






如果你是 NLP 领域初学者,欢迎关注我的博客,我不仅会分享理论知识,更会通过实例和实用技巧帮助你迅速入门。我的目标是让每个初学者都能轻松理解复杂的 NLP 概念,并在实践中掌握这一领域的核心技能。
通过我的博客,你将了解到:
- NLP 的基础概念,为你打下坚实的学科基础。
- 实际项目中的应用案例,让你更好地理解 NLP 技术在现实生活中的应用。
- 学习和成长的资源,助你在 NLP 领域迅速提升自己。
不论你是刚刚踏入 NLP 的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在 NLP 的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。
【NLP 基础知识一】词嵌入(Word Embeddings)
【NLP 基础知识二】词嵌入(Word Embeddings)之“Word2Vec:一种基于预测的方法”
【NLP 基础知识三】词嵌入(Word Embeddings)之“GloVe:单词表示的全局向量”
一、词嵌入
1、概述
机器学习模型“查看”数据的方式与我们(人类)不同。例如,我们可以很容易地理解文本“我看到了一只猫”,但模型却不能,模型需要特征向量。这样的特征向量被称为词嵌入,是一种可以输入模型的词语表示。
2、工作原理:查找表(词表)
在实践中,你有一个事先确定好的词汇表。对于每个词汇表中的单词,查找表都有该单词对应的词嵌入,我们可以使用单词在词汇表中的索引找到该词嵌入。
为了表示未登录词(即不在词汇表中的词),词汇表通常包含一个特殊的单词 UNK。当然,我们也可以选择忽略未登录词,或者简单分配一个零值向量。
二、如何获得这些词向量?
1、离散符号表示:独热向量(One-hot Vectors)
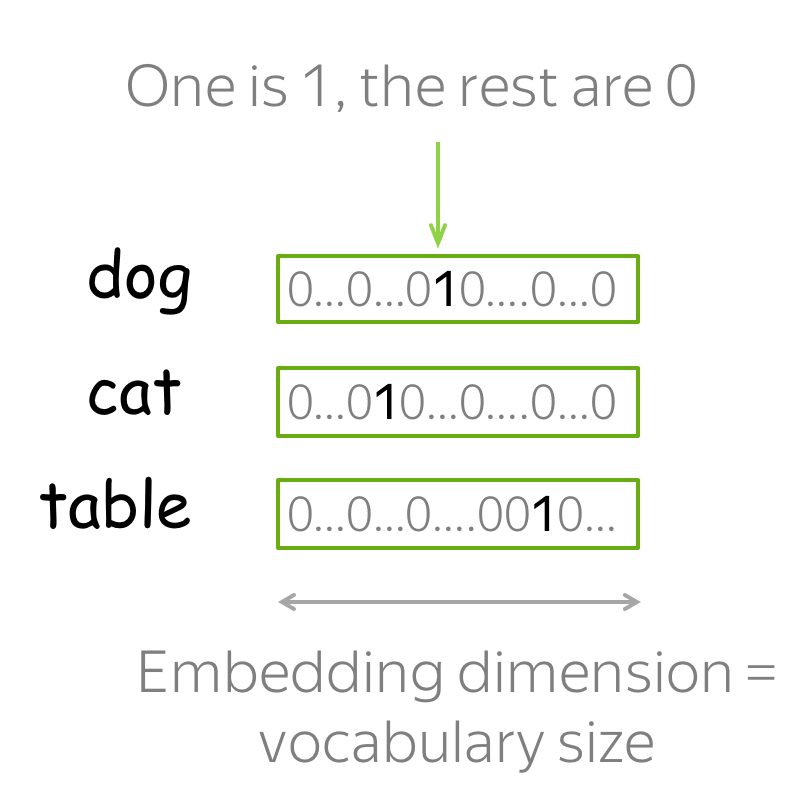
最简单的词向量表示方法是用独热(One-hot)向量表示每个单词:对于词汇表中的第 i 个单词,独热向量的第 i 个维度为 1,其余为 0。在机器学习中,独热向量是表示分类特征最简单的方法。
你大概能猜到为什么独热向量不是表示单词的最佳方式。它的一个已知问题是,独热向量在词汇表较大时会变得非常长,因为独热向量的维度就等于词汇表大小,这在实践中是不可取的。但这并不是最关键的问题。
真正重要的是,独热向量对它们所代表的词语一无所知。例如,明显背离常识的是,独热向量居然认为 “猫”到“狗”和“桌子”的语义距离一样近!因此,我们认为独热向量没有捕捉到单词含义。
那么问题来了,我们怎么知道什么是含义呢?
2、分布式语义
为了捕捉单词向量表示的含义,我们首先需要定义可以在实践中使用的“含义”的概念。为此,让我们首先来了解人类如何知道哪些词具有相似的含义。
看一下下面这几张图,可以帮助你更加直观的理解。
你知道
![]()
这个词的含义吗?
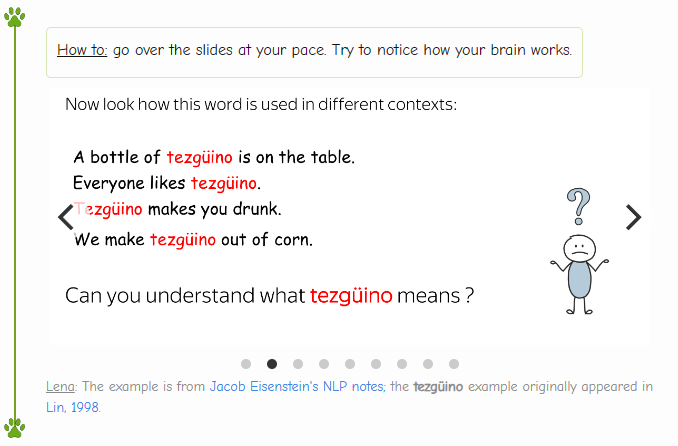
下面给出一些包含这个词的句子,现在你能理解这个词的意思了吗?
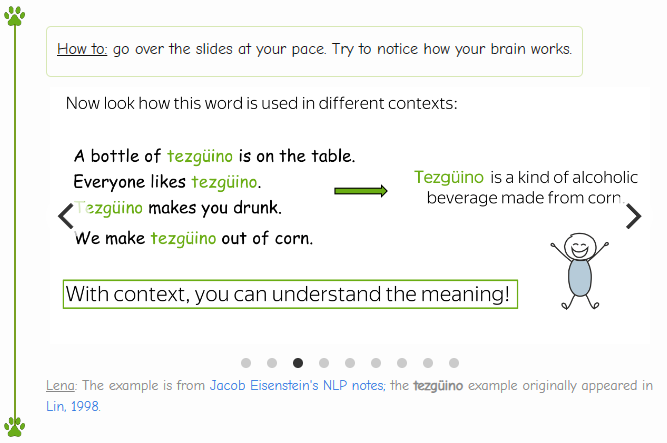
这个词的意思是一种饮料,现在你可以理解了吧。
然后呢?
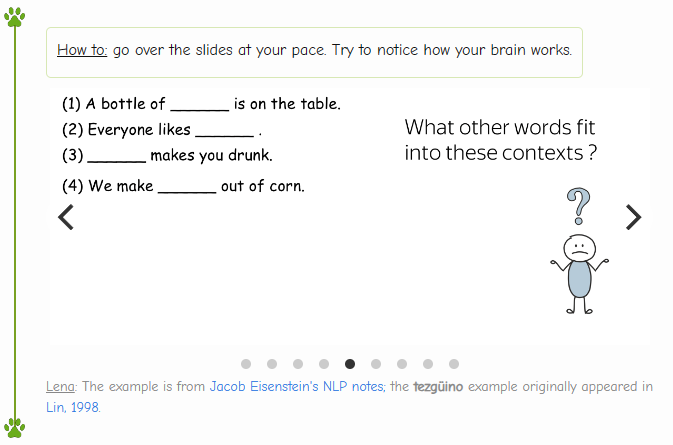
有没有其他的词可以填入这些空呢?(遇到同样的句子,空的位置却是其他的词。)
1 代表可以填入,0 代表不能。

形成的向量,有一些行是非常相似的。
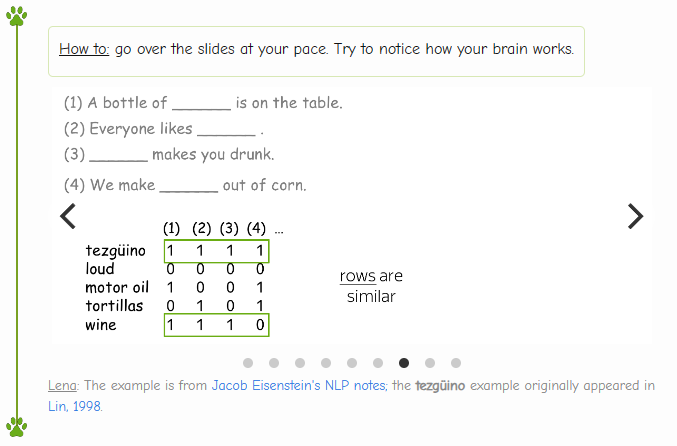
行与行之间越相似,我们认为这两个词越相似

这就是分布式语义的思想
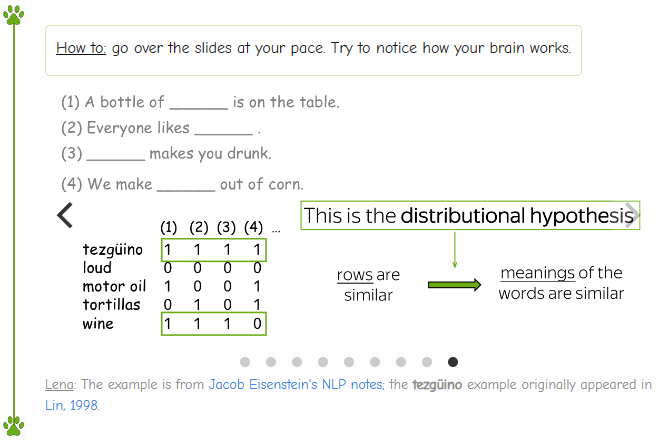
人类有一种能力:一旦你看到未知词语在不同语境中的使用方式,你就能够理解它的含义。那人类是怎么做的呢?
猜想是:你的大脑搜索了其他可用于相同语境的词,找到一些单词(例如,葡萄酒),并得出结论 tezgüino 与这些词具有相似的含义。这就是分布假设:
经常出现在相似上下文中的词具有相似含义。
Words which frequently appear in similar contexts have similar meaning.这是一个非常有价值的想法:可以用在实践中让词向量捕捉单词的含义。根据分布假设,“捕捉含义”和“捕捉上下文”在本质上是一样的。 因此,我们需要做的就是将有关单词上下文的信息引入单词表示中。
核心思想:我们需要将有关单词上下文的信息引入单词表示中。在本次课程中,我们要做的就是使用不同的方法来做到这一点。
3、基于计数的方法
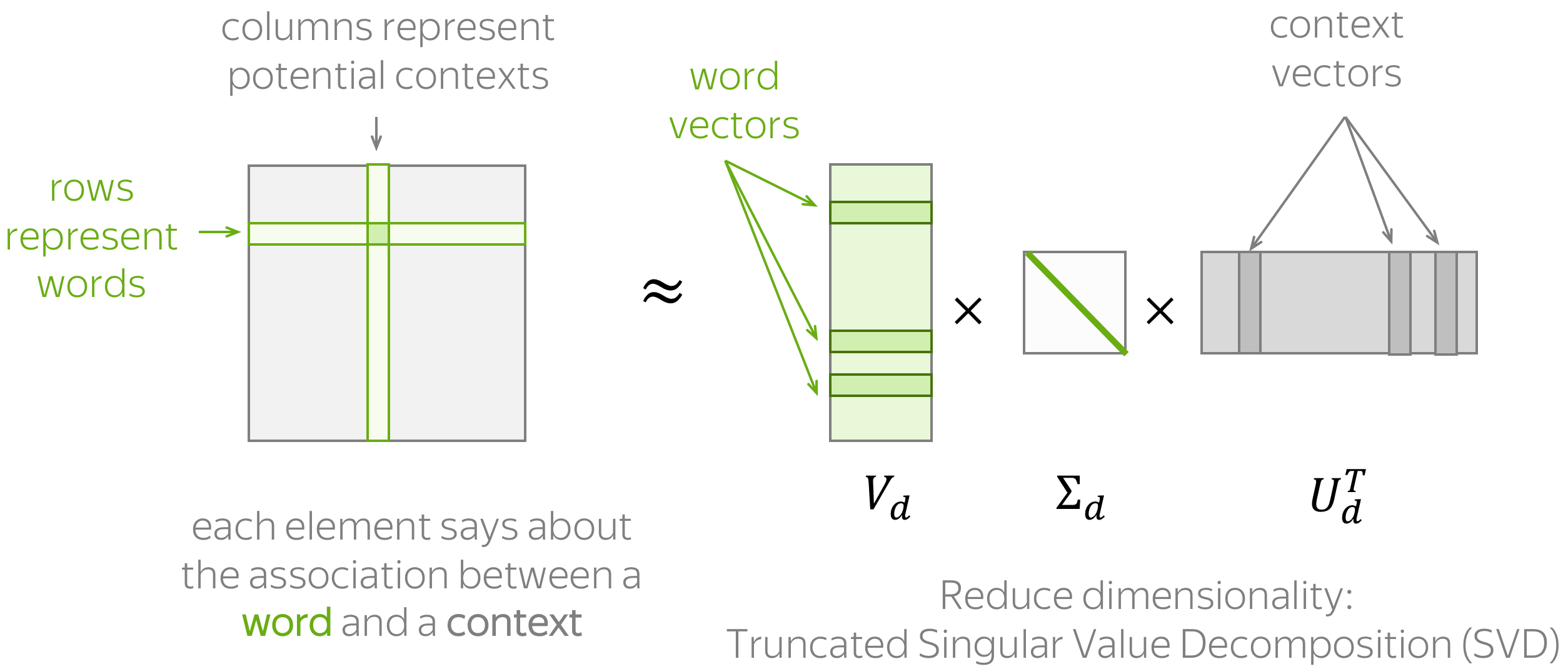
如果你看不懂上面的图,请继续向下看
再来重申一下我们的核心思想:
核心思想:我们需要将有关上下文的信息引入词向量中。基于计数的方法非常直观地实现了这个想法:
具体做法:根据全局的语料统计手动地放置这些信息。一般地,该方法包括两个步骤 (过程如上图所示):(1) 构造一个单词-上下文 (Word-Context) 的关联矩阵; (2) 降低该矩阵的维度。这里降维主要有两个原因:一方面,原始矩阵非常大。另一方面,由于很多词语只出现在比较少见的上下文中,这样的矩阵可能有很多没什么信息量的元素(例如,空值)。
要设计一个基于计数的方法,我们需要定义两件事:
- 上下文的定义(包括单词出现在上下文中意味着什么)
- 关联的定义(即如何计算单词-上下文关联矩阵中每个元素)。
下面我们介绍几种主流的方法来实现这两个概念。
简单:共现计数
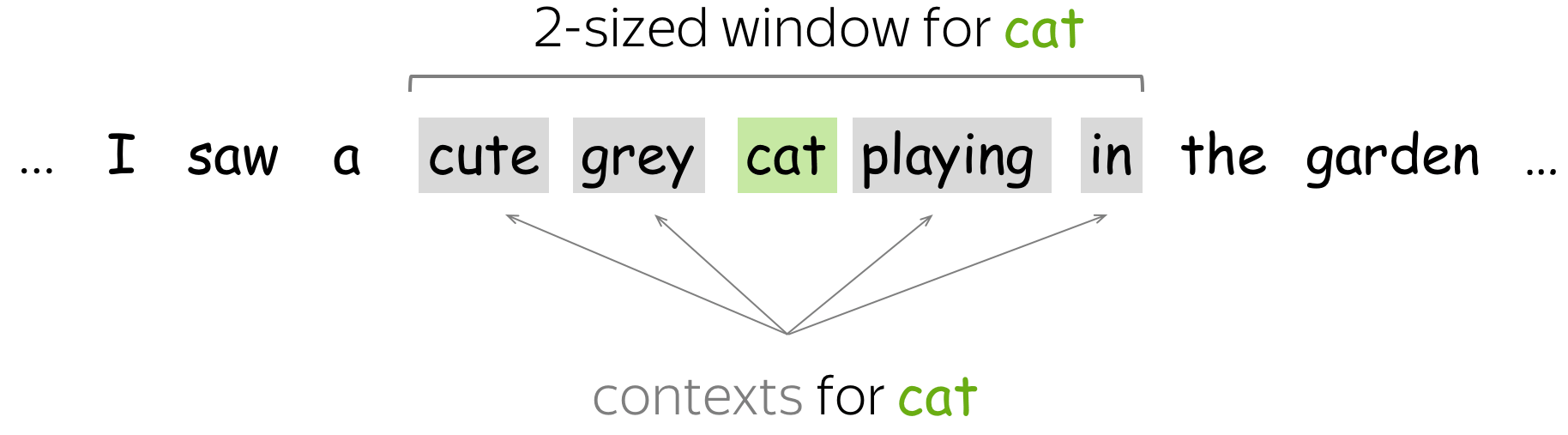

在本方法中,上下文被定义为 L 大小窗口中的每个单词。而单词-上下文组成的 (w, c) 对应的关联矩阵元素是 w 在上下文 c 中出现的次数。这是获取词嵌入非常基本(且非常古老)的方法。
正点交互信息 (PPMI)

以上图如果看不懂,请继续往下看
先了解一下什么是 PMI(Pointwise Mutual Information)点互信息:
这一指标用来衡量两个事物之间的相关性。公式如下:
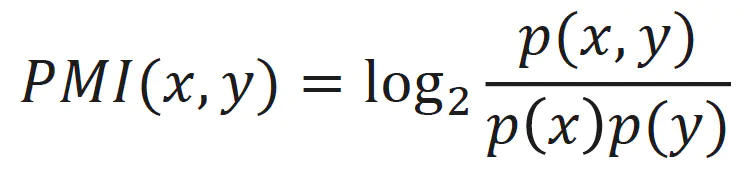
在概率论中,如果 x 和 y 无关,p(x,y)=p(x)p(y);如果 x 和 y 越相关,p(x,y) 和 p(x)p(y) 的比就越大。从后两个条件概率可能更好解释,在 y 出现的条件下 x 出现的概率除以单看 x 出现的概率,这个值越大表示 x 和 y 越相关。
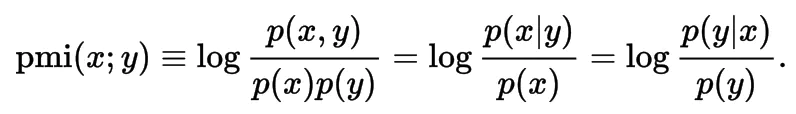
log 来自于信息论的理论,而且 log 1 = 0 ,也恰恰表明 P(x,y) = P(x)P(y),相关性为 0,而且 log 是单调递增函数,所以 “P(x,y) 就相比于 P(x)P(y) 越大,x 和 y 相关性越大” 这一性质也得到保留。
通常会计算一个 PPMI(Positive PMI) 来避免出现 -inf,即

在这种方法中,上下文的定义和之前一样,但是单词和上下文之间关联矩阵的计算采用了更加聪明的 PPMI (Positive Pointwise Mutual Information, 正点交互信息) 度量。 PPMI 度量被广泛认为是神经网络出现前用于度量分布相似性的最佳技术。
重要:本方法与神经网络密不可分!事实证明,接下来介绍的一些基于神经网络的方法 (Word2Vec) 被证明实际上是在隐式逼近(移位的)PMI 矩阵的因式分解。敬请关注!
潜在语义分析 (LSA):理解文档

LSA (Latent Semantic Analysis, 潜在语义分析) 方法 需要分析文档的集合。在前人方法中,上下文仅用于获取词向量,之后就会被丢弃。但在 LSA 方法中,上下文也要被充分利用,用来计算文档向量。也因此,LSA 成为最简单的主题模型之一:所获得的文档向量之间的余弦相似度可以用来衡量文档之间的相似度。
术语 LSA 有时是指将 SVD 应用于单词-文档矩阵的通用方法,其中单词-文档矩阵的各个元素可以通过不同的方式计算(例如,简单的共现、tf-idf 或其他的衡量方法 ).
动画预告! LSA 的 Wikipedia 主页在单词-文档矩阵中有一个很好的动画用于揭示文档的主题探测过程,一定要看看!
4、Word2Vec:一种基于预测的方法
今天太晚了,先到这里,Word2Vec:一种基于预测的方法,这一章篇幅有点多,明天才能产出。
出了链接就在这里:
【NLP基础知识二】词嵌入(Word Embeddings)之“Word2Vec:一种基于预测的方法”
在这个充满科技魔力的时代,自然语言处理(NLP)正如一颗璀璨的明星般照亮我们的数字世界。当我们涉足 NLP 的浩瀚宇宙,仿佛开启了一场语言的奇幻冒险。正如亚历克斯 · 康普顿所言:“语言是我们思想的工具,而 NLP 则是赋予语言新生命的魔法。”这篇博客将引领你走进 NLP 前沿,发现语言与技术的交汇点,探寻其中的无尽可能。不论你是刚刚踏入 NLP 的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在 NLP 的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。















 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









