







# Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
扩散模型可解释性新探索,图像生成一致性创新高!AI视频生成新机遇?在本文中,作者提出了一种基于成对平均CLIP分数的语义一致性分数。本文提出的语义一致性分数为图像生成的一致性提供了一个量化工具,这有助于评估特定任务的模型架构,并为选择合适的模型提供了参考依据。
1. 本文概要
在本研究中,作者指出了对图像生成扩散模型的可重复性或一致性进行定量评分的重要性。本文提出了一种基于成对平均CLIP(对比语言-图像预训练)分数的语义一致性评分方法。通过将此度量应用于比较两种领先的开源图像生成扩散模型——Stable Diffusion XL(SDXL)和PixArt-α,作者发现它们在语义一致性分数上存在显著的统计差异。所选模型的语义一致性分数与综合人工标注结果的一致性高达94%。此外,本文还研究了SDXL及其经过LoRA(低秩适应)微调的版本之间的一致性,结果显示微调后的模型在语义一致性上有显著提高。本文提出的语义一致性分数为图像生成的一致性提供了一个量化工具,这有助于评估特定任务的模型架构,并为选择合适的模型提供了参考依据。
论文标题:Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
论文链接:https://arxiv.org/abs/2404.08799
开源链接:https://github.com/brinnaebent/semantic-consistency-score
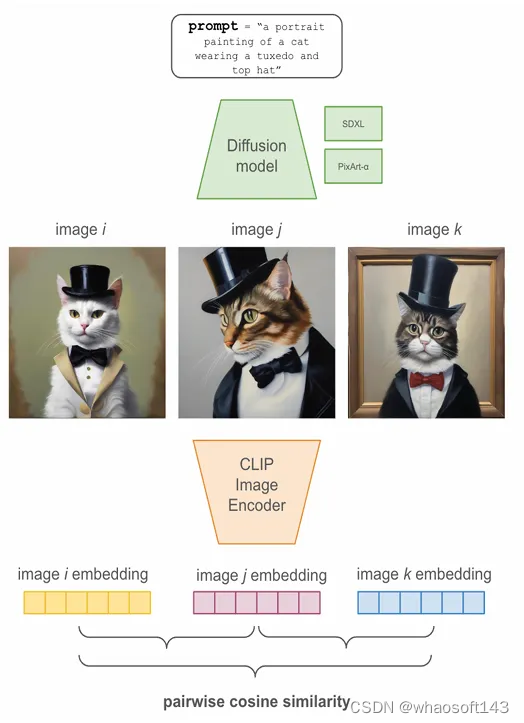
图1:将单个提示通过设置好的随机种子重复n次传递到扩散模型中。生成的图像通过CLIP图像编码器传递,计算所有来自单个提示生成的图像的成对余弦相似度。
2. 方法引出
随着图像生成扩散模型的研究和应用不断增长,对这些模型输出的可解释性进行更深入的研究变得尤为重要。在使用扩散模型进行图像生成时,输出结果会显示出一定的变异性。这种变异性是由扩散过程中的随机因素造成的,包括随机初始化、概率分布采样以及非线性激活函数等。尽管变异性是扩散模型的一个内在特点,但由于模型架构、训练过程(包括近似方法)以及用于指导生成过程的技术的不同,不同模型之间的变异性水平也会有所不同。在将这些模型应用于实际问题时,需要在输出的多样性和创造性与输入提示的一致性和连贯性之间找到一个平衡点。对输出的一致性或可重复性进行量化,可以使对这种变异性进行量化分析,并在决定使用哪种扩散模型来完成特定任务时,提供创造性与一致性之间的平衡参考。这种量化方法能够评估模型的稳定性和一致性,检测意外的偏差,验证模型输出的解释,并提高人类对模型的理解。
3. 方法详析
3.1. 语义一致性分数
作者认识到,为了量化扩散模型在图像生成中的可重复性或一致性,一个量化分数是必需的。在本研究中,本文介绍了一种基于语义的方法来计算这一分数,即通过使用成对平均CLIP分数(公式1)来实现。

3.2. 图像生成模型评估

3.2.1 数据集构建:SDXL和PixArt-

3.2.2 数据集构建:SDXL和LoRA

3.2.3 人工标注
标注由13名人类标注者完成。本文构建了一个标注界面,并排显示SDXL和PixArt-生成的图像库,标注者选择他们认为最一致的库,并浏览每个提示。通过比较语义一致性得分最高的模型与每个标注者的选择以及所有标注者的整体响应(按频率聚合)来衡量一致性。
3.2.4 敏感性分析

根据敏感性分析的结果,本文对每个模型的每个提示进行了20次重复 (随机种子),得到了 张图像进行分析。
3.2.5 统计分析
对于每个提示和每个模型,计算成对平均CLIP分数。使用Kolmogorov-Smirnov正态性检验发现,每个模型的分数分布都不服从正态分布(p<0.05)。因此,作者使用Wilcoxon符号秩检验(非参数配对样本显著性检验)和两样本Kolmogorov-Smirnov检验(非参数检验,用于确定两个样本是否来自同一连续分布)来检查统计显著性。
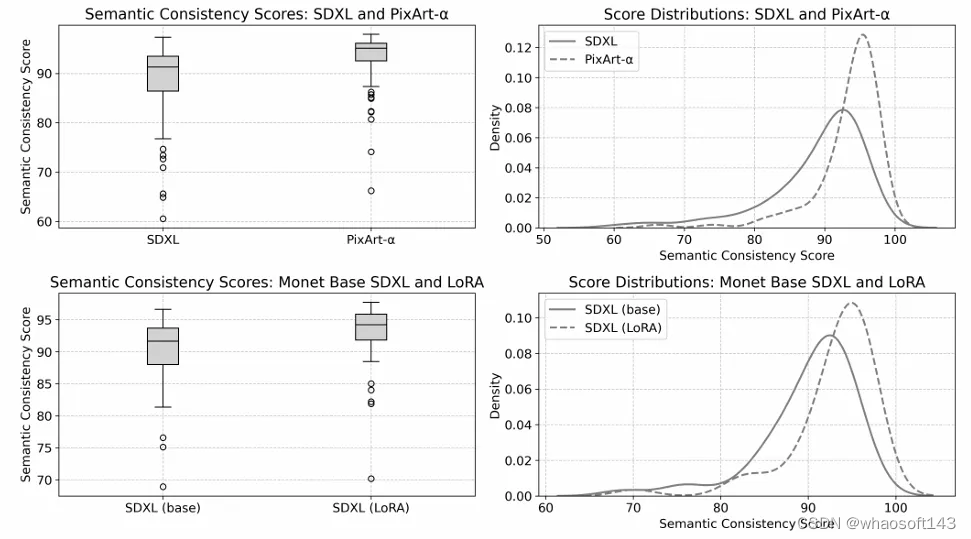
图2:(上行)SDXL和PixArt-α在成对得分和分布上显示出显著差异,使用箱线图和核密度估计图可视化。(下行)SDXL(基础)和SDXL(基于Monet的LoRA微调)在成对得分和分布上显示出显著差异,使用箱线图和核密度估计图可视化。
4. 实验
4.1. 敏感性分析
作者进行了敏感性分析,以确定分析的最佳提示重复次数,平衡准确性和计算效率。作者发现,至少需要20次重复,才能确保得分在所有重复的平均得分和100次重复得分的1%范围内。在95%的迭代中,使用20次重复可将得分保持在平均得分和100次重复得分的0.5%范围内。
4.2. 模型比较:SDXL和PixArt-

4.3. 模型比较:SDXL和基于LoRA的SDXL微调版本
本文探讨了基础SDXL和基于LoRA微调的SDXL版本在图像生成一致性方面的差异。在50个提示和每个模型1k张图像中,SDXL的平均一致性得分为90.1±5.4(中位数91.7),LoRA微调SDXL模型的平均一致性得分为92.9±5.0(中位数94.2)。两样本Kolmogorov-Smirnov检验显示,两个模型的得分分布存在显著差异(KS统计量=0.38;p值=0.001)。Wilcoxon符号秩检验也显示配对得分存在显著差异(Wilcoxon统计量=95.0;p值=5.80e-09)。
4.4. 局限性
这项研究将大大受益于进一步与人类判断图像生成一致性的比较。此外,作者使用CLIP嵌入模型,因为它在其他用例中已被证明是稳健的,但应该探索其他多模态嵌入模型,如BLIP2,特别是因为CLIP模型已被证明会从输入提示中吸收偏差。
5. 结论

对扩散模型权重进行LoRA微调是一种常见的做法,旨在生成更符合预期的输出。通过采用语义一致性分数进行评估,作者发现与原始SDXL相比,经LoRA微调的SDXL版本在语义一致性上表现更佳。本研究提出的语义一致性分数为图像生成的一致性提供了一个量化指标,有助于评估特定任务下LORA模型的性能。此外,作者还考虑了对提示的评估,这在尝试量化和编纂各种用例 (包括连贯故事和电影生成) 所使用的提示工程时可能非常有用。 whaosoft aiot http://143ai.com
作者提出的量化生成模型输出一致性的概念,不仅适用于图像生成,也可以扩展到其他领域,如生成文本、音频或者视频输出的一致性评估,这将为生成模型的发展带来新的机遇。
# diffusion 生成扩散模型论文汇总
001 (2024-04-26) MV-VTON Multi-View Virtual Try-On with Diffusion Models
https://arxiv.org/pdf/2404.17364.pdf
002 (2024-04-26) Simultaneous Tri-Modal Medical Image Fusion and Super-Resolution using Conditional Diffusion Model
https://arxiv.org/pdf/2404.17357.pdf
003 (2024-04-25) CyNetDiff -- A Python Library for Accelerated Implementation of Network Diffusion Models
https://arxiv.org/pdf/2404.17059.pdf
004 (2024-04-25) Investigating the effect of particle size distribution and complex exchange dynamics on NMR spectra of ions diffusing in disordered porous carbons through a mesoscopic model
https://arxiv.org/pdf/2404.17054.pdf
005 (2024-04-25) Conditional Distribution Modelling for Few-Shot Image Synthesis with Diffusion Models
https://arxiv.org/pdf/2404.16556.pdf
006 (2024-04-25) DiffSeg A Segmentation Model for Skin Lesions Based on Diffusion Difference
https://arxiv.org/pdf/2404.16474.pdf
007 (2024-04-24) TI2V-Zero Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
https://arxiv.org/pdf/2404.16306.pdf
008 (2024-04-24) Unifying Bayesian Flow Networks and Diffusion Models through Stochastic Differential Equations
https://arxiv.org/pdf/2404.15766.pdf
009 (2024-04-24) Generative Diffusion Model (GDM) for Optimization of Wi-Fi Networks
https://arxiv.org/pdf/2404.15684.pdf
010 (2024-04-24) AnoFPDM Anomaly Segmentation with Forward Process of Diffusion Models for Brain MRI
https://arxiv.org/pdf/2404.15683.pdf
011 (2024-04-24) CharacterFactory Sampling Consistent Characters with GANs for Diffusion Models
https://arxiv.org/pdf/2404.15677.pdf
012 (2024-04-23) Optimizing OOD Detection in Molecular Graphs A Novel Approach with Diffusion Models
https://arxiv.org/pdf/2404.15625.pdf
013 (2024-04-23) ControlTraj Controllable Trajectory Generation with Topology-Constrained Diffusion Model
https://arxiv.org/pdf/2404.15380.pdf
014 (2024-04-23) Taming Diffusion Probabilistic Models for Character Control
https://arxiv.org/pdf/2404.15121.pdf
015 (2024-04-23) Perturbing Attention Gives You More Bang for the Buck Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
https://arxiv.org/pdf/2404.15081.pdf
016 (2024-04-23) Music Style Transfer With Diffusion Model
https://arxiv.org/pdf/2404.14771.pdf
017 (2024-04-23) Gradient Guidance for Diffusion Models An Optimization Perspective
https://arxiv.org/pdf/2404.14743.pdf
018 (2024-04-22) Align Your Steps Optimizing Sampling Schedules in Diffusion Models
https://arxiv.org/pdf/2404.14507.pdf
019 (2024-04-5) Conditional diffusion models for downscaling & bias correction of Earth system model precipitation
https://arxiv.org/pdf/2404.14416.pdf
020 (2024-04-22) GeoDiffuser Geometry-Based Image Editing with Diffusion Models
https://arxiv.org/pdf/2404.14403.pdf
021 (2024-04-22) Collaborative Filtering Based on Diffusion Models Unveiling the Potential of High-Order Connectivity
https://arxiv.org/pdf/2404.14240.pdf
022 (2024-04-22) FLDM-VTON Faithful Latent Diffusion Model for Virtual Try-on
https://arxiv.org/pdf/2404.14162.pdf
023 (2024-04-21) Universal Fingerprint Generation Controllable Diffusion Model with Multimodal Conditions
https://arxiv.org/pdf/2404.13791.pdf
024 (2024-04-21) Concept Arithmetics for Circumventing Concept Inhibition in Diffusion Models
https://arxiv.org/pdf/2404.13706.pdf
025 (2024-04-21) Motion-aware Latent Diffusion Models for Video Frame Interpolation
https://arxiv.org/pdf/2404.13534.pdf
026 (2024-04-20) Accelerating the Generation of Molecular Conformations with Progressive Distillation of Equivariant Latent Diffusion Models
https://arxiv.org/pdf/2404.13491.pdf
027 (2024-04-20) Generating Daylight-driven Architectural Design via Diffusion Models
https://arxiv.org/pdf/2404.13353.pdf
028 (2024-04-20) Pixel is a Barrier Diffusion Models Are More Adversarially Robust Than We Think
https://arxiv.org/pdf/2404.13320.pdf
029 (2024-04-20) Latent Schr{ö}dinger Bridge Diffusion Model for Generative Learning
https://arxiv.org/pdf/2404.13309.pdf
030 (2024-04-20) Optimal Control of a Sub-diffusion Model using Dirichlet-Neumann and Neumann-Neumann Waveform Relaxation Algorithms
https://arxiv.org/pdf/2404.13283.pdf
031 (2024-04-20) A Massive MIMO Sampling Detection Strategy Based on Denoising Diffusion Model
https://arxiv.org/pdf/2404.13281.pdf
032 (2024-04-20) FilterPrompt Guiding Image Transfer in Diffusion Models
https://arxiv.org/pdf/2404.13263.pdf
033 (2024-04-19) DISC Latent Diffusion Models with Self-Distillation from Separated Conditions for Prostate Cancer Grading
https://arxiv.org/pdf/2404.13097.pdf
034 (2024-04-19) RadRotator 3D Rotation of Radiographs with Diffusion Models
https://arxiv.org/pdf/2404.13000.pdf
035 (2024-04-19) Cross-modal Diffusion Modelling for Super-resolved Spatial Transcriptomics
https://arxiv.org/pdf/2404.12973.pdf
036 (2024-04-19) Neural Flow Diffusion Models Learnable Forward Process for Improved Diffusion Modelling
https://arxiv.org/pdf/2404.12940.pdf
037 (2024-04-19) Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
https://arxiv.org/pdf/2404.12920.pdf
038 (2024-04-19) Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
https://arxiv.org/pdf/2404.12908.pdf
039 (2024-04-19) ConCLVD Controllable Chinese Landscape Video Generation via Diffusion Model
https://arxiv.org/pdf/2404.12903.pdf
040 (2024-04-19) Detecting Out-Of-Distribution Earth Observation Images with Diffusion Models
https://arxiv.org/pdf/2404.12667.pdf
041 (2024-04-19) F2FLDM Latent Diffusion Models with Histopathology Pre-Trained Embeddings for Unpaired Frozen Section to FFPE Translation
https://arxiv.org/pdf/2404.12650.pdf
042 (2024-04-18) GenVideo One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
https://arxiv.org/pdf/2404.12541.pdf
043 (2024-04-18) Learning the Domain Specific Inverse NUFFT for Accelerated Spiral MRI using Diffusion Models
https://arxiv.org/pdf/2404.12361.pdf
044 (2024-04-18) LD-Pruner Efficient Pruning of Latent Diffusion Models using Task-Agnostic Insights
https://arxiv.org/pdf/2404.11936.pdf
045 (2024-04-18) FreeDiff Progressive Frequency Truncation for Image Editing with Diffusion Models
https://arxiv.org/pdf/2404.11895.pdf
046 (2024-04-17) Diffusion Schrödinger Bridge Models for High-Quality MR-to-CT Synthesis for Head and Neck Proton Treatment Planning
https://arxiv.org/pdf/2404.11741.pdf
047 (2024-04-17) Prompt Optimizer of Text-to-Image Diffusion Models for Abstract Concept Understanding
https://arxiv.org/pdf/2404.11589.pdf
048 (2024-04-17) SSDiff Spatial-spectral Integrated Diffusion Model for Remote Sensing Pansharpening
https://arxiv.org/pdf/2404.11537.pdf
049 (2024-04-17) Optical Image-to-Image Translation Using Denoising Diffusion Models Heterogeneous Change Detection as a Use Case
https://arxiv.org/pdf/2404.11243.pdf
050 (2024-04-17) RiboDiffusion Tertiary Structure-based RNA Inverse Folding with Generative Diffusion Models
https://arxiv.org/pdf/2404.11199.pdf
051 (2024-04-18) LAPTOP-Diff Layer Pruning and Normalized Distillation for Compressing Diffusion Models
https://arxiv.org/pdf/2404.11098.pdf
052 (2024-04-16) Forcing Diffuse Distributions out of Language Models
https://arxiv.org/pdf/2404.10859.pdf
053 (2024-04-16) RefFusion Reference Adapted Diffusion Models for 3D Scene Inpainting
https://arxiv.org/pdf/2404.10765.pdf
054 (2024-04-16) LaDiC Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation
https://arxiv.org/pdf/2404.10763.pdf
055 (2024-04-16) Efficient Conditional Diffusion Model with Probability Flow Sampling for Image Super-resolution
https://arxiv.org/pdf/2404.10688.pdf
056 (2024-04-16) Four-hour thunderstorm nowcasting using deep diffusion models of satellite
https://arxiv.org/pdf/2404.10512.pdf
057 (2024-04-16) SparseDM Toward Sparse Efficient Diffusion Models
https://arxiv.org/pdf/2404.10445.pdf
058 (2024-04-16) Generating Counterfactual Trajectories with Latent Diffusion Models for Concept Discovery
https://arxiv.org/pdf/2404.10356.pdf
059 (2024-04-18) Efficiently Adversarial Examples Generation for Visual-Language Models under Targeted Transfer Scenarios using Diffusion Models
https://arxiv.org/pdf/2404.10335.pdf
060 (2024-04-17) OmniSSR Zero-shot Omnidirectional Image Super-Resolution using Stable Diffusion Model
https://arxiv.org/pdf/2404.10312.pdf
061 (2024-04-16) EucliDreamer Fast and High-Quality Texturing for 3D Models with Depth-Conditioned Stable Diffusion
https://arxiv.org/pdf/2404.10279.pdf
062 (2024-03-20) Consistent Diffusion Meets Tweedie Training Exact Ambient Diffusion Models with Noisy Data
https://arxiv.org/pdf/2404.10177.pdf
063 (2024-04-15) Salient Object-Aware Background Generation using Text-Guided Diffusion Models
https://arxiv.org/pdf/2404.10157.pdf
064 (2024-04-15) A general thermodynamical model for finitely-strained continuum with inelasticity and diffusion its GENERIC derivation in Eulerian formulation and some application
https://arxiv.org/pdf/2404.10126.pdf
065 (2024-04-15) Taming Latent Diffusion Model for Neural Radiance Field Inpainting
https://arxiv.org/pdf/2404.09995.pdf
066 (2024-04-15) MaxFusion Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
https://arxiv.org/pdf/2404.09977.pdf
067 (2024-04-15) Ctrl-Adapter An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
https://arxiv.org/pdf/2404.09967.pdf
068 (2024-04-15) A Diffusion-based Data Generator for Training Object Recognition Models in Ultra-Range Distance
https://arxiv.org/pdf/2404.09846.pdf
069 (2024-04-17) Digging into contrastive learning for robust depth estimation with diffusion models
https://arxiv.org/pdf/2404.09831.pdf
070 (2024-04-15) Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement
https://arxiv.org/pdf/2404.09735.pdf
071 (2024-04-15) Entropy on the Path Space and Application to Singular Diffusions and Mean-field Models
https://arxiv.org/pdf/2404.09552.pdf
072 (2024-04-15) TMPQ-DM Joint Timestep Reduction and Quantization Precision Selection for Efficient Diffusion Models
https://arxiv.org/pdf/2404.09532.pdf
073 (2024-04-19) Watermark-embedded Adversarial Examples for Copyright Protection against Diffusion Models
https://arxiv.org/pdf/2404.09401.pdf
074 (2024-04-14) Fault Detection in Mobile Networks Using Diffusion Models
https://arxiv.org/pdf/2404.09240.pdf
075 (2024-04-13) Rethinking Iterative Stereo Matching from Diffusion Bridge Model Perspective
https://arxiv.org/pdf/2404.09051.pdf
076 (2024-04-13) Theoretical research on generative diffusion models an overview
https://arxiv.org/pdf/2404.09016.pdf
077 (2024-04-17) Diffusion Models Meet Remote Sensing Principles Methods and Perspectives
https://arxiv.org/pdf/2404.08926.pdf
078 (2024-04-12) ChangeAnywhere Sample Generation for Remote Sensing Change Detection via Semantic Latent Diffusion Model
https://arxiv.org/pdf/2404.08892.pdf
079 (2024-04-12) Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
https://arxiv.org/pdf/2404.08799.pdf
080 (2024-04-12) Diffusion-Based Joint Temperature and Precipitation Emulation of Earth System Models
https://arxiv.org/pdf/2404.08797.pdf
081 (2024-04-12) Lossy Image Compression with Foundation Diffusion Models
https://arxiv.org/pdf/2404.08580.pdf
082 (2024-04-12) Balanced Mixed-Type Tabular Data Synthesis with Diffusion Models
https://arxiv.org/pdf/2404.08254.pdf
083 (2024-03-14) Towards Faster Training of Diffusion Models An Inspiration of A Consistency Phenomenon
https://arxiv.org/pdf/2404.07946.pdf
084 (2024-04-11) An Overview of Diffusion Models Applications Guided Generation Statistical Rates and Optimization
https://arxiv.org/pdf/2404.07771.pdf
085 (2024-04-11) Joint Conditional Diffusion Model for Image Restoration with Mixed Degradations
https://arxiv.org/pdf/2404.07770.pdf
086 (2024-04-11) Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models
https://arxiv.org/pdf/2404.07724.pdf
087 (2024-04-10) Object-Conditioned Energy-Based Attention Map Alignment in Text-to-Image Diffusion Models
https://arxiv.org/pdf/2404.07389.pdf
088 (2024-04-10) GoodDrag Towards Good Practices for Drag Editing with Diffusion Models
https://arxiv.org/pdf/2404.07206.pdf
089 (2024-04-10) Fine color guidance in diffusion models and its application to image compression at extremely low bitrates
https://arxiv.org/pdf/2404.06865.pdf
090 (2024-04-10) DiffusionDialog A Diffusion Model for Diverse Dialog Generation with Latent Space
https://arxiv.org/pdf/2404.06760.pdf
091 (2024-04-11) Disguised Copyright Infringement of Latent Diffusion Models
https://arxiv.org/pdf/2404.06737.pdf
092 (2024-04-9) Efficient Denoising using Score Embedding in Score-based Diffusion Models
https://arxiv.org/pdf/2404.06661.pdf
093 (2024-04-9) Quantum State Generation with Structure-Preserving Diffusion Model
https://arxiv.org/pdf/2404.06336.pdf
094 (2024-04-9) DiffHarmony Latent Diffusion Model Meets Image Harmonization
https://arxiv.org/pdf/2404.06139.pdf
095 (2024-04-8) Map Optical Properties to Subwavelength Structures Directly via a Diffusion Model
https://arxiv.org/pdf/2404.05959.pdf
096 (2024-04-8) NAF-DPM A Nonlinear Activation-Free Diffusion Probabilistic Model for Document Enhancement
https://arxiv.org/pdf/2404.05669.pdf
097 (2024-04-8) BinaryDM Towards Accurate Binarization of Diffusion Model
https://arxiv.org/pdf/2404.05662.pdf
098 (2024-04-8) Resistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
https://arxiv.org/pdf/2404.05648.pdf
099 (2024-04-8) Investigating the Effectiveness of Cross-Attention to Unlock Zero-Shot Editing of Text-to-Video Diffusion Models
https://arxiv.org/pdf/2404.05519.pdf
100 (2024-04-25) DiffCJK Conditional Diffusion Model for High-Quality and Wide-coverage CJK Character Generation
https://arxiv.org/pdf/2404.05212.pdf
101 (2024-04-7) Generative downscaling of PDE solvers with physics-guided diffusion models
https://arxiv.org/pdf/2404.05009.pdf
102 (2024-04-7) Gaussian Shading Provable Performance-Lossless Image Watermarking for Diffusion Models
https://arxiv.org/pdf/2404.04956.pdf
103 (2024-04-7) Regularized Conditional Diffusion Model for Multi-Task Preference Alignment
https://arxiv.org/pdf/2404.04920.pdf
104 (2024-04-7) ShoeModel Learning to Wear on the User-specified Shoes via Diffusion Model
https://arxiv.org/pdf/2404.04833.pdf
105 (2024-04-6) Rethinking Diffusion Model for Multi-Contrast MRI Super-Resolution
https://arxiv.org/pdf/2404.04785.pdf
106 (2024-04-6) InitNO Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
https://arxiv.org/pdf/2404.04650.pdf
107 (2024-04-6) DifFUSER Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
https://arxiv.org/pdf/2404.04629.pdf
108 (2024-04-23) Latent-based Diffusion Model for Long-tailed Recognition
https://arxiv.org/pdf/2404.04517.pdf
109 (2024-04-5) Diffusion-RWKV Scaling RWKV-Like Architectures for Diffusion Models
https://arxiv.org/pdf/2404.04478.pdf
110 (2024-04-5) Aligning Diffusion Models by Optimizing Human Utility
https://arxiv.org/pdf/2404.04465.pdf
111 (2024-04-5) Pixel-wise RL on Diffusion Models Reinforcement Learning from Rich Feedback
https://arxiv.org/pdf/2404.04356.pdf
112 (2024-04-5) Score identity Distillation Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation
https://arxiv.org/pdf/2404.04057.pdf
113 (2024-04-4) Microscopic derivation of non-local models with anomalous diffusions from stochastic particle systems
https://arxiv.org/pdf/2404.03772.pdf
114 (2024-04-4) Bi-level Guided Diffusion Models for Zero-Shot Medical Imaging Inverse Problems
https://arxiv.org/pdf/2404.03706.pdf
115 (2024-04-4) CoMat Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
https://arxiv.org/pdf/2404.03653.pdf
116 (2024-04-4) PointInfinity Resolution-Invariant Point Diffusion Models
https://arxiv.org/pdf/2404.03566.pdf
117 (2024-04-4) Segmentation-Guided Knee Radiograph Generation using Conditional Diffusion Models
https://arxiv.org/pdf/2404.03541.pdf
118 (2024-04-4) SiloFuse Cross-silo Synthetic Data Generation with Latent Tabular Diffusion Models
https://arxiv.org/pdf/2404.03299.pdf
119 (2024-04-3) Many-to-many Image Generation with Auto-regressive Diffusion Models
https://arxiv.org/pdf/2404.03109.pdf
120 (2024-04-2) Jailbreaking Prompt Attack A Controllable Adversarial Attack against Diffusion Models
https://arxiv.org/pdf/2404.02928.pdf
121 (2024-04-3) Fast Diffusion Model For Seismic Data Noise Attenuation
https://arxiv.org/pdf/2404.02767.pdf
122 (2024-04-3) Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
https://arxiv.org/pdf/2404.02747.pdf
123 (2024-04-3) Diffexplainer Towards Cross-modal Global Explanations with Diffusion Models
https://arxiv.org/pdf/2404.02618.pdf
124 (2024-04-3) Solar synthetic imaging Introducing denoising diffusion probabilistic models on SDO/AIA data
https://arxiv.org/pdf/2404.02552.pdf
125 (2024-04-2) APEX Ambidextrous Dual-Arm Robotic Manipulation Using Collision-Free Generative Diffusion Models
https://arxiv.org/pdf/2404.02284.pdf
126 (2024-04-7) Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
https://arxiv.org/pdf/2404.02241.pdf
127 (2024-04-20) Diffusion$^2$ Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
https://arxiv.org/pdf/2404.02148.pdf
128 (2024-04-3) AUTODIFF Autoregressive Diffusion Modeling for Structure-based Drug Design
https://arxiv.org/pdf/2404.02003.pdf
129 (2024-04-3) Rigorous derivation of an effective model for coupled Stokes advection reaction and diffusion with freely evolving microstructure
https://arxiv.org/pdf/2404.01983.pdf
130 (2024-04-2) Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
https://arxiv.org/pdf/2404.01862.pdf
131 (2024-04-2) Upsample Guidance Scale Up Diffusion Models without Training
https://arxiv.org/pdf/2404.01709.pdf
132 (2024-04-8) Prior Frequency Guided Diffusion Model for Limited Angle (LA)-CBCT Reconstruction
https://arxiv.org/pdf/2404.01448.pdf
133 (2024-04-1) Bigger is not Always Better Scaling Properties of Latent Diffusion Models
https://arxiv.org/pdf/2404.01367.pdf
134 (2024-04-1) Measuring Style Similarity in Diffusion Models
https://arxiv.org/pdf/2404.01292.pdf
135 (2024-04-1) Video Interpolation with Diffusion Models
https://arxiv.org/pdf/2404.01203.pdf
136 (2024-04-1) Uncovering the Text Embedding in Text-to-Image Diffusion Models
https://arxiv.org/pdf/2404.01154.pdf
137 (2024-04-1) UFID A Unified Framework for Input-level Backdoor Detection on Diffusion Models
https://arxiv.org/pdf/2404.01101.pdf
138 (2024-04-1) Texture-Preserving Diffusion Models for High-Fidelity Virtual Try-On
https://arxiv.org/pdf/2404.01089.pdf
139 (2024-04-1) Towards Memorization-Free Diffusion Models
https://arxiv.org/pdf/2404.00922.pdf
140 (2024-04-1) The long-time behavior of solutions of a three-component reaction-diffusion model for the population dynamics of farmers and hunter-gatherers the different motility case
https://arxiv.org/pdf/2404.00907.pdf
# 扩散diffusion模型汇总2
扩散模型应用方向目录
-
1、扩散模型改进
-
2、可控文生图
-
3、风格迁移
-
4、人像生成
-
5、图像超分
-
6、图像恢复
-
7、目标跟踪
-
8、目标检测
-
9、关键点检测
-
10、deepfake检测
-
11、异常检测
-
12、图像分割
-
13、图像压缩
-
14、视频理解
-
15、视频生成
-
16、倾听人生成
-
17、数字人生成
-
18、新视图生成
-
19、3D相关
-
20、图像修复
-
21、草图相关
-
22、版权隐私
-
23、数据增广
-
24、医学图像
-
25、交通驾驶
-
26、语音相关
-
27、姿势估计
-
28、图相关
-
29、动作检测/生成
-
30、机器人规划/智能决策
-
31、视觉叙事/故事生成
-
32、因果生成
-
33、隐私保护-对抗估计
-
34、扩散模型改进-补充
-
35、交互式可控生成
-
36、图像恢复-补充
-
37、域适应-迁移学习
-
38、手交互
-
39、伪装检测
-
40、多任务学习
-
41、轨迹预测
-
42、场景生成
-
43、流估计-3D相关
一、扩散模型改进
1、Accelerating Diffusion Sampling with Optimized Time Steps
2、DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
-
https://github.com/mit-han-lab/distrifuser
3、Balancing Act: Distribution-Guided Debiasing in Diffusion Models
4、Few-shot Learner Parameterization by Diffusion Time-steps
5、Structure-Guided Adversarial Training of Diffusion Models
6、Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models
-
https://github.com/PangzeCheung/SingDiffusion
7、Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
8、Towards Memorization-Free Diffusion Models
9、SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer
二、可控文生图
10、ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
-
https://lukashoel.github.io/ViewDiff/
11、NoiseCollage: A Layout-Aware Text-to-Image Diffusion Model Based on Noise Cropping and Merging
-
https://github.com/univ-esuty/noisecollage
12、Discriminative Probing and Tuning for Text-to-Image Generation
-
https://github.com/LgQu/DPT-T2I
13、Dysen-VDM: Empowering Dynamics-aware Text-to-Video Diffusion with LLMs
14、Face2Diffusion for Fast and Editable Face Personalization
-
https://github.com/mapooon/Face2Diffusion
15、LeftRefill: Filling Right Canvas based on Left Reference through Generalized Text-to-Image Diffusion Model
-
https://github.com/ewrfcas/LeftRefill
16、InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
-
https://jiuntian.github.io/interactdiffusion/
17、MACE: Mass Concept Erasure in Diffusion Models
-
https://github.com/Shilin-LU/MACE
18、MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis
-
https://migcproject.github.io/
19、One-dimensional Adapter to Rule Them All: Concepts, Diffusion Models and Erasing Applications
-
https://lyumengyao.github.io/projects/spm
20、FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models
三、风格迁移
21、DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
-
https://tianhao-qi.github.io/DEADiff/
22、Deformable One-shot Face Stylization via DINO Semantic Guidance
-
https://github.com/zichongc/DoesFS
23、One-Shot Structure-Aware Stylized Image Synthesis
四、人像生成
24、Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
-
https://github.com/YanzuoLu/CFLD
25、High-fidelity Person-centric Subject-to-Image Synthesis
-
https://github.com/CodeGoat24/Face-diffuser
26、Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
-
https://hcplayercvpr2024.github.io/
27、A Unified and Interpretable Emotion Representation and Expression Generation
-
https://emotion-diffusion.github.io/
28、CosmicMan: A Text-to-Image Foundation Model for Humans
-
https://cosmicman-cvpr2024.github.io/
29、DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
30、Texture-Preserving Diffusion Models for High-Fidelity Virtual Try-On
五、图像超分
31、Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder
32、Diffusion-based Blind Text Image Super-Resolution
33、Text-guided Explorable Image Super-resolution
34、Building Bridges across Spatial and Temporal Resolutions: Reference-Based Super-Resolution via Change Priors and Conditional Diffusion Model
-
https://github.com/dongrunmin/RefDiff
六、图像恢复
35、Boosting Image Restoration via Priors from Pre-trained Models
36、Image Restoration by Denoising Diffusion Models with Iteratively Preconditioned Guidance
37、Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks
-
https://yuhaoliu7456.github.io/Diff-Plugin/
38、Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
-
https://github.com/iSEE-Laboratory/DiffUIR
39、Shadow Generation for Composite Image Using Diffusion Model
-
https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2
七、目标跟踪
40、Delving into the Trajectory Long-tail Distribution for Muti-object Tracking
-
https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT
八、目标检测
41、SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
-
https://github.com/zhanggang001/HEDNet
42、DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
43、SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection
九、关键点检测
44、Pose-Guided Self-Training with Two-Stage Clustering for Unsupervised Landmark Discovery
十、deepfake检测
####45、Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
十一、异常检测
46、RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection
-
https://github.com/cnulab/RealNet
十二、抠图/分割
47、In-Context Matting
-
https://github.com/tiny-smart/in-context-matting/tree/master
十三、图像压缩
48、Laplacian-guided Entropy Model in Neural Codec with Blur-dissipated Synthesis
十四、视频理解
49、Abductive Ego-View Accident Video Understanding for Safe Driving Perception
-
http://www.lotvsmmau.net/
十五、视频生成
50、FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation
51、Grid Diffusion Models for Text-to-Video Generation
52、TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
-
https://trip-i2v.github.io/TRIP/
53、Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
-
https://github.com/thuhcsi/S2G-MDDiffusion
54、Video Interpolation With Diffusion Models
-
https://vidim-interpolation.github.io/
十六、倾听人生成
55、CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
-
https://customlistener.github.io/
十七、数字人生成
56、Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework
-
https://github.com/ICTMCG/Make-Your-Anchor
十八、新视图生成
57、EscherNet: A Generative Model for Scalable View Synthesis
十九、3D相关
58、Bayesian Diffusion Models for 3D Shape Reconstruction
59、DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
-
https://github.com/tyhuang0428/DreamControl
60、DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
-
https://github.com/Carmenw1203/DanceCamera3D-Official
61、DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis
-
https://tangjiapeng.github.io/projects/DiffuScene/
62、IPoD: Implicit Field Learning with Point Diffusion for Generalizable 3D Object Reconstruction from Single RGB-D Images
-
https://yushuang-wu.github.io/IPoD/
63、Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
-
https://afford-motion.github.io/
64、MicroDiffusion: Implicit Representation-Guided Diffusion for 3D Reconstruction from Limited 2D Microscopy Projections
-
https://github.com/UCSC-VLAA/MicroDiffusion
65、Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior
-
https://stellarcheng.github.io/Sculpt3D/
66、Score-Guided Diffusion for 3D Human Recovery
-
https://statho.github.io/ScoreHMR/
67、Towards Realistic Scene Generation with LiDAR Diffusion Models
-
https://github.com/hancyran/LiDAR-Diffusion
68、VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation
-
https://vp3d-cvpr24.github.io/
二十、图像修复
69、Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting
-
https://github.com/htyjers/StrDiffusion
二十一、草图相关
70、It’s All About Your Sketch: Democratising Sketch Control in Diffusion Models
71、Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
二十二、版权隐私
72、CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion
-
https://github.com/Nicholas0228/Revelio
73、CPR: Retrieval Augmented Generation for Copyright Protection
二十三、数据增广
74、SatSynth: Augmenting Image-Mask Pairs through Diffusion Models for Aerial Semantic Segmentation
75、ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
-
https://github.com/chenshuang-zhang/imagenet_d
二十四、医学图像
76、MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant
二十五、交通驾驶
77、Controllable Safety-Critical Closed-loop Traffic Simulation via Guided Diffusion
-
https://safe-sim.github.io/
78、Generalized Predictive Model for Autonomous Driving
二十六、语音相关
79、FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
-
https://shivangi-aneja.github.io/projects/facetalk/
80、ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis
-
https://vcai.mpi-inf.mpg.de/projects/ConvoFusion/
81、Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners
-
https://yzxing87.github.io/Seeing-and-Hearing/
二十七、姿势估计
82、Object Pose Estimation via the Aggregation of Diffusion Features
-
https://github.com/Tianfu18/diff-feats-pose
二十八、图相关
83、DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
-
https://github.com/IIT-PAVIS/DiffAssemble
二十九、动作检测或生成
84、Action Detection via an Image Diffusion Process
85、Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
-
https://li-ronghui.github.io/lodge
86、OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
-
https://tr3e.github.io/omg-page/
三十、机器人规划/智能决策
87、SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution
-
https://skilldiffuser.github.io/
三十一、视觉叙事-故事生成
88、Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models
-
https://haoningwu3639.github.io/StoryGen_Webpage/
三十二、因果归因
89、 ProMark: Proactive Diffusion Watermarking for Causal Attribution
三十三、隐私保护-对抗估计
90、Robust Imperceptible Perturbation against Diffusion Models
-
https://github.com/liuyixin-louis/MetaCloak
三十四、扩散模型改进-补充
91、Condition-Aware Neural Network for Controlled Image Generation
-
https://github.com/mit-han-lab/efficientvit
三十五、交互式可控生成
92、Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation
-
https://github.com/haofengl/DragNoise
三十六、图像恢复-补充
93、Generating Content for HDR Deghosting from Frequency View
三十七、域适应/迁移学习
94、Unknown Prompt, the only Lacuna: Unveiling CLIP’s Potential for Open Domain Generalization
-
https://github.com/mainaksingha01/ODG-CLIP
三十八、手交互
95、Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction
-
https://github.com/JunukCha/Text2HOI
96、InterHandGen: Two-Hand Interaction Generation via Cascaded Reverse Diffusion
-
https://jyunlee.github.io/projects/interhandgen/
三十九、伪装检测
97、LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion
-
https://github.com/PanchengZhao/LAKE-RED
四十、多任务学习
98、DiffusionMTL: Learning Multi-Task Denoising Diffusion Model from Partially Annotated Data
-
https://prismformore.github.io/diffusionmtl/
四十一、轨迹预测
99、SingularTrajectory: Universal Trajectory Predictor Using Diffusion Model
-
https://github.com/inhwanbae/SingularTrajectory
四十二、场景生成
100、SemCity: Semantic Scene Generation with Triplane Diffusion
-
https://github.com/zoomin-lee/SemCity
四十三、3D相关/流估计
101、DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









