta DeepBDC) 和依赖非情景训练的简单迁移学习框架 (STL DeepBDC) 中实例化我们的 DeepBDC。与协方差矩阵相反,我们的 DeepBDC 可以自由处理非线性关系并充分表征独立性。与 EMD 相比,它还考虑了联合分布,最重要的是,它可以进行分析和有效地计算。与 MI 不同,BDC 不需要密度建模。我们展示了我们的 BDC 与 表1 中的对应物之间的差异。
Contributions
(1) 我们首次将布朗距离协方差 (BDC),一种基本但在很大程度上被忽视的依赖建模方法,引入基于深度网络的小样本分类。我们的工作表明 BDC 在深度学习中的巨大潜力和未来应用。
(2) 我们将 DeepBDC 制定为高度模块化和高效的层,适用于不同的小样本学习框架。此外,我们提出了两种用于少样本分类的实例,即基于以 ProtoNet 为蓝图的元学习框架的 Meta DeepBDC,以及基于简单迁移学习框架的 STL DeepBDC,无需情景训练。
(3) 我们对我们的方法进行了彻底的消融研究,并对六个少样本分类基准进行了广泛的实验。
Method
1、布朗距离协方差 (BDC)
BDC 度量具有离散观察的封闭形式表达式,令
![]()
其中
![]()
是在 X 的观测值对之间计算的欧几里德距离矩阵。类似地,我们计算欧几里德距离矩阵
![]()
![]()
那么 BDC 度量具有以下形式:
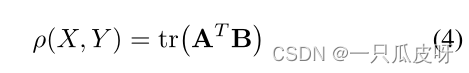
其中 tr(·) 表示矩阵迹,T 表示矩阵转置,A = (𝑎𝑘𝑙) 称为 BDC 矩阵。𝑎𝑘𝑙=
![]()
2、将 DeepBDC 制定为池化层
我们设计了一个适用于卷积网络的两层模块,分别执行降维和 BDC 矩阵的计算。随着 BDC 矩阵的大小相对于网络中的通道数(特征图)呈二次方增加,我们在网络主干的最后一个卷积层之后插入一个 1×1 卷积层进行降维。
我们开发了三个算子,依次计算平方欧几里得距离矩阵:=
![]()
![]()
![]()
BDC 矩阵 A 从 中减去其行均值、列均值和所有元素的均值。那是,
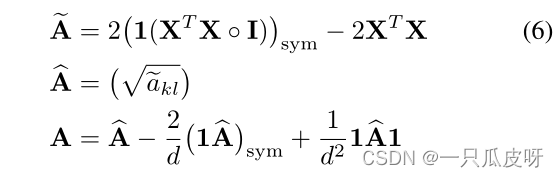
3、为小样本学习实例化 DeepBDC
Meta DeepBDC
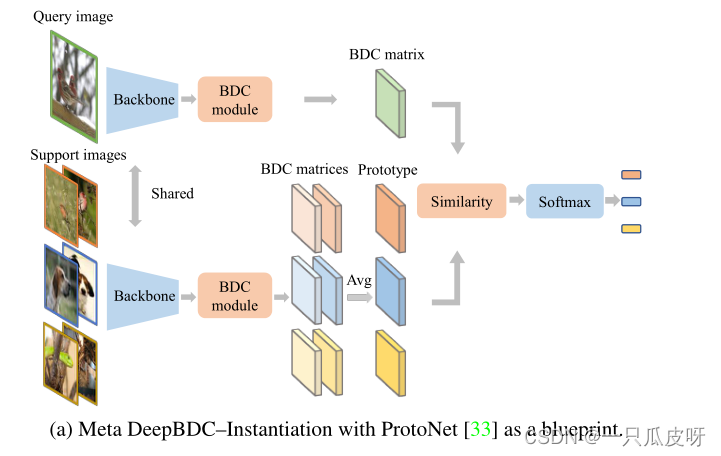
我们用 ProtoNet [33] 实例化 Meta DeepBDC 作为蓝图。它学习一个度量空间,其中通过计算到每个类的原型的距离来执行分类。在一项任务(Dsup,Dque)中,我们将图像 zj 输入网络以生成 BDC 矩阵 Aθ(zj)。支持类 k 的原型是属于其类的 BDC 矩阵的平均值 (Avg):
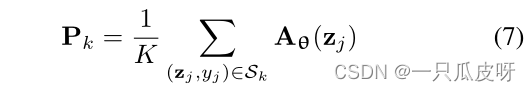
其中 Sk 是 Dsup 中标有 k 类的示例集。我们基于到支持类原型的距离上的 softmax 生成类分布,然后制定以下损失函数:
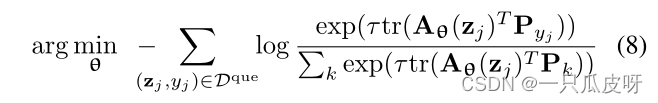
STL DeepBDC
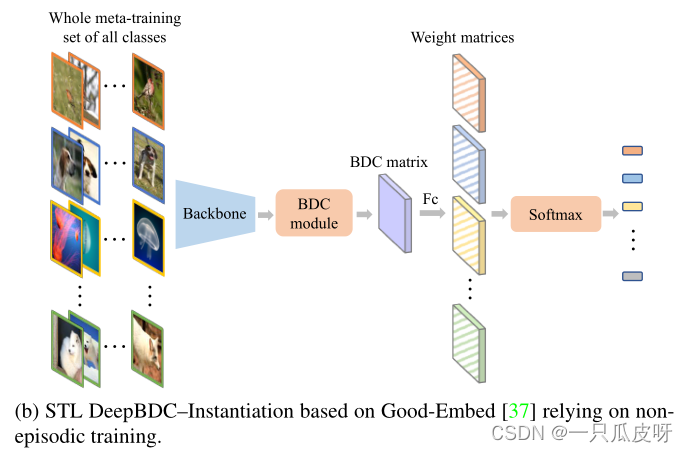
我们在跨越所有类的整个元训练集 Ctrain 上训练传统的图像分类任务。预测和真实标签之间的交叉熵损失用于从头开始训练学习者:

其中 Wk ∈ R^d×d 是第 k 个权重矩阵,τ 是一个可学习的缩放参数。对于从元测试集 Ctest 采样的任务(Dsup,Dque),我们使用训练好的模型作为特征提取器,在 Dsup 上为 K 类构建和训练一个新的线性分类器。在[37]之后,我们采用逻辑回归模型进行分类,而不是直接使用经过训练的模型进行元测试任务,而是使用顺序自蒸馏技术从元训练集上的训练模型中提取知识.
实验
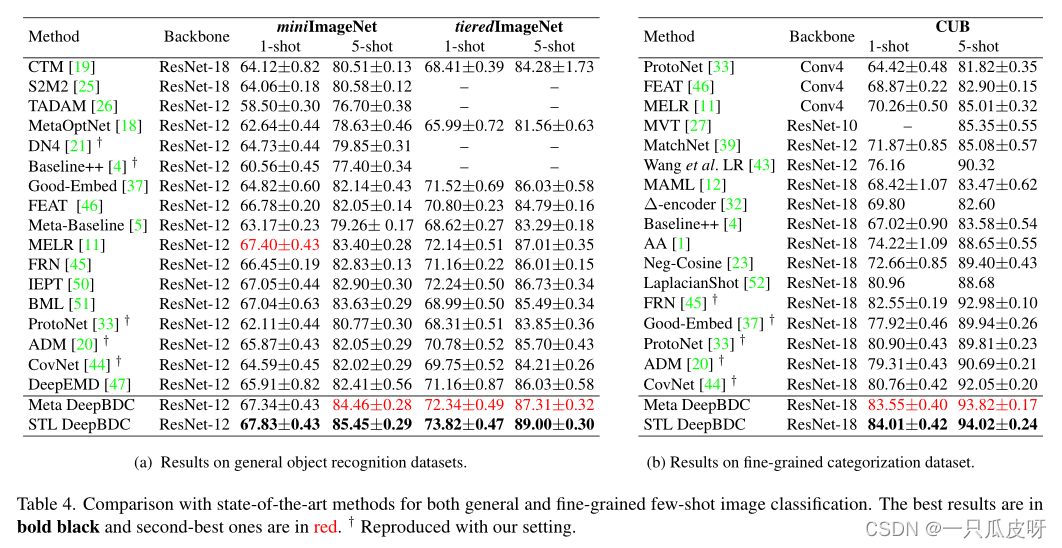















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









