







 斯坦福研究者提出的IMMA模型利用多层图注意力机制处理多智能体系统中的复杂交互,提高轨迹预测准确性和可解释性。通过隐空间的多层关系图,模型能更好地捕捉不同类型的交互,并通过逐层训练增强解耦,提升泛化能力。实验表明,IMMA在多个数据集上优于现有方法。
斯坦福研究者提出的IMMA模型利用多层图注意力机制处理多智能体系统中的复杂交互,提高轨迹预测准确性和可解释性。通过隐空间的多层关系图,模型能更好地捕捉不同类型的交互,并通过逐层训练增强解耦,提升泛化能力。实验表明,IMMA在多个数据集上优于现有方法。
搬来自斯坦福的研究者提出了 IMMA, 一种利用隐空间多层图 (multiplex latent graphs) 来表征多种独立的交互类型,并使用一种新型的多层图注意力机制 (multiplex attention mechanism) 来描述个体间交互强度的行为及轨迹预测模型。该方法不仅大幅提升了预测的准确度,同时也具有很强的可解释性 (interpretability) 和泛化能力 (zero-shot generalizability)。
-
论文链接:https://arxiv.org/abs/2208.10660
-
代码链接:https://github.com/fanyun-sun/IMMA
一.研究背景
对多智能体系统 (multi-agent systems) 的建模在很多领域和应用中起到重要作用,包括但不限于自动驾驶,移动机器人导航,以及人机协作。由于个体的行为会受到不同类型社会性交互 (social interactions) 的影响,多智能体系统的动力学建模面临着极高的挑战。
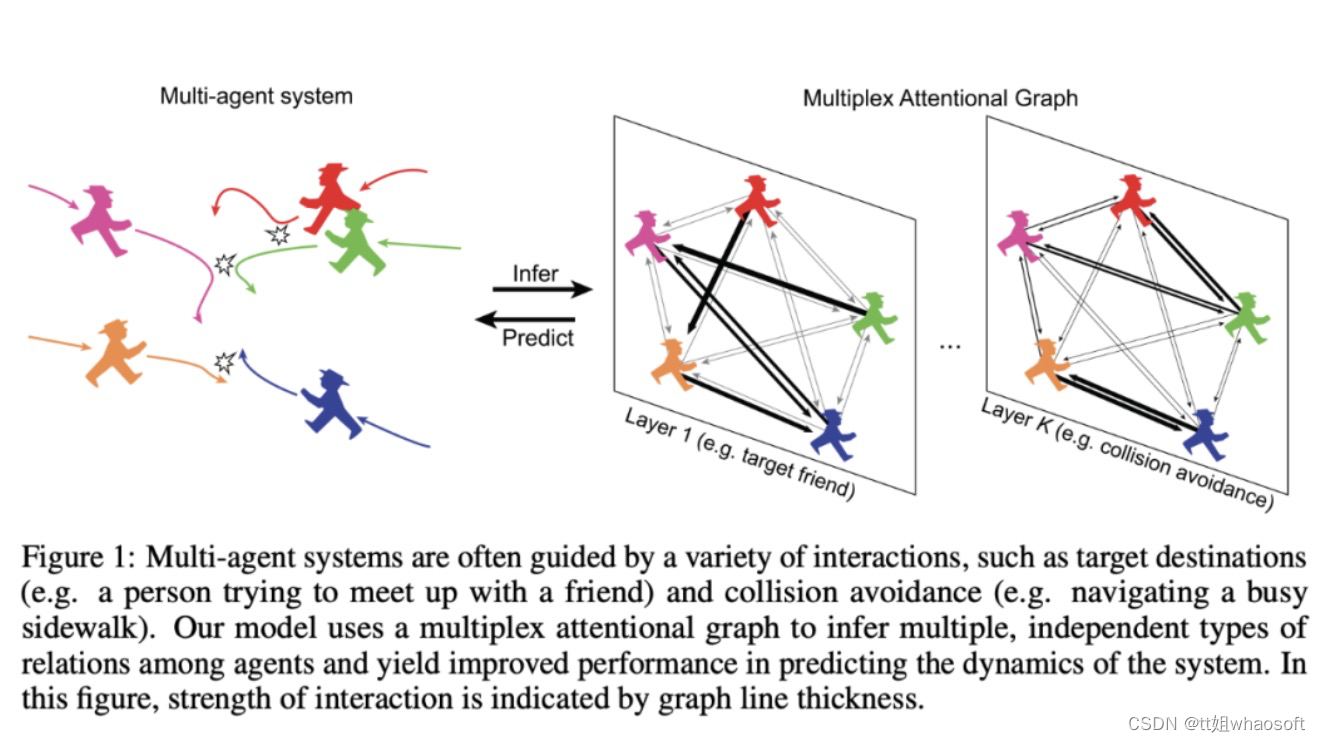
过去已有的方法例如 NRI[1]和 EvolveGraph[2]利用图神经网络 (GNN) 来推测每一对智能体之间的关系类型,但是这样并不能显式地对在多智能体系统中出现的不同层级的交互关系进行建模,从而导致模型的预测效果和可解释性下降。下面 Figure 1 介绍了生活中人与人之间交互的一个实例。
该研究提出了 IMMA(Interaction Modeling with Multiplex Attention)方法,通过利用隐空间中的多层关系图结构 (multiplex latent interaction graphs), 对不同层级中不同类型的交互关系进行推理,同时,该研究还设计了一种新的多层图注意力机制 (multiplex attention mechanism) 来学习每种交互关系的强度。另外,该研究还提出了一种逐层训练 (progressive layer training) 的方法来加强不同层的关系图之间的解耦,从而进一步提升了模型的可解释性 (interpretability) 和泛化能力 (zero-shot generalizability)。本文方法在多种不同领域的问题中都取得了最优效果,包括 social navigation, cooperative task achievement 和 team sports.
 二.研究方法
二.研究方法
问题描述:假设场景中包含 N 个智能体,模型的输入包含这 N 个智能体的轨迹,任务目标是根据过去一段时间内的轨迹观测来预测未来一段时间内的轨迹,同时要对智能体之间的交互关系进行建模和推理。
核心观点:在已有的方法中 ([1][2]),隐变量 z 中的每个元素表示交互关系图中对应的 edge 属于每一种可能的关系的概率,意味着用于 Decoder 的关系图中每一对智能体的关系只能是其中的一种。然而,复杂的交互系统中可能存在某些智能体之间同时存在多种相互独立的关系的情况,并且每种关系的强度也可能有所区别,仅通过一层关系图不能准确描述具有这类性质的多体系统。因此,该研究提出利用多层关系图拓扑结构来进行更精准的建模,不仅可以提升预测效果,同时也能用模型学到的多层关系图提供对模型预测的解释,一定程度上可以分析各智能体行为之间的因果关系。另外,由于多层关系图也可以提升模型在训练数据中没有包含的场景中取得更好的效果,增强泛化能力和训练样本效率(sample efficiency)。
模型介绍:该研究提出的模型 IMMA 由一个 Encoder 和一个 Decoder 组成。Encoder 的输入是一系列轨迹观测,输出是一个在隐空间内的交互关系图。Decoder 通过对推测出的关系图里面的信息进行传递和整合来生成对每个智能体未来轨迹的预测。下面 Figure 2 提供了模型示意图和进一步解释。模型整体基于 Conditional Variational Autoencoder 框架,并通过以下目标函数来训练模型参数:
三.实验结果和分析
本文的实验试图回答以下四个问题:
1. 本文方法 (IMMA w/ PLT) 是否在各种 social multiagent systems 数据集测试中始终优于已有的基准方法?
2.Multiplex attentional latent graph 的使用是否给模型提供了更多可解释性?
3. 模型中的每个模块对模型效果的提升有多大贡献?
4. 本文方法相比于基准方法是否可以提升 sample efficiency?它是否可以很好地泛化到新环境或新场景?
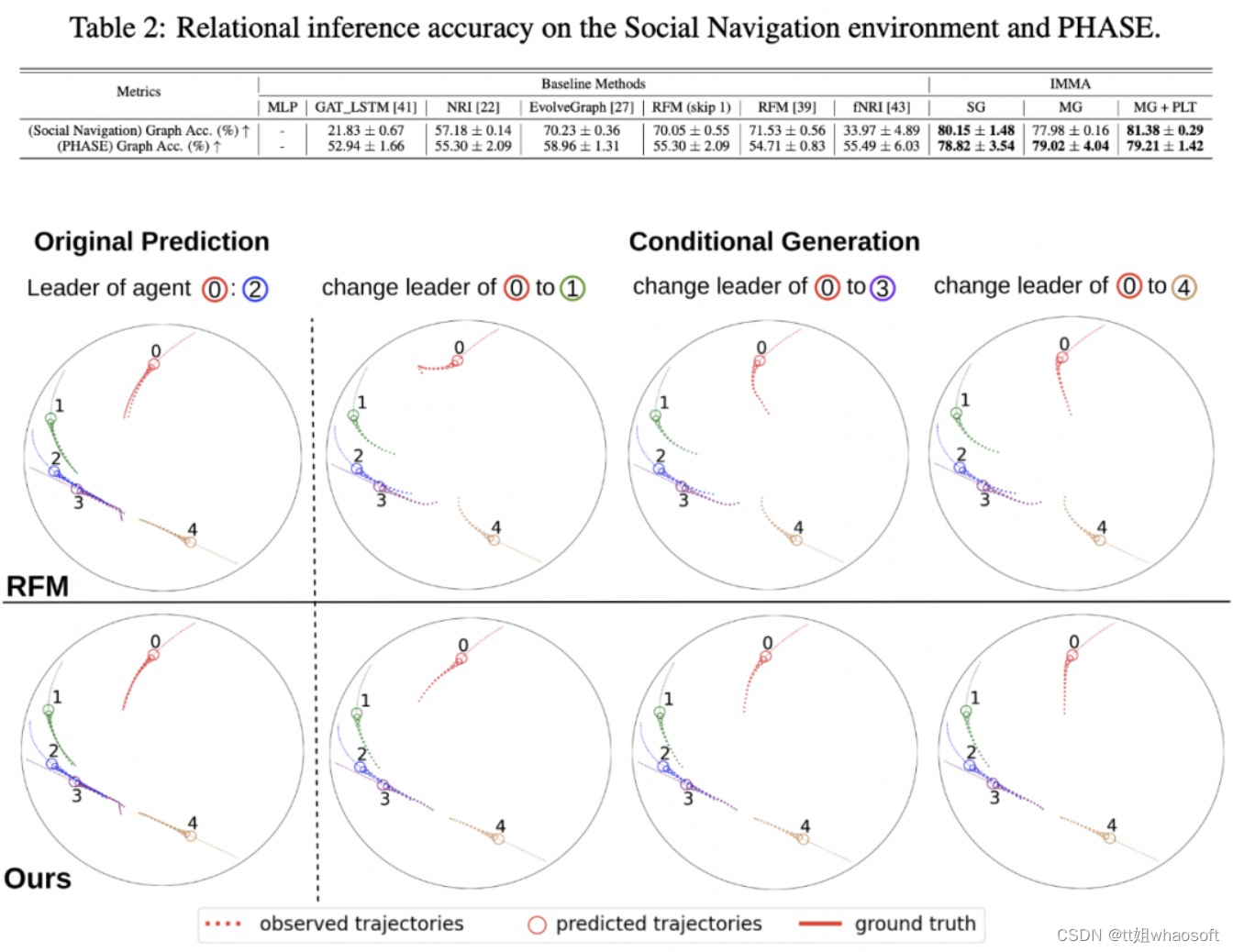
1. 该研究主要用以下三个数据集进行实验:Social Navigation Environment (基于 ORCA), PHASE dataset 和 NBA dataset,所有数据集上的结果如 Table 1 所示。该研究发现使用 Multiplex attentional latent graph 和渐进层训练 (MG w/ PLT) ,结果在所有三个数据集上都优于已有的最强基线模型。 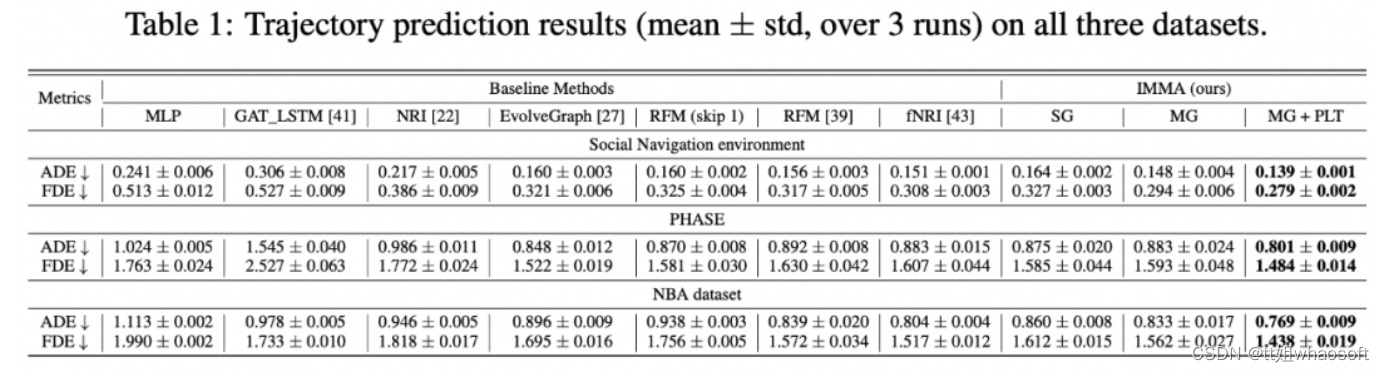
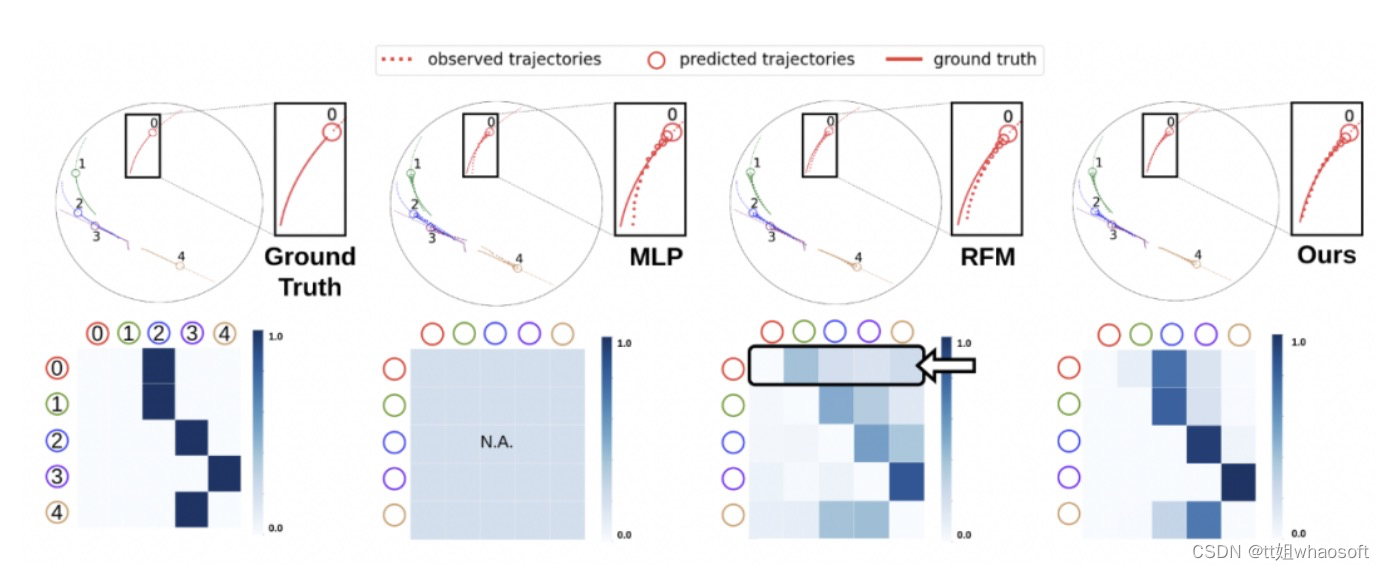
对于 Social Navigation dataset 的可视化结果如下图所示。第一排表示预测轨迹。圆圈越小表示离当前时间点越远。最左边是真实的未来轨迹和交互关系图。第二排表示预测的 latent graph。智能体 i 和 j 之间的 relation 由 heatmap 中的第 i 行第 j 列的元素表示。RFM 错误地预测了智能体之间的关系——用箭头突出显示,绿色 agent 被错误地赋予了比蓝色 agent 更高的权重。因此,预测的轨迹偏离了事实。相反,本文方法准确地预测了交互关系和未来轨迹。
 本文方法在 PHASE(左)和 NBA 数据集 (右) 的结果可视化如下图所示。在右侧的 NBA 图中,橙色代表篮球,不同轨迹颜色代表不同球队。 whaosoft aiot http://143ai.com
本文方法在 PHASE(左)和 NBA 数据集 (右) 的结果可视化如下图所示。在右侧的 NBA 图中,橙色代表篮球,不同轨迹颜色代表不同球队。 whaosoft aiot http://143ai.com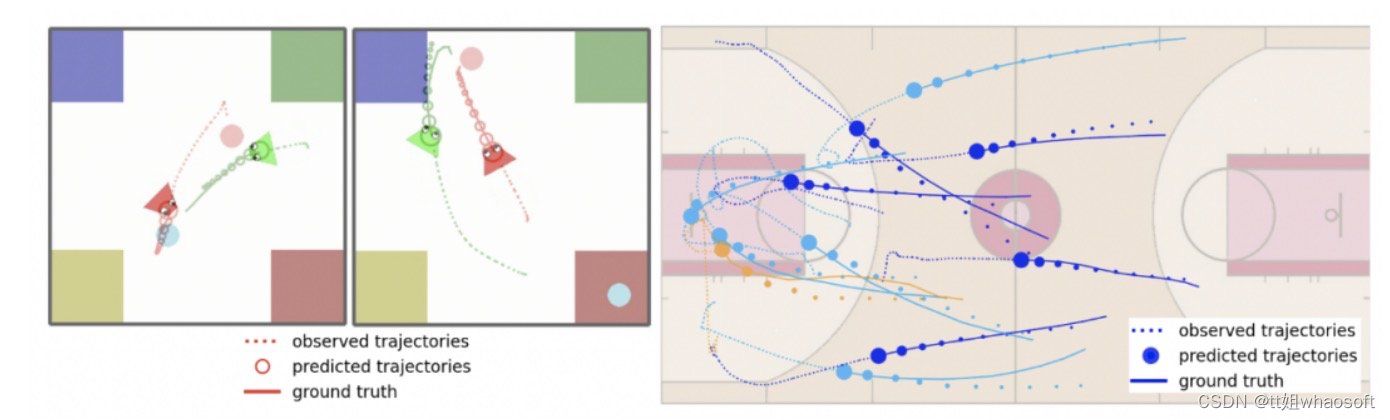
2. 以上实验证明本文方法可以更准确地预测运动轨迹,之后,该研究进一步探究了关系推理能力和对轨迹预测的影响。首先,本文对于关系推理更加准确 (见 Table 2),这不仅帮助模型预测运动轨迹,也提供了更好的 disentanglement 和可解释性。如下图所示,IMMA 中改变 agent 的 leader 会显著改变预测的轨迹,以新 leader 为目标,同时保持对其他 agent 的预测不变。而 RFM 生成的轨迹包括不切实际的转弯 (如红色 agent) 并且对其他 agent 的轨迹预测变差。
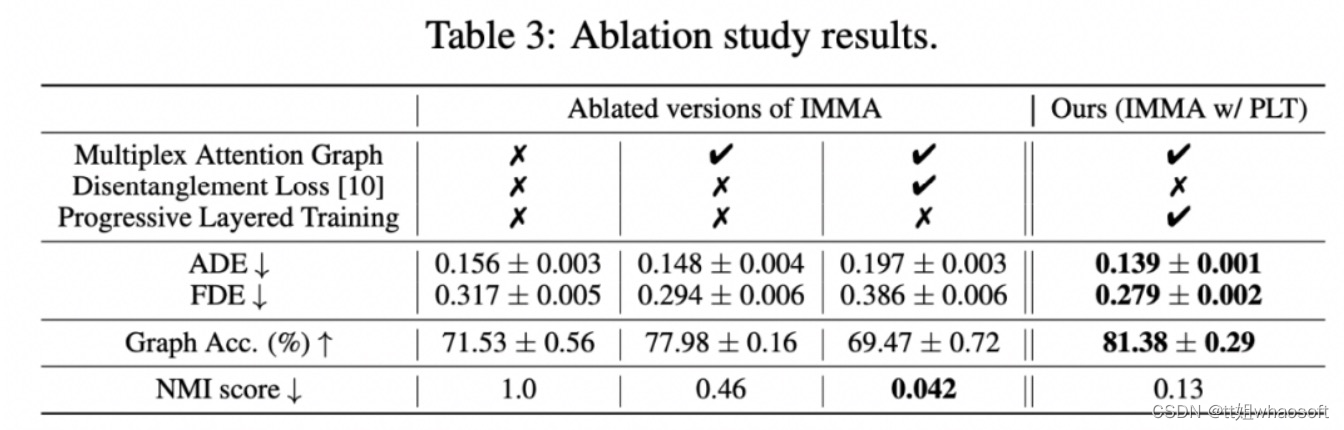
3. Ablation study 结果如 Table 3 所示,实验结果证明 multiplex attention graph 在模型中起到了至关重要的作用,逐层训练进一步提升了轨迹预测和关系推理准确度。
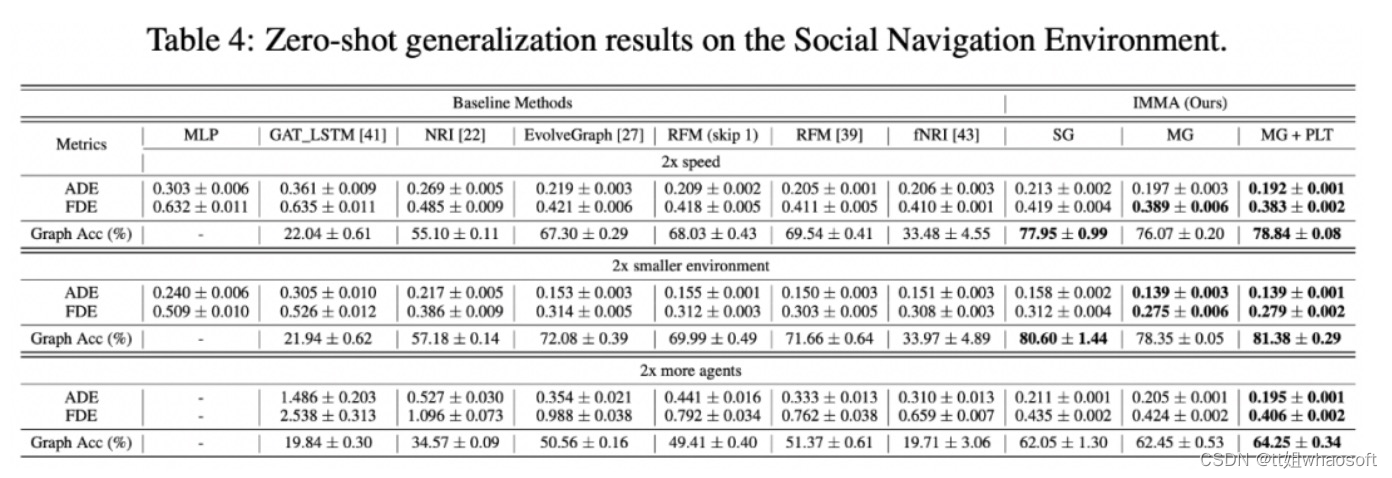
4. Table 4 显示 IMMA 的 zero-shot 泛化能力比基线方法更好。
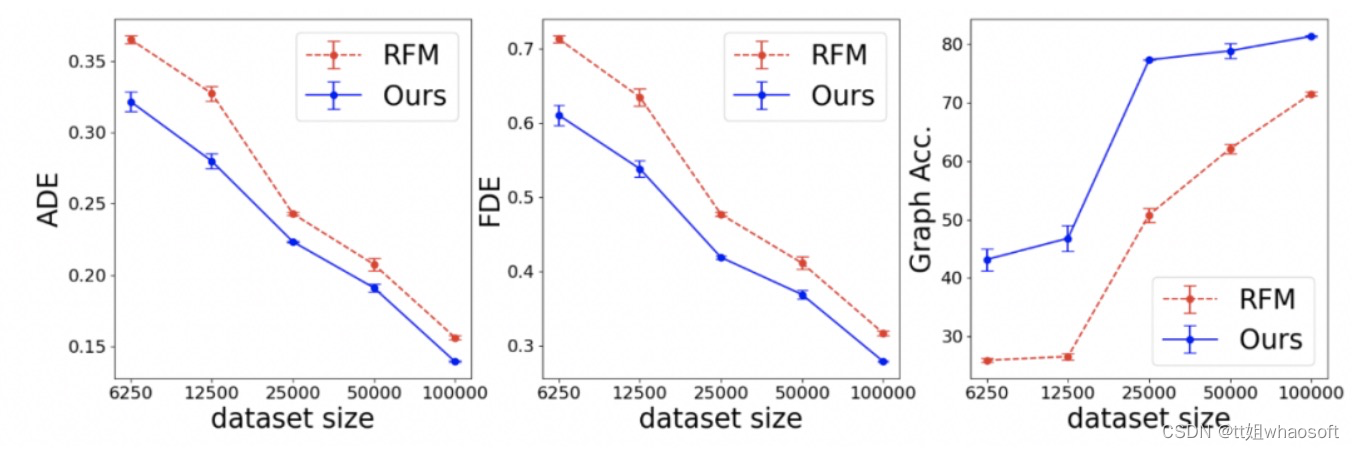
 另外,下图显示相比最优基线方法 (RFM), IMMA 需要更少的训练数据就可以得到更好的结果。
另外,下图显示相比最优基线方法 (RFM), IMMA 需要更少的训练数据就可以得到更好的结果。
四.结论
由于存在潜在的多层社会交互 (social interactions) 关系,多智能体系统 (multi-agent systems) 的动力学 (dynamics) 通常很复杂。智能体 (agent) 的行为可能会受到与其他每个智能体多种独立关系类型的影响,例如在物理系统中通常不存在的复杂属性 (意向性或合作关系)。本文提出了一种包含交互建模的预测方法 (IMMA),该方法使用 multiplex latent graph 作为隐空间表征 (latent representation) 来建模这种多层交互类型可能产生的行为。本文方法在行为和轨迹建模以及关系推理方面均优于其他最先进的方法,并有很强的可解释性 (interpretability) 和泛化能力 (zero-shot generalizability)。

















 4166
4166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









