







PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
在本论文中,我们介绍了 PixArt-Σ,一个 Diffusion Transformer(DiT)模型,能够直接生成 4K 分辨率的图像。PixArt-Σ 相比其前身 PixArt-α,具有显著的进步,提供了质量更高且与文本提示更加对齐的图像。PixArt-Σ 的一个关键特性是其训练效率。借助 PixArt-α 的基础预训练,它通过整合更高质量的数据从“较弱” 的基线发展到 “较强” 的模型,这一过程我们称之为 “弱到强的训练”。PixArt-Σ 的进步有两个方面:(1)高质量的训练数据:PixArt-Σ 整合了优质的图像数据,配以更精确和详细的图像标题。(2)高效的 token 压缩:我们在 DiT 框架内提出了一种新颖的注意力模块,可以压缩键(key)和值(value),显著提高效率并促进超高分辨率图像的生成。多亏了这些改进,PixArt-Σ 在比现有的文本到图像扩散模型(如 SDXL(2.6B参数)和 SD Cascade(5.1B 参数))更小的模型尺寸(0.6B参数)下,实现了更优质的图像质量和用户提示的遵循能力。此外,PixArt-Σ 生成 4K 图像的能力支持高分辨率海报和壁纸的创作,有效地促进了电影和游戏等行业高质量视觉内容的生产。
项目地址:https://pixart-alpha.github.io/PixArt-sigma-project/
2. 相关工作
(2023|ICCV,DiT,扩散 transformer,Gflops)使用 Transformer 的可扩展扩散模型
(2023,训练分解,高效 DiT,高信息数据集)PIXART-α:用于逼真文本到图像合成的扩散Transformer的快速训练
(2023,微调节,多纵横比训练,细化模型)SDXL:用于高分辨率图像合成的改进的潜在扩散模型
3. 框架
3.1 数据分析
更高的审美和更高的分辨率。为了提升我们数据集的审美质量,我们将内部数据从 14M 扩展到 33M。为了清晰起见,我们分别将这两个数据集命名为 Internal-α 和 Internal-Σ。需要注意的是,与当前可用的开源模型(如使用 2B 数据的 SD v1.5)所使用的大量图像相比,这种扩展仍然不足。我们证明了,即使在数据量有限的情况下,有效的训练策略仍然可以获得强大的 T2I 模型。 Internal-Σ 中的图像分辨率在 1K 以上。为了促进 4K 分辨率的生成,我们另外收集了一个包含 8M真实摄影图像的数据集,分辨率为 4K。为了确保审美质量,我们采用审美评分模型(AES)[1] 来过滤这些 4K 图像。这一过程产生了一个经过高度精炼的、包含 2M 超高分辨率和高质量图像的数据集。
有趣的是,我们观察到随着图像分辨率的增加,模型的保真度(Fréchet Inception Distance(FID)[16])和语义对齐(CLIP Score)有所提高,这凸显了生成高分辨率图像的能力的重要性。

更好的文本-图像对齐。最近的研究,如 PixArt-α [4] 和 DALL-E 3 [30] 强调了文本-图像描述对齐的重要性。加强这种对齐对于提升模型的能力至关重要。为了进一步完善我们收集的 “原始(raw)” 描述,我们专注于提高我们标题的长度和准确性。值得注意的是,我们的标题(Internal-Σ)在以下方面显示出与 PixArt-α(Internal-α)中使用的标题相比的几个优势:
- 提升了标题的准确性:如图 5 所示,PixArt-α 中使用的 LLaVa 存在一定的幻觉问题。我们利用了更强大的视觉语言模型,即 Share-Captioner [5],生成详细且正确的标题,增强了收集到的原始提示。
- 增加了标题长度:如表 1 和图 6 所示,平均标题长度显著增加至 180 个单词,极大地增强了标题的描述能力。此外,我们将文本编码器的令牌处理长度从120个令牌(PixArt-α中的长度)扩展到300个令牌。我们的模型使用长(Share-Captioner)和短(原始)标题的混合训练,比例分别为60%和40%。这种方法增强了文本描述的多样性,并减轻了仅依赖生成性标题可能产生的潜在偏见。
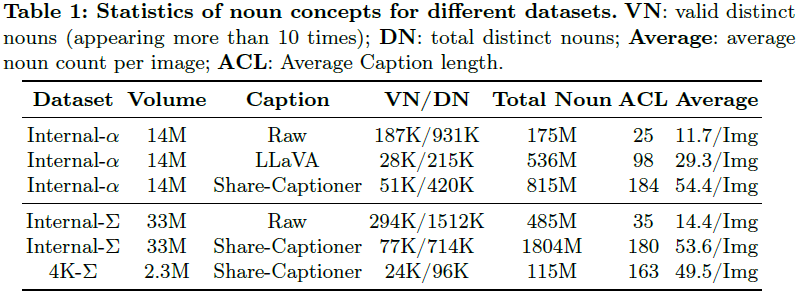
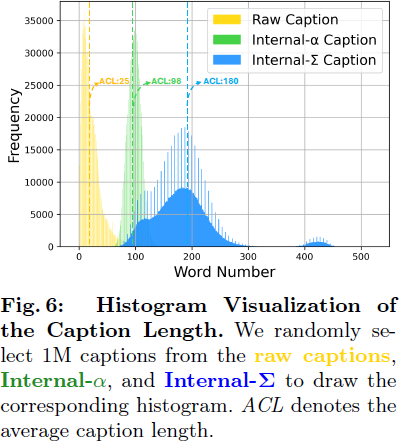
表 1 展示了 Internal-α 和 -Σ 的摘要,我们通过各种指标,包括名词种类的多样性、总名词计数、平均标题长度和平均图像中名词数量,评估了数据集的多样性。
高质量评估数据集。大多数 SoTA T2I 模型选择 MSCOCO [20] 作为评估集来评估 FID 和 CLIP 分数。然而,我们观察到在 MSCOCO 数据集上进行的评估可能无法充分反映模型在审美和文本-图像对齐方面的能力。因此,我们提出了一个由 30,000 个高质量、审美的文本图像对组成的精选集(curated set),以促进评估。数据集的选定样本见附录。该数据集旨在提供对模型性能的更全面评估,特别是在捕捉美学吸引力和文本描述与视觉内容对齐的复杂性方面。除非另有说明,论文中的评估实验均在收集到的高质量评估数据集上进行。
3.2 高效的 DiT 设计
高效的 DiT 网络至关重要,因为在生成超高分辨率图像时,计算需求显著增加。注意机制在Diffusion Transformers 的效能中起着关键作用,然而它的二次计算需求显著限制了模型的可扩展性,特别是在更高的分辨率下,如 2K 和 4K。受 PVT v2 [45] 的启发,我们在原始 PixArt-α 的框架中引入 KV 压缩来解决计算挑战。这种设计仅增加了总参数的 0.018%,但通过 token 压缩实现了计算成本的有效降低,同时仍然保留了空间和语义信息。
键-值(Key-Value,KV)token 压缩。我们的动机源于一个有趣的观察:直接将 键-值(KV)token 压缩应用于预训练的 PixArt-α 仍然可以生成合理的图像。这表明了特征中存在冗余。考虑到相邻 R×R patch 之间的高相似性,我们假设窗口内的特征语义是冗余的,并且可以合理地压缩。 我们提出了 KV token 压缩,表示为 fc(·),通过压缩算子来压缩 R×R 窗口内的 token 特征,如图 7 所示。
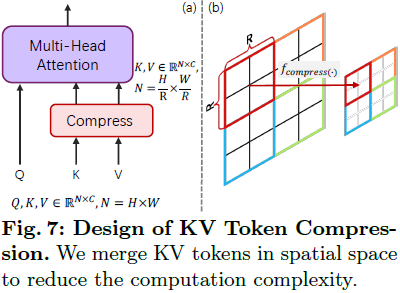
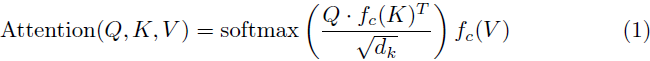
此外,为了减轻 KV 压缩在自注意力计算中可能导致的潜在信息丢失,我们选择保留所有查询(Q)的 token。这种策略使我们能够有效地利用 KV 压缩,同时减轻了丢失关键信息的风险。通过采用 KV 压缩,我们增强了注意力计算的效率,并将计算复杂度从 O(N^2) 降低到 O(N^2 / R^2),从而使直接生成高分辨率图像的计算成本可控。
我们使用卷积算子 “Conv2×2” 和特定初始化来压缩深层。其他设计变体的详细实验在第 5 节中讨论。具体地,我们设计了一种专门的卷积核初始化方法 “Conv Avg Init”,利用了组卷积(group convolution),并将权重初始化为 w = 1 / R^2,相当于一个平均运算符。这种初始化策略可以初步产生粗略的结果,加速微调过程,同时只引入了额外的 0.018% 参数。
3.3 弱到强训练策略
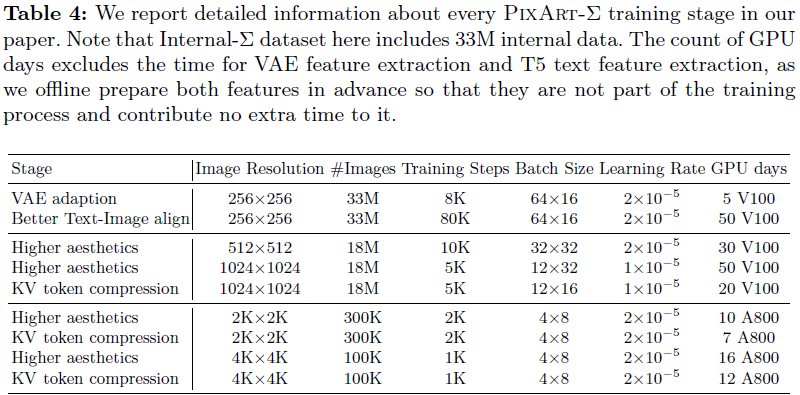
我们提出了几种有效的训练策略,以增强从“弱”模型向“强”模型的过渡。这些策略包括 VAE 快速适应、高分辨率微调和 KV token 压缩。

适应新的 VAE 模型。 随着 VAE 的不断发展,从头开始训练 T2I 模型是资源密集型的。我们用 SDXL 的 VAE 替换 PixArt-α 的 VAE,并继续微调扩散模型。我们观察到了一个快速收敛现象,微调在 2K 训练步骤时快速收敛,如图 8(a) 所示。处理 VAE 模型转移时,微调更加高效,并且消除了从头开始训练的必要性。
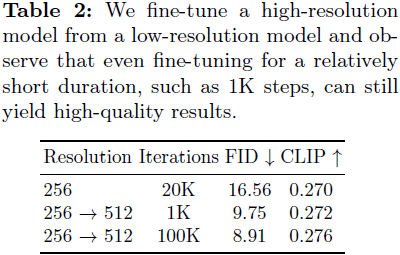
适应更高分辨率。当我们从低分辨率(LR)模型微调到高分辨率(HR)模型时,我们观察到性能下降,如图 8(b) 所示,我们将其归因于不同分辨率之间位置嵌入(positional embeddings,PE)的差异。为了减轻这个问题,我们利用 “PE插值” 技巧 [4, 48]:通过插值 LR 模型的 PE 来初始化 HR 模型的 PE,显著增强 HR 模型的初始状态,并加速微调过程。即使只进行 100 次训练迭代,我们也能获得视觉上令人满意的图像。此外,我们定量评估了模型的性能变化,如表 2 所示。微调在 1K 步骤时快速收敛,进一步的训练略微提高了性能。这表明使用 “PE插值” 技巧可以快速收敛到更高分辨率的生成,无需从头开始训练以生成更高分辨率的图像。
将模型调整为 KV 压缩。在从未使用 KV 压缩的 LR 预训练模型进行微调时,我们可以直接使用 KV 压缩。如图 8(c) 所示,通过我们的 “Conv Avg Init.” 策略,PixArt-Σ 从一个更好的初始状态开始,使得收敛更加容易和快速。值得注意的是,PixArt-Σ 即使在 100 个训练步骤内也能产生令人满意的视觉结果。最后,通过第 3.2 节中的 KV 压缩算子和压缩层设计,我们可以减少约 34% 的训练和推理时间。
4. 实验

5. 消融研究
我们对不同 KV 压缩设计的生成性能进行了消融研究。除非另有说明,实验都是在 512px 生成上进行的。每个消融实验的详细设置都包含在附录中。
5.1 实验设置
我们使用第 3.1 节描述的测试集进行评估。我们采用 FID 来计算收集和生成数据之间的分布差异,作为比较指标。此外,我们利用 CLIP-Score 来评估提示与生成图像之间的对齐情况。
5.2 压缩设计
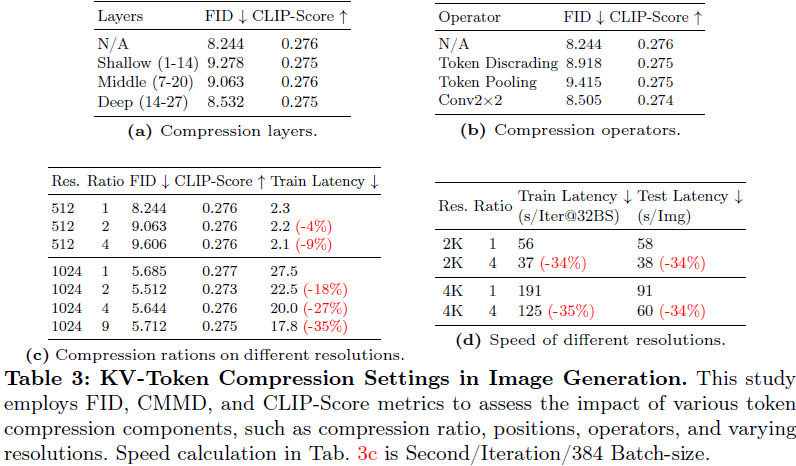
压缩位置。我们在 Transformer 结构的不同深度实现了 KV 压缩:在浅层(1∼14)、中间层(7∼20)和深层(14∼27)。如表 3a 所示,将 KV 压缩应用于深层明显可以实现更优越的性能。我们推测这是因为浅层通常编码了详细的纹理内容,而深层抽象了高层次的语义内容。由于压缩往往会影响图像质量而不是语义信息,压缩深层可以实现最少的信息丢失,这使其成为加速训练但不影响生成质量的实际选择。
压缩运算符。我们探讨了不同压缩运算符的影响。我们采用了三种技术,随机丢弃、平均池化和参数卷积,将 2×2 的 token 压缩为一个单一的 token。如表 3b 所示,“Conv 2×2” 方法优于其他方法,强调了使用可学习的核来更有效地减少冗余特征的优势,而不是简单的丢弃方法。
不同分辨率上的压缩比例。我们调查了不同分辨率上不同压缩比例的影响。如表 3c 所示,显著地,我们发现 token 压缩对文本和生成图像之间的对齐(CLIP 分数)没有影响,但在不同分辨率下影响图像质量(FID)。虽然随着压缩比例的增加,图像质量略有下降,但我们的策略带来了 18% 到 35% 的训练加速。这表明我们提出的 KV 压缩对于实现高分辨率 T2I 生成既有效又高效。
不同分辨率上的速度比较。我们进一步全面验证了训练和推理速度在不同分辨率下的加速情况,如表 3d 所示。我们的方法可以在 4K 生成中将训练和推理加速约 35%。值得注意的是,我们观察到随着分辨率的增加,训练加速逐渐增加。例如,随着分辨率从 1K 增加到 4K,训练逐渐加速从 18% 到 35%。这表明我们的方法在分辨率增加时的有效性,并显示其潜在适用于更高分辨率图像生成任务。

















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









