







一文详解多模态技术在 QQ 浏览器视频搜索上的实践经验。了解多模态搜索算法如何让视频搜索更精准?还是腾讯大佬厉害啊~~~腾讯独家揭秘
视频搜索作为搜索中最大的横向垂类,在约 50% 的搜索词下都会有视频结果的展现。然而,视频资源又不同于文本网页资源,在视频理解、视频匹配排序,以及交互行为等方面都会带来新的技术挑战。
多模态技术近年逐步走进人们的视野,特别是 Transformer 结构在 NLP 领域的大放异彩后,也向视觉、音频等多模态领域延伸,为跨模态融合带来更大的便利和可能。多模态预训练(比如 ViLBERT/VisualBERT/VL-BERT/ERNIE-ViL 等)、多模态融合技术(比如基于矩阵、基于普通 NN、基于 attention 等)、多模态对齐技术、对比学习技术(如 CLIP)的发展,也为视频搜索业务效果的快速提升带来了可能。
作为一款每天服务千万人的工具,腾讯 QQ 浏览器的搜索功能承担着重要角色。伴随着过去几年的视频生产 / 消费的趋势,人们也在习惯消费视频,搜索视频。
本文作者来自腾讯搜索应用部,旨在分享多模态技术在 QQ 浏览器视频搜索上的实践经验。包括:
-
多模态技术在视频搜索整个架构中的逻辑位置,以及其中的技术难点;
-
介绍多模态技术的整体框架,包括封面模态匹配技术,视频内容帧匹配技术,多模态融合等技术的演进和实践经验。
1.1 视频搜索场景难点
在 QQ 浏览器的搜索入口进行搜索,在综搜结果页或视频 tab 页下,有 50% 左右的搜索词下会有相关的视频结果展示:
 (图 1:QQ 浏览器搜索入口,以及视频搜索场景)
(图 1:QQ 浏览器搜索入口,以及视频搜索场景)
不同于文本网页搜索,视频搜索有其自身独特性:视频封面作为丰富的视觉呈现,对用户有很大的吸引力,同时视频帧也蕴含巨大的信息,并且视频还有封面 OCR 文本、字幕文本等有信息增益的特征(如图 2、3 所示)。最后,视频资源作为众多模态的综合载体,如何把它们进行对齐融合也存在挑战。

(图 2:视频示例:query = 好看高级的围巾系法)
 (图 3:视频是多种模态信息的综合载体)
(图 3:视频是多种模态信息的综合载体)
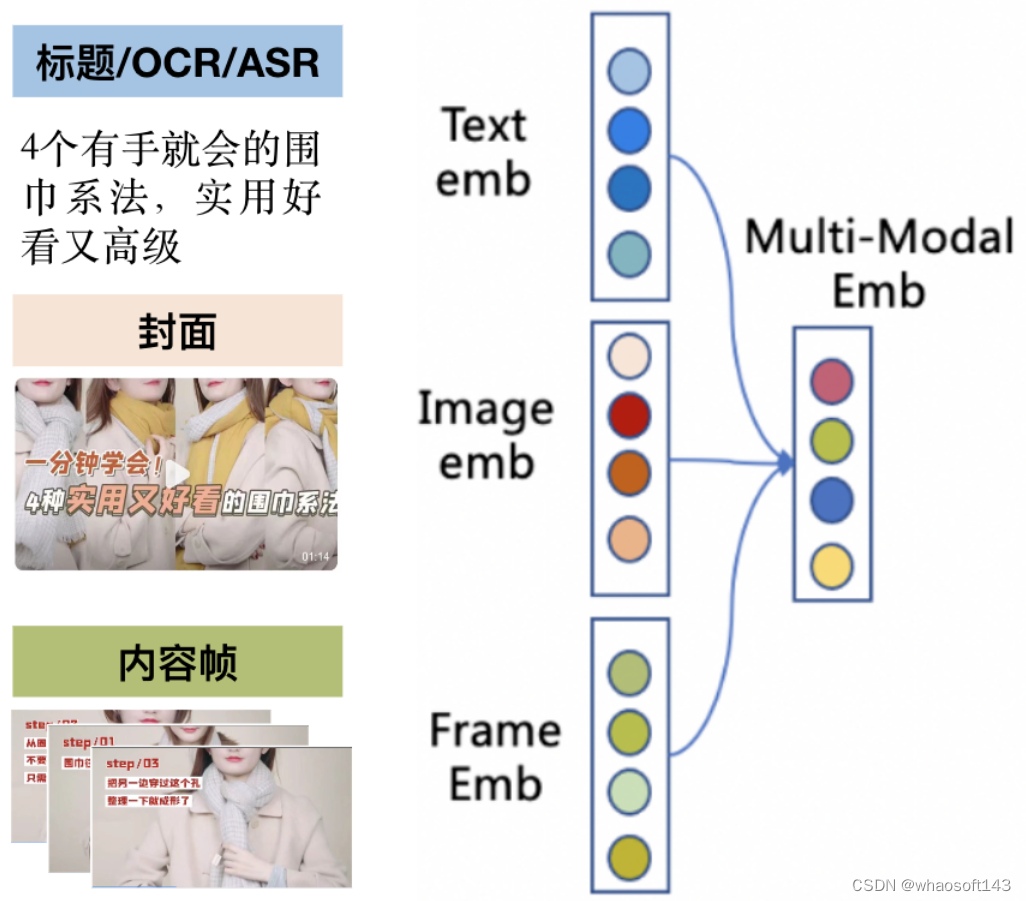 (图 4:视频多模态的融合)
(图 4:视频多模态的融合)
1.2 多模态技术的位置
视频多模态技术即要解决上述提及的相关问题,包括 query - 视频封面匹配、query - 视频内容帧匹配、query - 视频融合态匹配、query - 感知域融合匹配。这些匹配信息生效在视频精排阶段,起到非常高的权重作用。同时视频多模态技术还涉及质量价值、ASR/OCR 识别、tag 标记、索引等逻辑场景。
 (图 5:视频多模态技术生效的逻辑位置示意 (红))
(图 5:视频多模态技术生效的逻辑位置示意 (红))
接下来,本文将着重阐述在视频搜索排序中的相关技术实践。
2 关键技术
2.1 背景
视频搜索多模态技术围绕以下三个技术关键点:
-
模态表征:对视频的文本 / 图像 / 帧序列进行更好的表征,是后续模态融合 / 匹配的基础。
-
模态融合:视频本身是多模态的信息载体(包括文本 / 图像 / 音频等),而多模态的表征和建模的核心在于如何对不同模态的表征进行有效的融合。
-
模态匹配:传统搜索引擎以 query 和 doc 文本匹配信息为主(即文本相关性),而视频搜索场景下如何进行更好的跨模态匹配则是关键。
在分享视频搜索多模态技术实践之前,我们会对这些技术的发展演进进行梳理和总结,以方便读者后续更好的理解。
2.1.1 模态表征技术
2.1.1.1 图像模态的表征学习
整体而言,图像模态表征学习技术的发展和演进,可以从以下两个角度看:
-
表征模型:
-
CNN 时期(2020 年之前):以 VGG、ResNet 等为代表。我们在第一版本时就是使用了 ResNet 方案。
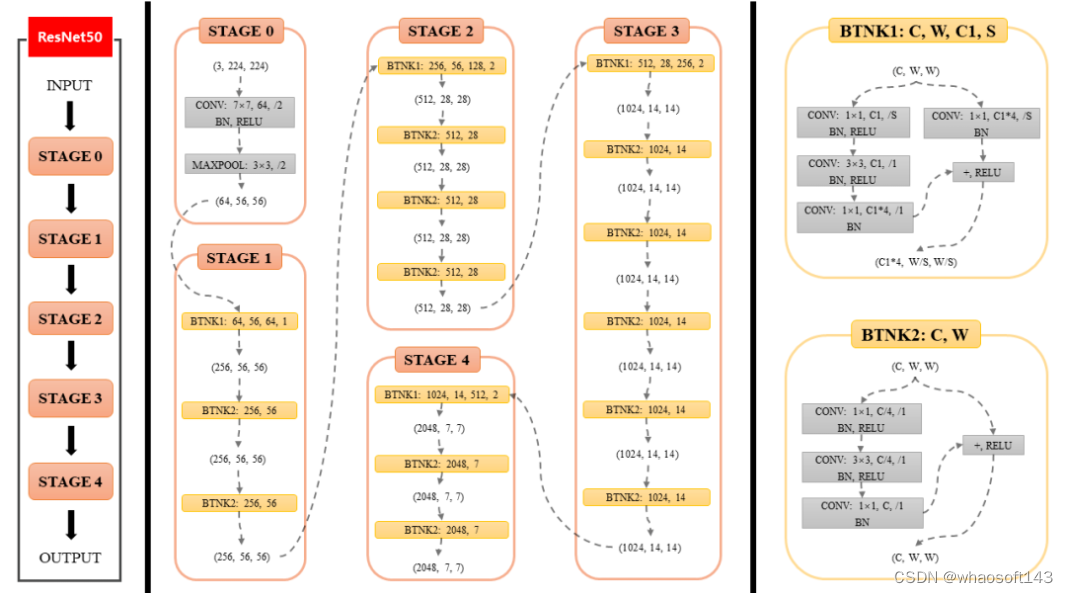
(图 6:CNN 时期的图像模态表征模型代表 --ResNet)
-
Transformer 时期(2020 年至今):以 Vision Transformer (简称 ViT) 和 Swin Transformer 等为代表。后来我们逐步将方案由卷积迁移到注意力方案上来。
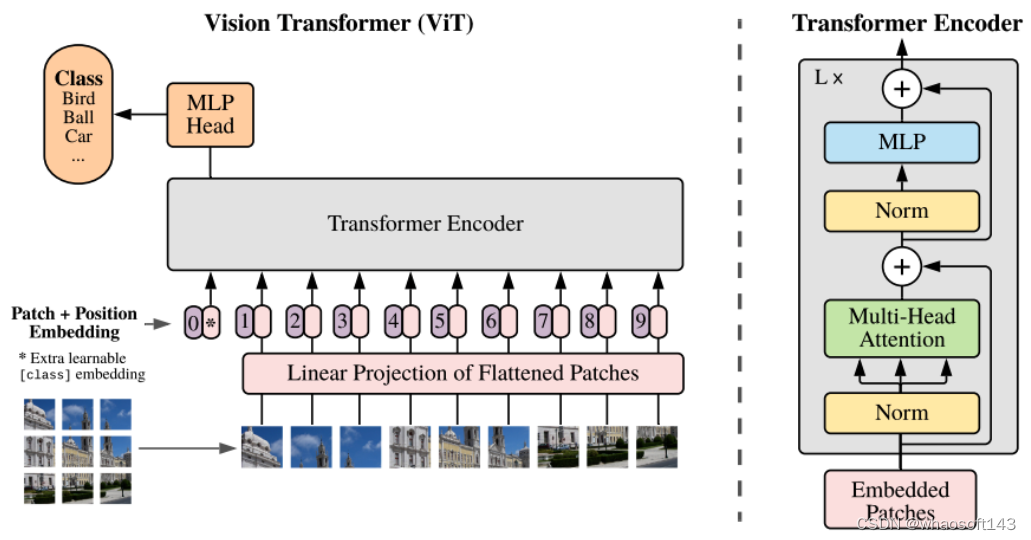 (图 7:Transformer 时期的图像模态表征模型代表 --Vision Transformer (ViT))
(图 7:Transformer 时期的图像模态表征模型代表 --Vision Transformer (ViT))
2.1.1.2 内容帧模态的表征学习
从视觉角度上看,视频可以认为是由一组时间序列连续的图像模态构成。
表征内容帧模态的经典模型方法包括:
-
以 CNN 为 backbone 的代表模型:I3D、X3D 等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2900
2900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









