






召回率 (Recall):正样本有多少被找出来了(召回了多少)。
准确率 (Precision):你认为的正样本,有多少猜对了(猜的准确性如何)。
阐述机器学习分类模型评估中常见的性能度量指标(performance measure):Accuracy(精度)、Precision(精准度)和Recall(召回率),这是理解更为复杂分类模型性能度量指标(例如目标检测任务中的mAP)的基础。
(一)Accuracy and Error Rate
Accuracy(精度)和Error Rate(错误率)是分类模型中最常见的两种性能度量指标,既适用于二分类任务,也适用于多分类任务。

(二)Precision and Recall
Accuracy虽然常用,但是无法满足所有分类任务需求。我们看两个例子:
例1:恐怖分子识别任务,二分类问题,恐怖分子为正例,非恐怖分子负例。
这个任务的特点是正例负例分布非常不平均,因为恐怖分子的数量远远小于非恐怖分子的数量。假设一个数据集中的恐怖分子的数量与非恐怖分子的数量比例为1:999999999,我们引入一个二分类判别模型,它的行为是将所有样例都识别为负例(非恐怖分子),那么在这个数据集上该模型的Accuracy高达99.9999999%,但恐怕没有任何一家航空公司会为这个模型买单,因为它永远不会识别出恐怖分子,航空公司更关注有多少恐怖分子被识别了出来。
例2:垃圾邮件识别任务,二分类问题,垃圾邮件为正例,非垃圾邮件为负例。
与恐怖分子识别任务类似,人们更关心有多少垃圾邮件被识别了出来,而不是Accuracy。
在上述两个任务中,人们的关注点发生了变化,Accuracy已经无法满足要求,由此我们引入Precision(精准度)和Recall(召回率),它们仅适用于二分类问题。
对于一个二分类任务,二分类器的预测结果可分为以下4类:
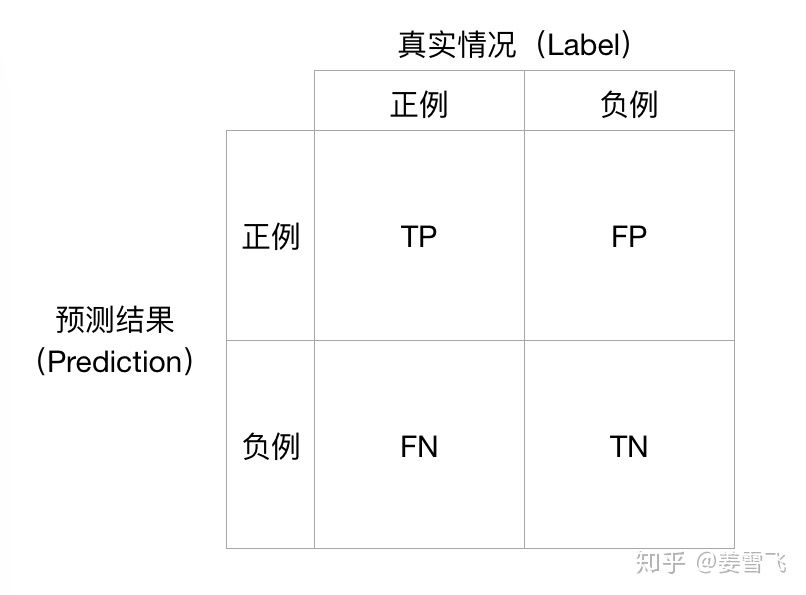
二分类器的结果可分为4类

Precision从预测结果角度出发,描述了二分类器预测出来的正例结果中有多少是真实正例,即该二分类器预测的正例有多少是准确的;Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
Precision和Recall通常是一对矛盾的性能度量指标。一般来说,Precision越高时,Recall往往越低。原因是,如果我们希望提高Precision,即二分类器预测的正例尽可能是真实正例,那么就要提高二分类器预测正例的门槛,例如,之前预测正例只要是概率大于等于0.5的样例我们就标注为正例,那么现在要提高到概率大于等于0.7我们才标注为正例,这样才能保证二分类器挑选出来的正例更有可能是真实正例;而这个目标恰恰与提高Recall相反,如果我们希望提高Recall,即二分类器尽可能地将真实正例挑选出来,那么势必要降低二分类器预测正例的门槛,例如之前预测正例只要概率大于等于0.5的样例我们就标注为真实正例,那么现在要降低到大于等于0.3我们就将其标注为正例,这样才能保证二分类器挑选出尽可能多的真实正例。
那么有没有一种指标表征了二分类器在Precision和Recall两方面的综合性能呢?答案是肯定的。如前面所说,按照二分类器预测正例的门槛的不同,我们可以得到多组precision和recall。在很多情况下,我们可以对二分类器的预测结果进行排序,排在前面的是二分类器认为的最可能是正例的样本,排在最后的是二分类器认为的最不可能是正例的样本。按此顺序逐个逐步降低二分类器预测正例的门槛,则每次可以计算得到当前的Precision和Recall。以Recall作为横轴,Precision作为纵轴可以得到Precision-Recall曲线图,简称为P-R图:
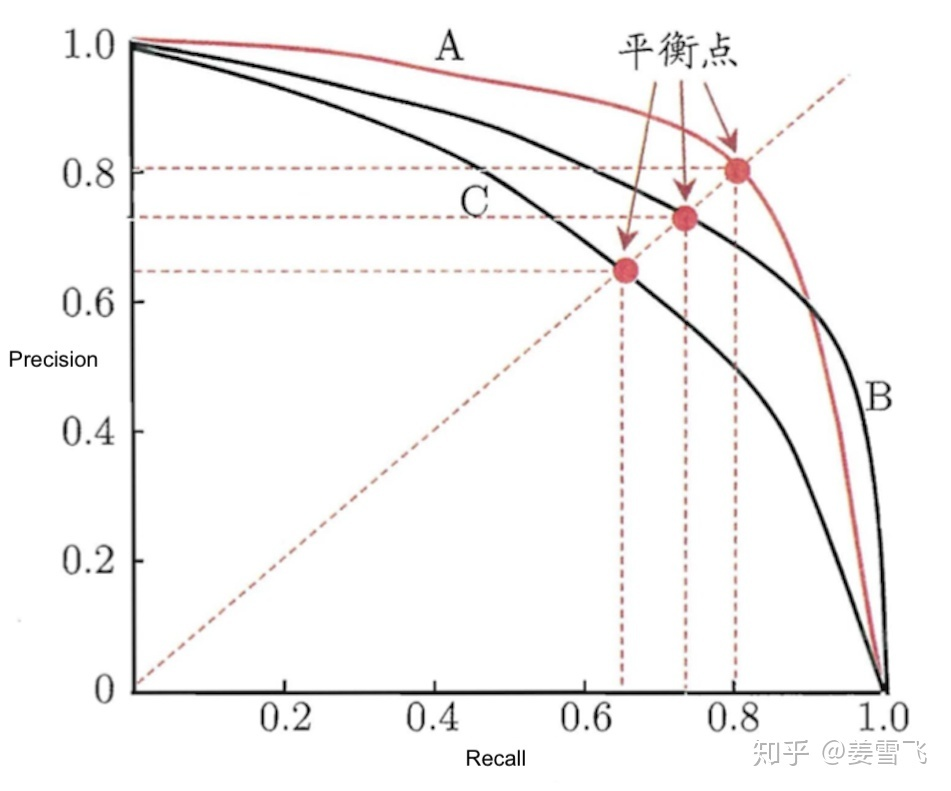
P-R曲线
P-R图可直观地显示出二分类器的Precision和Recall,在进行比较时,若一个二分类器的P-R曲线被另一个二分类器的P-R曲线完全包住,则可断言后者的性能优于前者,例如上图二分类器A的性能优于C;如果两个二分类器的P-R图发生了交叉,则难以断言二者性能孰优孰劣,例如上图中的二分类器A与B。然而,在很多情况下,人们还是希望将二分类器A和B性能比个高低,这时一个比较合理的指标是P-R曲线下面的面的大小,它在一定程度上表征了二分类器在Precision和Recall这两方面的综合性能。
(三)总结
- Precision和Recall往往是一对矛盾的性能度量指标;
- 提高Precision == 提高二分类器预测正例门槛 == 使得二分类器预测的正例尽可能是真实正例;
- 提高Recall == 降低二分类器预测正例门槛 == 使得二分类器尽可能将真实的正例挑选出来;
- P-R曲线下面的面积表征了二分类器在Precision和Recall这两方面的综合性能;

















 4128
4128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









