







Abstract
Few-shot 分类旨在将来自未见类别的样本分类为只有很少的标记样本。为了应对这样的挑战,许多方法利用由大量标记样本组成的基类数据集来学习实例嵌入函数,即图像特征提取器,并且有望在不同任务之间具有良好的可迁移性。这种few-shot学习的特点与传统的图像分类只追求有区别的图像表示有着本质的不同。在本文中,我们建议通过擦除修复来学习完整的特征,以进行小样本分类。具体来说,我们认为提取目标对象的完整特征更具可转移性,然后提出一种新的交叉集擦除修复(CSEI)方法。CSEI 使用擦除和修复处理支持集中的图像,然后使用它们来增强同一任务的查询集。因此,我们提出的方法产生的特征嵌入可以包含更完整的目标对象信息。此外,我们提出了特定于任务的特征调制,以使特征适应当前任务。在两个广泛使用的基准上进行的大量实验很好地证明了我们提出的方法的有效性,它可以始终如一地为不同的基线方法获得可观的性能提升。
Contributions
- 我们建议在实例匹配中增强嵌入函数的可迁移性,而不是为少样本学习提取判别信息。
- 我们提出了一种新的用于网络训练的交叉集擦除修复,它可以强制嵌入函数从目标对象的不同区域提取更多信息。
- 我们将所提出的技术整合到代表性的少样本学习方法中,并在 5-way 1-shot 和 5-way 5-shot 设置上对它们进行实验评估。结果表明,我们提出的方法可以始终如一地带来性能增益。
Method
1、问题公式化
Few-shot 分类有三个重要的概念:大标注数据集 Dbase、支持集𝑆𝑡𝑒𝑠𝑡和查询集 𝑄𝑡𝑒𝑠𝑡。支持集包含N个不属于Dbase的类别,每个类别包含M个样本,即N-way M-shot。查询集 Qtest 是从 N 个类别中采样形成的,样本与支持集中的样本不同。我们的目标是使用 Dbase 和支持集将查询集中的样本正确分类到 N 个类别中。
对于支持特征,我们使用平均向量为每个类计算一个原型向量:
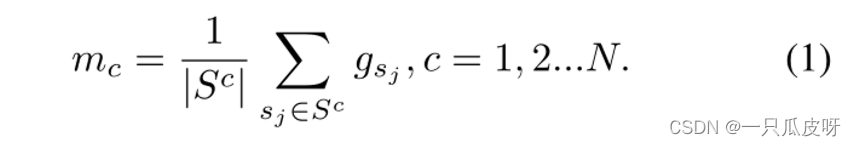
给定一个距离函数 d,那么我们可以计算查询样本在类上的分布为:
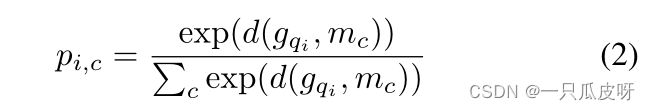
为方便起见,我们将 I(*) 定义为获取样本基本事实的标签函数(获取样本标签):
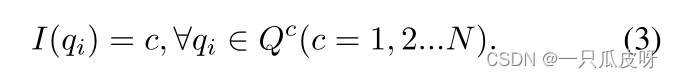
然后,这一eposide训练的损失 L 由所有查询支持对的平均交叉熵损失定义:
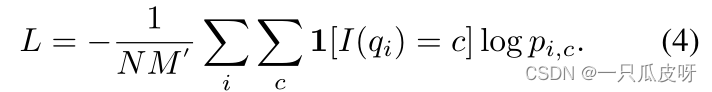
训练完成后,我们使用g提取支持集Stest和查询集Qtest中样本对应的特征嵌入和
。类似地,我们使用公式(1)计算支持集 Stest中每个类别的原型
。最后,我们使用最近邻分类器将
的类别确定为:
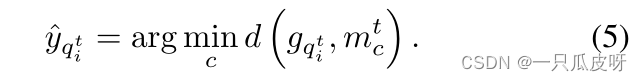
2、方法总览
在这项工作中,我们的目标是在少样本分类中为度量计算获得更好的图像特征。为此,我们建议增强嵌入函数的可迁移性并提高特征对任务的适应性。图 2 说明了我们提出的方法的整体架构。具体来说,为将输入图像转换为特征嵌入的所有集合构建了一个共享嵌入函数。然后对特征嵌入进行调制以适应当前任务,从而使距离度量的最终特征更加具体。
特别是,我们提出了一种新的交叉集擦除(CSEI)模块来强制嵌入功能来提取代表目标对象更完整信息的完整特征。原则上,CSEI 首先删除图像中最具辨别力的区域,然后强制嵌入网络对其他区域做出响应。因此,可以提取目标对象的更多信息。此外,我们提出了一个特定于任务的特征调制(TSFM)模块,以提高特征对当前任务的适应性。
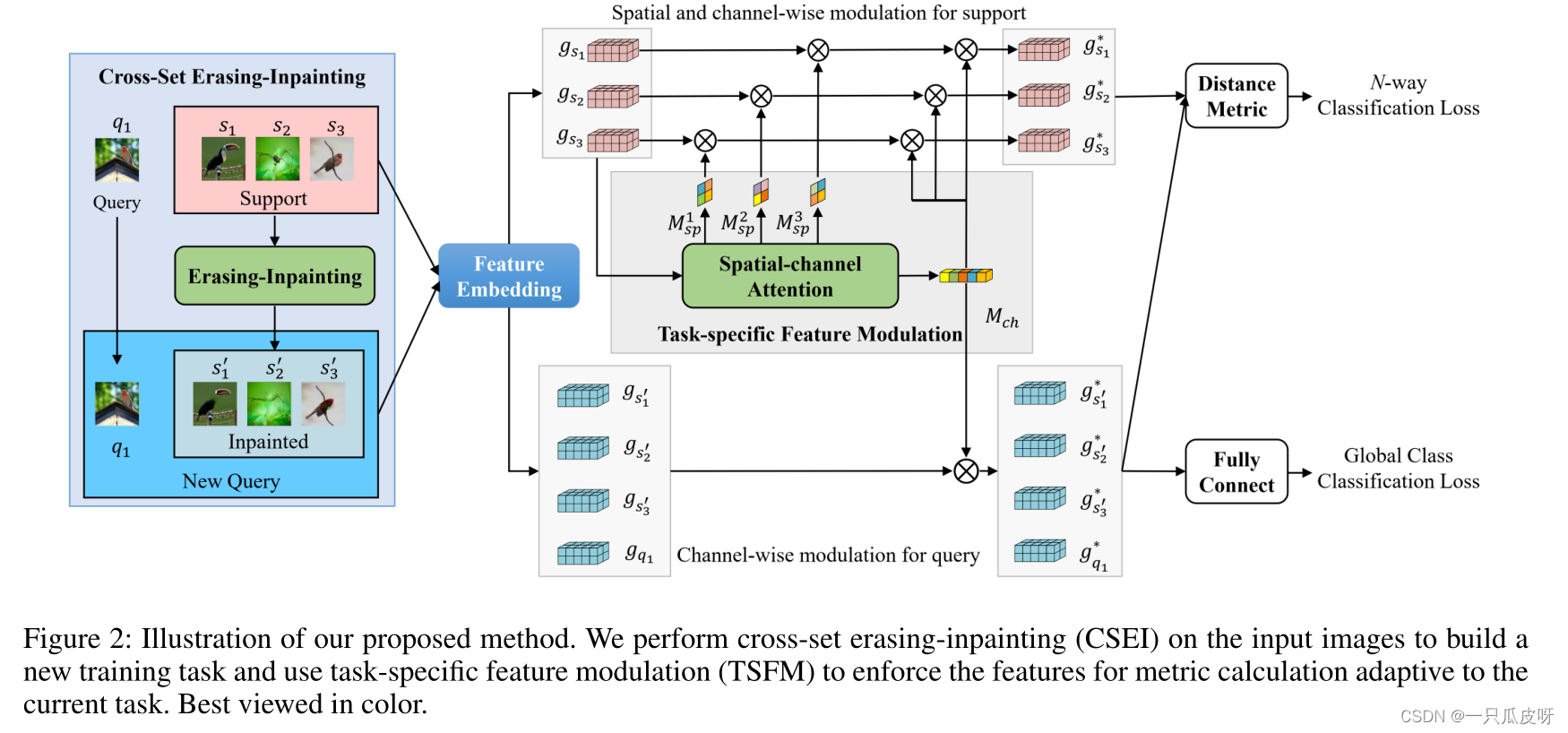
3、Cross-Set Erasing-Inpainting
跨集擦除修复模块主要由两部分组成,即擦除修复和跨集数据增强。我们首先使用擦除修复来处理支持图像以生成新图像,然后我们使用交叉集数据增强来构建新任务。最后,使用新任务训练模型。请注意,CSEI 仅用于训练阶段,因此不会导致推理时间的增加。
3.1 Erasing-Inpainting
我们首先需要在基础集 Dbase 上训练一个包含全局池化层的传统分类网络。对于每个输入图像 I,令 fi(x,y) 表示在位置 (x,y) 处全局池化层之前第 i 个特征图的激活。那么类别 c 的得分为:
![]()
其中 H 和 W 表示空间分辨率,𝑤𝑖𝑐 是对应于单元i的类别c的权重。我们可以得到类 c 的类激活map Mc:
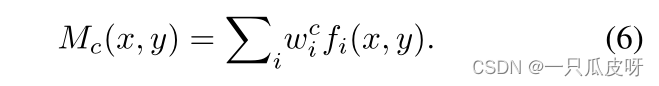
Mc(x, y) 表示在空间网格 (x, y) 处激活值对将图像 I 分类为 c 类的重要性。因此,Mc(x, y) 可以作为 c 类最具辨别力区域的指标。更具体地说,我们首先对每张图像的分数进行排序,并得到分数最高的前 K 个类别的索引(𝑂𝑐𝑖,…𝑂𝑐2,…..𝑂𝑐𝑘)。然后我们可以得到 K 类激活图(Mc1 , ..., Mck , ..., McK )。
我们将 𝑀𝑐𝑘 归一化为 (0, 1),然后使用阈值策略将其转换为二进制掩码𝑀𝑐𝑘。然后我们得到蒙版的图像:
![]()
这里将擦除区域赋值为0。显然,擦除区域与周围区域非常不一致,会带来干扰。在这项工作中,我们使用图像修复技术来完成擦除图像,使擦除区域与周围区域一致。在实验中,我们直接使用作者提供的 EC模型完成𝐼𝑘并得到修复图像𝐼𝑘′。因此,对于我从 Dbase 中采样的每个图像,我们可以得到 K 个修复图像𝐼1′,….𝐼𝑘′,….𝐼𝐾′。在实践中,我们提前处理 Dbase 中的所有图像并将结果存储在磁盘上,以减少训练时间。
3.2 Cross-Set Data Augmentation
在这项工作中,我们使用擦除修复产生的图像通过数据增强来增强特征提取器。具体来说,每个任务都有一个支持集 𝑆𝑡𝑟𝑎𝑖𝑛 和一个查询集 𝑄𝑡𝑟𝑎𝑖𝑛。我们使用erasing-inpainting模块对支持集𝑆𝑡𝑟𝑎𝑖𝑛中的图像进行处理,得到一组修复图像:
![]()
![]()
然后我们可以通过联合原始查询集和修复的支持集来构建一个新的查询集:

最后,我们使用任务()来训练我们的模型,并使用情节训练策略(元学习策略)。
可以看出,我们使用支持集中的样本来扩充查询集,因此称为交叉集数据扩充。通过这样的数据处理,强制特征提取器响应除判别部分之外的目标对象的更多区域。具体来说,查询集中的修复样本已经删除了判别部分(例如,“头部”),相应的特征将不包含该部分的信息。在训练期间,为了将查询样本与支持样本正确匹配,特征提取器必须捕获判别部分之外的信息。
4、Task-Specific Feature Modulation
对于不同的任务,即使对于相同的图像,区分所涉及的类的特征也可能有很大的不同。也就是说,度量计算的特征需要适应当前的任务。为此,我们建议从两个方面对特征嵌入进行调制,如图 2 所示。
- 首先,我们学习了支持集和查询集的通道级注意𝑀𝑐h,以突出显示重要的模式,因为特征映射的每个通道代表一个特定的模式。
- 其次,我们只为支持集学习空间注意力以突出目标对象,其中为支持集中的样本生成不同的注意力图。
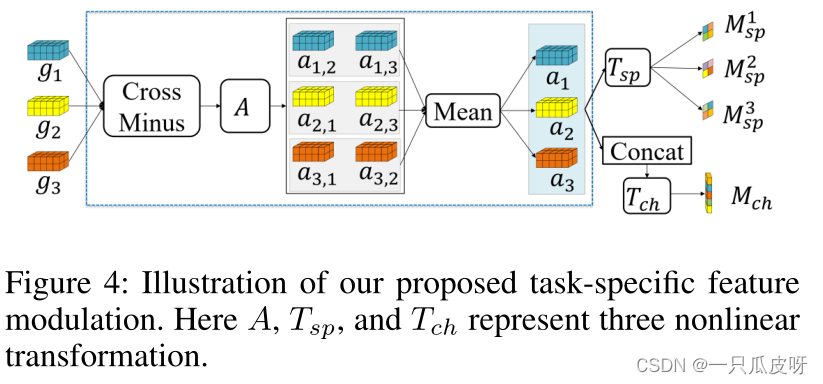
形式上,假设我们已经得到了支持集中每个类别的原型 Ms = (m1,···, mc,···, mN) 和查询特征 Gq = (𝑔𝑞1,…𝑔𝑞𝑁𝑀′) .然后我们融合支持集中所有样本的信息来学习注意力图,如图4所示。这里的支持样本实际上代表了当前任务。
具体来说,我们首先使用交叉减法计算原型之间的差异,然后应用非线性变换 A 得到 𝒂𝒊,𝒋 = A(mi− mj)。之后,我们得到某个类别 c 的特征与其他类别的特征之间的差异信息:
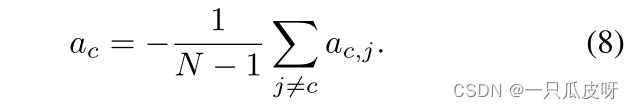
![]()
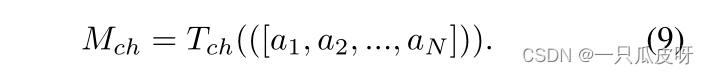
另一方面,我们使用非线性变换 Tsp 将 𝑎𝑐 的通道压缩为一维,以获得每个原型 c 的空间注意力:
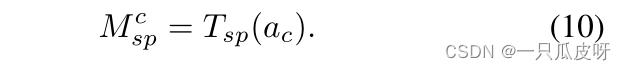
最后,我们使用 𝑀𝑠𝑝𝑐 和 𝑀𝑐h 将支持集和查询集的特征调制为:
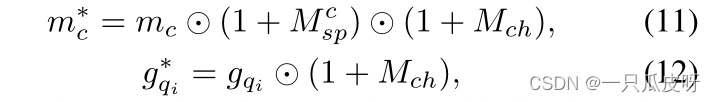
5、损失函数
我们构建了一个 N-way 分类损失 𝐿𝑁−𝑤𝑎𝑦,如等式(4),同时构建一个全局分类损失 𝐿𝑔𝑙𝑜𝑏𝑎𝑙,附加到全连接层以将特征 𝑔𝑞𝑖∗ 分类到 Dbase 中的所有类别。那么整体损失函数定义为:
![]()
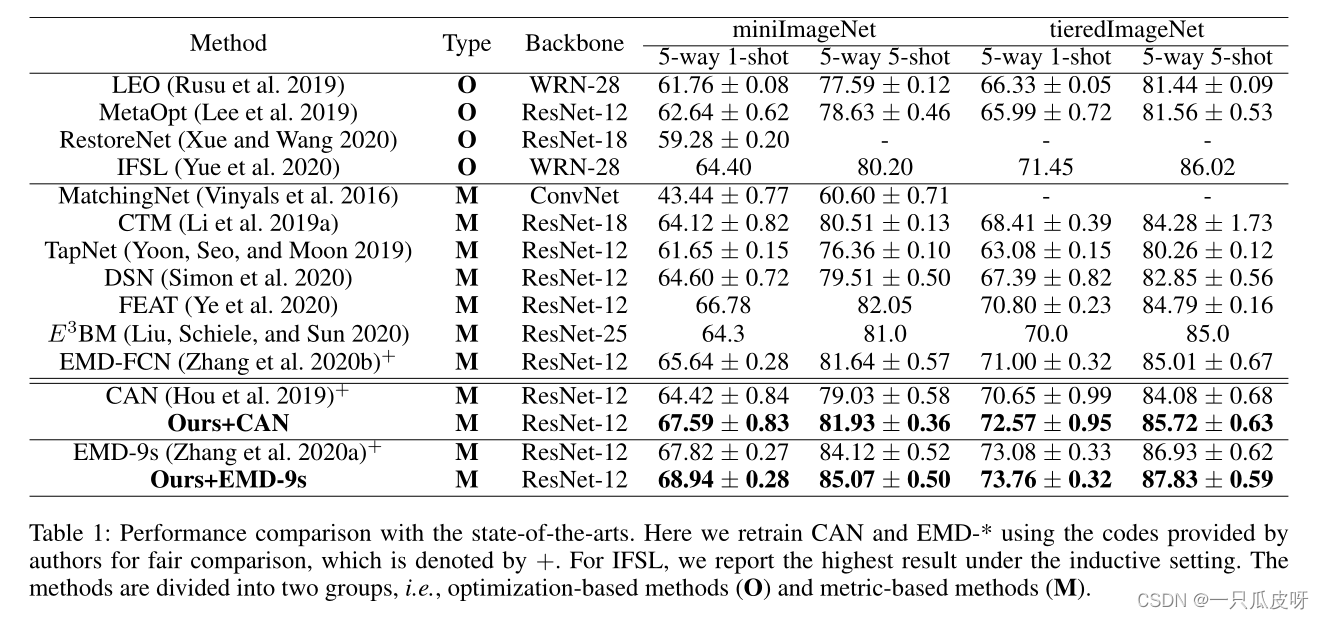
实验
















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









