







 本文详细介绍了Least-Squares Policy Iteration (LSPI)在解决经典强化学习问题——car-on-the-hill问题上的应用。通过离线和在线乐观LSPI算法的实施与比较,展示其在策略迭代中的行为。离线LSPI通常在7-9次迭代中收敛,而在线LSPI在模拟实验中展现出与离线算法相当的性能,尽管步幅较小。此外,价值迭代算法作为对比,收敛速度较慢。LSPI在解决此类问题时,执行时间较长,但能有效找到近似最优策略。
本文详细介绍了Least-Squares Policy Iteration (LSPI)在解决经典强化学习问题——car-on-the-hill问题上的应用。通过离线和在线乐观LSPI算法的实施与比较,展示其在策略迭代中的行为。离线LSPI通常在7-9次迭代中收敛,而在线LSPI在模拟实验中展现出与离线算法相当的性能,尽管步幅较小。此外,价值迭代算法作为对比,收敛速度较慢。LSPI在解决此类问题时,执行时间较长,但能有效找到近似最优策略。
《Reinforcement Learning: State-of-the-Art》 第三章 Least-Squares Methods for Policy Iteration 第五节 举例说明最小二乘法对策略迭代的行为。
将离线LSPI和在线乐观LSPI两种方法,应用于car-on-the-hill问题(Moore和Atkeson,1995),这是近似强化学习的经典benchmark。
由于其维度低,这个问题可以使用简单的线性逼近器来解决,基函数分布在等距网格上。 我们专注于算法的行为。
1.问题模型
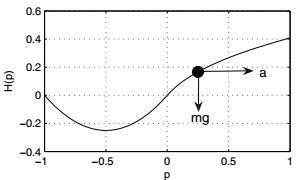
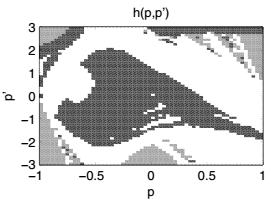
图1 左:山上的汽车,小车显示为黑色点。 右:近乎最优的策略(黑色表示a = -4,白色表示a = +4,灰色表示两个行为同样好)
在山上车问题中,必须通过施加水平力驱动质点小车越过无摩擦的山顶。 对于一些初始状态,由于可用力有限,必须首先将汽车向左侧,向上相反的斜坡驱动,并获得向右加速前朝向目标动量。
用 表示汽车的水平位置,它的动力学模型是(在Ernst等人,2005的变体中):
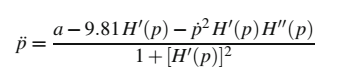 (1)
(1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









