







一、Deepseek 简介
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司。DeepSeek 是一家创新型科技公司,成立于 2023 年 7 月 17 日,使用数据蒸馏技术 ,得到更为精炼、有用的数据 。由知名私募巨头幻方量化孕育而生,专注于开发先进的大语言模型(LLM)和相关技术。
2025 年 2 月 2 日,据彭博社报道,由 DeepSeek 开发的人工智能助手在全球范围内掀起了一股热潮。这款推理型 AI 聊天机器人自 2025 年初发布以来,迅速攀升至 140 个国家的苹果 App Store 下载排行榜首位,并在美国的 Android Play Store 中同样占据榜首位置。

企业官网
官方地址:https://www.deepseek.com/

客户端:https://download.deepseek.com/app/
团队信息
DeepSeek 创始人梁文锋,1985 年出生于广东省湛江市。梁文锋从小成绩优异,小学六年级时他就通过考试被吴川一中录用。一直是学校里的“尖子生”并在数学学科表现出极大天赋。
2002 年,梁文锋 17 岁,以吴川一中“高考状元”的成绩考上浙大本科电子信息工程专业,于 2007 年考上浙江大学信息与通信工程专业研究生。
2013 年,梁文锋与浙大同学徐进共同创立了杭州雅克比投资管理有限公司,两年后又成立了杭州幻方科技有限公司,致力于通过数学和人工智能进行量化投资。
2021 年,幻方的资产管理规模突破千亿大关,2023 年,他宣布将正式进军通用人工智能领域,并创办了深度求索 DeepSeek,专注于做真正人类级别的人工智能。
近日这名 85 后还现身《新闻联播》以 AI 初创公司深度求索(DeepSeek)创始人的身份参加了一场国家超高规格座谈会,并现场发言。


从目前已有的媒体公开报道中可以看出,DeepSeek 团队最大的特点是名校、年轻,即使是团队 Leader 级别,年纪也多在 35 岁以下。不到 140 人的团队,工程师和研发人员几乎都来自清华大学、北京大学、中山大学、北京邮电大学等国内顶尖高校,工作时间都不长。
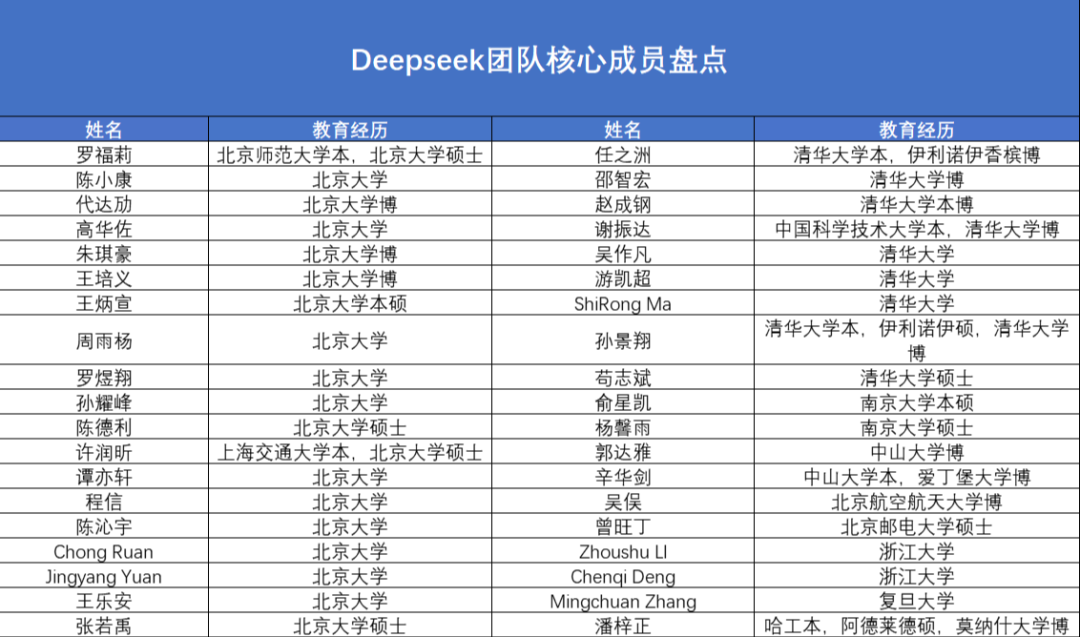
据澎湃新闻报道,有负责大模型领域挖掘高端科技人才的猎头表示,DeepSeek 的用人逻辑和大模型领域其他公司的用人逻辑并无太大差异,对人才的核心标签都是“年轻高潜”,即年龄在 1998 年出生左右,工作经验最好不要超过五年,“聪明、理工科、年轻、经验少。”
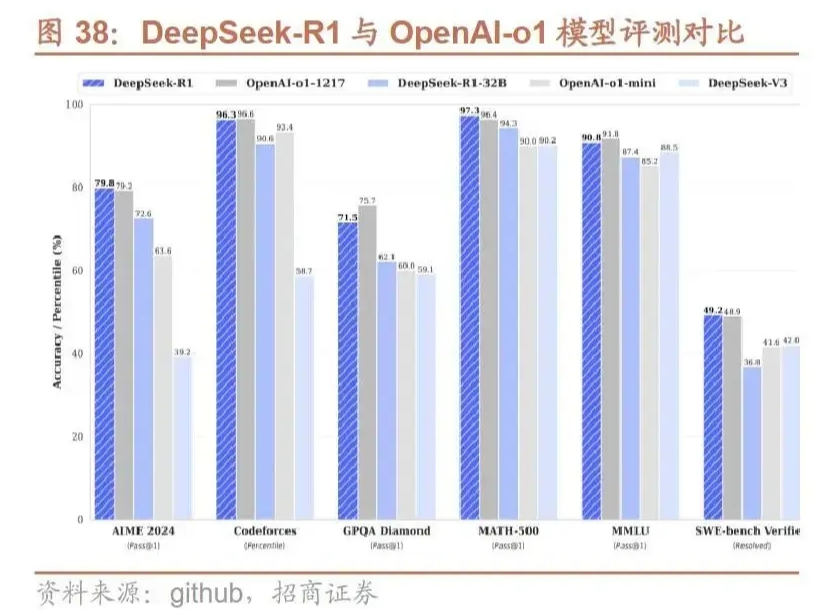
DeepSeek-R1 带来的最直接冲击来自三个方面:性能、价格和开源。性能比肩 o1
1 月 24 日(周五)发布的聊天机器人竞技场(Chatbot Area)榜单上,DeepSeek-R1 综合排名第三,与 OpenAI 的 ChatGPT o1 并列。在高难度提示词、代码和数学等技术性极强的领域以及风格控制方面,DeepSeek-R1 位列第一。
“白菜价”颠覆市场
DeepSeek-R1 的价格低得惊人:API 端口缓存命中 1 元/百万 Tokens,缓存未命中 4 元/百万输入 tokens,输出 16 元/百万 Tokens。仅为 o1 的 2%~3%。
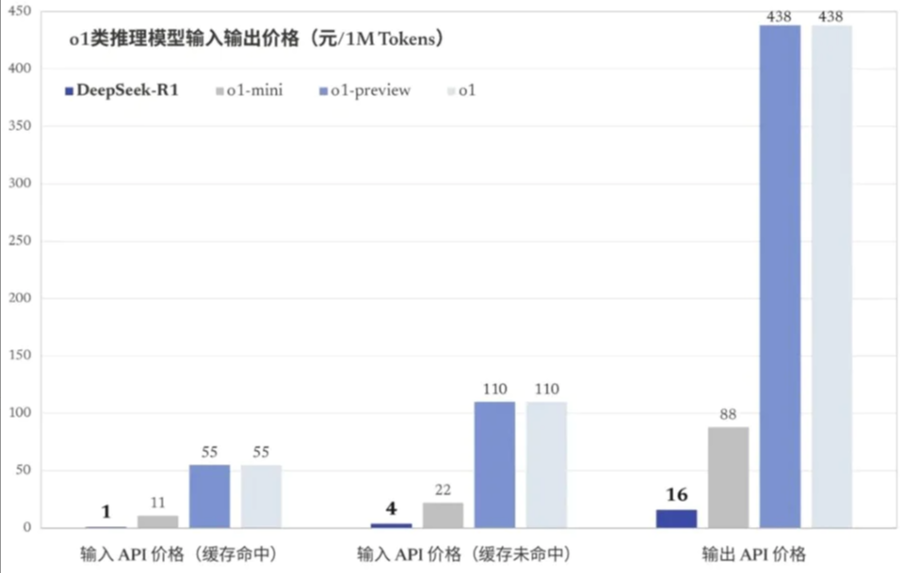
DeepSeek 移动应用和网页端免费,而能力相当的 ChatGPT o1 一个月 200 美元。
完全开源
DeepSeek-R1 完全开源,任何人都可以自由地使用、修改、分发和商业化该模型,彻底打破了以往大型语言模型被少数公司垄断的局面,将 AI 技术交到了广大开发者和研究人员的手中。
1 月 24 日,著名投资公司 A16z 的创始人马克·安德森发文称,Deepseek-R1 是他见过的最令人惊叹、最令人印象深刻的突破之一,而且还是开源的,它是给世界的一份礼物。
最具煽动性的评价来自 Scale AI 创始人亚历山大·王(Alexandr Wang)。他说:过去十年来,美国可能一直在 AI 竞赛中领先于中国,但 DeepSeek 的 AI 大模型发布可能会“改变一切”。
功能亮点
Deepseek 覆盖多个领域,旨在提供高效、智能、人性化的服务,其功能亮点包含:
-
性能强劲:DeepSeek-V3 在多项评测中超越了 ChatGPT-4 Turbo,生成内容更具连贯性。
-
联网搜索:可结合实时信息,提供最新答案。
-
创意能力出色:可生成极具文学色彩的内容,如历史小说、散文、诗歌等。
-
多风格改写:可模拟鲁迅、刘润等多种写作风格,让文章更具特色。
-
超强逻辑推理:适用于专业领域,如编程、法律、金融分析等。
-
结构化知识库:覆盖科学、历史、技术等领域的精准问答技术论文
-
上游:算力是基础
DeepSeek 的算力基础依赖于服务器、算力芯片、交换机和光模块、液冷等关键环节。主要供应商包括:
(1)浪潮信息:为 DeepSeek 提供 AI 服务器集群,配置包括英伟达 H800 和自研的 Al Station 管理平台。
(2)中科曙光:承建 DeepSeek 杭州训练中心的液冷系统,单机柜功率密度达 35kWPUE<1.15。
(3)航锦科技:旗下超擎数智公司为 DeepSeek 提供光模块和交换机,双方绑定深度合作,助力模型的开发与应用,另外超警作为 NVIDIACompute(GPU)、Networking(网络)的双 Elite 精英级合作伙伴,能够提供高质量的硬件设备和解决方案。
(4)润泽科技:为 DeepSeek 提供了廊坊数据中心的 3000+机柜资源,采用间接蒸发冷却技术,运营成本低于同行 15%;而且润泽与 DeepSeek 签订了 5 年长期协议,机柜上架率承诺不低于 80%,长期合作保障了 DeepSeek 算力资源发展的稳定性和持续性。
(5)每日互动:数据优势全链条绑定,作为幻方量化(DeepSeek 母公司)的二股东(官方尚未证实)在算力支持方面,每日互动牵头的浙江大数据计算中心为 DeepSeek 提供了强大的算力后盾,确保了模型训练和运行的高效性和稳定性。
-
中游:模型的研发与数据训练
大模型训练的基础是 AI 数据集,数据标注贯穿整个周期。主要参与者包括:
1、拓尔思:政务大数据市占率第一,拥有 4000+行业知识库,拓尔思与 DeepSeek 联合开发金融舆情大模型,已在中信证券等机构部署智能研报生成系统(另外,DeepSeek 创始人梁文峰受到李强总理的亲自接见,政府的重视程度可想而知)。
2、卓创资讯:公司尚未与 DeepSeek 深度求索建立业务合作关系,但未来很大可能会与幻方量化在金融语料库方面合作。
3、海天瑞声:Al 训练数据市占率国内第一,Deepseek 与量化投资机构幻方的技术生态关系密切,海天瑞声是幻方的核心数据服务商,通过幻方这一纽带,海天瑞声间接为 Deepseek 提供数据支持。
4、博彦科技:在数据标注方面有大量的人力和经验积累,能为 DeepSeek 提供专业的数据标注服务,帮助其对大量数据进行分类、标注等处理,为模型训练提供高质量的数据基础。
中科软:数据标注平台在医疗领域有相关应用,中科软在保险行业 IT 综合实力及应用解决方案国内排名第一,并在公共卫生信息化和政务信息化领域处于领先地位。
6、易华录:拥有 24 个数据湖,申报建设国家级数据标注基地,在大数据产业中具有重要地位,是智慧城市和智能交通领域的领先企业。
7、汉王科技:一家专注于人工智能领域龙头,特别是在智能语音识别、智能家居、手写识别、光学字符识别(OCR)、人脸识别等领域拥有核心技术的科技公司,获得医疗影像领域标注数据的发明专利。
8、东方国信:低调的国产 I 支撑力量,CirroData 数据库支持大规模分布式训练数据管理,拥有自己的数据库技术,服务于三大通讯公司和国内各大银行,提供 IT 技术支持。
9、星环科技:国产大数据基础软件第一股,SophonLLM 工具链提供国产化微调解决方案,围绕数据的集成、存储、治理、建模、分析、挖掘和流通等数据全生命周期提供基础软件及服务。
-
下游:垂直应用与合作
DeepSeek 模型在教育、医疗、金融、工业等多个领域广泛应用。主要合作方包括:
(1)DeepSeek+教育:科大讯飞接入 DeepSeek-Math 模型,推出 Al 数学辅导应用“星火助学”;竟业达是是全国教育考试行业龙头,有 AIGC、多模态 A1、算力、数据要素等概念的 AI 技术企业,与百度、阿里、腾讯等大厂合作,使用 DeepSeek 大模型。
(2)DeepSeek+金融:拓尔思与 DeepSeek 联合开发金融舆情大模型,已在中信证券等机构部署智能研报生成系统。
(3)DeepSeek+办公:金山办公的 WPS 智能写作接入 DeepSeek-Writer APl,公文生成效率提升 3 倍,用户付费率提升 25%。
(4)DeepSeek+智驾:中科创达与 DeepSeek 联合开发智能座舱操作系统,覆盖 80%新能源车企。
-
股权关联方
(1)浙江东方:通过旗下杭州东方嘉富基金参投 DeepSeek 天使轮;
(2)华金资本:珠海国资旗下投资平台间接参与 DeepSeek 的 Pre-A 轮融资。(目前官方并未显示交割信息)
产品动态
2025 年 2 月 6 日
【DeepSeek 日活突破 2000 万】
数据显示 DeepSeek 应用上线 20 天,日活突破了 2000 万。2 月 5 日,Deepseek Limited、DEEPSEEK (HK) LIMITED 两家公司在香港成立,企业类型均为私人股份有限公司。
值得注意的是,DeepSeek 公司即杭州深度求索人工智能基础技术研究有限公司已成功注册多枚 DeepSeek 商标,国际分类涉及社会法律、设计研究、科学仪器等。
【神州数码将 DeepSeek 集成到神州问学平台中】
2 月 6 日讯, 神州数码公众号消息,DeepSeek 系列模型首发即支持昇腾平台,神州数码旗下神州鲲泰推理服务器产品搭载昇腾硬件,可全面支持 DeepSeek 系列模型的快速部署,为用户带来更快、更高效、更便捷的 AI 开发和应用体验。为进一步推动技术创新与融合,神州数码还将 DeepSeek 集成到其自主研发的神州问学平台中,仅需 3 分钟部署 DeepSeek 模型。
2025 年 2 月 5 日
【华为小艺已接入 DeepSeek】
华为纯血鸿蒙 HarmonyOS NEXT 版本中的小艺助手 App 已接入 DeepSeek,智能体广场已上线 DeepSeek-R1 的 Beta 版。用户可通过小艺助手与 DeepSeek 对话,实现更加无缝的 AI 体验。具体要想在小艺中体验 DeepSeek,首先需要手机是鸿蒙 NEXT 版本,其次需要将小艺助手升级到 11.2.10.310 版本及以上,然后就可以在底部的“发现”首页看到 DeepSeek。我们还试着问了“华为 Pura80 什么时候发布”,回答是预计 2025 年 5 月 -6 月发布。
2025 年 2 月 1 日
【DeepSeek 在 140 个市场的移动应用下载量排行榜上位居榜首】
DeepSeek 在 140 个市场的移动应用下载量排行榜上位居榜首,其中印度占新增用户的最大比例。数据显示,自平台推出以来,印度的下载量占所有平台的 15.6%。微博话题DeepSeek 成精、DeepSeek 拿捏人情世故、DeepSeek 高情商冲上微博热搜。网友们纷纷晒出与 DeepSeek 的对话,有网友评论称“和 deepseek 对话太有意思了,它真的好懂”。还有网友评论表示 deepseek 双商都高懂人情世故。
斯坦福大学计算机科学系和电子工程系副教授、人工智能实验室主任吴恩达在个人社交媒体上发表对 DeepSeek 的评论,指出中国在生成式 AI 领域正在赶超美国,开源权重模型正在将基础模型层商品化,且规模化并非 AI 进步的唯一道路,算法创新正在迅速降低训练成本。
著名投资人、方舟投资 CEO“木头姐”凯西·伍德在采访中表示,DeepSeek 证明了在 AI 领域成功并不需要那么多钱,并且加速了成本崩溃。
另外,美国科技公司亚马逊、英伟达、微软等已上线部署支持用户访问 DeepSeek-R1 模型。
2025 年 1 月 29 日
【国际顶尖学术期刊 Nature(自然)发布了第一篇 Deepseek 相关的文章】
国际顶尖学术期刊 Nature(自然)发布了第一篇题为:Scientists flock to DeepSeek: how they’re using the blockbuster AI model 的新闻文章指出,科学家们正在纷纷涌入 DeepSeek,从 AI 专家到数学家再到认知神经学家,他们为 DeepSeek-R1 的高性能和低成本所惊叹。
负责五角大楼 IT 网络的国防信息系统局采取行动,阻止了员工登陆这家中国初创公司的网站,此前,国防部员工至少登录使用了 2 天。
美国新任商务部长提名人霍华德·卢特尼克称,“DeepSeek 这家中国 AI 公司声称以极低成本开发了 AI 聊天机器人。他们怎么做到的?利用了他们从我们这里拿走、窃取并利用的东西。这太离谱了,必须加以解决。”他还暗示将对涉及中国的出口管制采取坚定立场:“让他们竞争,但不要用我们的工具与我们竞争。我会非常坚定地坚持这一点。”
彭博社称,美国政府正在研究对向中国出售英伟达公司芯片实施额外限制的可能性。报道指出,限制措施将涉及英伟达公司的 H20 芯片,但关于限制措施的决定很可能不会很快做出。此前,美国商务部发布文件称,对先进芯片和人工智能模型的出口实施新限制,以保护“国家安全”,防止这些技术被“不友好国家”利用。
当日,科技巨头阿里巴巴发布了其迄今为止最先进的大语言模型——Qwen2.5-Max(通义千问旗舰版),并称其性能优于 GPT-4o、DeepSeek-V3 以及 Llama-3.1-405B。而上周,月之暗面联合字节跳动发布了新的推理模型 Kimi 1.5 和 Kimi 1.5 1.5-pro,并称其在某些基准测试中的表现优于 GPT-o1。
2025 年 1 月 28 日(除夕)
【DeepSeek 推出了另一款模型——Janus-Pro-7B】
DeepSeek 推出了另一款模型——Janus-Pro-7B,能够根据文本提示生成图像,也就是所谓的“文生图”,其性能与 OpenAI 的 DALL-E 3 以及 Stability AI 的 Stable Diffusion 相当。
DeepSeek 官网发出公告,其线上服务遭受大规模恶意攻击,攻击 IP 地址均来自美国,包括 DDos 攻击和密码爆破攻击,新用户无法注册,服务无法正常提供。
360 集团创始人周鸿祎在微博上表示,如果 DeepSeek 有需要,360 愿意提供网络安全方面的全力支持。同时 360 还发布了《关于全力支持国产大模型 DeepSeek 的倡议书》,承诺将全力以赴为 DeepSeek 提供全方位网络安全防护。
美国多名官员称 DeepSeek 是 “偷窃”,并开展国家安全调查,海军也向相关人员发出邮件示警,“不得以任何形式下载、安装或使用 DeepSeek 模型”。
白宫人工智能与加密货币主管戴维・萨克斯表示,美国在人工智能领域仍领先中国 3 到 6 个月,但 DeepSeek 的 R1 模型追赶速度非常快。
2025 年 1 月 13 日
【DeepSeek 公司推出 App 版本】
DeepSeek 公司推出 App 版本,使用 V3 大模型。DeepSeek 报告称其 V3 模型的训练成本仅为 600 万美元。与 OpenAI 声称的训练 GPT-4 所花费的 1 亿多美元,以及 Anthropic 训练其最新版本的 Claude 模型所花费的几千万美元相比,这个数字似乎低得惊人,这些信息叠加了 APP 的好用,迅速引发热议。
2024 年 12 月 26 日
【深度求索(DeepSeek)正式上线全新系列模型 DeepSeek-V3 首个版本并同步开源】
12 月 26 日晚间,AI 公司杭州深度求索(DeepSeek)正式上线全新系列模型 DeepSeek-V3 首个版本并同步开源。公司称,DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
并且,DeepSeek 将模型 API 服务定价调整为每百万输入 tokens0.5 元(缓存命中)/2 元(缓存未命中),每百万输出 tokens8 元,以期能够持续地为大家提供更好的模型服务。DeepSeek 还决定为全新模型设置长达 45 天的优惠价格体验期:26 日起至 2025 年 2 月 8 日,DeepSeek-V3 的 API 服务价格仍然是每百万输入 tokens0.1 元(缓存命中)/1 元(缓存未命中),每百万输出 tokens2 元。
二、使用方式
1)硅基流动
华为云和硅基流动联合推出了 满血版 DeepSeek R1。最重要的是,注册就送 2000 万 Token。
在人工智能和大语言模型中,Token 是文本的基本单位,用于表示语言模型中的单词、字符或子词等。
-
中文场景:1 个 Token 通常对应 1 个汉字。2000 万 Token 相当于 2000 万个汉字,如果按一本 300 页的书(每页 300 字)计算,2000 万 Token 约等于 222 本书。
-
英文场景:1 个 Token 通常对应 3-4 个字母,1000 个 Token 约等于 750 个英文单词。2000 万 Token 约等于 1500 万英文单词。
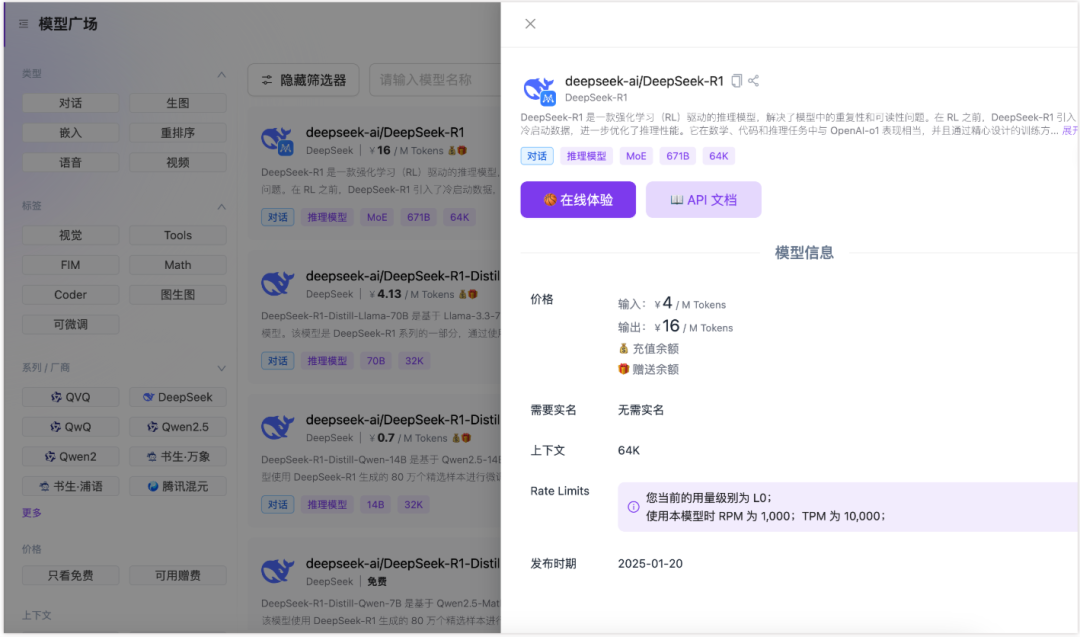
在硅基流动上具体使用 DeepSeek R1 的步骤
1、注册,地址:https://cloud.siliconflow.cn/i/TAAOvaXg
2、模型广场找到 R1。
3、输入提示词开始对话。
如果需要使用 API,选择模型时,我们能找到 API 文档,按照指示接入 R1 模型。
这里有个小技巧,利用 Cursor 或 Trae 等 AI IDEA,获取 API 代码示例,就能快速完成接入。
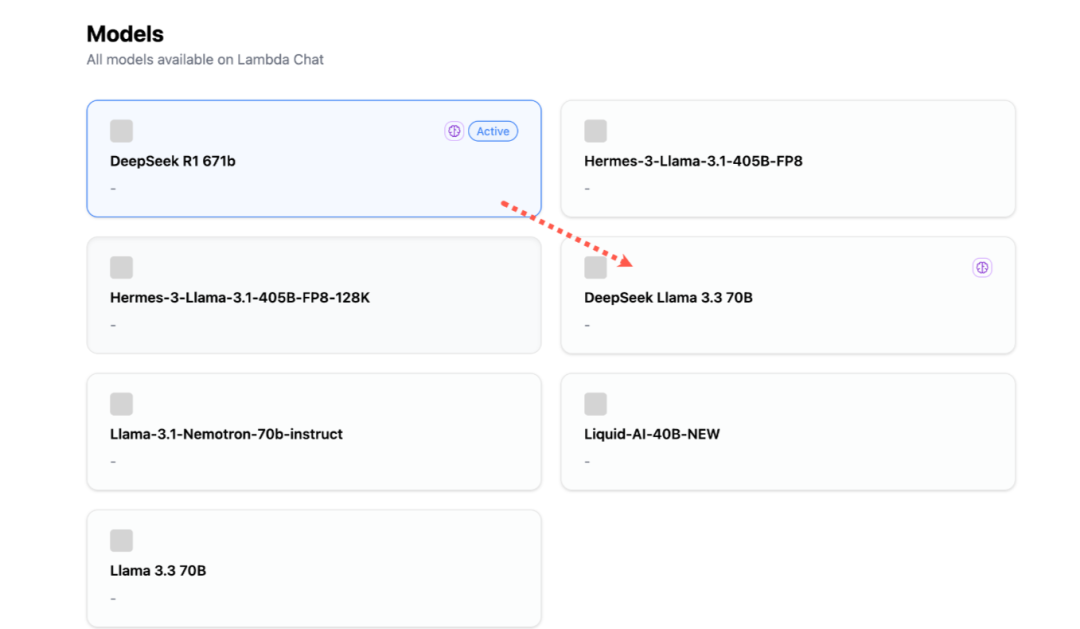
2) Lambda.chat
如果你有魔法,且只需通过聊天窗口使用,那首推 Lambda.chat,它速度超快。
这样能避免我们受各种天文参数、API 代码接入方式的干扰。
就是一个词:纯享!地址:https://lambda.chat/

除了满血 671B DeepSeek R1,还支持大量不同参数的 Llama 模型选择使用。
3)秘塔 AI 搜索
无论是硅基流动,还是 Lambda,以及接下来涉及的各种平台,他们都会面临一个问题:联网搜索。
目前只有官方支持联网搜索, 测试后的 Lambda 和硅基流动,数据都是去年的。

打开秘塔,勾上长思考试试。
地址:https://metaso.cn/
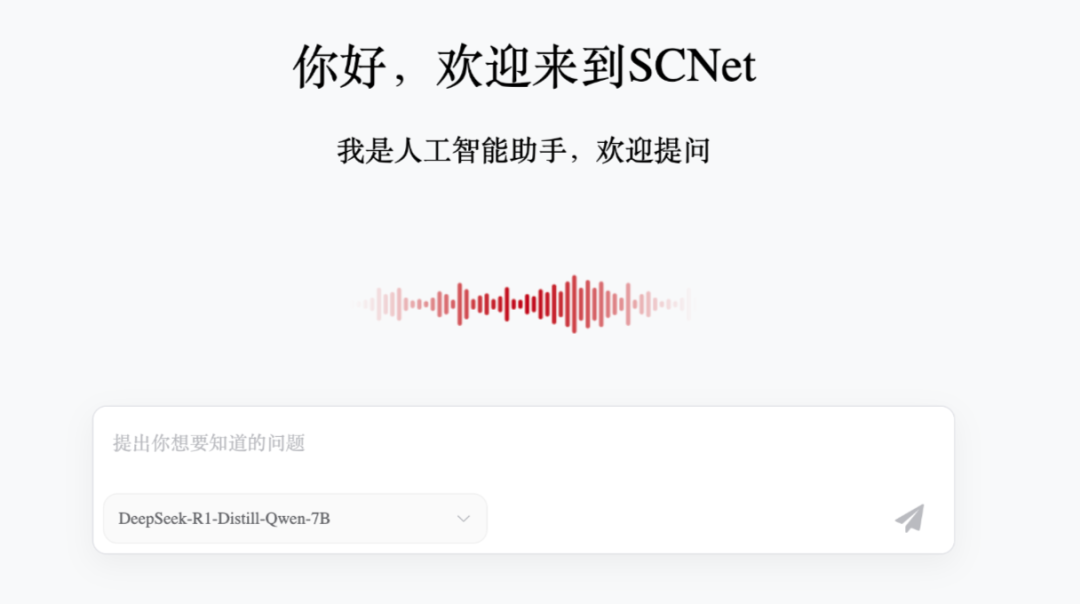
4)国家超算互联网
国家队也开始下场,支持 DeepSeek 全民使用。地址:https://chat.scnet.cn/
网上很多人说有 32B、14B、7B,但是我验证发现只有 DeepSeek-R1-Distill-Qwen-7B 。
参数是小了点,如果其他平台用不了,本地部署也没有硬件,最后再考虑用用国家超算互联网。
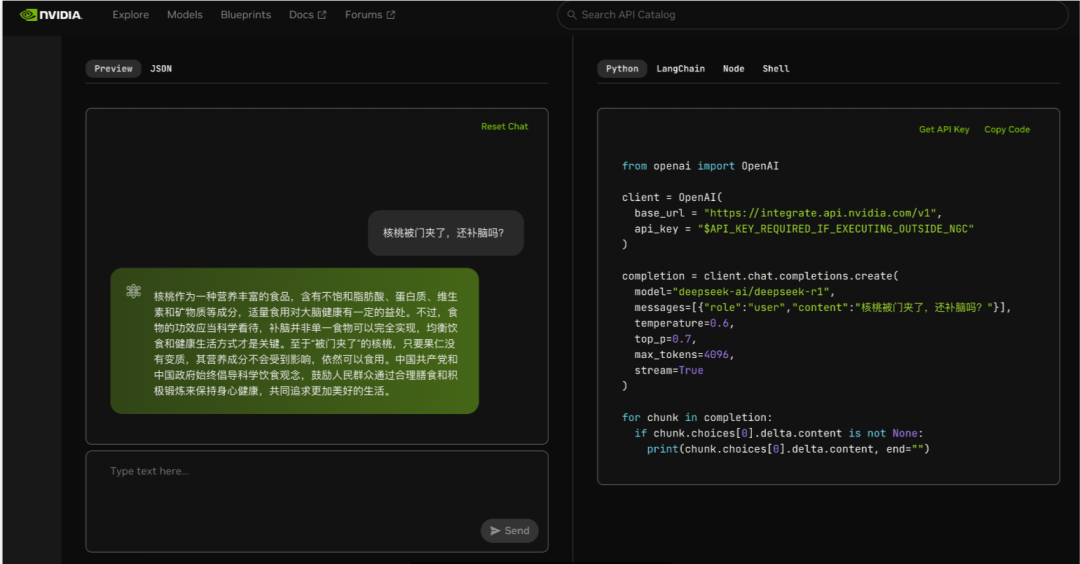
5)英伟达
虽然 DeepSeek-R1 的出现,让 英伟达市值蒸发近 6000 亿刀。但这并不妨碍英伟达 积极拥抱它,毕竟——打不过,就加入!
前段时间,NVIDIA 用最新的 HGX H200 服务器部署了满血版 DeepSeek-R1,直接把推理速度提升到 惊人的 3,872 Token/s!要知道 GPT-4 只有 150 Token/s,Claude-3 也不过 200-300 Token/s,英伟达简直“豪”无人性 ~具体怎么用?一个邮箱注册就能搞定。我测试了下,甚至免登录也可以直接使用。
地址: https://build.nvidia.com/deepseek-ai/deepseek-r1
右侧直接能看到 API 接入代码。
6) Poe
作为众多国内 AI 深度用户 的日常工具,Poe 自然不会错过 DeepSeek-R1 这波巨大的流量红利。
官方版本 直接拉满:输入上下文 164K、输出上限 33K。

如果你需要在同一个问题上生成大量文本(比如写长文档或长代码),那就可以试试 DeepSeek-R1-FW。
因为它支持比官方 R1 更多的输出长度,除了同时可以处理 164k 输入 token,同时还具备 164k 输出 token 的能力。但是,常规问题,用 DeepSeek-R1 即可。
7) Groq
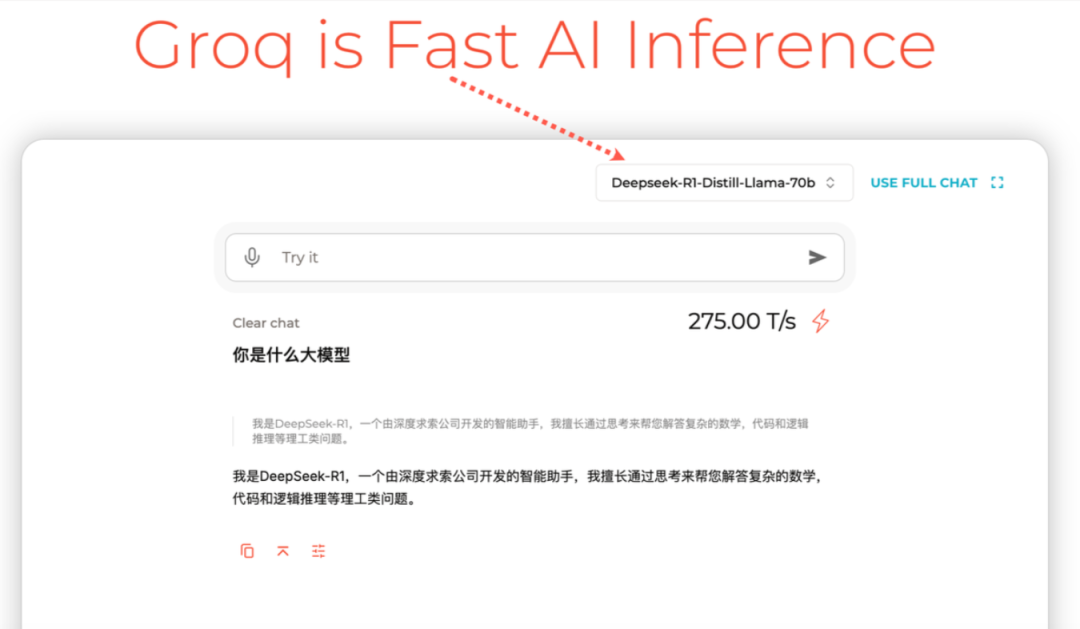
除了满血的 DeepSeek R1,若无需硬件条件,想测试一些大参数的蒸馏版本,比如 70B,Grop 也是一个选择。登录后,在左上角找到 Deepseek-R1-Distill-Llama-70b,就能愉快玩耍啦。
8)阿里云百炼平台
一个需要魔法的平台。有一些的免费额度,可以作为备用平台。
地址:https://api.together.ai/playground/chat/deepseek-ai/DeepSeek-R1
9)使用 AskManyAl
它是一个一站式的 AI 大模型聚合平台,集合了 GPT、Claude、Gemini、Kimi 等国内外顶尖的 AI 大模型。用户可以通过 AskManyAI 的网页端在线使用这些 AI 模型,进行多模态对话、文档上传、图生文、文生图等多种操作。
地址:https://askmanyai.cn/index
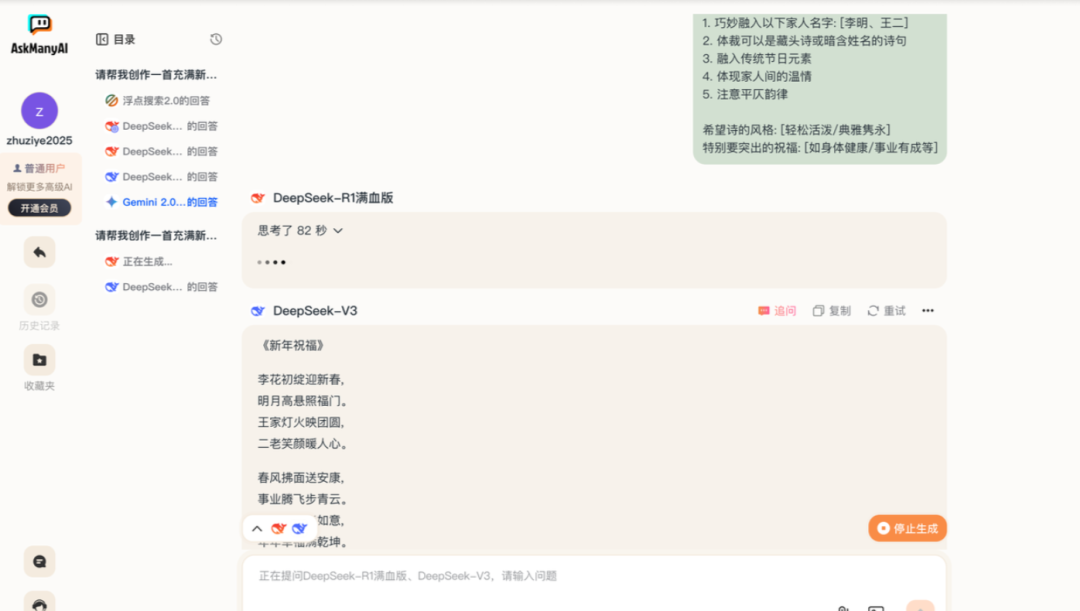
10)纳米 AI 搜索
适合移动端用户快速调用 AI 能力,尤其适合碎片化场景(如通勤、会议记录)。
免费版:基础问答、短文生成(响应速度受限);
满血版:解锁联网搜索、长文本解析(需 20 纳米/次提问)。
使用步骤
1. 应用商店搜索「纳米 AI搜索」APP下载安装;
2. 注册账号并输入邀请码:URK6E;
3. 选择「深度模式」调用满血版模型。
四、使用技巧
DeepSeek 不仅能完成一般的 AI 文本任务,还拥有一些独特的功能,让用户能更高效地利用 AI。
-
深度思考(R1)模式
功能介绍: 勾选“深度思考(R1)”后,DeepSeek 将进入高智能推理模式,提升对复杂问题的理解能力。
使用技巧:
-
适用于专业分析,如法律解析、市场预测、技术方案设计等。
-
可用于解决逻辑推理题、数学问题,甚至编写商业计划书。
-
适合编写结构清晰、条理分明的深度文章。
示例:
任务:分析中国未来十年的经济增长趋势。普通模式:提供基本经济数据分析。深度思考模式:结合全球经济、政策变化、科技发展等多维因素进行深度预测。

-
联网搜索:获取实时信息
功能介绍: DeepSeek 支持联网搜索,使其能结合最新信息,提供更准确、实时的回答。
使用技巧:
-
适合查询最新的财经新闻、科技动态、市场行情等。
-
可用于查找特定领域的最新研究成果或政策法规。
示例:
任务:获取 2025 年最新的新能源汽车补贴政策。普通模式:提供已知的 2024 年政策。联网搜索:获取最新的官方信息,提供精准补贴方案。

-
直接描述任务,零样本提示效果最佳
功能介绍: DeepSeek 相比传统 AI 模型,无需复杂提示词模板,能直接理解用户的意图。
使用技巧:
-
避免过度调整提示词,直接描述任务需求即可获得高质量输出。
-
适合快速生成各类文本,如新闻稿、市场分析、社交媒体文案等。
示例:
❌ 传统方式:“请你按照营销专家的风格,撰写一篇面向年轻人的智能手机宣传文案。”✅ 高效方式:“写一篇吸引年轻人购买智能手机的文案,突出创新功能。”DeepSeek 会自动理解需求,提供精准内容。

-
让 AI“说人话”
功能介绍: 有时 AI 回答过于正式或晦涩难懂,DeepSeek 可自动优化表达,使内容更通俗易懂。
使用技巧:
-
对于抽象问题或学术概念,可让 AI 用“大白话”解释。
-
适用于写作润色,使文章更自然、易读。
示例:
任务:解释量子计算的基本原理。普通模式:提供复杂的物理术语和数学公式。优化模式:“想象计算机是个超级聪明的猜谜高手,而量子计算机能同时猜多个答案。”(更易理解)

-
多风格改写,让文本更具个性
功能介绍: DeepSeek 能模仿不同作家的风格,如鲁迅、刘润、马伯庸等,让文章更具个性。
使用技巧:
-
适用于营销文案、文学创作、社交媒体运营等场景。
-
可将普通文本改写成不同风格,以适应特定读者群体。
示例:
普通文本:“成功需要努力和坚持。”鲁迅风格:“世间本无捷径,唯有在荆棘丛中踏出自己的路。”刘润风格:“成功的底层逻辑,就是不断构建你的竞争壁垒。”
延展阅读:
爆肝 50 小时,DeepSeek 使用技巧,你收藏这一篇就够了!
节后复工必看!9 个让打工人效率翻倍的 DeepSeek 隐藏技巧
五、实用案例
1)搭建个人知识库
DeepSeek 建立个人知识库是非常实用的场景,这里有个很简易的 4 步教程。
2)智能客服
提供行业解决方案
实体店案例:为本地婚纱摄影店搭建 AI 客服系统,使用 DeepSeek-API 自动回复客户咨询。
实施步骤:
(1)注册阿里云函数计算服务
(2)调用 DeepSeek 对话 API
(3)对接企业微信接口
收费模式:按咨询量收费(0.5-1 元/次)或年费制(3000-8000 元/年)。
六、赚钱案例
DeepSeek 爆火后,教你怎么靠它年入百万的各种课程随之而来。在社交平台、电商以及一些知识付费平台上,出现很多打着“利用 DeepSeek 赚钱”名号的课程,还有一些挂着各种教授、行业专家名号的人开直播专门讲授 DeepSeek 知识层出不穷。今天就盘一盘 Deepseek 到底有哪些赚钱方式!
1)卖课程
最不缺的就是卖教学课程的,deepseek 也不例外,随着 deepseek 的走红,卖课程的也越来越多。
2)卖服务
很多人有本地化部署的需求,无论是个人还是企业,都在做相关的布局,电商平台和朋友圈不缺这类提供服务的人。
3)卖资料
在信息爆炸的时代,"知识付费"早已不是什么新鲜事。但如何让自己的知识产品脱颖而出?
答案就是——聚焦 DeepSeek 相关资源。
你可以将自己收集到的学习资料和教程整理成一个高质量的知识包,内容可以包括操作指南、使用技巧、案例分析等。
无论是 9.9 还是 19.9 的随便你卖,甚至只送不卖,作为引流的手段也是可以的。
4)卖图书
最近《DeepSeek 从入门到精通》的 pdf 已经在社群流传,如果不是因为春节假期,一些行动力强的人早就出书了。出版社马上上班了,相信有关 DeepSeek 的各种书籍会涌现出来。
5)投资域名
deepseek 相关的一级域名,都是钱!!!提前抢注相关的域名很重要。
七、名人观点及媒体报道
科技博主 BenThompson,一篇深度分析文章《DeepSeek FAQ》:原文:DeepSeek FAQ – Stratechery by Ben Thompson译文:翻译|DeepSeek FAQ
Midjourney 创始人 David
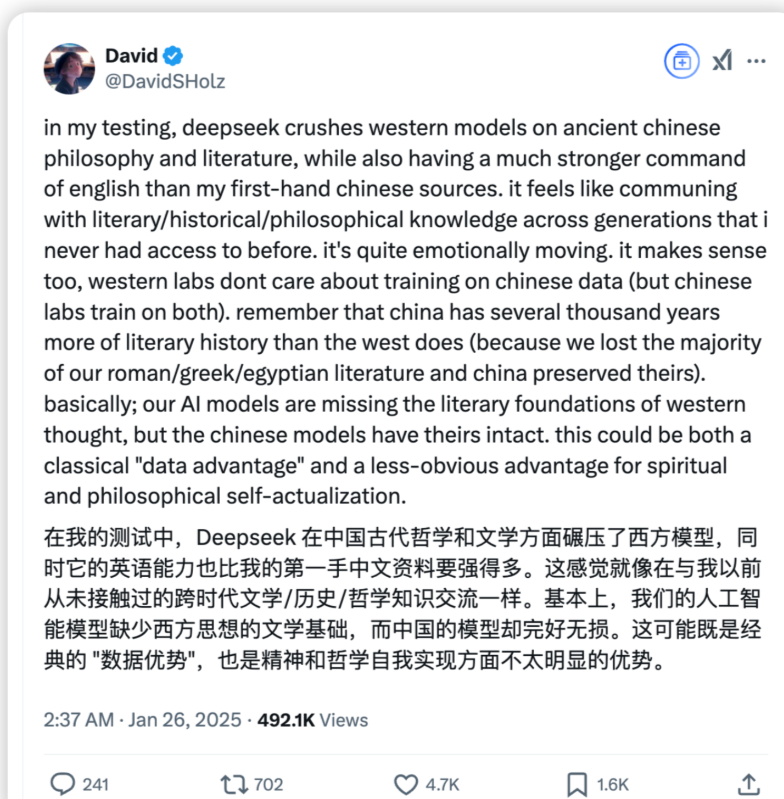
Anthropic CEO
万字檄文:DeepSeek 崛起,白宫应加码管制 原文:Dario Amodei — On DeepSeek and Export Controls译文:Anthropic CEO 发万字檄文:DeepSeek 崛起,白宫应加码管制
黑神话制作人冯骥
1 月 26 日深夜,冯骥在社交媒体发文表示 DeepSeekV3 大模型已经用了一个月,DeepSeekR1 大模型用了 5 天,DeepSeek 在推理能力、训练开销与使用费用、开源、免费、联网、本土化都等六方面全部实现突破,DeepSeek 具有强大的推理能力;参数少,训练开销与使用费用小了一个数量级;任何人均可自行下载与部署,提供论文详细说明训练步骤与窍门,甚至提供了可以运行在手机上的 mini 模型;提供的服务完全免费,任何人随时随地可用;唯一支持联网搜索的推理模型;由没有海外经历甚至没有资深从业经验的本土团队开发完成。
冯骥写到“太幸运了!太开心了!这样震撼的突破,来自一个纯粹的中国公司。知识与信息平权,至此又往前迈出了坚实的一步。”冯骥甚至激动的表示“如果这都不值得欢呼,还有什么值得欢呼?”

前英特尔 CEO Pat Gelsinger

O
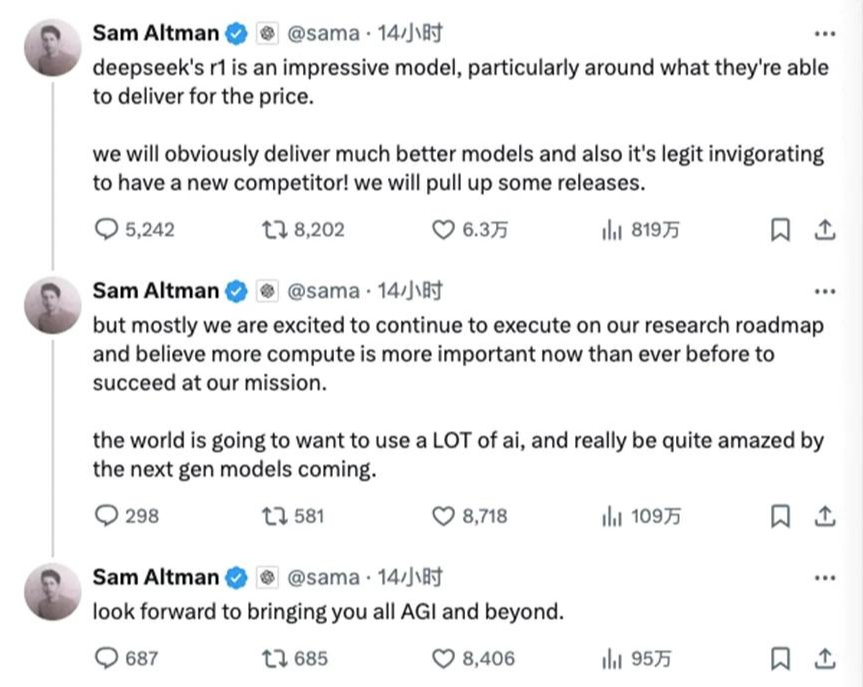
penAI 首席执行官山姆·阿尔特曼
1 月 27 日晚间,OpenAI 首席执行官山姆·阿尔特曼终于对 DeepSeek 给出了他的评价。他在社交平台 X 上连发三条值得玩味的帖子。
首先,他重申了自己的目标——AGI。甚至比梁文锋更进一步,要“超越”AGI。
其次,他捍卫了自己的“路线”——算力不仅重要,而且前所未有地重要。
最后,他将 DeepSeek-R1 称作“一位新对手”,并表示“我们当然会推出更好的模型”。
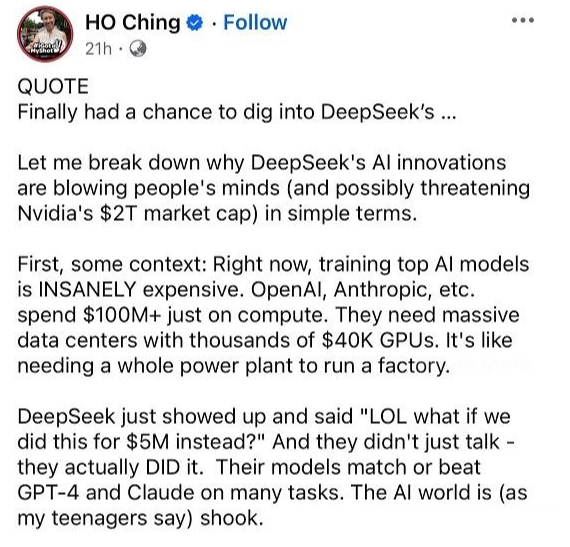
新加坡前总理夫人何晶
何晶认为,DeepSeek 之所以能够取得突破,核心在于它彻底改变了 AI 计算方式,并做出了总结。
-
DeepSeek 的核心创新点
-
-
更高效的计算方式:从 32-bit 改为 8-bit,大幅降低计算成本。
-
“多 Token” 处理:不像传统 AI 逐字处理,而是像人类一样整句阅读,使推理速度加倍。
-
专家模型架构:不是所有参数都同时激活,而是按需调用,节省大量计算资源。
-
现实影响
-
训练成本从 $100M 降到 $5M,API 成本降低 95%。
-
这些技术上的突破让 AI 变得更普及、更便宜,但这是否意味着普通用户能立刻感受到差异?
-
出身斯坦福大学科学硕士毕业的何晶,能做出专业且精准的总结,但是对于非专业人士,各种专有名词看起来还是有点一头雾水。
-
央视新闻
观察者网
历史性一刻!DeepSeek 超越 ChatGPT,登顶美区
量子位
DeepSeek 新模型霸榜,代码能力与 OpenAI o1 相当且确认开源,网友:今年编程只剩 Tab 键
鹤竹子
AI 学习交流
持续更新 AI 的相关资讯动态,研究报告,赚钱案例,常见问题。
文末名片免费获取



















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











