







杭州深度求索(DeepSeek)人工智能基础技术研究有限公司,是一家成立于2023年7月的中国人工智能初创企业,总部位于浙江省杭州市。该公司由量化对冲基金幻方量化(High-Flyer)的联合创始人梁文锋创立,致力于开发开源大型语言模型(LLM)及相关技术。
此前,DeepSeek 并不为大众所熟知,但最近其发布的新人工智能模型 DeepSeek-R1 在全球科技界引起了巨大反响。该模型的能力被认为可与谷歌和 OpenAI 的先进技术相媲美。根据上周(即2025年1月22日)发布的研究论文,DeepSeek 团队在训练该模型时仅花费了不到 600 万美元的计算成本,这一数字远低于 OpenAI 和谷歌(ChatGPT 和 Gemini 的开发者)数十亿美元的人工智能预算。因此,硅谷知名风险投资家马克·安德森(Marc Andreessen)将这一突破称为“人工智能的斯普特尼克时刻”。“斯普特尼克”一词源自1957年苏联发射的世界首颗人造卫星“斯普特尼克1号”(Sputnik 1),它曾震惊美国并推动了美国航天和科技的快速发展,最终促成了阿波罗登月计划(Apollo Program)的创立。DeepSeek 作为一家中国小型初创公司,能够与硅谷顶尖企业竞争,挑战了美国在人工智能领域的主导地位,并引发了对英伟达、Meta 等公司高估值的质疑。本周周一,英伟达股价暴跌 17%,市值蒸发近 6000 亿美元,该公司在生成人工智能所需的半导体领域几乎处于垄断地位。摩根士丹利认为,DeepSeek的成功可能会激发一波AI创新浪潮。美国“元”公司首席AI科学家杨立昆在社交媒体上发文说,Deep-Seek-R1的面世,意味着开源模型正在超越闭源模型。美国总统唐纳德·特朗普上周宣布启动一项价值 5000 亿美元的人工智能计划,由 OpenAI、甲骨文(总部位于德克萨斯州)和日本软银集团牵头。特朗普表示,DeepSeek 应该成为“警钟”,提醒美国工业界需要“全神贯注于竞争以赢得胜利”。
本文旨在避开政治和社会层面的喧哗,专注于从技术角度剖析 DeepSeek 的核心创新,以及它为何能够在短期内,在生成人工智能领域取得如此显著的成功。
自 2024 年以来,DeepSeek 共发表了 8 篇DeekSeek相关的科技论文,其中三篇尤为关键,揭示了其技术核心以及在人工智能技术创新和实际应用中的重大突破:
-
DeepSeek-LLM:以长期主义推动开源语言模型扩展
该论文于 2024 年 1 月发布,从长期主义的角度提出了开源语言模型的发展策略,旨在推动技术民主化。论文提出了社区驱动的开源治理框架和多任务优化方法,为开源生态的可持续发展提供了理论支持。 -
DeepSeek-V3:高效的混合专家模型
2024 年 12 月发布的这篇论文,提出了一种高效的混合专家模型。该模型通过仅激活少量参数,在性能和计算成本之间实现了优化平衡,成为大规模模型优化领域的重要突破。 -
DeepSeek-R1:通过强化学习提升大型语言模型的推理能力
2025 年 1 月发布的这篇论文,提出了一种基于强化学习而非传统监督学习的方法,显著提升了语言模型在数学和逻辑推理任务中的表现。这一成果为大型语言模型的研究开辟了新的方向。
这三篇论文集中体现了 DeepSeek 在技术创新和实际应用中的核心贡献,展示了其如何通过开源策略、模型优化和新学习方法推动人工智能领域的发展。
1. DeepSeek-LLM:以长期主义扩展开源语言模型
2024年1月,DeepSeek大语言模型团队在《以长期主义扩展开源语言模型》 (LLM Scaling Open-Source Language Models with Longtermism)论文中提出从长期主义角度推动开源语言模型的发展,重点研究了大语言模型的规模效应。他们基于研究成果开发了DeepSeek Chat,并在此基础上不断升级迭代。

图1,DeepSeek 2024年发布的大语言模型(DeepSeek-LLM)论文
1.1 背景与目标
近年来,大型语言模型(LLM)通过自监督预训练和指令微调,逐步成为实现通用人工智能(AGI)的核心工具。然而,LLM 的规模化训练存在挑战,尤其是在计算资源和数据分配策略上的权衡问题。DeepSeek LLM 的研究旨在通过深入分析模型规模化规律,推动开源大模型的长期发展。该项目探索了模型规模和数据分配的最优策略,并开发了性能超越 LLaMA-2 70B 的开源模型,尤其在代码、数学和推理领域表现卓越。
1.2 数据与预训练
1.2.1 数据处理
文章处理了包含 2 万亿个 token 的双语数据集(中文和英文)。采取了去重、过滤和重新混合三阶段策略,以提高数据多样性和信息密度。使用 Byte-level Byte-Pair Encoding(BBPE)分词算法,词表大小设置为 102,400。
1.2.2 模型架构
微观设计:借鉴 LLaMA 的架构,采用 RMSNorm 和 SwiGLU 激活函数,以及旋转位置编码。
宏观设计:DeepSeek LLM 7B 具有 30 层,而 67B 增加至 95 层,并通过深度扩展优化性能。
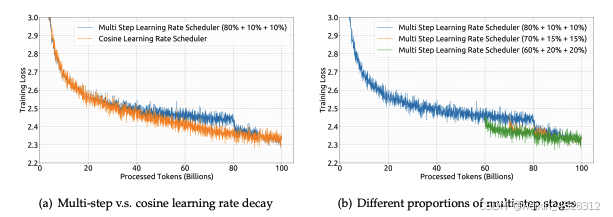
1.2.3 超参数优化
作者引入多阶段学习率调度器,优化训练过程并支持持续训练。使用 AdamW 优化器,并对学习率、批次大小等关键超参数进行了规模化规律研究。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5181
5181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









