







# 仿真平台与端到端系统~ 面向协同自动驾驶
-
论文链接:https://arxiv.org/pdf/2404.09496
-
代码链接:https://github.com/CollaborativePerception/V2Xverse
摘要
本文介绍了面向协同自动驾驶:仿真平台与端到端系统。车路协同辅助(V2X-AD)在提供更安全的驾驶解决方案方面具有巨大潜力。尽管在交通和通信方面进行了大量的研究以支持V2X-AD,但是这些基础设施和通信资源在提高驾驶性能方面的实际利用仍未得到充分探索。这突显了协同自动驾驶的必要性,即优化信息共享策略来改进每辆汽车驾驶性能的机器学习方法。这项工作需要两个关键的基础条件:一个能够生成数据来促进V2X-AD训练和测试的平台,以及一个集成驾驶相关完整功能与信息共享机制的综合系统。从平台的角度看,本文提出了V2Xverse,这是一个用于协同自动驾驶的综合仿真平台。该平台为协同驾驶提供了完整的流程:多智能体驾驶数据集生成方案、部署全栈协同驾驶系统的代码库、具有场景定制的闭环驾驶性能评估。从系统的角度看,本文引入了CoDriving,这是一种新型的端到端协同驾驶系统,它将V2X通信正确地集成到整个自动化流程中,促进了基于共享感知信息的驾驶。其核心思想为一种新型的面向驾驶的通信策略,即使用稀疏但信息丰富的感知线索在单视图中选择性地补充关键的驾驶区域。通过这一策略,CoDriving在优化通信效率的同时,提高了驾驶性能。本文使用V2Xverse进行全面基准测试,分析了模块化性能和闭环驾驶性能。实验结果表明:1)与SOTA端到端驾驶方法相比,CoDriving的驾驶得分显著提高了62.49%,行人碰撞率急剧降低了53.50%;2)与动态约束通信条件相比,CoDriving实现了持续的驾驶性能优势。
主要贡献
本文的贡献总结如下:
1)本文提出了V2Xverse,这是一个综合的V2X辅助的自动驾驶仿真平台。该平台支持驾驶相关子任务的离线基准生成和不同场景下的在线闭环驾驶性能评估,从而实现协同驾驶系统的开发;
2)本文提出了CoDriving,这是一种新型的端到端协同自动驾驶系统,通过共享关键驾驶信息来提高驾驶性能; whaosoft aiot http://143ai.com
3)本文进行综合的实验,并且验证了:1)支持V2X通信的信息共享显著优于单个智能体的端到端自动驾驶系统;2)CoDriving在模块化和系统级评估中实现了优越的性能-带宽权衡。
总结
本项工作通过仿真平台和端到端系统来推进协同自动驾驶。本文开发了一个综合的闭环V2X全自动驾驶仿真平台V2Xverse。该平台为开发以终极驾驶性能为目标的协同自动驾驶系统提供了完整的流程。同时,V2Xverse维持了对单功能模块和单智能体驾驶系统进行集成和验证的适应性和可扩展性。此外,本文提出了一种新的端到端协同自动驾驶系统CoDriving,其通过共享关键的驾驶感知信息来提高驾驶性能,同时优化通信效率。对整个驾驶系统的综合评估表明,CoDriving在不同的通信带宽下显著优于单智能体系统。本文的V2Xverse平台和CoDriving系统为更可靠的自动驾驶提供了潜在的解决方案。
# FisheyeDetNet
目标检测在自动驾驶系统当中是一个比较成熟的问题,其中行人检测是最早得以部署算法之一。在多数论文当中已经进行了非常全面的研究。然而,利用鱼眼相机进行环视的近距离的感知相对来说研究较少。由于径向畸变较大,标准的边界框表示在鱼眼相机当中很难实施。为了缓解上述提到的相关问题,我们探索了扩展边界框的标准对象检测输出表示。我们将旋转的边界框、椭圆、通用多边形设计为极坐标弧/角度表示,并定义一个实例分割mIOU度量来分析这些表示。所提出的具有多边形的模型FisheyeDetNet优于其他模型,同时在用于自动驾驶的Valeo鱼眼相机数据集上实现了49.5%的mAP指标。目前,这是第一个关于自动驾驶场景中基于鱼眼相机的目标检测算法研究。
文章链接:https://arxiv.org/pdf/2404.13443.pdf
网络结构
我们的网络结构建立在YOLOv3网络模型的基础上,并且对边界框,旋转边界框、椭圆以及多边形等进行多种表示。为了使网络能够移植到低功率汽车硬件上,我们使用ResNet18作为编码器。与标准Darknet53编码器相比,参数减少了近60%。提出了网络架构如下图所示。
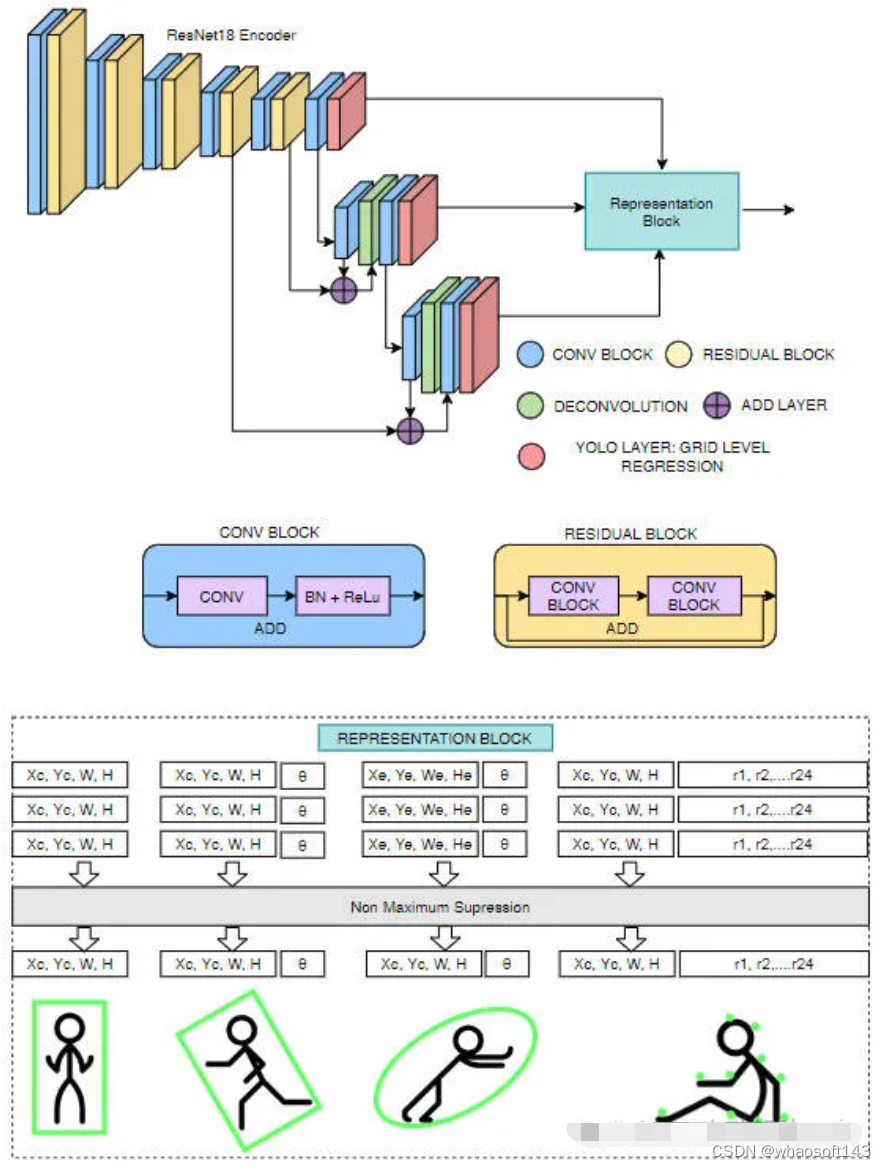
边界框检测

旋转边界框检测

椭圆检测
椭圆回归与定向框回归相同。唯一的区别是输出表示。因此损失函数也与定向框损失相同。
多边形检测
我们提出的基于多边形的实例分割方法与PolarMask和PolyYOLO方法非常相似。而不是使用稀疏多边形点和像PolyYOLO这样的单尺度预测。我们使用密集多边形注释和多尺度预测。
实验对比
我们在Valeo鱼眼数据集上评估,该数据集有 60K 图像,这些图像是从欧洲、北美和亚洲的 4 个环绕视图相机捕获的。
所有模型都使用 IoU 阈值为 50% 的平均精度度量 (mAP) 进行比较。结果如下表所示。每个算法都基于两个标准进行评估—相同表示和实例分割的性能。


# 100个路径规划相关概念
-
路径规划(Path Planning)
路径规划是寻找从起点到终点最佳路线的过程,关键在于如何高效地避开障碍物并优化特定的路径指标(如距离、时间或能量消耗)。在机器人导航、自动驾驶、物流和游戏设计等领域,路径规划是基础且关键的问题。高级路径规划系统还会考虑动态环境变化,如移动障碍物和不确定性因素,以适应复杂的实际应用场景。
-
广度优先搜索(BFS)
BFS是一种图搜索算法,从一个节点开始,逐层探索周围节点,直到找到目标节点。它使用队列来管理待探索的节点,保证了每一层的节点都在进入下一层之前被完全探索。这种方法特别适合于找到最短路径问题,在无权图(即所有边的权重相同)中尤其有效。
-
深度优先搜索(DFS)
DFS是一种图搜索算法,它沿着一条路径深入探索,直到无法继续,然后回溯到上一个分叉点继续探索其他路径。DFS使用栈(可以是递归函数调用栈)来跟踪待探索的路径。DFS适合于需要遍历所有可能路径的场景,如解决迷宫问题、图的连通性检查等。
-
Dijkstra算法
Dijkstra算法是解决加权图中单源最短路径问题的经典算法。它逐步扩展已知最短路径的边界,直到达到目标节点。虽然Dijkstra算法能够高效地处理大量节点,但它不适用于包含负权重边的图。
-
启发式搜索(Heuristic Search)
启发式搜索使用启发式函数来估计从任一节点到目标的距离,从而指导搜索过程,优先探索更有希望的路径。这种方法能够显著提高搜索效率,特别是在搜索空间庞大且目标位置未知的情况下。
-
A*搜索算法
A算法是一种高效的启发式搜索算法,它结合了BFS的全面性和启发式搜索的高效性。A算法通过评估函数f(n) = g(n) + h(n)来选择路径,其中g(n)是从起点到当前节点的实际成本,h(n)是当前节点到目标的估计成本。A*算法广泛应用于各种路径规划和图搜索问题,如游戏设计和机器人导航。
-
基于采样的算法
基于采样的路径规划算法通过在配置空间中随机采样并尝试连接这些样本点来避免对环境的显式表示。这些算法,特别是RRT和PRM,适用于高维空间和复杂约束条件下的路径规划,能够有效处理机器人臂和移动机器人的规划问题。
-
RRT算法
RRT算法以其随机性和简单性而著称,适合于解决高维空间和复杂约束下的路径规划问题。RRT通过从初始状态开始,不断向随机采样的状态扩展,直到达到目标区域或满足特定条件,从而构建出一棵覆盖配置空间的树。
-
运动学模型
运动学模型描述了系统的几何运动特性,不考虑力和质量的影响。在机器人领域,运动学模型是理解和预测机器人如何在其环境中移动的基础,对于设计控制系统和规划运动轨迹至关重要。
-
动力学模型
动力学模型考虑了物体的运动和作用于物体的力之间的关系,提供了对系统动态行为的更深入理解。这些模型对于设计高性能机器人系统和高级控制策略非常重要,特别是在需要精确控制力和运动的应用中。
-
Dubins曲线
Dubins曲线为具有最小转弯半径限制的车辆提供了从一点到另一点的最短路径解决方案。这种路径由三段组成:直线、圆弧和直线(LSL)、或圆弧、直线、圆弧(LSR)。Dubins曲线在需要考虑车辆转向限制的路径规划中非常有用,如无人机和自动驾驶车辆。
-
Reeds-Shepp曲线
Reeds-Shepp曲线扩展了Dubins曲线,允许路径中包含倒车(即车辆可以向后移动)。这为路径规划提供了更大的灵活性,使得Reeds-Shepp曲线适用于更多种类的车辆和更复杂的规划环境。
-
混合A*算法
混合A算法结合了经典A算法的图搜索能力和连续空间规划的优势,通过离散化车辆的状态空间来考虑车辆的动力学约束。这种方法特别适合于复杂环境中的自动驾驶汽车路径规划,因为它能够生成适应车辆动力学的实际可行路径。
-
DWA算法
动态窗口法考虑了机器人的当前速度和加速度约束,通过搜索一系列在短时间内可达的速度空间(动态窗口)来选择最优的速度和转向角。DWA算法适用于动态环境中的避障和路径跟踪,特别是对于需要快速响应的移动机器人。
-
TEB算法
时间弹性带(TEB)算法是一种基于优化的路径规划方法,它将路径建模为一系列连接的点,这些点可以在时间和空间中进行优化调整,以适应动态约束和避免障碍。TEB算法特别适合于需要考虑动态环境和复杂交互的应用,如自动驾驶车辆在城市交通中的导航。
-
Ubuntu版本与ROS版本
Ubuntu是一个基于Debian的Linux发行版,以其用户友好和广泛的社区支持而闻名。ROS(Robot Operating System)是一个为机器人应用开发提供库和工具的框架,与Ubuntu紧密集成。ROS有多个版本,每个版本通常针对特定的Ubuntu发行版进行优化。例如,ROS Noetic是专为Ubuntu 20.04 LTS(Focal Fossa)开发的,而ROS Melodic则更适合Ubuntu 18.04 LTS(Bionic Beaver)。了解ROS和Ubuntu版本之间的兼容性对于设置机器人开发环境非常重要。
-
ROS(Robot Operating System)
ROS是一个开源的机器人中间件,提供了一种简化机器人应用开发的方式。它包括一系列工具和库,用于帮助开发者构建复杂且健壮的机器人应用。ROS的核心是其通信系统,允许不同部分的机器人系统(如传感器、控制器、算法模块等)通过主题、服务和动作等机制进行交互。
-
TurtleBot
TurtleBot是一个流行的开源移动机器人平台,经常用于教育和研究。它基于ROS,支持各种传感器和扩展模块。TurtleBot提供了一个低成本、易于使用的平台,用于开发和测试机器人算法,包括导航、映射和交互。
-
Gazebo, RViz, Stage_ros
Gazebo是一个高级的3D机器人仿真环境,能够模拟复杂的动态和传感器交互。
RViz是一个3D可视化工具,用于显示ROS中的传感器数据、机器人模型和算法输出,支持用户与数据进行交互。
Stage_ros是一个快速的2D机器人仿真环境,适用于测试机器人导航和路径规划算法。
-
ROS Navigation Stack
ROS Navigation Stack是一个功能强大的软件包,提供了使机器人能够自主定位和导航到目标位置的工具和算法。它结合了多个组件,包括地图构建(SLAM)、定位(AMCL)、路径规划(Dijkstra、A*等)和避障,为移动机器人提供了一套完整的导航解决方案。
-
栅格地图(Grid Map)
栅格地图通过将环境分割成一个个小方格来构建对环境的数字表示。每个方格代表环境中的一块区域,可以存储不同类型的信息,如该区域是否可通行(无障碍物),或者该区域的特定属性(如地形的高度)。这种地图的优势在于其简单性和直观性,使其成为机器人路径规划和室内导航中常用的地图类型。
-
ESDF地图(Euclidean Signed Distance Field)
ESDF地图为每个点提供到最近障碍物表面的最短欧几里得距离。正值表示该点在障碍物外部,负值表示在障碍物内部。这种地图对于避障和路径规划非常有用,因为它不仅告诉机器人哪里有障碍,还提供了关于障碍物大小和形状的详细信息,使路径规划更加安全和高效。
-
维诺图(Voronoi Diagram)
维诺图通过将平面分割成多个区域来构建,每个区域内的所有点都比其他区域的点更接近某个特定的“种子”点。在路径规划中,维诺图常被用来确定一条避开障碍物的安全路径,因为这种路径最大限度地远离障碍物,从而减少与障碍物发生碰撞的风险。
-
点云地图(Point Cloud Map)
点云地图由一系列在三维空间中分布的点组成,每个点代表了环境中的一个特征,如物体的边缘或表面。这些地图通常由激光扫描仪、深度相机等传感器生成,能够提供环境的详细三维结构信息,对于机器人进行精确的空间定位和环境建模至关重要。
-
拓扑地图(Topological Map)
拓扑地图关注的是空间中的地点(节点)及地点之间的连接关系(边),而非具体的几何形状或距离。这种地图适用于描述环境的抽象结构,如不同房间之间的关系,使得机器人可以在更大的尺度上进行有效的路径规划和导航。
-
差速底盘模型(Differential Drive Model)
差速底盘模型描述了两轮独立驱动的机器人如何通过改变两个轮子的速度差来实现转向和移动。这种模型适用于很多基本的移动机器人,因为它结构简单,容易实现。通过调节左右轮的速度,机器人可以原地转弯、直线行驶或沿曲线路径移动。
-
自行车模型(Bicycle Model)
自行车模型是车辆运动学的一种简化,其中车辆被假设为具有两个轮子的自行车,前轮用于转向,后轮在车身后部固定。这种模型在自动驾驶和车辆动力学研究中非常有用,因为它能够以简单的数学形式捕捉车辆的转向动态和行为。
-
质点模型(Particle Model)
质点模型是物理学中的一个基本概念,它将物体简化为一个具有质量但没有体积的点,忽略其形状和大小。这种模型适用于分析物体的线性运动(如平移),因为它忽略了旋转和形状变化等复杂因素。质点模型使问题简化,便于理解和计算物体的运动状态(如位置、速度、加速度)。
-
膨胀半径(Inflation Radius)
在机器人路径规划中,膨胀半径是一种安全策略,用于增加机器人与障碍物之间的安全距离。通过在障碍物周围设定一个虚拟的“膨胀区域”,确保机器人在规划路径时不仅避开障碍物本身,还能避开这个膨胀区域,从而预留出足够的空间来应对定位误差、机器人尺寸或其他潜在因素,增加路径的安全性。
-
MPC(模型预测控制)
模型预测控制是一种动态系统的控制策略,其核心思想是利用系统的当前状态来预测未来一段时间内的系统行为,并在此基础上优化控制输入,以实现期望的输出。MPC在每个控制周期都会解决一个优化问题,以确定当前的最优控制动作。这种控制方法特别适合于处理有约束的系统,因为它能够在规划过程中考虑到系统的物理限制和操作限制。
-
硬约束和软约束
在优化和控制问题中,硬约束是指必须被严格遵守的约束条件,违反硬约束会导致解变得不可接受或不可行。例如,机器人的物理尺寸限制了它不能穿过比自己小的空间,这就是一个硬约束。软约束则是那些在优化过程中希望遵守但并非绝对必须满足的条件。软约束通常通过在目标函数中加入惩罚项来实现,允许在一定程度上的违反,以获得更优的整体性能或更灵活的解决方案。
-
多项式曲线(Polynomial Curve)
多项式曲线是由多项式方程定义的一类曲线,其形式为P(x) = a_n*xn + a_{n-1}x{n-1} + ... + a_1x + a_0,其中a_n, a_{n-1}, ..., a_1, a_0是多项式的系数,n是多项式的阶数。多项式曲线在插值、曲线拟合和动画中广泛使用,因为它们数学表达简单,易于计算和调整。
-
贝塞尔曲线(Bezier Curve)
贝塞尔曲线是一种广泛使用的参数曲线,特别是在计算机图形和动画设计中。贝塞尔曲线通过一组控制点定义,曲线形状由这些控制点的位置和顺序决定。贝塞尔曲线具有很好的数学性质,如局部控制性(移动一个控制点只影响曲线的一部分)和可变形性(通过调整控制点可以轻松改变曲线形状),使其在设计和动画制作中非常灵活和有用。
-
螺旋线(Spiral)
螺旋线是一种在平面或三维空间中半径随角度变化的曲线。在二维空间中,螺旋线从一个固定点开始,随着角度的增加,离中心点的距离也逐渐增加。螺旋线在自然界和技术应用中都非常常见,如蜗牛的壳、春卷的形状和道路设计中的缓和曲线。
-
离散点(Discrete Points)
离散点指的是在数学和计算机科学中,点的集合中的元素是分开的、不连续的。在数据分析、图像处理和科学计算中,经常需要处理由离散点组成的数据集。这些点可以代表各种物理量的测量值,如温度、压力或其他传感器数据。
-
泰勒展开近似
泰勒展开是一种数学方法,用来近似表示复杂函数。它将一个函数展开成多项式的形式,使我们可以用几个简单的项来近似计算函数的值。这种方法在物理和工程问题中非常有用,尤其是当直接计算函数值很困难时。
-
完整性约束和非完整性约束
完整性约束指的是系统的运动可以完全由其位置和位置变化来描述的约束。例如,一个可以自由移动的机器人在平面上的运动可以完全由其在该平面上的位置来描述。
非完整性约束涉及到系统的运动不能仅由位置和位置的变化来描述的情况。例如,汽车由于其转向机制的限制,不能横向移动。
-
凸优化
凸优化是一类特殊的优化问题,其中目标函数是凸函数,这意味着函数的任意两点连线上的点都不低于函数曲线。凸优化问题的一个关键特性是它们的局部最优解也是全局最优解。凸优化在金融、机器学习和自动控制系统设计中有广泛应用。
-
非线性优化
非线性优化是指目标函数或约束条件为非线性的优化问题。这类问题更为常见,但也更难解决。非线性优化广泛应用于机器人路径规划、能源管理和化学工程设计等领域。
-
二次规划
二次规划是一种特殊类型的优化问题,其目标函数是二次的,而约束条件是线性的。二次规划在投资组合优化、飞行器航迹规划和机器人运动规划中有重要应用。
-
Eigen库
Eigen是一个高级C++库,用于进行矩阵运算、线性代数变换、数值解析等。它在计算机视觉、机器人技术和物理模拟中被广泛使用,以提高数学运算的效率和准确性。
-
OSQP求解器
OSQP(Operator Splitting Quadratic Program)求解器是专门用于求解凸二次规划问题的软件库。它在自动驾驶车辆的轨迹优化、能量系统的优化调度等领域有着重要的应用。
-
NLopt求解器
NLopt是一个用于求解非线性优化问题的库,支持多种优化算法。它可以应用于工程设计优化、经济学模型优化和机器学习模型调优等领域。
-
横纵向解耦
横纵向解耦是在车辆动力学控制中将车辆的纵向控制(加速和制动)与横向控制(转向)分开处理的方法。这种方法简化了控制系统的设计,常见于自动驾驶系统的开发中。
-
时空联合
时空联合是在路径规划和调度问题中同时考虑时间和空间约束的方法。例如,在自动驾驶中,需要规划一条既考虑避免与其他车辆和障碍物空间上的碰撞,又要考虑到达时间的路径。
-
碰撞检测(Collision Detection)
碰撞检测是指在计算机模拟和机器人学中确定两个或多个对象是否相互接触或交叉的过程。在自动驾驶领域,碰撞检测用于确保车辆在行驶过程中能够避开其他车辆、行人和障碍物,从而保障行车安全。
-
AABB(Axis-Aligned Bounding Box)
AABB,即轴对齐边界盒,是一种简单的碰撞检测技术,其中使用与坐标轴平行的矩形或立方体来包围物体。AABB简化了碰撞检测的计算,使其在计算机图形学和游戏开发中得到广泛应用。
-
DP动态规划(Dynamic Programming)
动态规划是一种算法设计技术,用于解决具有重叠子问题和最优子结构的复杂问题。在自动驾驶中,动态规划可用于路径规划、速度优化等,通过将大问题分解为小问题并存储中间结果来提高计算效率。
-
曲率和曲率导数
曲率描述了曲线弯曲的程度,是曲线上任意点处切线方向变化的速率。在车辆路径规划中,曲率用于评估路径的转弯强度,确保车辆能够安全行驶。
曲率导数则描述了曲率沿曲线的变化率,对于分析和控制车辆的转向动态特别重要。
-
一阶导数和二阶导数
一阶导数表示函数值随变量变化的瞬时速率,用于描述物体的速度或曲线的斜率。
二阶导数表示一阶导数的变化率,用于描述加速度或曲线的凹凸性(曲率)。
-
曲线连续和平滑
曲线的连续性和平滑性是曲线几何特性的度量,直接影响路径规划和车辆控制的质量。连续的曲线没有断点,平滑的曲线则没有尖锐的转弯,这对于确保自动驾驶车辆平稳舒适的行驶至关重要。
-
Frenet坐标系
Frenet坐标系是一种沿着曲线定义的局部坐标系,使用曲线上的点(位置)、切向量(方向)、法向量和副法向量来描述。在自动驾驶中,Frenet坐标系常用于路径规划,因为它可以简化车辆沿道路行驶的描述。
-
笛卡尔坐标系(Cartesian Coordinate System)
笛卡尔坐标系是最常见的坐标系,由垂直的x轴和y轴组成,用于在平面上定位点。自动驾驶中使用笛卡尔坐标系来表示车辆、障碍物的位置以及规划的路径。
-
行为决策(Behavioral Decision)
行为决策是自动驾驶系统中决定车辆行为(如变道、加速、减速)的过程。这涉及到理解周围环境,预测其他交通参与者的行为,并根据当前的交通状况做出安全且合理的驾驶决策。
-
转弯半径(Turning Radius)
转弯半径是指车辆进行转弯时,车辆中心点所描述的圆的半径。它是车辆操控性的一个重要参数,影响车辆在有限空间内的行驶能力。在自动驾驶中,合理规划转弯半径对于确保车辆安全通过弯道至关重要。
-
控制量(Control Variable)
控制量是控制系统中可以被调节以影响系统行为的变量。在自动驾驶车辆中,控制量通常包括加速度、方向盘转角等,通过调整这些变量来实现对车辆运动状态的精确控制。
-
轨迹优化(Trajectory Optimization)
轨迹优化是寻找最优路径的过程,使得车辆能够在满足所有约束(如避免碰撞、遵守交通规则)的情况下,以最优的方式(如最短时间、最低能耗)从起点移动到终点。这是自动驾驶中路径规划的核心环节。
-
速度规划(Speed Planning)
速度规划是确定车辆在路径上的速度分布的过程。它需要考虑各种因素,如道路限速、交通状况、曲率等,以确保行驶安全同时提高行驶效率。
-
T型和S型速度曲线(Trapezoidal and S-curve Speed Profiles)
T型速度曲线(Trapezoidal Speed Profile)是指速度随时间变化呈现线性上升、恒速和线性下降的形态,像一个梯形。这种速度曲线常用于简单的运动控制场景。
S型速度曲线(S-curve Speed Profile)则在加速度和减速度过程中加入了平滑过渡,使得速度曲线在起始和结束时更为平滑,减少了冲击和振动,适用于需要平滑加减速的场景。
-
自动驾驶参考线(Reference Line for Autonomous Driving)
自动驾驶参考线是车辆预计行驶的理想路径,通常基于道路中心线或车道线生成。规划模块会在此基础上生成实际的行驶轨迹,尽可能地跟随参考线,同时考虑动态障碍物、交通规则等因素。
-
BEV(Bird's Eye View)
鸟瞰视图(BEV)是从顶部向下看的视角,提供了对车辆周围环境的全面视图。在自动驾驶系统中,BEV常用于融合来自多个传感器的信息,帮助算法更好地理解车辆周围的情况,进行决策。
-
语义信息(Semantic Information)
语义信息是指对环境元素的类型和功能的理解,如路标、车辆、行人等。在自动驾驶中,语义信息对于理解道路情况、做出正确的行为决策至关重要。通过对传感器数据(如来自摄像头和雷达的数据)进行深度学习分析,自动驾驶系统能够识别和理解周围环境的语义信息。
-
曲率突变(Curvature Discontinuity)
曲率突变是指曲线在某一点或某一区域内曲率发生急剧变化的现象。在道路和路径规划中,曲率突变可能导致车辆行驶不稳定,因此避免在自动驾驶车辆的路径规划中产生曲率突变是非常重要的。
-
换挡点(Shift Points)
换挡点是指自动变速器根据车辆速度和发动机负载决定换挡时机的点。在自动驾驶系统中,合理设置换挡点对于保证驾驶平顺性和提高燃油经济性都非常关键。
-
SL图和ST图(SL and ST Graphs)
SL图是Frenet坐标系下的表示,将车辆路径分解为沿着道路中心线的纵向距离(S)和横向偏移(L)。SL图常用于路径规划,以简化车辆相对于道路的位置表示。
ST图表示时间(T)与纵向距离(S)的关系,常用于速度规划,以确保车辆遵循预定的时空轨迹,避免碰撞,并优化行驶效率。
-
重规划(Replanning)
重规划是指在自动驾驶过程中,由于检测到新的障碍物、变化的交通条件或其他未预见因素,自动驾驶系统需要重新计算路径或行为策略。重规划确保车辆能够适应动态环境,安全高效地到达目的地。
-
概率完备(Probabilistic Completeness)
概率完备是指一个算法如果给予足够的时间运行,最终能够以高概率找到问题的解(如果解存在的话)。在自动驾驶路径规划中,考虑概率完备性的算法能够在复杂环境中提高找到安全路径的可能性。
-
KPH(Kilometers Per Hour)
KPH是速度的度量单位,表示每小时行驶的公里数。在自动驾驶系统中,对车辆速度的测量、规划和控制通常使用KPH作为单位。
-
换道(Lane Changing)
换道是指车辆从当前行驶车道转移到另一车道的行为。自动驾驶系统中的换道决策需要考虑周围车辆的位置、速度、以及换道后的行驶效率和安全性。
-
线控底盘(By-Wire Chassis)
线控底盘是指车辆的控制系统(如转向、制动、加速)完全通过电子信号控制,而不是传统的机械连接。在自动驾驶车辆中,线控底盘是实现高级自动化控制的基础。
-
Lattice Planner
格点规划器(Lattice Planner)是一种用于路径规划的算法,它通过创建一个离散的格点网络,并在这个网络中搜索从起点到终点的最优路径。格点规划器能够考虑车辆的动态约束和路况,广泛应用于自动驾驶车辆的轨迹规划中。
-
EMPlanner
EMPlanner(Expectation Maximization Planner)是一种基于期望最大化算法的路径和行为规划器。它能够处理周围环境的不确定性,通过预测其他交通参与者的行为来规划出一条安全高效的路径。EMPlanner在复杂交通场景下的自动驾驶系统中特别有用。
73-74. 二次规划和非线性优化
前文已经进行了说明,二次规划和非线性优化是解决优化问题的两种方法,分别处理目标函数是二次和非线性的情况。
-
OSQP
前文已经介绍了OSQP求解器,它是专门用于求解凸二次规划问题的库,尤其适用于处理稀疏问题。
-
NLopt
NLopt是一个用于非线性优化的开源库,支持多种全局和局部优化算法。NLopt能够处理包括无约束、有约束、连续和离散变量在内的各种优化问题。
-
Ipopt
Ipopt(Interior Point OPTimizer)是一个用于求解大规模非线性优化问题的开源软件包。它使用内点法,适用于处理具有复杂约束的优化问题,如工业设计和金融模型优化。
-
梯度下降法和拟牛顿法
梯度下降法是一种最优化算法,通过沿着目标函数梯度下降的方向迭代更新变量值来寻找函数的最小值。梯度下降法简单易实现,适用于各种优化问题。
拟牛顿法是求解非线性优化问题的一类算法,通过逼近海森矩阵(Hessian Matrix)的逆或者海森矩阵本身来寻找函数的极小值点,提高优化的效率和准确性。
-
优化变量和决策变量
优化变量和决策变量是指在优化问题中需要被优化或决策的变量。在自动驾驶的轨迹规划中,优化变量可能包括车辆的速度、加速度、方向等。
-
非线性约束
非线性约束是指在优化问题中约束条件为非线性方程或不等式的情况。非线性约束增加了优化问题的复杂度,常见于工程设计和经济模型中。
-
完整性约束和非完整性约束
前文已经进行了说明,完整性约束和非完整性约束涉及系统运动的描述方式,特别是在自动驾驶车辆的动力学建模中。
-
行为决策
行为决策是指自动驾驶系统决定车辆行为(如跟车、变道、转弯等)的过程。行为决策需要考虑交通规则、周围环境、车辆状态和乘客的安全与舒适。
-
有限状态机(Finite State Machine, FSM)
有限状态机是一种计算模型,它通过一组定义良好的状态和在这些状态之间的转换来描述系统的行为。在自动驾驶系统中,有限状态机常用于实现车辆行为的决策逻辑。
-
代码Review
代码Review是软件开发过程中的一种质量保证活动,其中开发人员检查同事的代码,以发现错误并改进代码质量。在自动驾驶系统的开发中,代码Review是确保软件可靠性和安全性的关键步骤。
-
代码版本管理
代码版本管理是指使用专门的工具(如Git)来管理软件开发过程中代码的变更历史的做法。这使得开发团队能够协作开发,跟踪每次代码改动,并能在必要时恢复到旧版本。
-
矩阵运算
矩阵运算是线性代数中的基本运算,包括矩阵加法、乘法、转置等。在自动驾驶系统中,矩阵运算被广泛用于处理传感器数据、执行数学变换和优化计算。
-
最优控制(Optimal Control)
最优控制是一种寻找控制系统最优输入(如加速度或转向角度)的方法,使得系统性能达到最佳。在自动驾驶中,最优控制策略可以帮助车辆以最经济或最快的方式从一个状态转移到另一个状态,同时满足所有的动态约束和安全要求。
-
MPC(Model Predictive Control)
模型预测控制是一种先进的控制策略,通过解决一系列优化问题,预测未来一段时间内的系统行为,并计算出最优控制输入。MPC能够考虑系统的未来行为和约束,因此在自动驾驶系统中特别有用,用于路径规划和避免障碍物。
-
状态转移方程(State Transition Equation)
状态转移方程描述了系统状态如何随时间变化,通常以数学模型的形式出现。在自动驾驶中,状态转移方程可以表示车辆的动态行为,如速度、加速度和位置的变化,对于预测车辆未来状态至关重要。
-
贝塞尔曲线求导(Derivatives of Bézier Curves)
贝塞尔曲线的导数用于计算曲线在某一点的切线和曲率,对于分析和控制曲线形状特别重要。在自动驾驶中,贝塞尔曲线及其导数可用于平滑路径规划和轨迹生成。
-
B样条曲线及其求导(B-spline Curves and Their Derivatives)
B样条曲线是一种通过一组控制点定义的平滑曲线,广泛用于计算机图形学和路径规划。B样条曲线的导数可用于分析曲线的局部性质,如切线方向和曲率,对于设计平滑连续的车辆轨迹至关重要。
-
五次多项式曲线及其曲率表达式(Quintic Polynomial Curves and Their Curvature Expressions)
五次多项式曲线是一种通过五次方程定义的曲线,常用于路径规划中以生成平滑的轨迹。曲率表达式描述了曲线弯曲程度的变化,对于评估路径的可行性和安全性非常重要。
-
螺旋线与其他样条曲线的区别
螺旋线是一种半径随曲线长度变化的曲线,常用于道路和轨道设计中的过渡曲线。与其他样条曲线(如B样条和贝塞尔曲线)相比,螺旋线在连接直线和圆弧段时能提供更平滑的转换,减少车辆转向时的离心力。
-
非线性最小二乘(Nonlinear Least Squares)
非线性最小二乘是一种数学优化方法,用于拟合非线性模型到数据。它通过最小化预测值和实际值之间的差异的平方和来寻找最佳拟合参数。在自动驾驶系统中,非线性最小二乘可用于传感器数据融合和车辆状态估计。
95-96. 微分平坦(Differential Flatness)
微分平坦是指系统的所有状态和控制输入都可以通过一组“平坦输出”及其导数来表示。在无人机和无人车领域,微分平坦性使得系统的控制和规划更加简单,因为可以直接在平坦输出空间中进行。
-
ADAS(Advanced Driver-Assistance Systems)
高级驾驶辅助系统(ADAS)是一系列使用先进技术来提高驾驶安全和舒适性的系统。这包括自动紧急刹车、车道保持辅助、自适应巡航控制等功能。ADAS是自动驾驶技术发展的基础。
-
高精地图(High-Definition Maps)
高精地图是自动驾驶系统中使用的详细地图,提供道路、交通标志、交通灯和其他关键地理信息的精确表示。高精地图对于自动驾驶车辆的定位、导航和环境感知至关重要。
-
不确定性规划MDP(Markov Decision Processes)
MDP是一种数学框架,用于建模决策过程中的不确定性和随机性。在自动驾驶中,MDP可用于模拟车辆在不确定的交通环境中做出决策的过程,如何在不同的交通情况下选择最佳的行为策略,以最大化行驶的安全性和效率。
-
概率完备性(Probabilistic Completeness)
概率完备性是指一个算法最终能够以一定的概率找到问题的解(如果解存在)。在自动驾驶的路径规划中,考虑概率完备性的算法可以提高在复杂和不确定环境中找到安全路径的可能性。
-
有限状态机(Finite State Machine, FSM)
有限状态机是描述一个系统可以处于有限个状态之一,并且在给定的输入下可以从一个状态转移到另一个状态的数学模型。自动驾驶系统中的行为决策往往利用有限状态机来管理不同的驾驶模式和行为,如巡航、变道、避障等。
-
代码版本管理(Version Control)
代码版本管理是使用专门的系统(如Git)来追踪和管理软件代码变更的过程。这使得团队成员可以协作开发,跟踪每次更改,并能够在需要时恢复到之前的版本,是自动驾驶软件开发不可或缺的部分。
# 单目3D车道线检测
3D车道检测在自动驾驶中起着至关重要的作用,通过从三维空间中提取道路的结构和交通信息,协助自动驾驶汽车进行合理、安全和舒适的路径规划和运动控制。考虑到传感器成本和视觉数据在颜色信息方面的优势,在实际应用中,基于单目视觉的3D车道检测是自动驾驶领域的重要研究方向之一,引起了工业界和学术界越来越多的关注。不幸的是,最近在视觉感知方面的进展似乎不足以开发出完全可靠的3D车道检测算法,这也妨碍了基于视觉传感器的完全自动驾驶汽车的发展,即实现L5级自动驾驶,像人类控制的汽车一样驾驶。
这是这篇综述论文得出的结论之一:在使用视觉传感器的自动驾驶汽车的3D车道检测算法中仍有很大的改进空间,仍然需要显著的改进。在此基础上,本综述定义、分析和审查了3D车道检测研究领域的当前成就,目前绝大部分进展都严重依赖于计算复杂的深度学习模型。此外,本综述涵盖了3D车道检测流程,调查了最先进算法的性能,分析了前沿建模选择的时间复杂度,并突出了当前研究工作的主要成就和局限性。该调查还包括了可用的3D车道检测数据集的全面讨论以及研究人员面临但尚未解决的挑战。最后,概述了未来的研究方向,并欢迎研究人员和从业者进入这个激动人心的领域。
在人工智能的推动下,自动驾驶技术近年来取得了快速发展,逐渐重塑了人类交通运输的范式。配备了一系列传感器,自动驾驶车辆模仿人类的视觉和听觉等感知能力,以感知周围环境并解释交通场景以确保安全导航。其中关键的传感器包括激光雷达、高分辨率相机、毫米波雷达和超声波雷达,它们促进了特征提取和目标分类,并结合高精度地图制图来识别障碍物和车辆交通景观。视觉传感器是自动驾驶车辆中最广泛使用的,它们作为环境感知的主要手段,包括车道检测、交通信号灯分析、路标检测和识别、车辆跟踪、行人检测和短期交通预测。在自动驾驶中处理和理解视觉场景,包括交通信号灯的分析、交通标志的识别、车道检测以及附近行人和车辆的检测,为转向、超车、变道或刹车等操作提供更稳健和更安全的指令。传感器数据和环境理解的整合无缝地过渡到自动驾驶中的场景理解领域,这对于推进车辆自主性和确保道路安全至关重要。
场景理解代表了自动驾驶领域中最具挑战性的方面之一。缺乏全面的场景理解能力,使得自动驾驶车辆在交通车道中安全导航就像对于人类来说眼睛被蒙住的情况下行走一样艰难。车道检测尤其在场景理解的领域中是一个至关重要且具有挑战性的任务。车道是道路上最常见的交通要素,是分割道路以确保车辆安全高效通过的关键标志。自动识别道路标线的车道检测技术是不可或缺的;缺乏此功能的自动驾驶车辆可能导致交通拥堵甚至严重碰撞,从而危及乘客安全。因此,车道检测在自动驾驶生态系统中起着至关重要的作用。与典型的物体不同,车道标线仅占道路场景的一小部分,并且分布广泛,这使得它们在检测方面具有独特的挑战性。此任务由于多种车道标线、光照不足、障碍物以及来自相似纹理的干扰而变得更加复杂,这些在许多驾驶场景中都很常见,因此加剧了车道检测所固有的挑战。
基于单目视觉的车道检测方法主要可以分为传统手动特征方法和基于深度学习的方法。早期的努力主要集中在提取低级手动特征,如边缘和颜色信息。然而,这些方法通常涉及复杂的特征提取和后处理设计,并且在动态变化的场景中表现出有限的鲁棒性。基于手动特征提取的传统车道检测算法首先通过识别车道线的颜色、纹理、边缘、方向和形状等特征,构建近似直线或高阶曲线的检测模型。然而,由于缺乏明显特征并且对动态环境的适应性差,基于手动特征的传统方法通常不够可靠且计算开销较大。
随着深度学习的迅速发展,在计算机视觉领域的图像分类、目标检测和语义分割方面取得了重大进展,为车道检测的研究带来了创新的视角。深度学习中根植于深度学习的深度神经网络(DNNs)在从图像数据中提取特征方面具有深刻的能力,其中卷积神经网络(CNNs)是应用最广泛的。CNNs代表了DNNs的一种特殊类别,其特点是多个卷积层和基础层,使其特别适用于处理结构化数据,如视觉图像,并为各种后续任务提供高效的特征提取。在车道检测的上下文中,这意味着利用深度CNNs实时提取高级特征,然后由模型处理以准确确定车道线的位置。
背景和相关工作
由于深度学习技术的进步,研究人员开发了许多策略,大大简化、加快和增强了车道检测的任务。与此同时,随着深度学习的普及和新概念的不断涌现,车道检测领域的方法也得到了进一步的专业化和完善。在这个领域的主流研究轨迹上反思,基于相机的车道检测方法可以主要分为二维(2D)和三维(3D)车道检测范式。
2D车道检测方法 旨在准确地描绘图像中的车道形状和位置,主要采用四种不同的方法:基于分割、基于anchor、基于关键点和基于曲线的策略。
-
基于分割的方法将2D车道检测看作像素级分类挑战,生成车道mask。
-
基于anchor的方法以其简单和高效而受到赞誉,通常利用线性anchor来回归相对于目标的位置偏移。
-
基于关键点的方法提供了对车道位置更灵活和稀疏的建模,首先估计点位置,然后使用不同的方案关联属于同一车道的关键点。
-
基于曲线的方法通过各种曲线方程和特定参数来拟合车道线,通过检测起始点和结束点以及曲线参数,将2D车道检测转化为曲线参数回归挑战。
尽管2D车道检测取得了一些进展,但在2D结果与实际应用要求之间仍存在显著差距,尤其是对于精确的三维定位。
3D车道检测。 由于2D车道检测中固有的深度信息缺乏,将这些检测投影到3D空间可能会导致不准确和降低鲁棒性。因此,许多研究人员已经将他们的关注点转向了3D领域内的车道检测。基于深度学习的3D车道检测方法主要分为基于CNN和基于Transformer的方法,最初构建稠密的鸟瞰特征图,然后从这些中间表示中提取3D车道信息。
基于CNN的方法主要包括D-LaneNet,它提出了一种双路径架构,利用逆透视映射(IPM)将特征转置,并通过垂直anchor回归检测车道。3D-LaneNet+将BEV特征分割为不重叠的单元,通过相对于单元中心的横向偏移、角度和高度变化来解决anchor方向的限制。GenLaneNet首创使用虚构的俯视坐标系来更好地对齐特征,并引入了一个两阶段框架来解耦车道分割和几何编码。BEVLaneDet通过虚拟相机来确保空间一致性,并通过基于关键点的3D车道表示适应更复杂的场景。GroupLane在BEV中引入了基于行的分类方法,适应任何方向的车道,并与实例组内的特征信息进行交互。
基于Transformer的方法包括CLGo,提出了一个两阶段框架,能够从图像中估计摄像机姿态,并基于BEV特征进行车道解码。PersFormer使用离线相机姿态构建稠密的BEV查询,将2D和3D车道检测统一到基于Transformer的框架下。STLanes3D使用融合的BEV特征预测3D车道,并引入了3DLane-IOU损失来耦合横向和高度误差。Anchor3DLane是一种基于CNN的方法,直接从图像特征中基于3D anchor回归3D车道,大大减少了计算开销。CurveFormer利用稀疏查询表示和Transformer内的交叉注意机制,有效地回归3D车道的多项式系数。LATR在CurveFormer的查询anchor建模基础上构建了车道感知查询生成器和动态3D地面位置嵌入。CurveFormer++提出了一种单阶段Transformer检测方法,不需要图像特征视图转换,并直接从透视图像特征推断3D车道检测结果。
挑战与动机
准确估计车道标线的三维位置需要具有鲁棒的深度感知能力,特别是在光照和天气条件多变的复杂城市环境中。此外,由于各种因素如不同的道路类型、标线和环境条件,现实世界中用于三维车道检测的数据表现出很高的变异性,使得在不同场景中训练具有良好泛化能力的模型变得艰难。处理用于车道检测的三维数据需要大量的计算资源;这在低延迟至关重要的实时应用中尤为关键。此外,车道标线可能会被各种环境因素如遮挡、阴影、雨雪等遮挡或破坏,给在恶劣条件下可靠检测带来挑战。此外,将三维车道检测集成到综合感知系统中,同时使用其他传感器如相机、激光雷达和雷达,并处理它们的联合输出,也面临着集成挑战。不幸的是,社区缺乏一个统一的、单一的参考点,以确定基于相机的三维车道检测技术在自动驾驶中的当前成熟水平。
考虑到上述挑战和基于视觉传感器的语义分割在准确场景理解和解析中的重要性,在本调查中积累了现有的研究成果和成果。本调查中突出显示的主要研究问题如下:
-
现有数据集在复杂视觉场景中具备进行3D车道检测的潜力吗?
-
当前方法的模型大小和推断速度如何,这些方法能够满足自动驾驶车辆的实时要求吗?
-
当前方法是否能够有效地在包含雾和雨等不确定性的复杂视觉场景中进行三维车道检测?
贡献
本调查向前迈出了一步,对近年来三维车道检测技术的最新状态进行了批判性审查,并为社区做出了以下主要贡献:
-
1)全面介绍了3D车道检测技术,定义了通用流程并逐步解释了每个步骤。这有助于该领域的新人们迅速掌握先前的知识和研究成果,特别是在自动驾驶的背景下。据我们所知,这是第一份关于基于相机的3D车道检测的调查。
-
2)讨论和批判性分析了近年来在三维车道检测领域受到重视的最相关的论文和数据集。
-
3)对当前最先进的方法进行性能研究,考虑它们的计算资源需求以及开发这些方法的平台。
-
4)基于分析的文献,推导出未来研究的指导方针,确定该领域的开放问题和挑战,以及可以有效探索的研究机会,以解决这些问题。
综述方法论
本调查中讨论的研究作品是使用不同的关键词检索而来的,例如自动驾驶中的3D车道检测、基于视觉的3D车道检测和基于学习的3D车道检测。大多数检索到的论文与研究主题直接相关,但也有一些例外,例如多模态方法和基于点云的方法,与本调查的主题关系较小。此外,上述关键词在多个库中进行了搜索,包括Web of Science和Google Scholar,以确保检索到相关内容。包含标准确保了一篇论文被自动驾驶专家所认可,基于诸如引用次数或先前工作的影响等因素。值得一提的是,在查阅文献时,并没有找到基于传统方法的单目3D车道检测工作。这可能是因为,与单目相机的二维车道检测不同,后者仅需要在二维图像中识别属于车道的像素,单目3D车道检测需要使用二维图像确定车道在三维空间中的三维位置信息。如果没有像LiDAR这样的距离测量传感器的帮助,或者没有通过深度学习进行预测,这是很难实现的。
自动驾驶中的单目3D车道检测
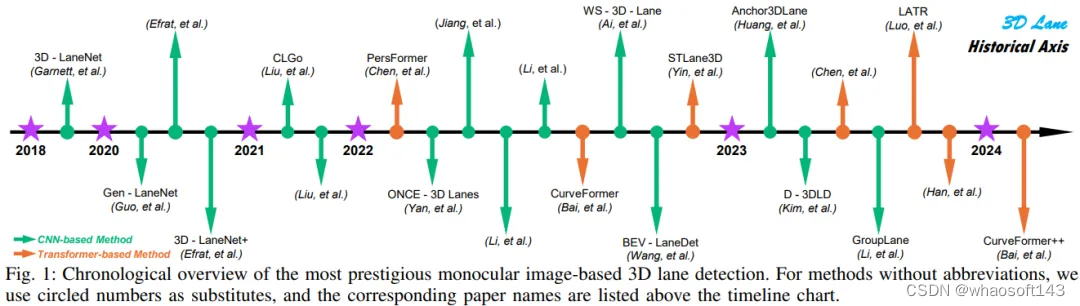
随着深度学习和自动驾驶技术的快速发展,基于深度学习的单目车道检测引起了工业界和学术界的越来越多的关注。在单目车道检测领域,早期工作主要集中在二维车道检测上。随着自动驾驶技术的成熟,对车道检测提出了更高的要求,即从单张图像中预测车道线的三维信息。因此,从2018年开始,陆续出现了关于单目3D车道检测的工作。如图1所示,该图提供了单目3D车道检测算法的时间线概述。可以看到,随着时间的推移,越来越多的研究工作涌现出来,表明这一领域越来越受到关注。在该图中,绿色箭头代表基于CNN的方法,橙色箭头代表基于Transformer的方法。
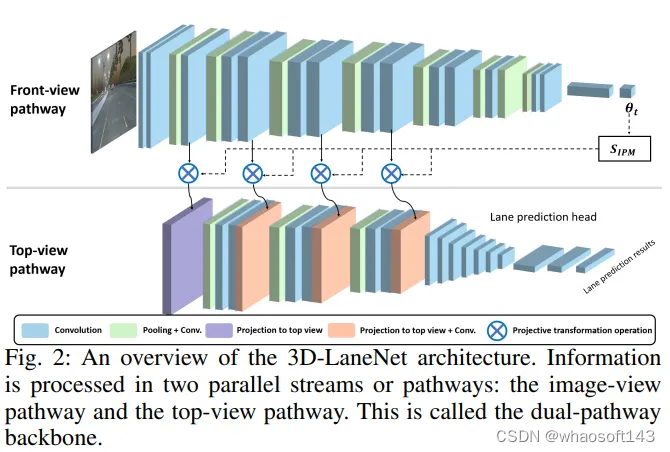
在这些方法中,3D-LaneNet是单目3D车道检测领域的开创性工作。3D-LaneNet引入了一个网络,可以从单目图像中直接预测道路场景中的三维车道信息。该工作首次使用车载单目视觉传感器解决了三维车道检测任务。3D-LaneNet引入了两个新概念:网络内部特征图逆透视映射(IPM)和基于anchor的车道表示。网络内部IPM投影在前视图和鸟瞰图中促进了双重表示信息流。基于anchor的车道输出表示支持端到端的训练方法,这与将检测三维车道线的问题等同于目标检测问题的常见启发式方法不同。3D-LaneNet的概述如图2所示。
受到FCOS和CenterNet等工作的启发,3D LaneNet+是一种无anchor的三维车道检测算法,可以检测任意拓扑结构的三维车道线。3D LaneNet+的作者遵循了3D LaneNet的双流网络,分别处理图像视图和鸟瞰图,并将其扩展到支持检测具有更多拓扑结构的三维车道线。3D LaneNet+不是将整个车道预测为整体,而是检测位于单元内的小车道段及其属性(位置、方向、高度)。此外,该方法学习了每个单元的全局嵌入,将小车道段聚类为完整的三维车道信息。姜等设计了一个两阶段的三维车道检测网络,其中每个阶段分别训练。第一个子网络专注于车道图像分割,而第二个子网络专注于根据第一个子网络的分割输出预测三维车道结构。在每个阶段分别引入了高效通道注意(ECA)注意机制和卷积块注意模块(CBAM)注意机制,分别提高了分割性能和三维车道检测的准确性。
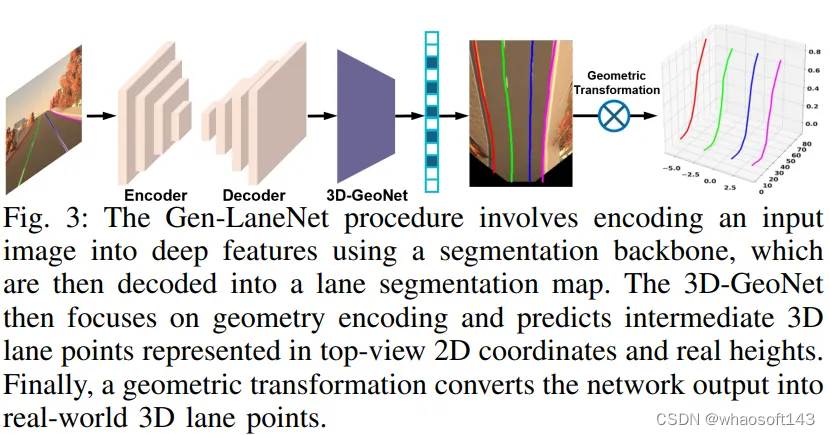
郭等提出了GenLaneNet,这是一种通用且可扩展的三维车道检测方法,用于从单张图像中检测三维车道线,如图3所示。作者引入了一种新颖的几何引导车道anchor表示,并对网络输出直接进行了特定的几何变换,以计算真实的三维车道点。该anchor设计是对3D-LaneNet中anchor设计的直观扩展。该方法将anchor坐标与底层鸟瞰图特征对齐,使其更能处理不熟悉的场景。此外,该论文提出了一个可扩展的两阶段框架,允许独立学习图像分割子网络和几何编码子网络,从而显著减少了训练所需的三维标签数量。此外,该论文还介绍了一个高度真实的合成图像数据集,其中包含丰富的视觉变化,用于开发和评估三维车道检测方法。
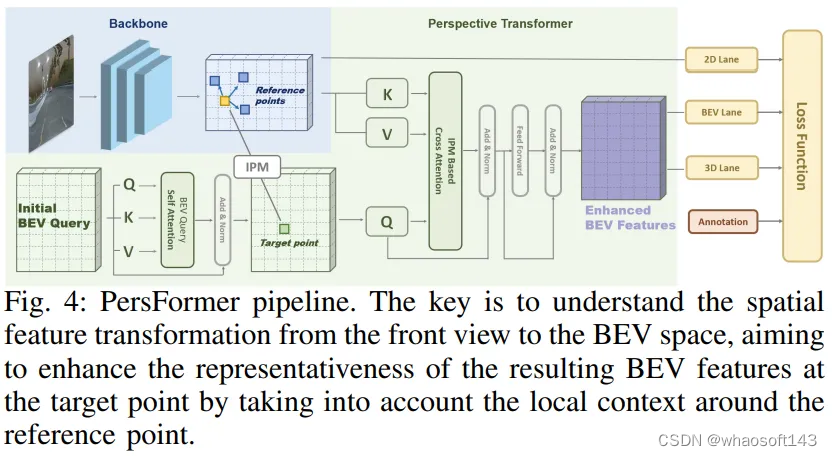
刘等人提出了CLGo,这是一个用于从单张图像预测三维车道和相机姿态的两阶段框架。第一阶段专注于相机姿态估计,并引入了辅助的三维车道任务和几何约束进行多任务学习。第二阶段针对三维车道任务,并使用先前估计的姿态生成鸟瞰图像,以准确预测三维车道。PersFormer引入了第一个基于Transformer的三维车道检测方法,并提出了一种称为Perspective Transformer的新型架构,如图4所示。这种基于Transformer的架构能够进行空间特征转换,从而实现对三维车道线的准确检测。此外,该提出的框架具有同时处理2D和3D车道检测任务的独特能力,提供了一个统一的解决方案。此外,该论文还提出了OpenLane,这是一个基于具有影响力的Waymo Open数据集建立的大规模三维车道检测数据集。OpenLane是第一个提供高质量标注和多样化实际场景的数据集,为推动该领域的研究提供了宝贵资源。
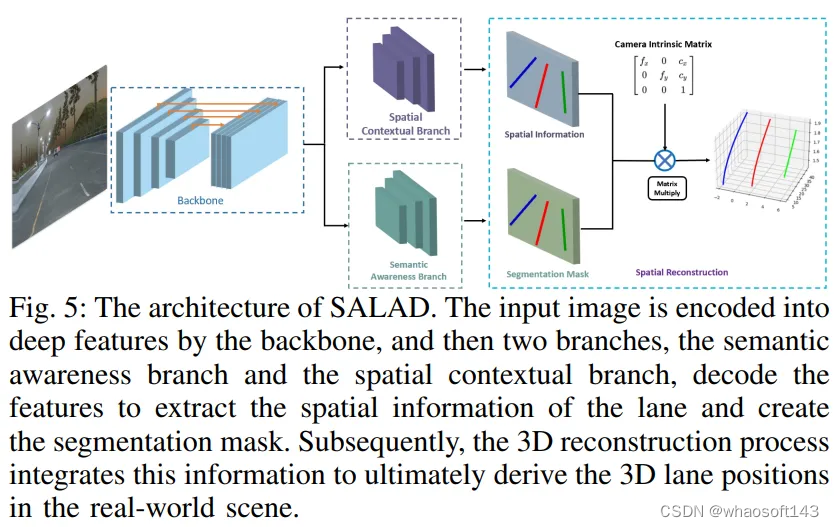
在[108]中,研究人员介绍了最大的真实世界三维车道检测数据集,ONCE-3DLanes数据集,并提供了更全面的评估指标,以重新激发人们对这一任务在真实场景中的兴趣。此外,该论文提出了一种名为SALAD的方法,该方法可以直接从前视图图像生成三维车道布局,无需将特征映射转换为鸟瞰图(BEV),SALAD的网络架构如图5所示。
文章[45]提出了一种新颖的损失函数,利用了三维空间车道的几何结构先验,实现了从局部到全局的稳定重建,并提供了明确的监督。它引入了一个2D车道特征提取模块,利用了来自顶视图的直接监督,确保车道结构信息的最大保留,特别是在远处区域,整体流程如图7所示。此外,该论文还提出了一种针对三维车道检测的任务特定数据增强方法,以解决地面坡度和摄像机姿态的数据分布不平衡问题,增强了在罕见情况下的泛化性能。

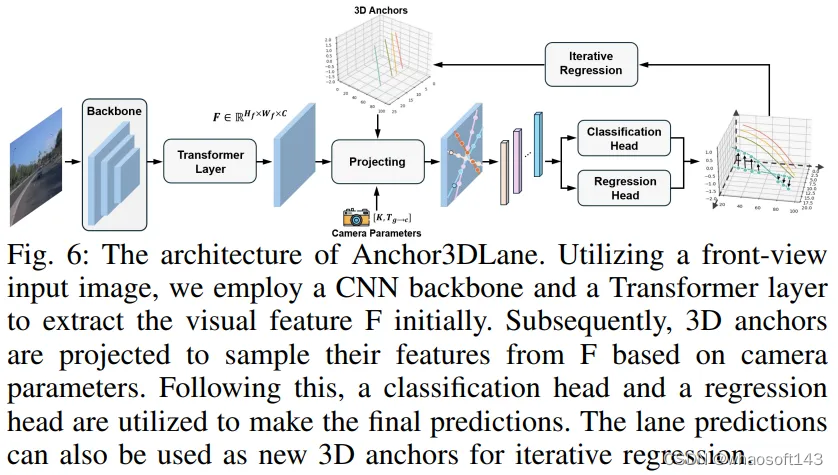
Bai等人提出了CurveFormer,这是一种基于Transformer的三维车道检测算法。在这篇论文中,研究人员将解码器层中的查询形式化为一个动态的anchor集,并利用曲线交叉注意力模块计算查询与图像特征之间的相似度。此外,他们还引入了一个上下文采样单元,通过组合参考特征和查询来预测偏移量,引导采样偏移的学习过程。Ai等人提出了WS-3D-Lane,这是首次提出了一种弱监督的三维车道检测方法,只使用2D车道标签,并在评估中胜过了之前的3D-LaneNet 方法。此外,作者提出了一种摄像机俯仰自校准方法,可以实时在线计算摄像机的俯仰角,从而减少由不平整的路面引起的摄像机和地平面之间的俯仰角变化导致的误差。在BEV-LaneDet 中,作者提出了虚拟摄像机,这是一个新颖的数据预测处理模块,用于统一摄像机的外部参数和数据分布的一致性,作者提出了关键点表示,一种简单而有效的三维车道结构表示。此外,还提出了基于MLP的空间转换金字塔,这是一种轻量级结构,实现了从多角度视觉特征到BEV特征的转换。黄等人提出了Anchor3DLane框架,直接定义了三维空间中的anchor,并且直接从前视图中回归出三维车道,如图6所示。作者还提出了Anchor3DLane的多帧扩展,以利用良好对齐的时间信息并进一步提高性能。此外,还开发了一种全局优化方法,通过利用车道等宽属性对车道进行微调。
Li等人提出了一种方法[45],可以直接从前视图图像中提取顶视图车道信息,减少了2D车道表示中的结构损失。该方法的整体流程如图7所示。作者将3D车道检测视为从2D图像到3D空间的重建问题。他们提出,在训练过程中明确地施加3D车道的几何先验是充分利用车道间和车道内部关系的结构约束,以及从2D车道表示中提取3D车道高度信息的关键。作者分析了3D车道与其2D表示之间的几何关系,并提出了一种基于几何结构先验的辅助损失函数。他们还证明了显式几何监督可以增强对3D车道的噪声消除、异常值拒绝和结构保留。
Bai等人提出了CurveFormer 和CurveFormer++ ,这是基于Transformer的单阶段方法,可以直接计算3D车道的参数,并且可以绕过具有挑战性的视图转换步骤。具体来说,他们使用曲线查询将3D车道检测形式化为曲线传播问题。3D车道查询由动态和有序的anchor集表示。通过在Transformer解码器中使用具有曲线表示的查询,对3D车道检测结果进行迭代细化。此外,他们引入了曲线交叉注意力模块来计算曲线查询与图像特征之间的相似性。此外,提供了一个上下文采样模块,以捕获更相关的曲线查询图像特征,进一步提高了3D车道检测的性能。
与[66]类似,Li等人提出了GroupLane,这是一种基于按行分类的3D车道检测方法。GroupLane的设计由两组卷积头组成,每组对应一个车道预测。这种分组将不同车道之间的信息交互分离开来,降低了优化的难度。在训练过程中,使用单赢一对一匹配(SOM)策略将预测与车道标签匹配,该策略将预测分配给最适合的标签进行损失计算。为了解决单目图像中不可避免的深度模糊所引起的在车道检测过程中构建的替代特征图与原始图像之间的不对齐问题,Luo等人提出了一种新颖的LATR模型 。这是一个端到端的3D车道检测器,它使用不需要转换视图表示的3D感知前视图特征。具体来说,LATR通过基于车道感知的查询生成器和动态3D地面位置嵌入构造的查询和键值对之间的交叉注意力来检测3D车道。一方面,每个查询基于2D车道感知特征生成,并采用混合嵌入以增强车道信息。另一方面,3D空间信息作为位置嵌入从一个迭代更新的3D地面平面注入。
为了解决在将图像视图特征转换为鸟瞰图时由于忽略道路高度变化而引起的视图转换不准确的问题,Chen等人提出了一种高效的用于3D车道检测的Transformer 。与传统的Transformer不同,该模型包括一个分解的交叉注意力机制,可以同时学习车道和鸟瞰图表示。这种方法与基于IPM的方法相比,允许更准确的视图转换,并且更高效。以前的研究假设所有车道都在一个平坦的地面上。然而,Kim等人认为,基于这种假设的算法在检测实际驾驶环境中的各种车道时存在困难,并提出了一种新的算法,D-3DLD。与以前的方法不同,此方法通过利用深度感知体素映射将图像域中的丰富上下文特征扩展到3D空间。此外,该方法基于体素化特征确定3D车道。作者设计了一种新的车道表示,结合不确定性,并使用拉普拉斯损失预测了3D车道点的置信区间。
Li等人提出了一种轻量级方法 [46],该方法使用MobileNet作为骨干网络,以减少对计算资源的需求。所提出的方法包括以下三个阶段。首先,使用MobileNet模型从单个RGB图像生成多尺度的前视图特征。然后,透视transformer从前视图特征计算鸟瞰图(BEV)特征。最后,使用两个卷积神经网络预测2D和3D坐标及其各自的车道类型。在论文[26]中,Han等人认为,基于曲线的车道表示可能不适用于现实场景中许多不规则车道线,这可能会导致与间接表示(例如基于分割或基于点的方法)相比的性能差距。文中作者提出了一种新的车道检测方法,该方法可以分解为两部分:曲线建模和地面高度回归。具体来说,使用参数化曲线来表示鸟瞰图空间中的车道,以反映车道的原始分布。对于第二部分,由于地面高度由路况等自然因素决定,因此地面高度与曲线建模分开回归。此外,作者设计了一个新的框架和一系列损失函数,以统一2D和3D车道检测任务,引导具有或不具有3D车道标签的模型的优化。
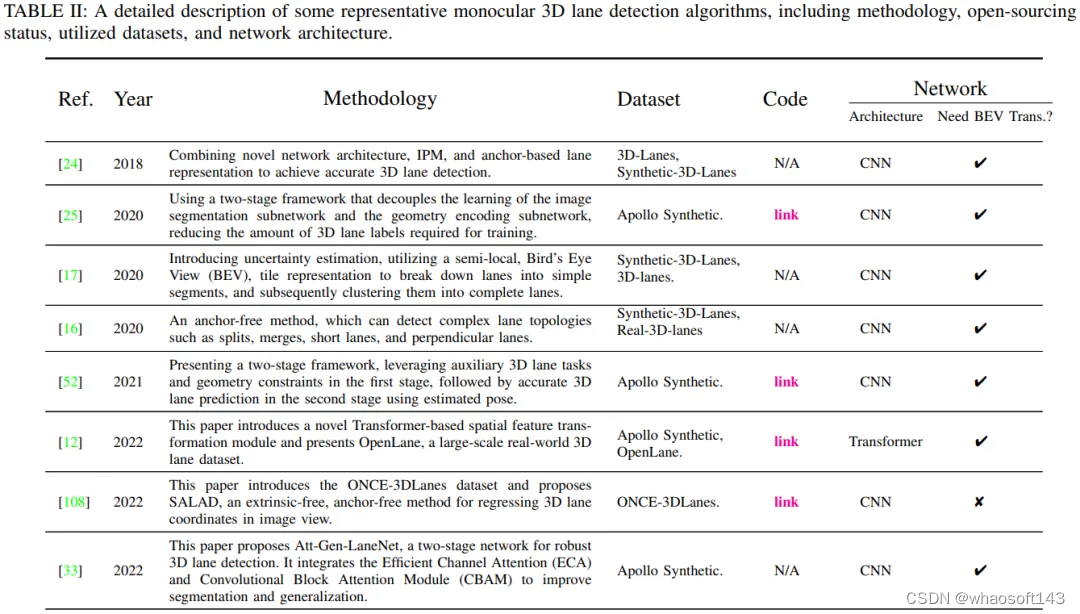
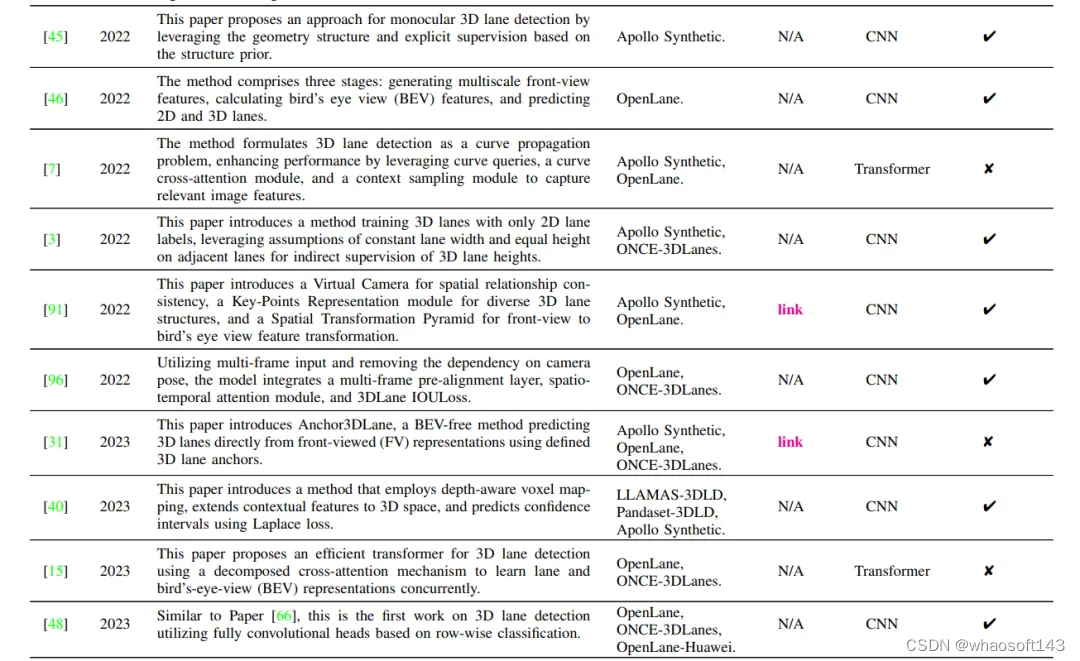
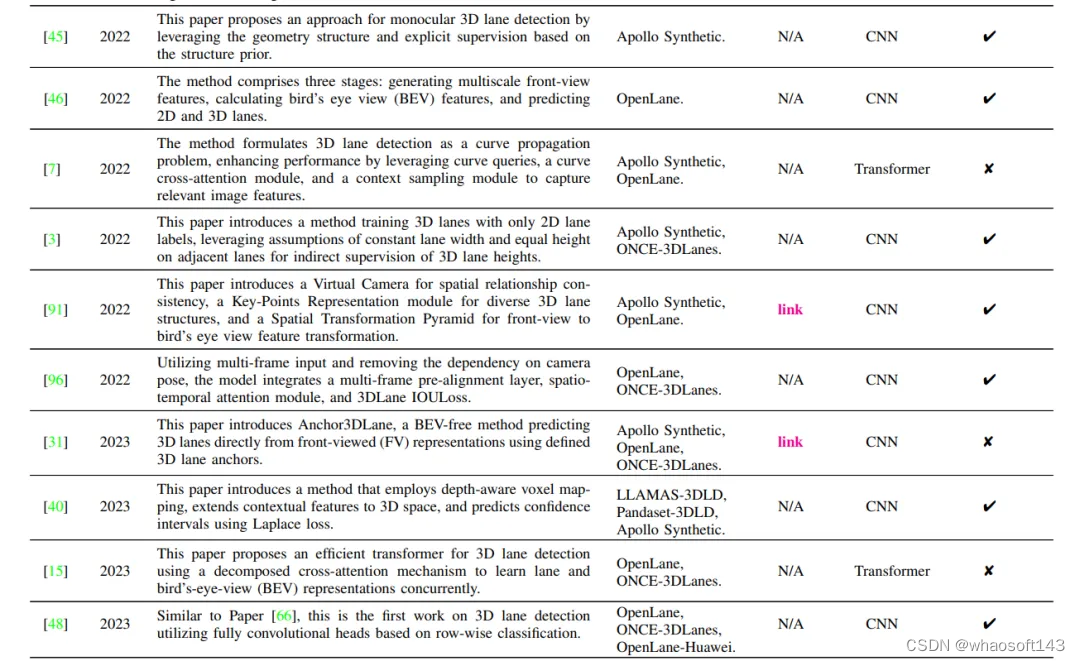
这些方法的直观总结如表II所示,包括方法描述、使用的数据集、开源状态以及网络架构。

3D车道检测性能评估
本节将讨论单目3D车道检测模型的性能评估。在此,我们解释评估指标、不同类型的目标函数、分析计算复杂度,并最终提供各种模型的定量比较。所使用变量的命名方式见表I。首先,呈现了3D车道线检测的可视化结果。由于一些算法未公开源代码,我们只在ApolloSim数据集上对一些开源算法进行了可视化测试。这些算法已在ApolloSim数据集上进行了训练,可视化结果如图8所示,其中红色线表示预测的车道线,蓝色线表示真值车道线。接下来,将介绍评估指标、用于训练算法的损失函数以及在公共数据集上进行的3D车道线检测的定量测试结果。



3D车道检测的评估指标
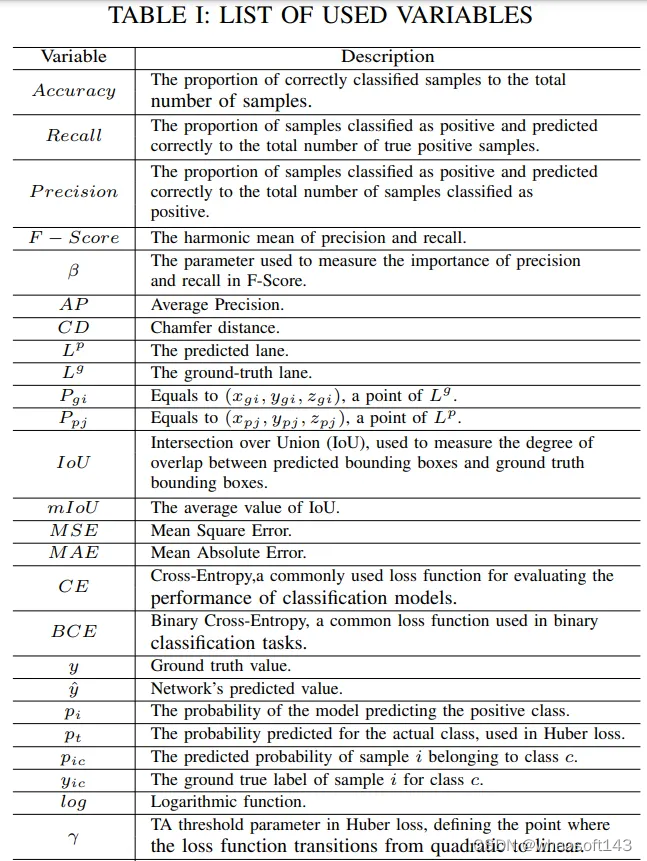
仅建立预测的单目3D车道检测模型并不明智也不可信,除非在未见数据上进行测试。大多数模型在用于训练的相同数据集的不相交集上评估其性能,即测试数据对训练模型来说是新的。用于单目3D车道检测任务的深度学习模型使用一些通用指标来评估基于真实值的最佳结果。对于单目3D车道检测任务,有不同类型的评估指标可供选择,将在接下来的内容中进行回顾:


3D车道检测的损失函数
在单目3D车道检测任务中,常见的基本损失函数包括以下几种:
MSE损失:这是最常用的损失函数之一,它计算模型预测值与真实值之间的平方差,然后取平均值。其数学表达式为:

二元交叉熵损失:二元交叉熵损失常用于训练二元分类任务,旨在最小化损失函数以提高模型对二元分类样本的预测准确性。它广泛应用于深度学习任务,如图像分类、文本分类和分割。其数学表达式为:

不同的方法使用特定的损失函数的方式各不相同,但基本上大多数都是基于上述基本损失函数的变体或组合。此外,通常使用匈牙利算法来将预测车道与真值车道匹配。
单目3D车道检测模型的定量分析
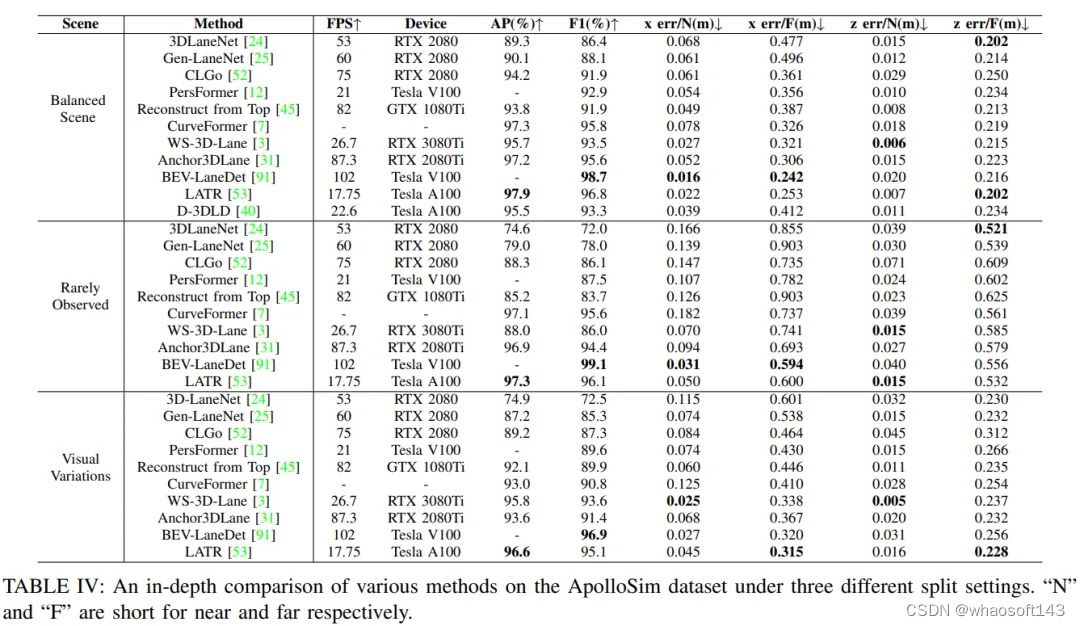
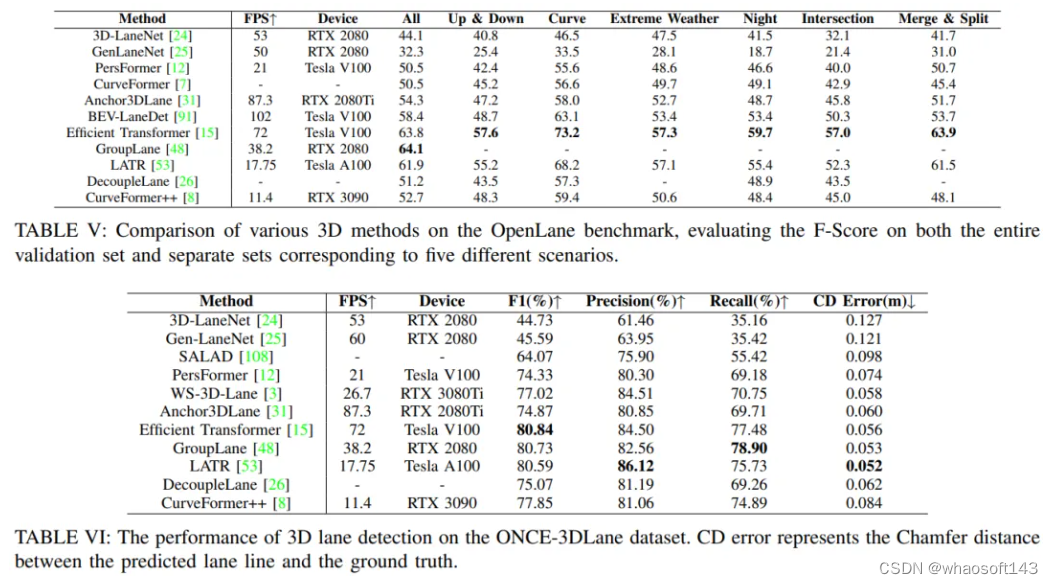
本节详细阐述了本文调查的单目3D车道检测方法的定量实证分析,这有助于实现自动驾驶。对于定量评估,利用四个评估指标来检查每种单目3D车道检测方法在ApolloSim数据集上的性能:AP、F-Score、x误差和z误差,并在表IV中报告结果。在Openlane数据集上,评估了每个模型的F-Score,如表V所示。在ONCE3DLane数据集上,我们评估了四个指标,即:F-Score、Precision、Recall和CD误差,结果报告在表VI中。此外,还考虑了计算效率,通过报告每种方法在推理过程中可达到的每秒帧数(FPS)。这些模型的总运行时间在表IV、V和VI中报告。在一些论文中,报告了算法的推理时间及其相应的硬件平台,直接使用。然而,在其他一些论文中,未显示算法的推理时间,因此我们在我们的实验平台上进行了自己的实验来测试推理时间。我们的实验平台的CPU配置包括运行Ubuntu 20.04操作系统的Intel(R) Core i9-12900K CPU处理器,而实验中使用的GPU是一块具有12GB显存的NVIDIA GeForce RTX 3080Ti GPU。在上述表格中,我们指定了每种方法推理所使用的硬件。
数据集
在基于深度学习的视觉任务中,同样重要的组成部分是数据集。在本节中,将介绍当前用于单目3D车道线检测任务的数据集。其中一些数据集是开放源代码且受到社区广泛使用的,而另一些仅在论文中描述,未公开。无论是开源还是专有数据集,为了更直观地了解这些数据集,我们编制了一张详细的表格,展示了所有现有的单目3D车道线检测数据集,如表III所示。
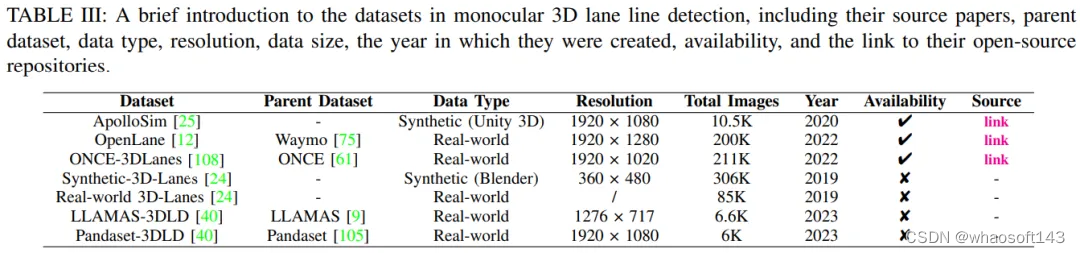
Apollo 3D Lane合成数据集
Apollo 3D Lane合成数据集是一个稳健的合成数据集,包括10,500帧高分辨率的1080 × 1920单目RGB图像,使用Unity 3D引擎构建。每个帧都附带相应的3D车道标签和摄像机俯仰数据。它基于美国硅谷,涵盖了各种环境,包括高速公路、城市区域、住宅区和市区设置。该数据集的图像囊括了广泛的日间和天气条件、各种交通/障碍情况以及不同的道路表面质量,从而使数据集具有高度的多样性和逼真度。数据集分为三种不同的场景类别:平衡场景、罕见观察到的场景和具有视觉变化的场景。
平衡场景用于作为全面和无偏见的数据集,用于基准标准驾驶场景。罕见观察到的场景用于测试算法对于复杂城市地图中罕见遇到的情况的适应能力,其中包括急剧的高程变化和急转弯。具有视觉变化的场景旨在评估算法在不同照明条件下的表现,通过在训练期间排除特定白天时段并在测试期间专注于它们。数据集中摄像机的固定内参参数,摄像机高度范围在1.4到1.8米之间,俯仰角范围从0到10度。
OpenLane
OpenLane是第一个大规模、真实世界的3D车道检测数据集,拥有超过200,000帧和880,000个精心标注的车道。OpenLane建立在具有影响力的Waymo Open数据集的基础上,采用相同的数据格式、评估管道和10Hz的采样率,由64束LiDAR在20秒内进行。该数据集为每个帧提供了详尽的细节,包括摄像机内参和外参,以及车道类别,其中包括14种不同类型,如白色虚线和路边。几乎90%的车道由双黄色实线和单白色实线和虚线组成。OpenLane数据集典型地展示了现实世界的情景,充分凸显了长尾分布问题。OpenLane包含帧中的所有车道,甚至包括相反方向的车道,前提是没有隔离路边。由于复杂的车道拓扑结构,如交叉口和环形交叉口,一个帧可以容纳多达24条车道。约25%的帧中包含超过六条车道,超过了大多数当前车道数据集的最大值。除此之外,该数据集还提供了场景标签的注释,例如天气和位置,以及最接近路径的目标(CIPO)-定义为与自车相关的最相关目标。这些辅助数据对于规划和控制中的后续模块至关重要,而不仅仅是感知。OpenLane的3D地面真值是使用LiDAR合成的,因此具有高精度和准确性。数据集分为包含157,000张图像的训练集和包含39,000张图像的验证集。
ONCE-3DLanes
ONCE-3DLanes数据集是另一个实用的3D车道检测数据集,精心从ONCE自动驾驶存储库中提取而来。该数据集包括由前置相机捕获的211,000个图像,以及相应的匹配LiDAR点云数据。展示了一系列不同时间和天气条件下的场景,如阳光明媚、阴天和雨天等,数据集涵盖了城市中心、住宅区、高速公路、桥梁和隧道等多种地形。这种多样性使数据集成为在各种真实世界场景下开发和验证强大的3D车道检测模型的关键资源。该数据集分为三个部分:用于验证的3,000个场景,用于测试的8,000个场景,以及剩余的5,000个场景用于训练。训练组件还额外补充了200,000个未标注的场景,以充分利用原始数据。虽然数据集提供了的摄像机内参,但省略了摄像机外参。
其他数据集
论文“3D-LaneNet: End-to-End 3D Multiple Lane Detection”介绍了两个不同的数据集:Synthetic3D-Lanes数据集和3D-Lanes数据集。通过开源图形引擎Blender创建的Synthetic3D-Lanes数据集包括300K个训练示例和5K个测试示例,每个示例都包含一个360×480像素的图像以及与之关联的真值参数,如3D车道、摄像机高度和俯仰。这个数据集在车道拓扑、目标位置和场景渲染方面具有重大的多样性,为方法开发和消融研究提供了宝贵的资源。此外,3D-Lanes数据集是一个真实世界的真值标注数据集,通过利用多传感器设置-前向相机、Velodine HDL32激光雷达扫描仪和高精度IMU来编制。该数据集由六个独立的行驶记录组成,每个记录在不同的路段上录制,总计近两个小时的行驶时间。借助激光雷达和IMU数据,生成了聚合的激光雷达俯视图像,并与半手动注释工具一起使用,建立了真值。总共标注了85,000张图像,其中1,000张来自一个单独的驾驶记录,被指定为测试集,其余作为训练集。3D-Lanes数据集在验证所提出的方法对真实世界数据的可转移性以及进行定性分析方面发挥了重要作用。尽管Synthetic-3D-Lanes数据集已经向研究界开放,但真实世界的3D-Lanes数据集仍然是专有的,无法公开获取。值得注意的是,尽管Synthetic-3D-Lanes数据集是可用的,但在后续领域研究中并没有得到广泛采用作为基准进行评估。
自动驾驶中的3D车道检测:挑战与方向
上述介绍的数据集涵盖了各种公开可用的道路场景。当前主流研究主要集中在适合进行三维车道检测的有利白天场景上,这些场景具有充足的照明和有利的天气条件。然而,许多汽车公司和原始设备制造商拥有大量数据,但由于涉及知识产权、产业竞争和《通用数据保护条例》(GDPR)等问题,他们不愿意公开分享这些数据。因此,在自动驾驶研究中,缺乏足够的带标注数据来准确理解动态天气条件,如夜间、雾霾天气和边缘情况,仍然是一个具有挑战性的任务。
这个研究领域是社区尚未充分解决的挑战之一。在本节中,对当前自动驾驶中三维车道检测的现状提出了关键观点,总结了一系列挑战,并提出了研究方向建议,以帮助社区进一步取得进展,有效地克服这些挑战。
开放性挑战
虽然研究人员在自动驾驶领域进行了大量研究,自动驾驶行业也在蓬勃发展,但仍然存在一些需要研究人员关注的开放性挑战,以实现完全智能的自动驾驶。这些挑战已经在相关文献的支持下进行了单独讨论:
粗结构化信息: 大多数文献中介绍的用于自动驾驶中3D车道检测的数据集记录在先进城市的正常和良好结构化基础设施中。当前开发的深度学习模型可能在结构化数据集上取得最佳结果,但它们在许多非结构化环境中的泛化能力较差。自动驾驶中的这个问题需要在数据收集方面进一步关注,同时在深度学习模型中引入新的有效表示机制。
不确定性感知决策: 车道检测和自动驾驶决策中一个被大部分忽视的方面是模型对输入数据进行预测的置信度。然而,模型输出的置信度在确保自动驾驶安全性方面起着至关重要的作用。车辆周围固有的不确定性本质似乎没有说服社区深入研究这个问题,因为目前的方法论趋势仅关注预测分数。幸运的是,置信度估计最近在社区中引起了关注。然而,来自证据深度学习的元素、深度神经网络的贝叶斯公式、近似神经网络输出置信度的简单机制(如蒙特卡洛丢失或集成)以及其他各种不确定性量化方法,应逐步作为决策的一个额外但至关重要的标准进行融合。在处理复杂环境时,由于缺乏能够完全代表所有可能场景的数据,模型会输出大量的认识不确定性。如果不将置信度作为AD的一个附加因素,或者当前研究仅关注预测和/或计算效率方面,那么科学界新兴的3D车道检测模型是否会实际上有用并且可转移至工业领域就无法保证。
弱监督学习策略: 在当前基于深度学习的模型中,大多数依赖于完全监督的学习策略,这对标注数据有很高的要求。在3D车道检测领域,特别具有挑战性,因为一般的视觉传感器数据缺乏深度信息。仅凭图像本身很难将3D信息简单地分配给车道,需要使用LiDAR等替代传感器获取3D车道信息。这导致了标注3D车道数据的成本高昂和劳动密集性。幸运的是,学术界和工业界已经意识到了这个问题,并且在深度学习领域对弱监督学习策略进行了广泛的研究和关注。然而,在3D车道检测的特定分支中,目前针对弱监督学习策略的研究仍然有限。如果我们能够有效地利用自监督/弱监督学习策略,将极大地降低数据收集成本,并允许更多的训练数据来增强3D车道检测算法的性能,从而进一步推动自动驾驶行业的发展。
未来方向
基于视频的自动驾驶3D车道检测: 借鉴基于视频目标检测、语义分割和2D车道检测的进展,可以明显看出,将基于视频的技术纳入其中显著提高了3D车道检测系统的精度和可靠性。基于视频的方法的核心优势在于它们能够利用时间数据,提供静态图像所缺乏的动态视角。这种动态视角在理解和预测三维空间中复杂的驾驶情况中尤其重要,其中车道位置和车辆相互作用的复杂性增加。像递归视频车道检测(RVLD)这样的方法展示了视频捕捉持续车道变化的能力,随时间的推移变化,这一特征对于3D建模的准确性极其有益。此外,将视频数据纳入这些系统还增强了我们对驾驶环境中空间动态的理解,这对于3D车道检测至关重要。通过将基于视频的目标检测和语义分割中使用的复杂深度学习技术纳入3D车道检测系统的未来版本,可以实现先进的空间意识,显著提高自动驾驶车辆的导航能力和安全性。
混合方法和多模态: 多模态3D车道检测技术的进展大大加快了各种传感器输入(如相机、LiDAR和雷达)的整合。这种整合标志着克服现有依赖相机的系统所面临挑战的一个有希望的途径。这种方法,强调了在多模态3D目标检测和语义分割中的成功,利用了每种传感器类型的互补优势,以提高检测精度和可靠性,特别是在具有挑战性的环境和复杂驾驶场景中。回顾了“深度多传感器车道检测”和“M2-3DLaneNet”等开创性模型,这些模型已经有效地利用了多传感器输入来优化车道边界估计,并在遮挡和光照条件变化方面表现出色,明显的发展潜力。这一领域未来的发展轨迹应强调对先进数据融合方法、细致的传感器校准和同步技术的探索,以及利用新兴技术如边缘计算进行实时多模态数据处理。
主动学习和增量学习: 机器学习中的主动学习指的是模型在测试阶段和部署后随时间和遇到新数据而适应和学习的能力。在现实世界的环境中,车辆可能会遇到随机出现的陌生场景和车道拓扑,这可能需要AI模型为进一步的操作做出决策,如刹车或加速以实现合理的驾驶操作。因此,车道检测技术应允许交互式方法来处理各种类型的场景和车道拓扑,涉及人类标注者来标注未标注的数据实例,以及人类参与训练过程。有不同类型的主动学习技术,如成员查询综合,其中生成合成数据,并且根据数据的结构调整合成数据的参数,这源于数据的基础物种。另一方面,3D车道检测模型能够增量地更新其对新数据的捕获知识,对于其可持续性和持续改进至关重要。我们预计,在未来的研究中,3D车道检测模型在道路理解方面的这两个能力将变得越来越重要。
恶劣天气条件: 对于自动驾驶的基于相机的3D车道检测系统的发展受到恶劣天气条件的明显阻碍,这些条件严重影响了能见度。如大雨、雾、雪和沙尘暴等事件会严重影响这些系统的功能。这主要问题源于视觉数据质量的损害,这些数据对于车道标线的精确检测和分割是必要的,导致可靠性下降,假阴性或假阳性的可能性增加。这种系统效能的降低不仅提高了安全隐患,而且限制了自动驾驶车辆的操作范围。然而,最近在目标检测和语义分割方面的突破,如“ACDC:适应不良条件的数据集及其对语义驾驶场景理解的对应关系”和“使用深度学习框架在恶劣天气下的车辆检测和跟踪”,展示了在挑战性天气条件下增强3D车道检测的途径。这些研究提出了利用深度学习算法在包括各种恶劣天气实例的数据集上训练,展示了有效的数据增强、针对特定条件的领域适应和使用语义分割技术的重要性。通过采用这些方法,基于相机的检测系统的能力可以得到大幅提升,以准确解释车道标线,并确保在能见度差的情况下安全导航,为自动驾驶技术领域的持续研究和发展奠定了乐观的路径。
大型语言模型(LLM)在3D车道检测中的应用: 大型语言模型(LLM)的出现,如ChatGPT,已经改变了人工通用智能(AGI)领域,展示了它们在使用定制用户提示或语言指令处理各种自然语言处理(NLP)任务方面remarkable zero-shot能力。计算机视觉涵盖了一系列与NLP中的挑战和概念迥然不同的挑战。视觉基础模型通常遵循预训练和后续微调的过程,虽然有效,但对于适应一系列下游应用而言,这意味着显着的额外成本。技术,如多任务统一化,旨在赋予系统一系列广泛的功能,但它们往往无法突破预先确定的任务的约束,与LLM相比,在开放式任务中留下明显的能力缺口。视觉提示调整的出现提供了一种通过视觉mask来划分特定视觉任务(如目标检测、实例分割和姿态估计)的新方法。然而,目前还没有将LLM与3D车道线检测相结合的工作。随着大型语言模型越来越普遍,其能力继续提升,LLM基于车道线检测的研究为未来的探索提供了有趣和有前途的途径。
实现更准确高效的自动驾驶3D车道检测方法: 当前3D车道检测技术的定性性能如表IV所示。可以观察到只有少数方法能够在模型准确性和推理延迟之间取得平衡。这些方法的实验结果表明,需要进一步改进以减轻计算负担,同时保持其无与伦比的性能。此外,从3D车道检测数据集中选择了一些具有挑战性的数据,并测试了3D车道线检测算法在这些挑战性数据样本上的性能。然而,算法在极端天气条件下的检测性能也不令人满意,如图9所示。改善算法在极端天气条件下的检测性能也是至关重要的。此外,表IV、V和VI中报告的时间复杂性表明,一些方法在部署在GPU设备上时可以实现实时执行。然而,考虑到当今自动驾驶系统中受限的计算资源,3D车道检测方法的重点也应转向计算复杂性。

基于事件相机的3D车道检测: RGB相机受其成像原理的限制,在高速或低光场景下会产生图像质量差的问题。幸运的是,事件相机可以克服这一限制。事件相机是具有高时间分辨率、高动态范围、低延迟和低能耗的视觉传感器。与传统相机根据光的强度和颜色捕获图像不同,事件相机是基于光强度变化捕获图像的。因此,只要光强度发生变化,事件相机就可以在低光场景下捕获图像。目前,关于基于事件相机的3D车道检测的研究还很有限。我们认为,在使用事件相机进行3D车道检测领域存在重大且广泛的研究潜力,包括开发专门用于使用事件相机进行3D车道检测的数据集,以及设计适用于仅使用事件相机或与RGB相机结合进行3D车道检测的算法。
考虑不确定性的3D车道检测: 在过去几年中,深度神经网络(DNNs)在众多计算机视觉任务中取得了显著的成功,巩固了它们作为高效自动感知的不可或缺的工具的地位。尽管在不同的基准测试和任务中始终提供出色的结果,但在广泛实施之前,仍然有一些重要的障碍需要克服。关于DNNs最常见和最著名的批评之一是在面对数据分布水平变化时,它们容易出现性能不稳定的问题,突显了迫切需要解决这一限制的问题。
目前,大多数深度学习模型提供确定性输出,即给出一个结果。然而,在真实世界的驾驶场景中,希望模型能够为其预测提供不确定性估计。下游决策模块可以利用这些不确定性信息做出更合理和更安全的驾驶指令。例如,在3D车道检测的情况下,如果模型输出的车道位置具有较高的不确定性,应该对模型的检测结果持怀疑态度,并采取保守的驾驶风格。相反,如果模型的输出具有较低的不确定性,我们可以对算法的预测感到有信心,并做出更自信的驾驶决策。
结论
视觉传感器是自动驾驶车辆的关键组成部分,在决策过程中起着关键作用。作为近年来增长最快的领域之一,计算机视觉技术被用于分析视觉传感器捕获的数据,以获取诸如交通灯检测、交通标志识别、可驾驶区域检测和三维障碍物感知等有用信息。随着传感器技术、算法能力和计算能力的进步,视觉传感器数据在自动驾驶车辆感知中的应用越来越受到关注。例如,基于单目图像的3D车道检测利用单个相机图像获取三维物理世界中车道线的位置,融合深度信息。了解车道线的深度信息对于自动驾驶车辆的安全和舒适的决策制定和规划至关重要。虽然可以使用其他传感器(如激光雷达)获取三维车道信息,但由于其成本效益和丰富的结构化彩色信息,视觉传感器在自动驾驶领域中发挥着至关重要的作用。
基于单目图像的3D车道检测在自动驾驶领域已经发展了多年。然而,现有文献中缺乏全面的、总结性的分析。本调查回顾了现有的车道检测方法,介绍了现有的3D车道检测数据集,并讨论了现有车道检测方法在公共数据集上的性能比较。还分析了当前3D车道检测面临的挑战和局限性。主要结论是,基于单目图像的3D车道检测领域的研究尚未达到完美,当前的方法存在许多限制,在调查中进行了详细讨论,并提供了相关建议和展望。涵盖了处理深度学习模型的基线工作,它们在3D车道检测任务中的层次结构,以及与每个模型类别相关的挑战。此外,深入探讨了自动驾驶领域中用于3D车道检测模型的性能评估策略、损失函数和广泛使用的数据集。通过提出开放挑战和未来研究方向来总结这项工作,并列举了最近文献中的基线参考。
最后,不可否认的是,智能交通系统社区的专家们不断努力改进3D车道检测策略,以有效利用视觉传感器的数据。主流研究致力于通过神经网络的能力提高模型的准确性,或者探索新颖的神经网络架构。然而,解决其他挑战是实现可靠、值得信赖和安全自动驾驶的必要条件。从3D车道检测的角度来看,这些挑战需要更强大的模型,具备预测车道遮挡、处理粗略结构信息和提供风险警报的能力。此外,当前的3D车道检测模型主要依赖于监督学习,这需要高质量的标注数据。然而,标注3D 车道数据是一项耗时且费力的任务。探索有价值且具有挑战性的方法,如自监督或弱监督学习,以实现3D车道检测是这一领域进一步发展的开放机会。如果能及时充分利用这些机会,将推动智能交通系统的研究,并将3D车道检测提升到一个新的水平。这将使无人驾驶车辆能够更有效地在现实环境中部署,并支持更安全、更可靠和更舒适的出行和物流服务。

















 2176
2176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









