





论文名称:基于自监督学习的大规模项目推荐
论文主要内容:
本文主要提出了 SSL 框架,采用对比学习的方式用于推荐中召回模型的训练,使模型取得更好的效果。
动机:
自监督学习再 CV 和 NLP 领域取得很好的效果,是否在推荐系统上也能获取更好的效果。
贡献:
- 提出 SSL 框架,用于辅助学习;
- 数据增强;
1. 自监督学习在 CV 和 NLP 领域比较常用,因为做起来较为方便。在 CV 领域,直接对图像进行旋转、裁剪等操作,就能进行数据增强;而在 NLP 领域,通过类似于 Word2vec 的方式,mask 掉句子中某个词语,就能做到 SSL。
2.对于推荐系统来说,其数据会很稀疏,原因包括:
- 数据分布是高度倾斜度的,长尾分布,这样导致长尾项目不能被充分的学习;
- 用户反馈的缺失,只有模糊隐含的正反馈,不够细致化。
3.SSL 框架图如下图所示, xi 和 xj 经过两种数据增强的方式(h 和 g),得到 yi、yi'、yj、yj',对应的 emb 是 zi、zi'、zj、zj',优化的方向是 maximize (zi 和 zi' 的相似度),minimize (zi 和 zj 的相似度),minimize (zi 和 zj' 的相似度)。传统上,针对 item 的 数据增强,是采用随机特征掩膜(RFM)。

4.作者尝试通过数据增强的方法,把同一个商品 xi 变成两种不同的输入 yi 和 yi', 并得到两 emb,借助自监督 Loss,提升模型对商品特征的辨别能力。基于以上正负样本,给出自监督 Loss 为
( 是温度系数,N 是batch size)

5.文中提出的数据增强的方法包括:
- Dropout:对于 multi-hot 的特征,通过对每一维特征设置 dropout 实现增强
- Masking:通过设置掩膜,将 item 的部分类目特征设为默认值(即输入为默认的emb),该步骤也可以看作对某个特征做了100% 的 dropout
6.对于 masking的方式,作者希望将特征划分为无重叠的两部分,并为此提出了2种划分方法:
RFM(Random Feature Masking): 随机掩膜,但在输入特征里,本身就可能存在相关度较高的特征,该方法划分出的2个输入,特征见可能相关性较大,导致自监督任务太简单,对模型没有增益
CFM(Correlated Feature Masking):随机选一个种子 feature,计算每个特征与它的互信息,将 TopK 个相似的特征与种子特征融合,作为一个输入,其他特征作为另一个输入;这里,作者的TopK为实际特征维度的一半,公式如下:
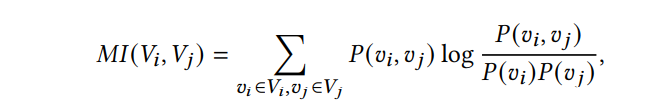
7.双塔模型
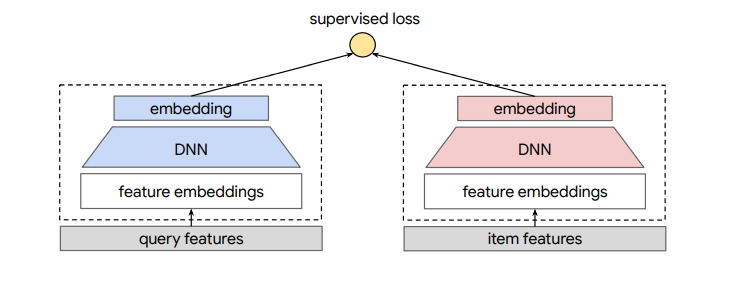
模型总的来说可以分成三层结构,分别是输入层、表示层和匹配层。
-
输入层 :将用户、物品的信息转化为数值特征输入;
-
表示层 :进一步用神经网络模型学习特征表示;
-
匹配层 :计算用户特征向量与物品特征向量的相似度。
8.模型结构
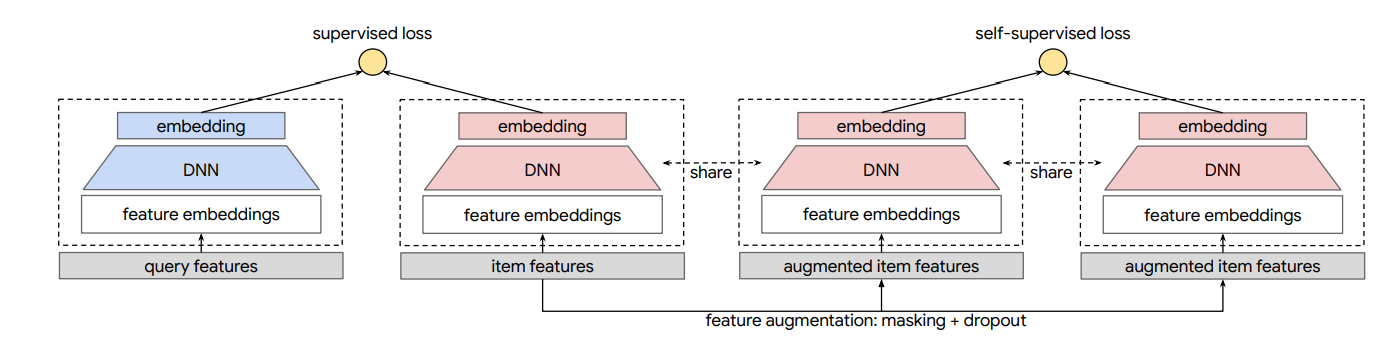
模型架构:带有 SSL 的两塔模型。在 SSL 任务中,我们对项目特征应用特征掩码和 dropout 来学习项目嵌入。整个项目塔(红色)与监督任务共享。
9.多任务学习
作者把 SSL 作为一个辅助损失,编码器(H、G)复用 item 塔的网络;整体 loss 为

其中,{ qi,xi } 为原双塔模型的训练数据(监督样本),{ xi } 是自监督的训练样本。作者这里构建了两条样本流分别对不同 loss 做训练,自监督 loss 没有复用监督样本得原因是长尾商品在监督样本中出现的频率低,监督样本中商品为长尾分布,自监督 loss 的一个作用就是充分学习长尾商品的表达,因此才用均匀分布从商品库中提取自监督的训练样本 { xi }。

10.实验
数据集:

Baseline:
- 双塔DNN;
- Feature Dropout (FD):在item塔进行feature dropout,没有联合学习;
- Spread-out Regularization (SO) :没有数据增强,有联合学习;
Result:
















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









