







前言
决策树(Decision Tree,DT),同样也是一个非常适合入门的分类算法,因为它的原理和KNN算法一样,很好理解和解释。DT对于数据量要求不是太高,且输入数据可以不需要进行规范化或者归一化处理。此外,还存在众多优势,这里不一一列举,各位可以自行百度了解。
首先简单看看原理和构建流程:

还是简单用一个例子介绍一下它的运作过程:
比如说想设计一个策略对一群人是否喜欢玩绝地求生游戏进行划分:
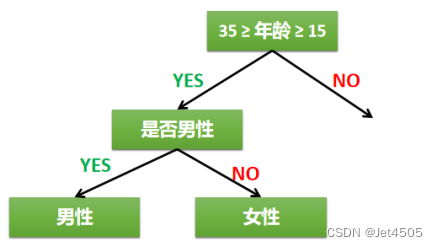
首先可以考虑年龄,我们粗暴地认为年龄在15岁到35岁区间的人群,玩游戏的概率大,这样就缩小了一部分范围;其次,进一步细分,这一次我们使用性别进行区分,无脑盲猜男同志更喜欢玩游戏。以上就是一个简单的决策、分类过程,其实就是“如果-那么”的过程,画成流程图的话,非常像一棵树:
根节点:第一个选择点(年龄范围);
非叶子结点与分支:中间决策过程(性别);
叶子结点:最终的决策结果(15岁到35岁区间的男性)。
稍微思考会发现下面一系列问题:
(1)根节点如何选择?依据是什么?(为什么首先考虑年龄进行划分)
(2)次根节点又如何选择?依据又是什么?(为什么是性别)
(3)根节点切割的依据又是什么?(为什么年龄区间设置在15岁到35岁)
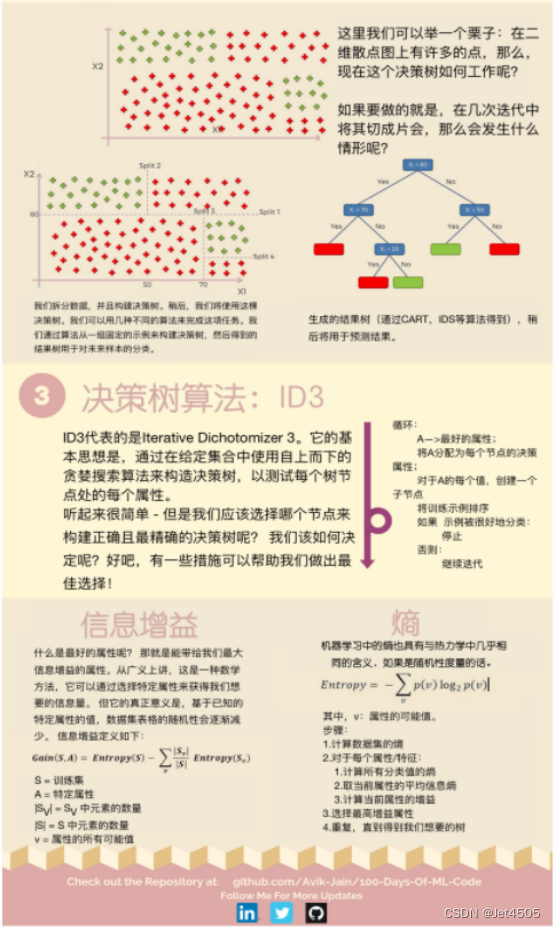
所以得指定一个指标,当机器把所有可能的特征排序进行模拟以后,得出一系列的分类情况,通过这个指标来判断哪一个特征作为根节点最好,以此类推,画出完整的决策树。这个指标就是信息增益:表示特征X使得类别Y的不确定性减少的程度。但在实际使用中,它也有弊端,所以有提出了2个指标:信息增益率和gini系数。人们分别把他们称为:ID3树、C4.5树和CART树。具体公式和数学原理不说了,可自行百度食用。
好了,原理说完了,开始进行实战:使用DT算法预测用户是否会购买SUV,没错,还是逻辑回归那个例子。
一、导入库与数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 导入数据集
dataset = pd.read_csv('Day 4 Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
Y = dataset.iloc[:, 4].values
# 性别转化为数字
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
二、数据集切分与特征缩放
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=0)
# 特征缩放
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
三、数据训练与预测
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)
保姆级操作演示
1、又到了刺激环节,看KNN的代码参数:DecisionTreeClassifier(),这里设置了两个不明参数,其他用的是默认参数,我们看看具体有什么:
clf = tree.DecisionTreeClassifier(criterion=“gini”, splitter=“best”, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0., max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0., class_weight=None, ccp_alpha=0.0)
① criterion:gini(默认),entropy。节点质量评估函数(gini为基尼系数,entropy为熵)。
② splitter:best(默认),random。分枝时变量选择方式(random:随机选择,best:选择最好的变量)。
③ max_depth:整数,默认None。树分枝的最大深度(为None时,树分枝深度无限制)。
④ min_samples_split:整数或小数,默认2。节点分枝最小样本个数。节点样本>=min_samples_split时,允许分枝,如果小于该值,则不再分枝(也可以设为小数,此时当作总样本占比,即min_samples_split=ceil(min_samples_split *总样本数)。
⑤ min_samples_leaf:整数或小数,默认1。叶子节点最小样本数。左右节点都需要满足>=min_samples_leaf,才会将父节点分枝,如果小于该值,则不再分枝(也可以设为小数,此时当作总样本占比,即min_samples_split=ceil(min_samples_split *总样本数))。
⑥ min_weight_fraction_leaf:小数,默认值0。叶子节点最小权重和。节点作为叶子节点,样本权重总和必须>=min_weight_fraction_leaf,为0时即无限制。
⑦ max_features:整数,小数,None(默认),{“auto”, “sqrt”, “log2”}。特征最大查找个数。先对max_features进行如下转换,统一转换成成整数。
整数:max_features=max_features
auto:max_features=sqrt(n_features)
sqrt:max_features=sqrt(n_features)
log2:max_features=log2rt(n_features)
小数:max_features=int(max_features * n_features)
None:max_features=n_features
如果max_features<特征个数,则会随机抽取max_features个特征,只在这max_features中查找特征进行分裂。
⑧ random_state:整数,None(默认)。需要每次训练都一样时,就需要设置该参数。
⑨ max_leaf_nodes:整数,None(默认)。最大叶子节点数。如果为None,则无限制。
⑩ min_impurity_decrease:小数,默认0。节点分枝最小纯度增长量。信息增益
⑪ class_weight:设置各类别样本的权重,默认是各个样本权重一样,都为1。
⑫ ccp_alpha:剪枝时的alpha系数,需要剪枝时设置该参数,默认值是不会剪枝的。
2、所以说,这个代码classifier = DecisionTreeClassifier(criterion = ‘entropy’, random_state = 0)表示:节点质量评估函数选用熵,random_state = 0是为了模型构建的可重复性。
四、模型评估
模型预测,使用混淆矩阵评估:
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
输出的结果:

用我们上一步赠送的混淆矩阵可视化代码:
有兴趣可以看看,DT算法和KNN算法的区别。

保姆级操作演示
在补充一点,这个代码classifier = DecisionTreeClassifier(criterion = ‘entropy’, random_state = 0)的“random_state = 0”,作用是为了确保每次运行的结果是可以重复的。凡是有“random_state”这种参数的,说明在运行过程中存在一个随机的过程。既然是随机,那么不施加一个固定参数,那么每一次结果也都是随机的(当然可能差距不是很大,取决于数据集)。如果你足够细心,你会发现在数据拆分函数,也有这个东西:train_test_split(X, Y, test_size=0.25, random_state=0)。
举例说明,估计更直观:
random_state = 0的混淆矩阵:
random_state = 1的混淆矩阵:
random_state = 520的混淆矩阵:
random_state = 10086的混淆矩阵:
结果大同小异,不过在random_state = 1的时候还是有差别。




总结
留一个问题,你知道怎么巧妙地利用random_state的这个设置么?后续再说。

















 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











