







前言
随机森林(Random Forest,RF)是一种非常流行的ML集成学习策略,之所以把随机森林放到决策树后面介绍,大家基本也猜到两者的关系了吧,所谓树木构成森林。随机森林的“森林”就是指该模型的基本单元是决策树,针对同一个问题建立多个决策树,分别输出自己的结果,最后将其结果来平均,得出最终的结果。
那么“随机”怎么体现呢?这里的随机叫做二重随机性:
(1)首先是随机选择数据。进行有放回的随机采样,比如说随机抽取70%的数据当作第一棵树的输入,再随机抽取70%的数据当作第二棵树的输入,这样构建的树有自己的个性。
(2)其次是随机选择特征。第一棵树随机选择所有特征中的60%来建模,第二棵再随机选择其中60%的特征来建模,这样就把差异放大了。
随机森林的目的就是要通过大量的基础树模型找到最稳定可靠的结果,如图所示:


好了,原理说完了,开始进行实战:使用DT算法预测用户是否会购买SUV,没错,还是逻辑回归那个例子。
一、导入库与数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 导入数据集
dataset = pd.read_csv('Day 4 Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
Y = dataset.iloc[:, 4].values
# 性别转化为数字
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
二、数据集切分与特征缩放
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=0)
# 特征缩放
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
三、数据训练与预测
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)
四、预测测试集结果
y_pred = classifier.predict(X_test)
保姆级操作演示
1、截至目前,我们介绍四个分类模型了,不知道大家有没有发现其实构建流程都是一致的,唯一的区别在于具体模型的代码和参数。能悟出这一点,说明开始入门了。话说回来,继续看RF的代码参数:RandomForestClassifier(),这里设置了三个不明参数,其中两个跟之前的DT是一样的,其他用的是默认参数,我们看看具体有什么:
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion=‘gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=‘auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
可以看到一些熟悉的参数,因为这些参数跟决策树是一致的:
① criterion:gini(默认),entropy。节点质量评估函数(gini为基尼系数,entropy为熵)。
② max_depth:整数,默认None。树分枝的最大深度(为None时,树分枝深度无限制)。
③ min_samples_split:整数或小数,默认2。节点分枝最小样本个数。节点样本>=min_samples_split时,允许分枝,如果小于该值,则不再分枝(也可以设为小数,此时当作总样本占比,即min_samples_split=ceil(min_samples_split *总样本数)。
④ min_samples_leaf:整数或小数,默认1。叶子节点最小样本数。左右节点都需要满足>=min_samples_leaf,才会将父节点分枝,如果小于该值,则不再分枝(也可以设为小数,此时当作总样本占比,即min_samples_split=ceil(min_samples_split *总样本数))。
⑤ min_weight_fraction_leaf:小数,默认值0。叶子节点最小权重和。节点作为叶子节点,样本权重总和必须>=min_weight_fraction_leaf,为0时即无限制。
⑥ max_features:整数,小数,auto(默认),{“auto”, “sqrt”, “log2”}。特征最大查找个数。先对max_features进行如下转换,统一转换成成整数。
整数:max_features=max_features
auto:max_features=sqrt(n_features)
sqrt:max_features=sqrt(n_features)
log2:max_features=log2rt(n_features)
小数:max_features=int(max_features * n_features)
None:max_features=n_features
如果max_features<特征个数,则会随机抽取max_features个特征,只在这max_features中查找特征进行分裂。
⑦ max_leaf_nodes:整数,None(默认)。最大叶子节点数。如果为None,则无限制。
⑧ min_impurity_decrease:小数,默认0。节点分枝最小纯度增长量。信息增益
⑨ random_state:整数,None(默认)。需要每次训练都一样时,就需要设置该参数。
⑩ class_weight:设置各类别样本的权重,默认是各个样本权重一样,都为1。
⑪ ccp_alpha:剪枝时的alpha系数,需要剪枝时设置该参数,默认值是不会剪枝的。
RF特有的参数:
① n_estimators:整数,默认10。决策树的个数,理论上越多越好,注意理论上,还是得根据数据集调整的。
② bootstrap:默认Ture。是否有放回的采样,之前说过原理了。
③ oob_score:默认False。带外数据,也就是在某次随机选取一批数据来构建决策树,那些没有被选取到的数据。可以用来做一个简单的交叉验证,性能消耗小,效果还行。
④ n_jobs:1,n,-1,默认1。设置多少个job同时进行运算,从而提高性能。1代表不并行;代表n个并行;-1代表CPU有多少个核,就多少个并行。
⑤ warm_start:默认Flase。热启动,决定是否使用上次调用该类的结果然后增加新的。
2、所以说,这个代码classifier = RandomForestClassifier(n_estimators = 10, criterion = ‘entropy’, random_state = 0)表示:节点质量评估函数选用熵,random_state = 0是为了模型构建的可重复性。其实这里面是有几个重要参数可以调的,但是第一次接触RF,就想用默认参数了。后续实战环节,在进行调参的介绍。
五、模型评估
模型预测,使用混淆矩阵评估:
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
输出的结果:

混淆矩阵可视化:
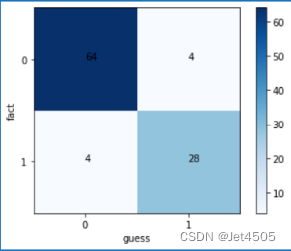
保姆级操作演示
有心的同学应该私下去对比了一下目前所学到的几个分类模型的性能了吧,应该都是差不多的。这说明结果的好坏,其实大多取决于数据集,所以流传着“没有最好的模型,只有最好的数据”的传说,虽然这个说法也有局限性,但是懂的都懂哈。
我们稍微来调整一下参数试试:
比如说,把决策树的数量调大到100,看看是否会有惊喜,
classifier = RandomForestClassifier(n_estimators = 100, criterion = 'entropy', random_state = 0)
输出结果:
然而并没有改进,不知道有没有同学好奇一个问题:这4+4=8个样本到底长什么样子,使得模型都分不开呢?
要是你能想到这个问题,那说明独立思考了,你的文章又可以多一个图了。

总结
NA

















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











