







目录
字节类型大小
#include <iostream>
using namespace std;
int main()
{
cout << "sizeof(bool) = " << sizeof(bool) << endl;
cout << "sizeof(char) = " << sizeof(char) << endl;
cout << "sizeof(int) = " << sizeof(int) << endl;
cout << "sizeof(float) = " << sizeof(float) << endl;
cout << "sizeof(double) = " << sizeof(double) << endl;
cout << "sizeof(long double) = " << sizeof(long double) << endl;
enum e{a, b=3};
cout << "sizeof(enum) = " << sizeof(e) << endl;
cout << "sizeof(int *) = " << sizeof(int *) << endl;
cout << "sizeof(char *) = " << sizeof(char *) << endl;
cout << "sizeof(NULL) = " << sizeof(NULL) << endl;
cout << "sizeof("0") = " << sizeof("0") << endl;
cout << "sizeof('0') = " << sizeof('0') << endl;
cout << "sizeof('\0') = " << sizeof('\0') << endl;
return 0;
}
结果:
sizeof(bool) = 1
sizeof(char) = 1
sizeof(int) = 4
sizeof(float) = 4
sizeof(double) = 8
sizeof(long double) = 16
sizeof(enum) = 4
sizeof(int *) = 8
sizeof(char *) = 8
sizeof(NULL) = 8
sizeof("0") = 2
sizeof('0') = 1
sizeof('\0') = 1
需要注意点:
-
在ubuntu 64位的系统下编译器是64位编译器,因此指针类型为8个字节。
-
NULL在C++中是void * 类型的。
#ifndef __cplusplus #define NULL ((void *)0) #else /* C++ */ #define NULL 0 #endif /* C++ */
3."0"代表字符串,占用2个字节,而'0'代表字符常量,占1个字节。
转义字符
C++中,所有的ASCII码都可以用“\”加数字(一般是8进制数字)来表示l,部分常用的ASCII码也可用“\”加字母表示。如'\?','\77','?'三者表示的都是同一个符号。
#include<iostream>
using namespace std;
int main()
{
char a = '?';
char b = '\77';
bool t = (a == b);
cout <<t<< endl;
}
输出:
1
原码、反码、补码
正数:三码相同
负数:
反码 = 原码按位取反(符号位除外)
补码 = 反码 + 1
例如 :
-129
原码:1000 0000 1000 0001
反码:1111 1111 0111 1110
补码:1111 1111 0111 1111
-128
原码:1000 0000 1000 0000
反码:1111 1111 0111 1111
补码:1111 1111 1000 0000
#include<iostream>
#include <bitset>
#include <climits>
using namespace std;
int main()
{
int t = INT_MIN ;
for(int i = 31;i>=0;i--)
cout << bitset<1>((t>>i)&1);
cout << endl;
cout << bitset<sizeof(int) * 8>(t) << endl;
char x = CHAR_MIN;
cout << bitset<sizeof(char) * 8>(x)<< endl;
}
输出:
11111111111111111111111110000000
10000000
char 与int 类型的转换
int 转 char: 取最低的8位。
#include<iostream>
#include <cstdio>
#include <bitset>
using namespace std;
int main()
{
int t = -1;
cout << bitset<sizeof(int) * 8>(t) << endl;;
char t_c = (int)t;
unsigned char t_uc =(int) t;
printf("%d\t%d\n",t_c,t_uc);//按10进制输出
}
输出:
11111111111111111111111111111111
-1 255
char 转int
对于signed char在前面补三个字节长度的0或者1,根据原来的字节首位是0还是1来决定。
对于unsigned char,在前面补三个字节长度的0。
#include<iostream>
#include <cstdio>
#include <bitset>
using namespace std;
int main()
{
char c = -128;
int d = (int)c;
unsigned int d_u = (int) c;
cout << bitset<sizeof(int) * 8>(d) <<" " << d<<endl;
cout << bitset<sizeof(int) * 8>(d_u) <<" " << d_u<<endl;
unsigned char c_u = 255;
d = (int)c_u;
d_u = (unsigned int)c_u;
cout << bitset<sizeof(int) * 8>(d) <<" " << d<<endl;
cout << bitset<sizeof(int) * 8>(d_u) <<" " << d_u<<endl;
}
输出:
11111111111111111111111110000000 -128
11111111111111111111111110000000 4294967168
00000000000000000000000011111111 255
00000000000000000000000011111111 255
字符数组初始化
字符数组定义不初始化会被随机赋值,因此用到数组的时候一定要先进行初始化。有下面几种方法:
- 可以直接用{}:
char a[10]={}或者char a[10]={0}或者char a[10]={'\0'},就可以让a[10]数组中的所有元素全为0;char a[10]={'0'}这种方法初始化是得数字0的ASCII码字符,与前三种是不一样的。 - {}内写一个非0值只会让第一个元素为这个值,后面的依旧是0。例如
char a[3]={'0'},数组实际上被初始化为{48,0,0}。('0'是非0值,ASCII码数值为48)。 memset函数(#include <cstring>)或者fill函数(#include <algorithm>)char a[10]; menset(a,'9',10);//初始化为'9'char a[10]; file(a,a+10,'9');//初始化为'9'
int 与 char * 类型互换
#include<iostream>
#include<cstdlib>
using namespace std;
int main()
{
int a = 12389;
char s[10] = {};
itoa(a,s,10);
cout << s << endl;
s[0] = '9';
a = atoi(s);
cout << a << endl;
}
输出:
12389
92389
注:itoa和atoi只是一个示例,相应的还有ltoa、atol、atof等。
除此之外,利用springf来转化两者更为常用一些,,因为效率更高,sprintf和printf的用法一样,只是打印到的位置不同而已,前者打印给buffer字符串,后者打印给标准输出。
#include<iostream>
#include<cstdlib>
using namespace std;
int main()
{
int a = -12389;
char b[4] = "abc";
char s[10] = {};
sprintf(s,"%d%s",a,b);
cout << s << endl;
}
%m.nf意义
在C语言的输出中,%m.nf意义:1、f表示输出的数据是浮点数;2、n表示输出的数据保留小数点后n为小数,第n+1位四舍五入,若不足n位则补0;3、m表示输出数据在终端设备上占有m个字符,并右对齐,如果实际的位数小于m时,左边用空格补足。如果实际位数大于m,则以实际位数打印。
#include<cstdio>
int main()
{
float a= -123.456;
printf("%8.2f\n",a);
float b = 123.1;
printf("%08.2f\n",b);
}
输出:
-123.46
00123.10
sprintf函数的多种用法
除了上述谈到的格式化字符串之外,sprintf还有很多有趣的用法。
- 连接结尾没有’\0’的字符数组或字符串缓冲区
输出:#include<stdio.h> int main() { char a[] = {'1', '2', '3', '4'}; char b[] = {'5', '6', '7', '8'}; char buffer[10]; sprintf(buffer, "%.*s%.*s", sizeof(a),a, sizeof(b),b); printf("%s\n", buffer); return 0; }12345678 - 利用sprintf中的返回值
输出:#include<stdio.h> int main() { char buf[100]; int pos = 0; for(int j = 0; j < 10; j++) pos += sprintf(buf+pos, "%d-", j); buf[pos-1] = '\n';//将最后一个字符'-'转换为'\n' printf(buf); return 0; }0-1-2-3-4-5-6-7-8-9
new和malloc的区别
C语言提供了malloc和free两个系统函数,完成对堆内存的申请和释放。而C++则提供了两个关键字new和delete;
- new/delete是关键字,效率高于malloc和free。
- 配对使用,避免内存泄漏和多重释放。
- new/delete 主要是用在类对象的申请和释放。申请的时候会调用构造器完成初始化,释放的时候,会调用析构器完成内存清理。而malloc则不会调用构造函数,free也不会调用析构函数,因此malloc/free来处理C++的自定义类型不合适。具体来说:
-
使用new操作符来分配对象内存时会经历三个步骤:
- 第一步:调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
- 第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
- 第三步:对象构造完成后,返回一个指向该对象的指针。
-
使用delete操作符来释放对象内存时会经历两个步骤:
- 第一步:调用对象的析构函数。
- 第二步:编译器调用operator delete(或operator delete[])函数释放内存空间。
-
- malloc分配内存失败时会返回NULL,而new分配内存失败时会抛出bad_alloc。
//malloc int *a = (int *) malloc(sizeof(int) * 10); if(a == NULL) {} else{} //new try { int * a= new int(); } catch(bad_alloc) {} - 对于数组而言,如需要分配一个10个int型数据的数组
//new int * a = new int[10]; delete [] a; //malloc int * a = (int *) malloc(sizeof(int) * 10); free(a); - C++允许重载new/delete操作符,malloc不允许重载。
scanf、getchar、gets
- scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串。
- gets() 认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对 gets() 来说就是一个完整的字符串。
- getchar() 用来读取输入缓冲区的中字符。
#include<stdio.h>
int main()
{
char buf[123];
gets(buf);
printf("%s\n",buf);
char a,b;
a = getchar();
b = getchar();
printf("%c %c\n",a,b);
int x,y;
scanf("%d %d",&x,&y);
printf("%d %d",x,y);
return 0;
}
fork函数
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。(windows下除非使用Cygwin自带的GCC,其他如MinGW、MinGW-w64、TDM-GCC无法使用)
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
int main(){
int count = 0;
pid_t pid = fork();
if(pid < 0)
printf("error\n");
else if(pid == 0){
printf("Child Id = %d\n", getpid());
count++;
}else{
printf("Parent Id = %d\n", getpid());
count++;
}
printf("count = %d\n", count);
return 0;
}
输出:
Parent Id = 3496
count = 1
Child Id = 3497
count = 1
POSIX
POSIX,即Portable Operating System Interface,可移植操作系统接口。IEEE最初开发POSIX标准,是为了提高UNIX环境下应用程序的可移植性。POSIX库函数是C标准库函数的超集。
- C标准库函数
<assert.h> Contains the assert macro, used to assist with detecting logical errors and other types of bug in debugging versions of a program.
<complex.h> C99 A set of functions for manipulating complex numbers.
<ctype.h> Defines set of functions used to classify characters by their types or to convert between upper and lower case in a way that is independent of the used character set (typically ASCII or one of its extensions, although implementations utilizing EBCDIC are also known).
<errno.h> For testing error codes reported by library functions.
<fenv.h> C99 Defines a set of functions for controlling floating-point environment.
<float.h> Defines macro constants specifying the implementation-specific properties of the floating-point library.
<inttypes.h> C99 Defines exact width integer types.
<iso646.h> NA1 Defines several macros that implement alternative ways to express several standard tokens. For programming in ISO 646 variant character sets.
<limits.h> Defines macro constants specifying the implementation-specific properties of the integer types.
<locale.h> Defines localization functions.
<math.h> Defines common mathematical functions.
<setjmp.h> Declares the macros setjmp and longjmp, which are used for non-local exits.
<signal.h> Defines signal handling functions.
<stdalign.h> C11 For querying and specifying the alignment of objects.
<stdarg.h> For accessing a varying number of arguments passed to functions.
<stdatomic.h> C11 For atomic operations on data shared between threads.
<stdbool.h> C99 Defines a boolean data type.
<stddef.h> Defines several useful types and macros.
<stdint.h> C99 Defines exact width integer types.
<stdio.h> Defines core input and output functions
<stdlib.h> Defines numeric conversion functions, pseudo-random numbers generation functions, memory allocation, process control functions
<stdnoreturn.h> C11 For specifying non-returning functions.
<string.h> Defines string handling functions.
<tgmath.h> C99 Defines type-generic mathematical functions.
<threads.h> C11 Defines functions for managing multiple Threads as well as mutexes and condition variables.
<time.h> Defines date and time handling functions
<uchar.h> C11 Types and functions for manipulating Unicode characters.
<wchar.h> NA1 Defines wide string handling functions.
<wctype.h> NA1 Defines set of functions used to classify wide characters by their types or to convert between upper and lower case
- POSIX API
<aio.h> Asynchronous input and output Issue 5
<arpa/inet.h> Functions for manipulating numeric IP addresses (part of Berkeley sockets) Issue 6
<assert.h> Verify assumptions ??
<complex.h> Complex Arithmetic, see C mathematical functions ??
<cpio.h> Magic numbers for the cpio archive format Issue 3
<dirent.h> Allows the opening and listing of directories Issue 2
<dlfcn.h> Dynamic linking Issue 5
<errno.h> Retrieving Error Number ??
<fcntl.h> File opening, locking and other operations Issue 1
<fenv.h> Floating-Point Environment (FPE), see C mathematical functions ??
<float.h> Floating-point types, see C data types ??
<fmtmsg.h> Message display structures Issue 4
<fnmatch.h> Filename matching Issue 4
<ftw.h> File tree traversal Issue 1
<glob.h> Pathname "globbing" (pattern-matching) Issue 4
<grp.h> User group information and control Issue 1
<iconv.h> Codeset conversion facility Issue 4
<inttypes.h> Fixed sized integer types, see C data types ??
<iso646.h> Alternative spellings, see C alternative tokens ??
<langinfo.h> Language information constants – builds on C localization functions Issue 2
<libgen.h> Pathname manipulation Issue 4
<limits.h> Implementation-defined constants, see C data types ??
<locale.h> Category macros, see C localization functions ??
<math.h> Mathematical declarations, see C mathematical functions ??
<monetary.h> String formatting of monetary units Issue 4
<mqueue.h> Message queue Issue 5
<ndbm.h> NDBM database operations Issue 4
<net/if.h> Listing of local network interfaces Issue 6
<netdb.h> Translating protocol and host names into numeric addresses (part of Berkeley sockets) Issue 6
<netinet/in.h> Defines Internet protocol and address family (part of Berkeley sockets) Issue 6
<netinet/tcp.h> Additional TCP control options (part of Berkeley sockets) Issue 6
<nl_types.h> Localization message catalog functions Issue 2
<poll.h> Asynchronous file descriptor multiplexing Issue 4
<pthread.h> Defines an API for creating and manipulating POSIX threads Issue 5
<pwd.h> passwd (user information) access and control Issue 1
<regex.h> Regular expression matching Issue 4
<sched.h> Execution scheduling Issue 5
<search.h> Search tables Issue 1
<semaphore.h> POSIX semaphores Issue 5
<setjmp.h> Stack environment declarations ??
<signal.h> Signals, see C signal handling ??
<spawn.h> Process spawning Issue 6
<stdarg.h> Handle Variable Argument List ??
<stdbool.h> Boolean type and values, see C data types ??
<stddef.h> Standard type definitions, see C data types ??
<stdint.h> Integer types, see C data types ??
<stdio.h> Standard buffered input/output, see C file input/output ??
<stdlib.h> Standard library definitions, see C standard library ??
<string.h> Several String Operations, see C string handling ??
<strings.h> Case-insensitive string comparisons Issue 4
<stropts.h> Stream manipulation, including ioctl Issue 4
<sys/ipc.h> Inter-process communication (IPC) Issue 2
<sys/mman.h> Memory management, including POSIX shared memory and memory mapped files Issue 4
<sys/msg.h> POSIX message queues Issue 2
<sys/resource.h> Resource usage, priorities, and limiting Issue 4
<sys/select.h> Synchronous I/O multiplexing Issue 6
<sys/sem.h> XSI (SysV style) semaphores Issue 2
<sys/shm.h> XSI (SysV style) shared memory Issue 2
<sys/socket.h> Main Berkley sockets header Issue 6
<sys/stat.h> File information (stat et al.) Issue 1
<sys/statvfs.h> File System information Issue 4
<sys/time.h> Time and date functions and structures Issue 4
<sys/times.h> File access and modification times Issue 1
<sys/types.h> Various data types used elsewhere Issue 1
<sys/uio.h> Vectored I/O operations Issue 4
<sys/un.h> Unix domain sockets Issue 6
<sys/utsname.h> Operating system information, including uname Issue 1
<sys/wait.h> Status of terminated child processes (see wait) Issue 3
<syslog.h> System error logging Issue 4
<tar.h> Magic numbers for the tar archive format Issue 3
<termios.h> Allows terminal I/O interfaces Issue 3
<tgmath.h> Type-Generic Macros, see C mathematical functions ??
<time.h> Type-Generic Macros, see C date and time functions ??
<trace.h> Tracing of runtime behavior (DEPRECATED) Issue 6
<ulimit.h> Resource limiting (DEPRECATED in favor of <sys/resource.h>) Issue 1
<unistd.h> Various essential POSIX functions and constants Issue 1
<utime.h> inode access and modification times Issue 3
<utmpx.h> User accounting database functions Issue 4
<wchar.h> Wide-Character Handling, see C string handling ??
<wctype.h> Wide-Character Classification and Mapping Utilities, see C character classification ??
<wordexp.h> Word-expansion like the shell would perform
windows下编译工具的选择:
- 从目标上说,MinGW 是让Windows 用户可以用上GNU 工具,比如GCC。Cygwin 提供完整的类Unix 环境,Windows 用户不仅可以使用GNU 工具,理论上Linux 上的程序只要用Cygwin 重新编译,就可以在Windows 上运行。
- 从能力上说,如果程序只用到C/C++ 标准库,可以用MinGW 或Cygwin 编译。如果程序还用到了POSIX API,则只能用Cygwin 编译。
- 从依赖上说,程序经MinGW 编译后可以直接在Windows 上面运行。程序经Cygwin 编译后运行,需要依赖安装时附带的cygwin1.dll。
参考
static 变量和static 成员函数
程序在内存中一般分为4个区域:代码区、全局数据区、堆区和栈区。new分配的内存放在堆区,函数内部的自动变量放在栈区。
一、面向过程
1.静态全局变量
静态全局变量存放在全局数据区,如果不显示初始化,就会默认初始化为0,不能被其他文件所引用。
2.静态局部变量
静态局部变量存放在全局数据区,但其作用域为局部作用域,如果不显示初始化,就会默认初始化为0。
3.静态函数
通常不希望被其他文件引用的函数声明为静态函数。
二、面向对象
1.静态数据成员
为整个类服务,而非某个对象服务,用解决数据共享问题。声明在类内进行,但是初始化要在类外进行。
2.静态成员函数
静态成员函数不能直接调用类中的非静态成员变量,需通过对象来调用。
class StaticTest
{
public:
StaticTest(int a, int b, int c);
void GetNumber();
void GetSum();
static void f1(StaticTest &s);
private:
int A, B, C;
static int Sum;
};
#include "StaticTest.h"
#include <iostream>
using namespace std;
int StaticTest::Sum = 0;//静态成员在此初始化
StaticTest::StaticTest(int a, int b, int c)
{
A = a;
B = b;
C = c;
Sum += A + B + C;
}
void StaticTest::GetNumber()
{
cout << "Number = " << endl;
}
void StaticTest::GetSum()
{
cout << "Sum = " << Sum <<endl;
}
void StaticTest::f1(StaticTest &s)
{
cout << s.A << endl;//静态方法不能直接调用一般成员,可以通过对象引用实现调用
cout << Sum <<endl;
}
#include "StaticTest.h"
#include <stdlib.h>
int main(void)
{
StaticTest M(3, 7, 10), N(14, 9, 11);
M.GetNumber();
N.GetSum();
M.GetNumber();
N.GetSum();
StaticTest::f1(M);
system("pause");
return 0;
}
多态、继承和虚函数
多态
在基类的函数前面加上virtual关键字,在派生类重写该函数,这样,如果在主函数中定义了一个指向派生类对象的基类指针,在运行时就会发生动态绑定,根据对象的实际类型来调用对应的函数。
对于每个包含虚函数的类,都会有一个虚函数表,与之对应还有指向虚函数表的虚表指针。构造函数的调用顺序是在构造子类对象时,要先调用父类的构造函数,之后再完成子类的构造。在调用父类的构造函数时,编译器只“看到了”父类,并不知道后面是否后还有继承者,它初始化虚表指针,将该虚表指针指向父类的虚表。当执行子类的构造函数时,虚表指针被重新赋值,指向自身的虚表。
虚函数和纯虚函数区别
- 纯虚函数必须在派生类中重新进行定义。
- 定义了纯虚函数的类是一个抽象类,不能被实例化。打个比方,在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。
虚析构函数
如果有有个派生类申请了内存空间,并在析构函数中进行释放,然后,你为了实现多态,你使用基类的指针指向了派生类的对象,这个时候基类就必须要虚析构函数,否则,调用基类指针的析构函数时无法发生动态绑定,就不用调用派生类的析构函数,也就无法释放派生类对象申请了内存了,也就发生了内存泄露。
extern关键字
变量
extern int a;//声明一个全局变量a,而不分配内存,表明a在其他文件定义的
int a; //定义一个全局变量a
extern int a =0 ;//定义一个全局变量a 并给初值。
int a =0;//定义一个全局变量a,并给初值,与上面等价
函数
int fun(void);//函数声明,省略了extern,完整些是extern int fun(void);
int fun(void)
{
return 0;
}//一个完整的全局函数定义,因为有函数体,extern同样被省略了。
总之,extern 和 static是相对的。不论变量定义还是函数定义默认都为extern。
多文件编译
1.使用函数声明
//main.c
#include <stdio.h>
#include <stdlib.h>
int myMax(int a,int b);
int main(){
int i = myMax(20,40);
printf("i = %d",i);
system("pause");
return 0;
}
//test.c
int myMax(int a,int b) {
if(a>b)
return a;
return b;
}
// gcc main.c test.c
2.使用头文件
//main.c
#include <iostream>
#include "test.h"
int main() {
printf("较大的数字是:%d\n",myMax(20,30));
return 0;
}
//test.h
int myMax(int a,int b);
//test.c
int myMax(int a,int b){
if(a>b)
return a;
return b;
}
//gcc main.c test.c
宏定义
#include <stdio.h>
#define S(a,b) a*b
int main(void)
{
int n = 3;
int m = 5;
printf("%d",S(n+m,m+n));
return 0;
}
结果:3+5*5+3=31.
交换值
temp = a;
a = b;
b =temp;
a = a + b;
b = a - b;
a = a - b;
a ^= b;
b ^= a;
a ^= b;
volatile 的作用
volatile 指出变量是随时可能发生变化的,每次使用它的时候必须从i的地址中读取,而不能从中间寄存器中直接取值,从而避免了编译器对代码的优化。
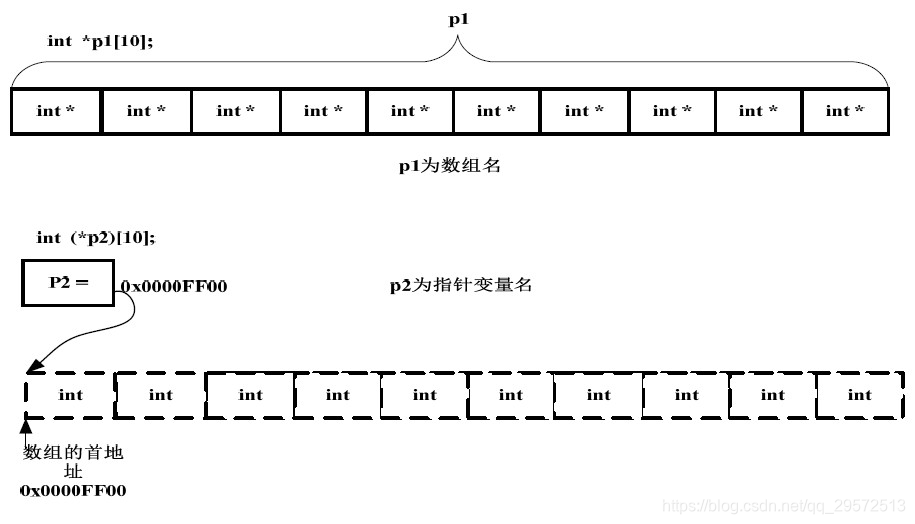
指针数组和数组指针
指针是左值,而数组名只是一个地址常量,它不可以被修改,所以数组名不是左值。
int (*p1)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
int *p2[3]; //[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。
#include <stdio.h>
int main()
{
int array[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int *p = (int *)(&array + 1);
printf("%d\n", *(p - 6));
return 0;
}
输出:4
注:这里p指向整个数组的下一个位置,即第11个位置,相当于越界了。因此(p - 6)指向数组第5个位置。
Cmake 支持c++11方法
add_definitions(-std=c++11)
or
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
or
add_compile_options(-std=c++11)














 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









