







PixArt-α 的训练速度明显超过了现有的大规模 T2I 模型,比如训练时间仅仅为 Stable Diffusion v1.5 的 12% 左右。大量实验表明,PIXART-α 在图像质量、艺术家和语义控制方面表现不俗。
本文提出的 PixArt-α 是一种基于 Transformer 的文生图 (Text-to-Image, T2I) 大模型,与一些耳熟能详的文生图模型如 Imagen[1], Midjourney 等相比起来也有竞争力。它支持高达 1024 × 1024 分辨率的高分辨率图像合成,且训练成本较低。基于3个核心贡献:
-
训练策略分解:PixArt-α 的训练基于3个不同的训练步骤,分别是优化像素依赖、文本图像对齐和图像美学质量。
-
高效的 T2I Transformer 架构:将 Cross-Attention 合并到 Diffusion Transformer (DiT) 中。
-
高信息量的数据:作者强调文本-图像对中概念密度的重要性,并使用大语言模型自动标记伪字幕来辅助文本图像对齐的训练。
PixArt-α 的训练速度明显超过了现有的大规模 T2I 模型,比如训练时间仅仅为 Stable Diffusion v1.5 的 12% 左右。大量实验表明,PIXART-α 在图像质量、艺术家和语义控制方面表现不俗。
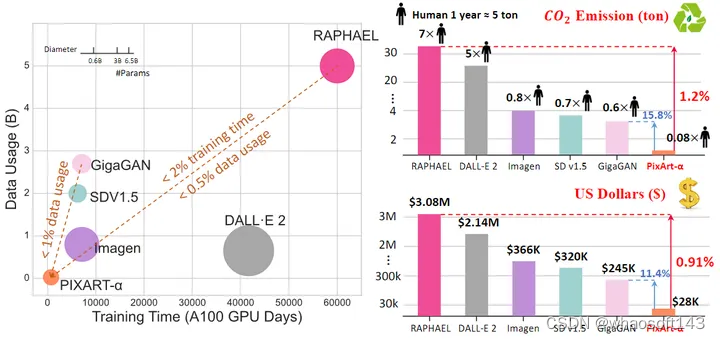
图1:不同文生图模型的 CO2 排放量和训练花销对比。PIXART-α 的训练成本非常低 28,400 美元。与 RAPHAEL 相比,其 CO2 排放和培训成本分别仅为 1.2% 和 0.91%
本文工作
-
将复杂的文本到图像生成任务分解为3个简化的子任务: 1) 学习自然图像的像素值,2) 学习文本图像对齐,以及 3) 提高图像的美学质量。对于第1个子任务,作者使用低成本的类条件模型初始化 T2I 模型,显着降低了学习成本。对于第2和第3子任务,作者制定了一个由预训练和微调组成的训练范式:对富含信息密度的文本图像对数据进行预训练,然后对具有卓越美学质量的数据进行微调,提高了训练效率。
-
提出高效的文生图 Transformer 架构: 基于 DiT[2],作者使用 Cross-Attention 模块注入文本条件,简化 class-condition 分支的计算。此外,还提出一种重参数化技术,允许 T2I 模型直接加载 class-condition 模型的参数,以提高计算效率。这样的好处是可以利用从 ImageNet[3]中学到的关于自然图像分布的先验知识来为 T2I Transformer 提供合理的初始化并加速其训练。
-
高信息量的数据: 本文的研究揭示了现有文本图像对数据集的显着缺点,例如 LAION[4]。其文本字幕往往缺乏信息性内容 (通常仅描述图像中的部分对象) 和严重的长尾效应 (具有大量出现在极低频率的名词)。这些缺陷极大地阻碍了 T2I 模型的训练效率,导致需要大量的训练才能实现稳定的文图对齐。为了解决这个问题,作者提出了一种自动标记 pipeline,利用最先进的视觉语言模型 (LLaVA[5]) 来生成 SAM[6]上的字幕。SAM 数据集因其丰富多样的对象集合而具有优势,更适合文本图像对齐学习。
1 PixArt-α:文生图扩散 Transformer 架构的快速训练
论文名称:PIXART-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis (ICLR 2024 Spotlight)
论文地址:http://arxiv.org/pdf/2310.00426
项目主页:http://pixart-alpha.github.io/
1.1 节约文生图模型的训练成本很重要
文生图 (Text-to-Image, T2I) 模型的进步,比如 DALL·E 2[7]、Imagen[1]和 Stable Diffusion[8]已经开启了照片级真实感的图像生成新时代,深度影响着许多下游的应用。但是这些先进模型的训练需要大量的计算资源。比如 SDv1.5[9]需要 6K A100 GPU days,大约花费 $320,000。而且,训练也会带来大量的 CO2 排放,带来环境压力。RAPHAEL[10]的训练导致35吨的二氧化碳排放,相当于一个人类7年的排放量。这样巨大的成本对 AIGC 社区的关键进步造成了重大的障碍。因此,能否开发一个具有负担得起资源消耗的高质量图像生成器?
1.2 文生图模型的问题
文生图 (Text-to-Image, T2I) 模型训练较慢的原因主要有两点:训练流程和数据。
1) 训练流程方面
T2I 的生成任务可以分解为3个方面:
捕获像素依赖: 生成真实图像涉及理解图像中复杂的像素级依赖关系并捕获它们的分布。
文本和图像之间的对齐: 需要精确的对齐学习来理解如何生成与文本描述完全匹配的图像。
高美学质量: 除了忠实的文本描述外,美观是生成图像的另一个重要性质。
目前的方法将这3个问题纠缠在一起,直接使用大量数据从头开始训练,导致训练效率低下。本文将训练分成3个阶段:
2) 数据方面
当前数据集的字幕质量也是一个问题。当前数据集中的图文对经常受到文本图像错位、描述不足、词汇使用不常见以及包含低质量数据的影响。这些问题给训练引入了困难,导致需要数百万次迭代来实现文本和图像之间的稳定对齐。为了应对这个问题,本文引入一种自动标记管道来生成精确的图像描述。

图2:LAION 原始字幕 vs LLaVA 细化字幕。LLaVA 能够提供高信息密度字幕,帮助模型在每次迭代中抓取更多的概念并提高文本图像对齐效率
1.3 训练策略分解
作者把 PixArt-α 的训练过程划分为3个阶段:
Stage1:像素依赖学习。 当前如 DiT 等的一些 class guided 方法可以生成语义连贯的单图像。训练一个像这样的 class-conditional 的图像生成模型相对容易。作者发现合适的初始化可以显著提高训练效率。因此,作者从 ImageNet 预训练模型中初始化 PixArt-α,且 PixArt-α 的架构被设计为与 ImageNet 预训练预训练的权重兼容。
Stage2:文本图像对齐学习。 从预训练的 class-guided 图像生成模型过渡到 text-to-image 图像生成模型的主要挑战是如何在文本和图像之间实现精准对齐。
这个对齐过程不仅耗时,而且本质上具有挑战性。为此,本文创建了一个高概念密度的由精确的图文对组成的数据集。通过使用准确以及信息丰富的数据,本文的训练过程可以在每次迭代过程中处理更多的名词,同时与之前的数据集相比歧义更少。
Stage3:高分辨率的美学图像生成。 作者使用高质量的美学数据来微调模型,以生成高分辨率的图像。值得注意的是,作者观察到这一阶段的适应过程收敛速度明显更快,这主要是由于前一阶段建立的强先验知识。
将训练过程解耦为3个不同的阶段可以显著缓解训练困难的问题,实现高效训练。
1.4 高效 T2I Transformer 架构
PixArt-α 的文生图架构基于 DiT[2]。但是 DiT 架构不能直接做文生图任务,因此 PixArt-α 做了一些针对性改进。
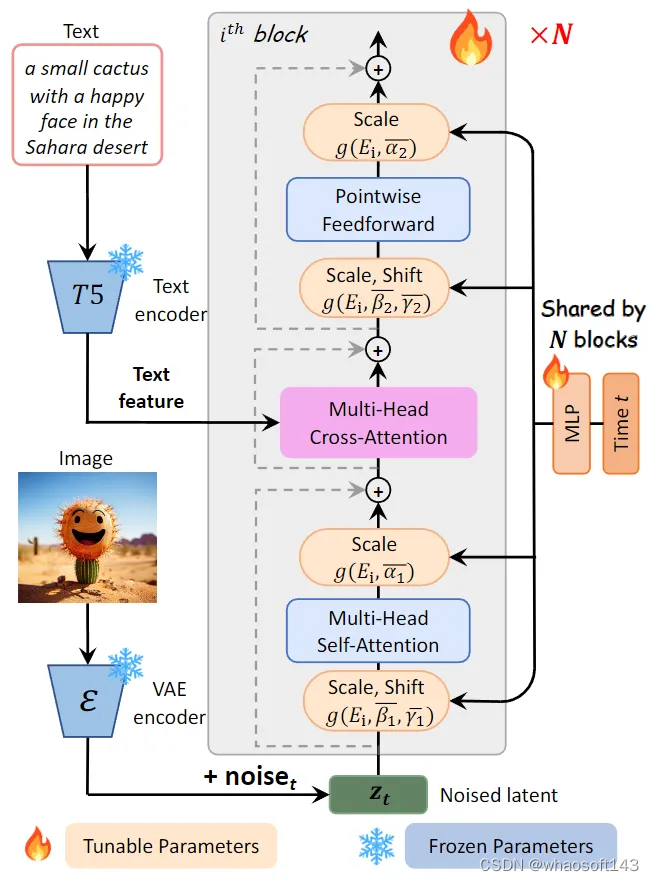
图3:PIXART-α 的模型架构。将 Cross-Attention 模块集成到每个 Block 中以注入文本的嵌入表征。为了优化效率,所有的 Block 共享相同的 adaLN-single 参数
-
Cross-Attention 模块: 作者在 DiT Block 中融合了一个 Cross-Attention 模块,如上图3所示。它位于 Self-Attention 层和 Feed-Forward 层之间,以便于模型可以灵活地与语言模型的文本 Embedding 交互。为了便于权重预训练,作者将 Cross-Attention 模块的输出投影层的权重初始化为0,目的是使其在训练的初期充当恒等映射。
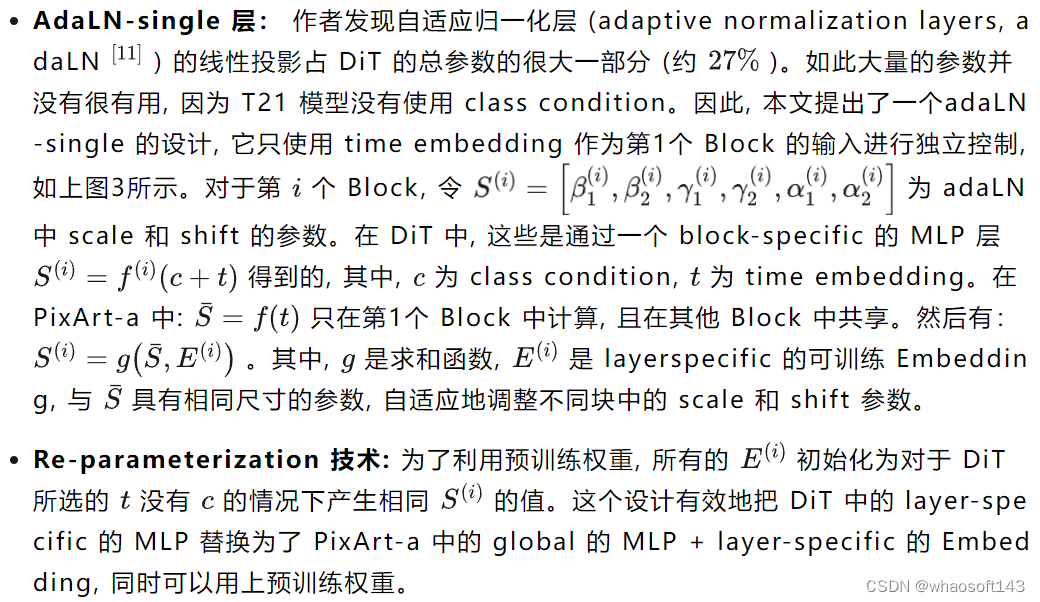
后续的实验结果也表明,使用 global 的 MLP + layer-specific 的 Embedding 来应对时间信息,再加上用于引入文本信息的 Cross-Attention 模块,可以在保留模型生成能力的同时有效减小体积。
1.5 数据集构造
LAION 数据集的字幕有各种各样的问题,比如文本图像错位、描述不足和一些不常见词汇等等,如上图2所示。为了生成具有高信息密度的字幕,本文利用最先进的视觉语言模型 LLaVA[5]以及如下 prompt,"Describe this image and its style in a very detailed manner",显著地提高了字幕的质量。
除此之外,本文作者使用 SAM[6]数据集,通过将 LLaVA 应用于 SAM,作者成功地获得了具有高概念密度的特征的高质量文本图像对。
在第3阶段,作者通过结合 JourneyDB[12]和 10M 内部数据集来构建我们的训练数据集,以增强生成图像的美学质量超出真实照片。
最后,作者在下图4中进行了词汇分析 Natural Language Toolkit。将在数据集中出现超过 10 次的名词定义为 valid distinct nouns。LAION 数据集有 2.46M 个不同的名词,但只有 8.5% 是有效的。这个有效的名词比例在 LLaVA 标记的字幕中从 8.5% 增加到 13.3%。尽管 LAION 的原始字幕包含 210K 个不同的名词,但其总名次数从 6.4 增加到了 21,表明原始 LAION 字幕不完整。此外,SAM-LLaVA 优于 LAION-LLaVA,总名次数为 328M,每张图片 30 个名词,表明 SAM 包含更丰富的目标,每个图像有更强的信息密度。最后,内部数据还确保足够的有效名次和平均信息密度进行微调。LLaVA 标记的字幕显著提高了平均名词数,提高了概念的密度。
1.6 PixArt-α 的训练细节
作者遵循 Imagen[13]和 DeepFloyd[14]使用 T5 大语言模型 (4.3B 的 Flan-T5-XXL) 作为文本编码器,并使用 DiT-XL/2 作为基础网络架构。text token 的长度调整到 120。为了捕捉输入图像的潜在特征,作者使用了来自 LDM[15]的预训练和冻结的 VAE。在将图像输入 VAE 之前,作者调整和居中裁剪它们具有相同的大小。作者还使用了 SDXL[9]中引入的多方面增强来实现任意方面图像生成。使用 AdamW 优化器,学习率 2e-5,weight decay 0.03,最终模型在 64 V100 上训练了大约 26 天。
评测指标
MSCOCO[16]数据集上面计算 FID[17],T2I-CompBench[18]。
1.7 性能对比
保真度评估: 本文方法与其他方法在 FID 及训练时间的比较如图4所示。在 COCO 数据集上做 Zero-Shot 测试,本文的 PixArt-α 模型的 FID 得分为 7.32。与通常使用大量资源训练的最先进方法相比,PIXART-α 显着消耗了大约 2% 的训练资源,同时实现了可比的 FID 性能。尽管表现最好的模型 (RAPHEAL) 表现出较低的 FID,但它依赖于负担不起的资源 (即训练样本增加 200 倍、训练时间长 80 倍,网络参数比 PIXART-α 高 5 倍)。作者认为 FID 可能不是图像质量评估的合适指标,使用人类用户评估更合适。
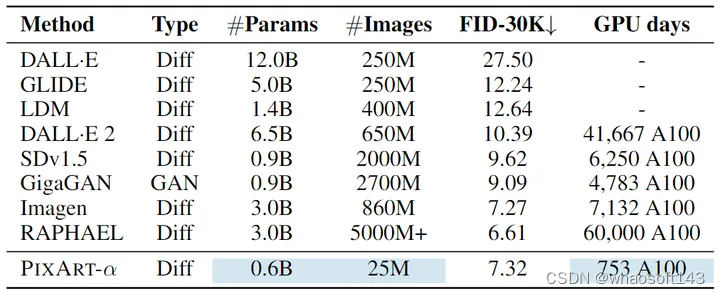
图4:PIXART-α 和最近的 T2I 模型在参数规模,训练图片数量,COCO FID-30K 和所需训练时间的对比
对齐评估: 除了上述评估之外,作者还使用 T2I-Compbench 评估生成的图像和文本条件之间的对齐,这是评估组合文本到图像生成能力的综合基准。如图5所示,作者评估了几个关键方面,包括属性绑定、对象关系和复杂组合。PixArt-α 在几乎所有 (5/6) 评估指标中表现出出色的性能。这个显著的性能主要归因于第2阶段中的图文对齐学习,其利用高质量的文本图像对来实现卓越的对齐能力。
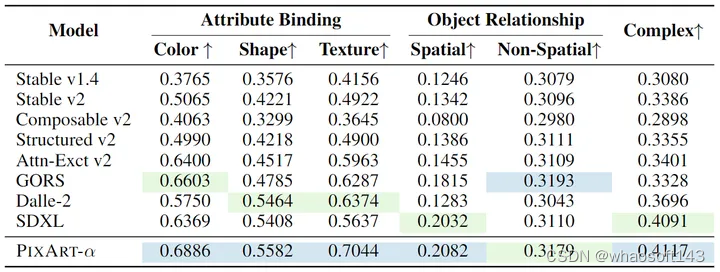
图5:T2I-CompBench 的对齐评价结果
User Study
虽然定量评估指标衡量两个图像集的整体分布,但它们可能无法全面评估图像的视觉质量。因此,作者进行了一项 User Study 来补充评估,并对 PIXART-α 的性能进行了更直观的评估。由于用户研究涉及人工评估员并且可能很耗时,作者选择了性能最佳的模型,即 DALLE-2、SDv2、SDXL 和 DeepFloyd,这些模型可以通过 API 访问并能够生成图像。
对于每个模型,作者使用来自[19]的一致的 300 个 prompt 来生成图像。然后,这些图像在 50 个人之间进行评估。参与者被要求根据生成的图像的感知质量和文本提示与相应图像之间的对齐精度对每个模型进行排名。结果如图6所示,PixArt-α 在更高的保真度和优越的对齐方面都表现出色。例如,与 SDv2 相比,PixArt-α 在图像质量方面提高了 7.2%,对齐提高了 42.4%。
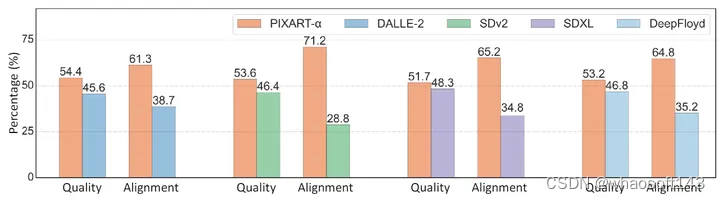
图6:300个固定 prompt 的 User Study 结果
1.7 消融实验结果
作者进行了消融实验,包括结构修改和重参数化设计。在图7中,作者提供了视觉结果和 FID 分析。作者从 SAM 测试集中随机选择8个 prompts 进行可视化并计算 SAM 数据集上的 Zero-Shot FID-5K 分数。 whaosoft aiot http://143ai.com
"w/o re-param" 结果是从从头开始训练的模型生成的,无需重参数化设计。作者额外训练了 200K iteration 来补偿预训练阶段的缺失,以便进行公平的比较。"adaLN" 结果来自遵循 DiT 结构的模型,以使用时间和文本特征的总和作为 MLP 层的输入,用于每个块内的 scale 和 shift 参数。"adaLN-single" 结果是使用本文 Transformer 块和 adaLN-single 模块的模型。这二者都使用了 re-parameterization,训练 200K iterations。

图7:左:视觉比较。右:SAM 的 Zero-shot FID-2K 以及显存占用。本文与 "adaLN" 相当,而且节省 21% GPU 显存
如上图7所示,尽管 "adaLN" 获得了较低的 FID,但它的视觉结果与本文的 "adaLN-single" 的设计相当。"adaLN" 的 GPU 内存消耗为 29GB,而 "adaLN single" 的 GPU 内存消耗减少到 23GB,节省了 21% 的 GPU 内存消耗。此外,考虑到模型参数,"adaLN" 方法消耗了 833M,而本文的方法减少到仅 611M,减少了 26%。"adaLN-single-L (Ours)" 结果是从与“adaLN-single”相同的设置的模型生成的,但在 1500K 次迭代的较长训练周期上进行训练。考虑到内存和参数效率,本文最终使用 "adaLN-single-L"。
视觉结果清楚地表明,尽管 "adaLN" 和 "adaLN-single" 模型之间的 FID 分数差异相对较小,但它们的视觉结果存在显著差异。"w/o re-param" 模型始终扭曲了图像,且缺乏关键的细节。


















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









