







文章目录
- 一、智能进化算法-LSTM(优化超参数)
- 1.金枪鱼算法TSO-LSTM——案例1
- 2.孔雀优化算法(POA)-LSTM——案例1
- 3.猎人优化算法(HPO)-LSTM——案例1
- 4.人工大猩猩部队优化算法(GTO)-LSTM——案例1
- 5.象鼻虫算法(WOA)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
- 6.草原犬鼠算法(PDO)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
- 7.人工兔算法(ARO)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
- 8.火鹰算法(FHO)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
- 二、改进的智能进化算法-LSTM(优化超参数)
- 1. 智能算法改进:改进蝠鲼觅食优化算法(dFDB-MRFO)-LSTM
- 2. 智能算法组合
- 3.收敛因子
- 4.混沌映射Tent
- 5.基于levy飞行
- 三、LSTM-CNN(提取特征)
- 1.LSTM-CNN
- 2.QR(分位数回归)-LSTM-CNN
- 3.Attention-QR-LSTM-CNN
一、智能进化算法-LSTM(优化超参数)
概述:
1.原理:通过进化算法寻找LSTM网络最优超参数,智能进化算法原理省略不讲。
2.本文测试数据为12输入单输出,解决回归问题。
3.评价指标:测试集实际值与预测值对比,目标函数为rmse,另外附MAE、MAPE、R2计算值。
4.常见优化LSTM三个参数,即隐含层神经元数,学习率,训练次数;
5.本代码进化算法为测试参数,为了提高运算速度,迭代次数为3,种群数量为5,可自行修改。
2.本文测试数据为12输入单输出,解决回归问题。
3.评价指标:测试集实际值与预测值对比,目标函数为rmse,另外附MAE、MAPE、R2计算值。
4.常见优化LSTM三个参数,即隐含层神经元数,学习率,训练次数;
5.本代码进化算法为测试参数,为了提高运算速度,迭代次数为3,种群数量为5,可自行修改。
1.金枪鱼算法TSO-LSTM
%TSO_LSTM
clear all;
close all;
clc;
Particles_no = 10; % 种群数量 50
Function_name=‘LSTM_MIN’;
Max_iter = 3; % 迭代次数 10
Low = [10 0.001 10 ];%三个参数的下限
Up = [200 0.02 200 ];%三个参数的上限
Dim = 3;%待优化参数数量
fobj = @(x)LSTM_MIN(x);
train_x=input(:,1:n);
train_y=output(:,1:n);
test_x=input(:,n+1:end);
test_y=output(:,n+1:end);
method=@mapminmax;
% method=@mapstd;
[train_x,train_ps]=method(train_x);
test_x=method(‘apply’,test_x,train_ps);
[train_y,output_ps]=method(train_y);
test_y=method(‘apply’,test_y,output_ps);
XTrain = double(train_x) ;
XTest = double(test_x) ;
YTrain = double(train_y);
YTest = double(test_y);
numFeatures = size(XTrain,1); %输入特征维数
numResponses = size(YTrain,1);%输出特征维数
layers = [ …
sequenceInputLayer(numFeatures)%输入层,参数是输入特征维数
lstmLayer(Tuna1(1,1))%lstm层,如果想要构建多层lstm,改几个参数就行了
fullyConnectedLayer(numResponses)%全连接层,也就是输出的维数
regressionLayer];%该参数说明是在进行回归问题,而不是分类问题
options = trainingOptions(‘adam’, …%求解器设置为’adam’
‘MaxEpochs’,Tuna1(1,3), …%这个参数是最大迭代次数,即进行200次训练,每次训练后更新神经网络参数
‘MiniBatchSize’,16, …%用于每次训练迭代的最小批次的大小。
‘InitialLearnRate’,Tuna1(1,2), …%学习率
‘GradientThreshold’,1, …%设置梯度阀值为1 ,防止梯度爆炸
‘Verbose’,false, …%如果将其设置为true,则有关训练进度的信息将被打印到命令窗口中。
‘Plots’,‘training-progress’);%构建曲线图
%对每个时间步进行预测,对于每次预测,使用前一时间步的观测值预测下一个时间步。
net = trainNetwork(XTrain,YTrain,layers,options);
numTimeStepsTest = size(XTest,2);
for i = 1:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,XTest(:,i),‘ExecutionEnvironment’,‘cpu’);
end
% 结果
% 反归一化
predict_value=method(‘reverse’,YPred,output_ps);
predict_value=double(predict_value);
true_value=method(‘reverse’,YTest,output_ps);
true_value=double(true_value);
for i=1
figure
plot(true_value(i,:),’-’,‘linewidth’,2)
hold on
plot(predict_value(i,:),’-s’,‘linewidth’,2)
legend(‘实际值’,‘预测值’)
grid on
title(‘TSO-LSTM预测结果’)
ylim([-500 500])
rmse=sqrt(mean((true_value(i,:)-predict_value(i,:)).^2));
disp([’-----------’,num2str(i),’------------’])
disp([‘均方根误差(RMSE):’,num2str(rmse)])
mae=mean(abs(true_value(i,:)-predict_value(i,:)));
disp([‘平均绝对误差(MAE):’,num2str(mae)])
mape=mean(abs((true_value(i,:)-predict_value(i,:))./true_value(i,:)));
disp([‘平均相对百分误差(MAPE):’,num2str(mape100),’%’])
r2=R2(true_value(i,:),predict_value(i,:));
disp([‘R-square决定系数(R2):’,num2str(r2)])
end
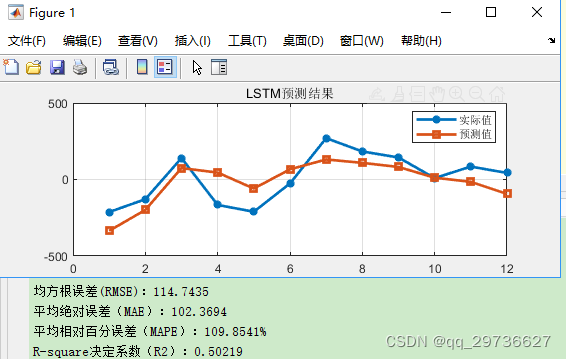
实际效果以自己的数据为准,本文测试结果并不代表算法最终效果。不同数据,数据处理方式,待优化参数等均不同。
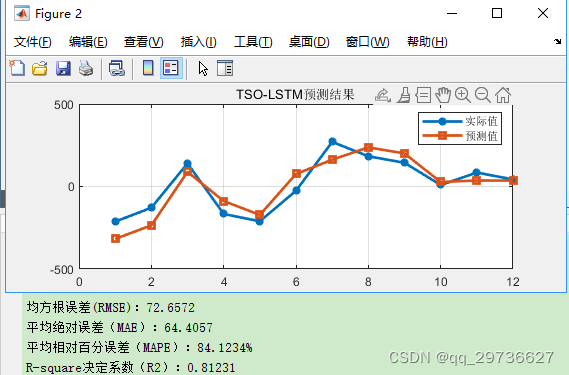
2.孔雀优化算法(POA)-LSTM
与上文同数据、同进化算法设置参数。效果仅供参考
实现效果如下(示例):
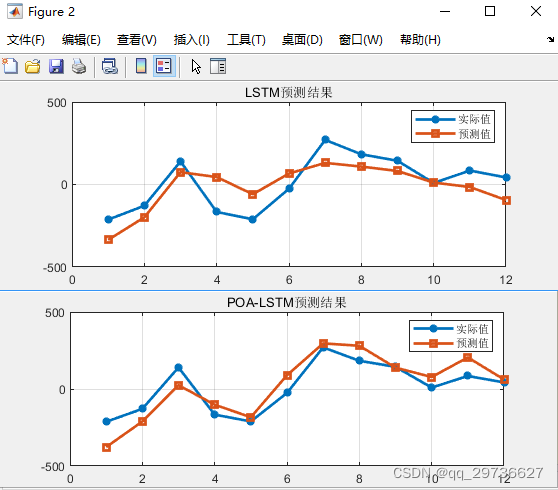
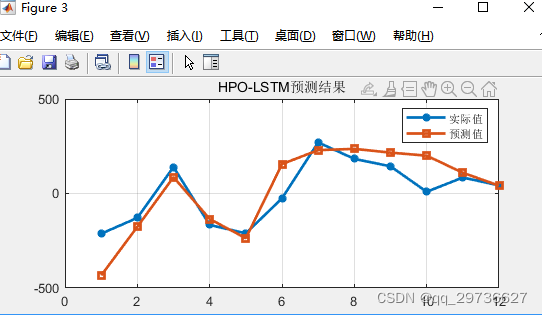
3.猎人优化算法(HPO)-LSTM
1.2021年Iraj Naruei等人提出的猎人优化算法,Hunter–prey optimization, 与LSTM网络结合,优化LSTM超参数。
2.该算法的灵感来自狮子、豹子和狼等捕食性动物以及雄鹿和瞪羚等猎物的行为。动物狩猎行为的场景有很多,其中一些已经转化为优化算法。本文使用的场景与之前算法的场景不同。在提议的方法中,猎物和捕食者种群以及捕食者攻击远离猎物种群的猎物。猎人向着这个远处的猎物调整自己的位置,而猎物则向着安全的地方调整自己的位置。作为适应度函数最佳值的搜索代理的位置被认为是安全的位置。在几个测试函数上实现的 HPO 算法以评估其性能。此外,对于性能验证,所提出的算法被应用于几个工程问题。结果表明,所提出的算法在解决测试功能和工程问题方面表现良好。
3.本文为测试数据,12输入,单输出,回归问题。与上文同数据、同进化算法设置参数。效果仅供参考。
实现效果如下(示例):
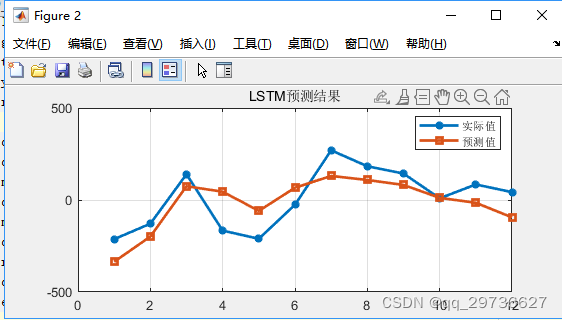
4.人工大猩猩部队优化算法(GTO)-LSTM
本文为测试数据,12输入,单输出,回归问题。与上文同数据、同进化算法设置参数。效果仅供参考。
实现效果如下(示例):
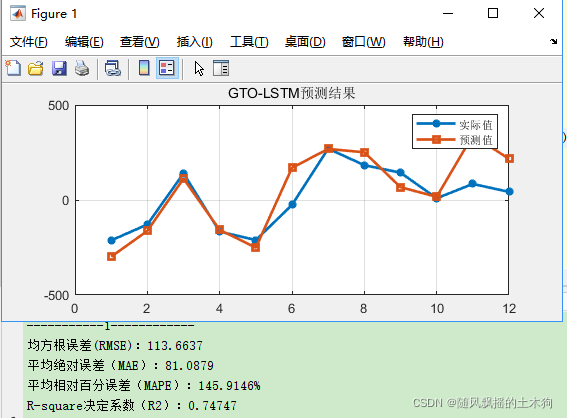
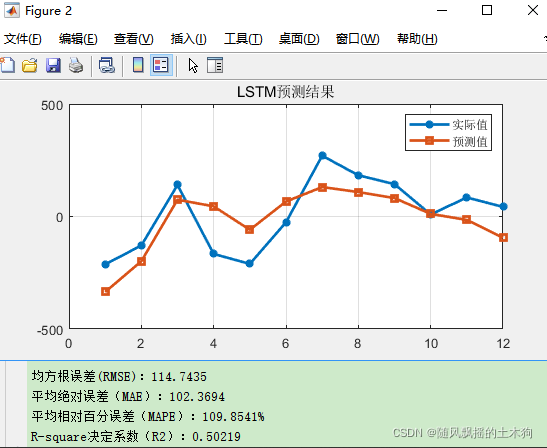
5.象鼻虫算法(WOA)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
操作运行视频如下:
2022年象鼻虫算法(WOA)-LSTM
Weevil 优化算法 (WOA)
作者: 赛义德·穆罕默德·侯赛因·穆萨维
% Weevil 优化算法 (WOA)
% 由 Seyed Muhammad Hossein Mousavi 开发 - 2022;% 象鼻虫,也称为 nunus,是属于超科的甲虫;Curculionoidea,以其细长的鼻子而闻名。许多象鼻虫被认为是害虫,因为它们能够破坏和杀死农作物。
引用格式
赛义德·穆罕默德·侯赛因·穆萨维 (2022)。Weevil 优化器算法
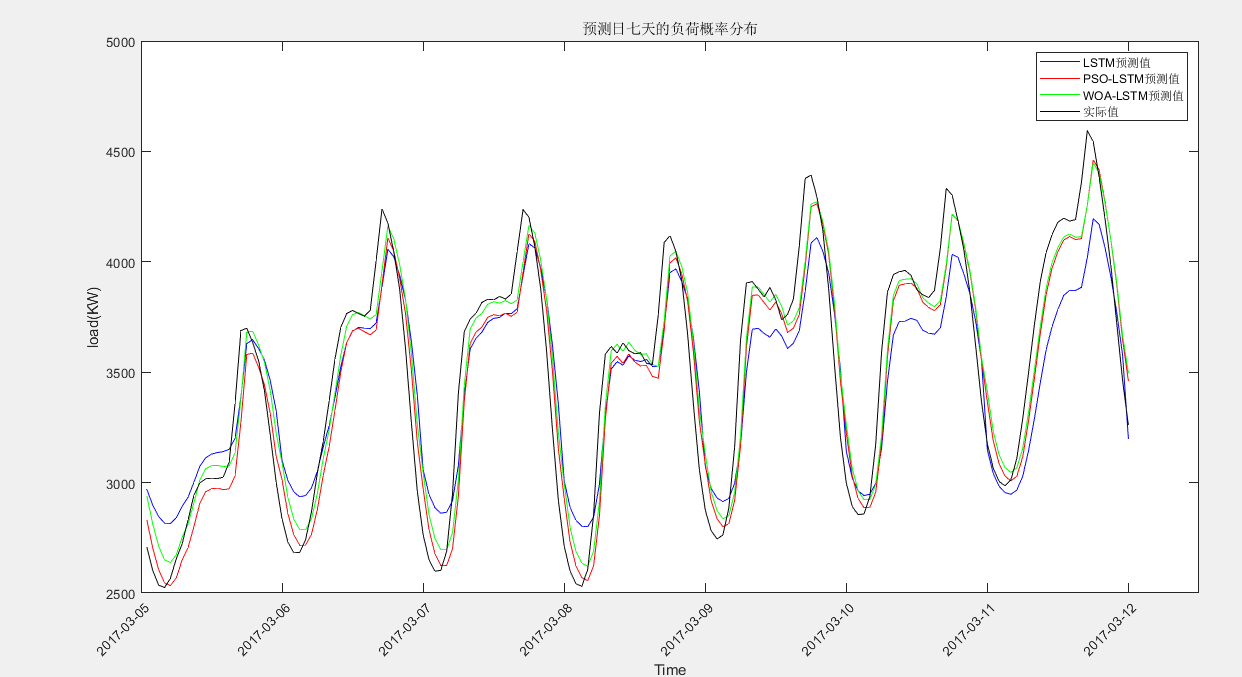
其中,WOA与LSTM优化参数一致,均为双层隐含层对应的神经元数, 迭代次数和学习率 。其次,为了便于计算,设置种群数量为5,迭代次数为2。
PSO-LSTM根均方差(RMSE):173.579
PSO-LSTM平均绝对误差(MAE):136.9961
PSO-LSTM平均相对百分误差(MAPE):3.9484%
PSO-LSTM决定系数(R2):0.9051
LSTM根均方差(RMSE):233.6107
LSTM平均绝对误差(MAE):194.5018
LSTM平均相对百分误差(MAPE):5.657%
LSTM决定系数(R2):0.85649
WOA-LSTM根均方差(RMSE):168.5163
WOA-LSTM平均绝对误差(MAE):130.863
WOA-LSTM平均相对百分误差(MAPE):3.871%
WOA-LSTM决定系数(R2):0.90586
6.草原犬鼠算法(PDO)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
操作视频如下:
2022年草原犬鼠算法(PDO)-LSTM
草原犬鼠优化算法
作者: 押沙龙·埃祖格乌
Prairie Dog Optimization (PDO) 是一种新的基于种群的元启发式算法,用于解决数值优化问题。
PDO 是一种新的受自然启发的元启发式算法,它模仿草原犬鼠在其自然栖息地的行为。所提出的算法使用四种草原犬鼠活动来实现两个常见的优化阶段,探索和利用。草原犬鼠的觅食和挖洞活动用于为 PDO 算法提供探索行为。
引用格式
Absalom E. Ezugwu、Jeffrey O. Agushaka、Laith Abualigah、Seyedali Mirjalili、Amir H Gandomi,“草原犬鼠优化算法”神经计算和应用,2022 年。DOI:10.1007/s00521-022-07530-9
其中,PDO与LSTM优化参数一致,均为双层隐含层对应的神经元数, 迭代次数和学习率 。其次,为了便于计算,设置种群数量为5,迭代次数为2。

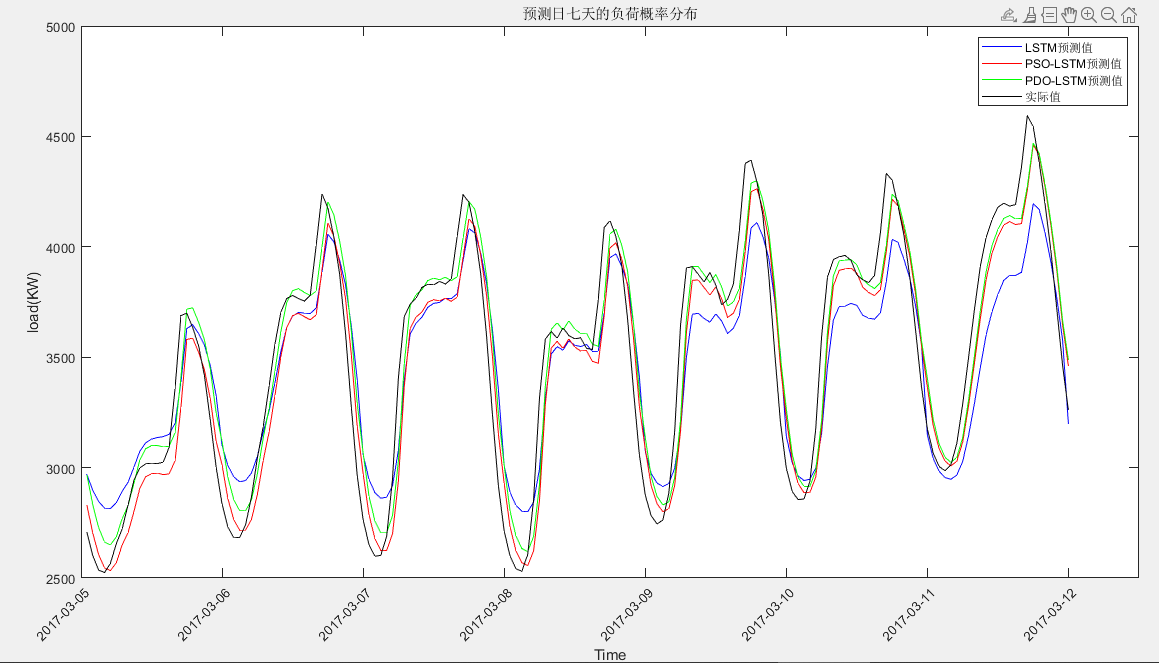
PSO-LSTM根均方差(RMSE):173.579
PSO-LSTM平均绝对误差(MAE):136.9961
PSO-LSTM平均相对百分误差(MAPE):3.9484%
PSO-LSTM决定系数(R2):0.9051
LSTM根均方差(RMSE):233.6107
LSTM平均绝对误差(MAE):194.5018
LSTM平均相对百分误差(MAPE):5.657%
LSTM决定系数(R2):0.85649
PDO-LSTM根均方差(RMSE):169.3895
PDO-LSTM平均绝对误差(MAE):132.0842
PDO-LSTM平均相对百分误差(MAPE):3.9328%
PDO-LSTM决定系数(R2):0.90469
7.人工兔算法(ARO)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
操作视频如下:
2022年人工兔算法(ARO)-LSTM
人工兔优化(ARO):一种新的仿生元启发式算法,用于解决工程优化问题;人工兔优化 (ARO) 的灵感来自自然界中兔子的生存策略。该算法有效且易于实现。
引用:Wang, L., Cao, Q., Zhang, Z., Mirjalili, S., & Zhao, W. (2022)。
http://https: //doi.org/10.1016/j.engappai.2022.105082
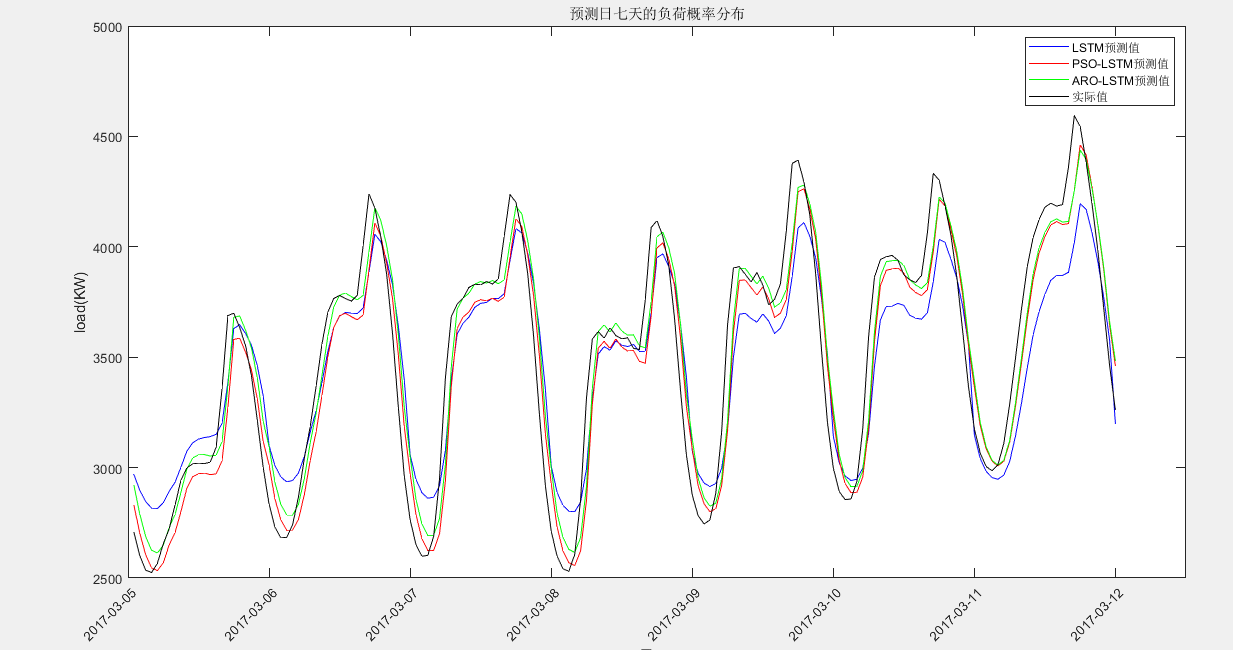
PSO-LSTM根均方差(RMSE):173.579
PSO-LSTM平均绝对误差(MAE):136.9961
PSO-LSTM平均相对百分误差(MAPE):3.9484%
PSO-LSTM决定系数(R2):0.9051
LSTM根均方差(RMSE):233.6107
LSTM平均绝对误差(MAE):194.5018
LSTM平均相对百分误差(MAPE):5.657%
LSTM决定系数(R2):0.85649
ARO-LSTM根均方差(RMSE):167.3975
ARO-LSTM平均绝对误差(MAE):128.4898
ARO-LSTM平均相对百分误差(MAPE):3.7967%
ARO-LSTM决定系数(R2):0.90527
8.火鹰算法(FHO)-LSTM——案例2(负荷预测并与PSO-LSTM/LSTM对比)
操作视频如下:
2022年火鹰算法FHO-LSTM
Fire Hawk Optimizer (FHO):一种新颖的元启发式算法
Fire Hawk Optimizer: a novel metaheuristic algorithm | SpringerLink
Fire Hawk Optimizer (FHO) 是一种基于口哨风筝、黑鸢和棕隼的觅食行为开发的新型元启发式算法。这些鸟被称为火鹰,考虑到它们在自然界捕捉猎物所采取的具体行动,特别是通过放火来捕捉猎物。
引用格式
阿齐兹、马赫迪等人。“火鹰优化器:一种新颖的元启发式算法。” 人工智能评论,Springer Science and Business Media LLC,2022 年 6 月,doi:10.1007/s10462-022-10173-w。

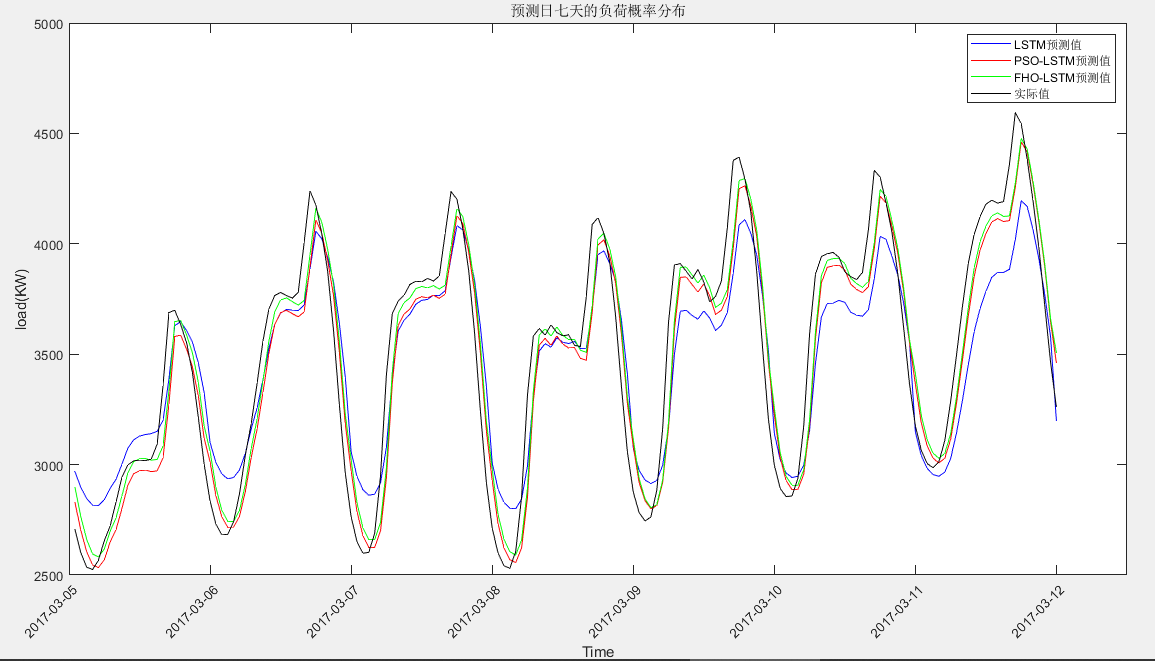
PSO-LSTM根均方差(RMSE):173.579
PSO-LSTM平均绝对误差(MAE):136.9961
PSO-LSTM平均相对百分误差(MAPE):3.9484%
PSO-LSTM决定系数(R2):0.9051
LSTM根均方差(RMSE):233.6107
LSTM平均绝对误差(MAE):194.5018
LSTM平均相对百分误差(MAPE):5.657%
LSTM决定系数(R2):0.85649
FHO-LSTM根均方差(RMSE):165.8632
FHO-LSTM平均绝对误差(MAE):127.8064
FHO-LSTM平均相对百分误差(MAPE):3.7457%
FHO-LSTM决定系数(R2):0.90644
二、改进的智能进化算法-LSTM(优化超参数)
1. 智能算法改进:改进蝠鲼觅食优化算法(dFDB-MRFO)-LSTM
dfDB-MRFO:强大的元启发式优化算法
操作视频如下:视频审核中,敬请期待
动态 FDB 选择方法:改进版平衡距离 dfDB-MRFO:使用 dFDB 改进的蝠鲼觅食优化器
论文链接:https ://link.springer.com/article/10.1007/s10489-021-02629-3
通过使用动态 FDB 选择方法,您可以将元启发式搜索算法转换为更强大和更有效的方法。为此,您应该分析元启发式搜索算法中的指南选择过程,并将动态FDB选择方法集成到该过程中。源代码中,我们将dFDB方法应用到了MRFO算法的导选过程中,实现了MRFO性能的独特提升。
Manta Ray Foraging Optimizer 已使用 dFDB 方法重新设计,因此开发了 dFDB-MRFO 算法以提高搜索性能。dFDB-MRFO 是一种最新且功能强大的元启发式搜索算法,可用于解决单目标优化问题。
引用格式
Kahraman, HT, Bakir, H., Duman, S., Kati, M., Aras, S., Guvenc, U. 动态 FDB 选择方法及其应用:定向过电流继电器协调的建模和优化。应用英特尔 (2021)。Dynamic FDB selection method and its application: modeling and optimizing of directional overcurrent relays coordination | SpringerLink
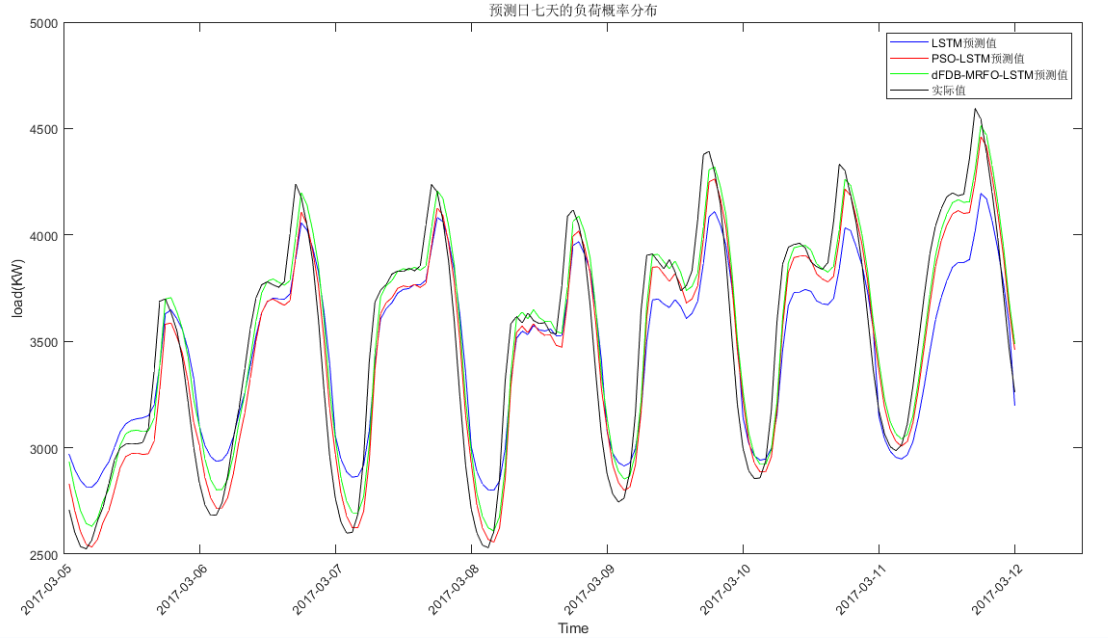
PSO-LSTM根均方差(RMSE):173.579
PSO-LSTM平均绝对误差(MAE):136.9961
PSO-LSTM平均相对百分误差(MAPE):3.9484%
PSO-LSTM决定系数(R2):0.9051
LSTM根均方差(RMSE):233.6107
LSTM平均绝对误差(MAE):194.5018
LSTM平均相对百分误差(MAPE):5.657%
LSTM决定系数(R2):0.85649
dFDB_MRFO-LSTM根均方差(RMSE):167.8976
dFDB_MRFO-LSTM平均绝对误差(MAE):130.1999
dFDB_MRFO-LSTM平均相对百分误差(MAPE):3.8654%
dFDB_MRFO-LSTM决定系数(R2):0.90504
%%%%%%%%%%%%%%%%待续%%%%%%%%%%%%%%%%
1.混沌映射Tent
2.收敛因子
3.多算法组合
4.基于levy飞行
本文将Levy飞行应用于鲸鱼的位置更新中,在算法进行更新后再进行一次Levy飞行更新个体位置,可以实现跳出局部最优解,扩大搜索能力的效果。位置更新的方式为:
X(t+1)=X(t)+α⊕Levy(λ)
其中,α \alphaα为步长缩放因子,本文取值为1;
Levy飞行的具体机制:
“莱维Levy飞行”以法国数学家保罗·莱维命名,指的是步长的概率分布为重尾分布的随机行走,也就是说在随机行走的过程中有相对较高的概率出现大跨步。莱维飞行的名称来源于本华·曼德博(Benoît Mandelbrot,莱维的学生)。他用“柯西飞行”来指代步长分布是柯西分布的随机行走,用“瑞利飞行”指代步长分布是正态分布(尽管正态分布没有重尾)的随机行走(瑞利分布是二维独立同方差正态变量模长的分布)。后来学者还进一步将莱维飞行的概念从连续空间推广到分立格点上的随机运动。
三、LSTM-CNN(提取特征)
1.LSTM-CNN
2.QR(分位数回归)-LSTM-CNN
3.Attention-QR-LSTM-CNN

















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











