







时间序列与统计方法
时间序列分析和统计方法是在处理时间相关数据时常用的技术,坦白来讲,在当前场景的许多实际应用中,简单的统计模型仍然具有相关性并适合企业面临的问题,特别是在供应链分析领域。原因是:
- 缺乏理论上的可用数据:除了直接需求数据之外,大多数公司仍然没有影响其直接需求数据的外部因素数据,例如,促销数据或营销活动数据或天气数据或影响需求的任何特定领域数据。但一旦数据变成单变量,统计方法就有很大机会优于深度学习方法
- 缺乏必要的硬件设施:深度学习模型需要较长的运行时间来生成预测并需要昂贵的 GPU 来进行计算,当然业界大公司已经进行了云迁移来进行模型计算,但对于中小型企业来说传统模型仍有其应用价值。
深度学习方法在未来可能会主导时间序列预测,但要想产生良好的预测结果,必须充分理解时间序列的统计性分析。
在传统时间序列的统计方法中,我们通常使用:
-
描述性统计分析: 通过计算均值、方差、标准差等指标来描述时间序列的基本特征。这可以帮助你了解数据的中心趋势和离散程度。
-
趋势分析: 用于检测和描述数据中的长期趋势。线性回归、移动平均和指数平滑是一些常用的趋势分析方法。
-
周期性分析: 识别时间序列中的周期性模式。傅里叶变换和周期图分析是用于检测周期性的工具。
-
季节性分析: 针对周期性出现在特定季节的模式进行分析。季节性调整可以帮助更好地理解数据的变化。
-
自回归移动平均模型(ARMA): 一种基于时间序列过去值和误差的统计模型,用于预测未来的值。
-
自回归积分移动平均模型(ARIMA): 是ARMA模型的扩展,包括对时间序列差分的处理,以便使其平稳。
-
季节性自回归积分移动平均模型(SARIMA): 是ARIMA模型的季节性扩展,适用于具有季节性变化的时间序列。
-
协整分析: 用于处理多个相关但非完全共线的时间序列。协整关系可以帮助理解多个时间序列之间的长期关系。
-
小波变换: 小波变换可以将时间序列分解成不同尺度的成分,有助于检测变化的局部特征。
来分析和模拟时间序列。
时间序列与深度学习方法
在时间序列预测领域,许多深度学习(DL)算法近年来已经崭露头角。其中值得注意的是RNN模型(诸如 LSTM, GRU等)、针对单变量的TCN 模型,Deep AR+(亚马逊开发的将深度学习与概率预测相结合的算法)、有效进行多元概率预测的Informer(Are Transformers Effective for Time Series Forecasting?) 等。
事实上,如果在kaggle比赛中我们可以发现尽管所有顶级解决方案都是使用 ML或DL 模型的组合完成的,但其中一般性的 ML或DL 模型方法其实并没有传统统计模型的效果好。事实是,在我们考虑ML或DL 模型建模时,并不是随便将数据输入随机挑选的一个机器学习模型就可以得到很好的模型结果,好的模型结果来自于:
- 可用且有效的数据:其实和上述结合起来就是,可用且有效的多源数据,例如在关于经典时序数据建模《M5 accuracy competition: Results, findings, and conclusions》也提到了,多源数据可以有效提高模型性能。
- 明显符合实际业务和技术场景的模型:比如M5 中也提到了LightGBM在这次比赛中的重要性,并且我们可以看到LightGBM在很多关乎实际场景的多元时序预测的kaggle比赛中都夺得了头筹。
- 合理的时间序列分析及时序信息挖掘。
对于技术背景的数据工作者,进行时序数据预测工作的一个常见问题,即进行完建模后,在技术逻辑没有问题的情况下,模型可能依旧不能取得良好的效果。这其实就是我们今天想说的。即使在现在,要想产生良好的预测结果,必须充分理解时序统计方法。所以在这里我们先不会像一般时间序列文章,马上介绍一般性时间序列统计算法,诸如ARIMA,而是首先从时间序列成分中理解时间序列的各部分关系,以及讨论实际应用场景中简单但有用的时间序列统计方法,并为之后各种时序模型的讨论做一个小小的铺垫。
ETS(误差趋势季节性)模型
介绍
ETS 模型是一种用于时间序列分析和预测的统计模型,它考虑了时间序列的误差项(Error)、趋势(Trend)和季节性(Seasonality)。“ETS” 代表 Error-Trend-Seasonality,这三个组成部分是 ETS 模型的核心。通过分解时间序列,将数据拆分成三个主要组成部分,即误差项(Residuals)、趋势(Trend)和季节性(Seasonality)。这种分解有助于更好地理解时间序列的结构和模式。
-
误差项(Residuals):误差项是时间序列中不能被趋势和季节性解释的剩余部分。它反映了时间序列中的随机波动和未知因素。在建立模型时,我们希望误差项是随机的,没有明显的模式。
-
趋势(Trend):趋势是时间序列中长期变化的部分。它反映了数据在较长时间内的整体趋势,可以是上升、下降或保持稳定。趋势分析有助于理解时间序列的长期走势,提供对未来走势的一定预测能力。
-
季节性(Seasonality):季节性是时间序列中周期性的、重复出现的模式。这些周期性模式通常与季节、月份、星期或其他时间单位有关。季节性分析有助于捕捉数据在特定时间段内的周期性变化。
将时间序列分解成误差项、趋势和季节性的组成部分,可以用数学方法实现,例如使用移动平均、指数平滑、分解法(如STL分解)等。
ETS模型基本结构
根据结合方法,我们可以建立加法模型和乘法模型。
- 加法模型(Additive Model):
在加法模型中,趋势、季节性和误差被看作是独立的组成部分,最终预测是这些部分的总和。
典型的加法模型公式为:
预测值=趋势+季节性+误差
- 乘法模型(Multiplicative Model):
在乘法模型中,趋势、季节性和误差相互影响,最终预测是这些部分的乘积。
典型的乘法模型公式为:
预测值=趋势×季节性×误差
在季节性乘法和加法中,选择使用哪一种取决于数据的特性。一般来说,如果季节性波动的幅度与趋势相对稳定,可以考虑使用加法模型。如果季节性波动的幅度随着趋势的增长而增加或减小,可能更适合使用乘法模型。
ETS基本结构组成
不同性质的时间序列,包括具有趋势和季节性的序列,如果考虑到趋势和季节性对时间趋势的综合影响,我们可以使用Holt-Winters方法。Holt-Winters方法是一种用于时间序列分析和预测的方法,它是对简单指数平滑的扩展,考虑了趋势和季节性成分。该方法主要用于处理具有趋势和季节性模式的时间序列数据。Holt-Winters方法包含三个主要组成部分:水平(Level)、趋势(Trend)和季节性(Seasonality)。
ETS 模型的具体形式根据误差,趋势,季节性三个组成部分的结合方式而有所不同,主要分为以下几种:
ETS(N, N): 表示模型没有趋势和季节性,那么无需考虑Holt-Winters方法,可以使用简单的指数平滑来模拟时间序列。
ETS(N, A): 表示模型无趋势和有加法季节性,那么可以考虑使用季节性指数平滑方法。在这种情况下,季节性波动在时间上是相对稳定的,但没有整体的趋势性增长或减小。一种常见的方法是季节性指数平滑(Seasonal Exponential Smoothing),该方法通常是Holt-Winters方法的季节性版本。季节性指数平滑适用于具有固定周期性波动的时间序列,其中季节性成分的影响在不同时间点是相对稳定的。如果时间序列具有季节性但没有趋势,可以考虑使用季节性指数平滑方法。在这种情况下,季节性波动在时间上是相对稳定的,但没有整体的趋势性增长或减小。
季节性指数平滑的基本思想是对每个季节性周期应用指数平滑,并在每个周期内更新季节性因子。模型的递推公式如下:

ETS(N, A): 表示模型有加法趋势,无季节性,可以考虑霍尔特线性方法。与完整的Holt-Winters方法相比,霍尔特线性方法主要关注趋势的估计,而不考虑季节性。

ETS(A, A): 表示误差项(Error),趋势(Additive Trend)和季节性(Additive Seasonality)中,模型包含误差项、加法趋势和加法季节性。

ETS(A, M): 表示模型包含误差项、加法趋势和乘法季节性。
其中,“A” 表示加法(Additive),“M” 表示乘法(Multiplicative)。这些标记描述了趋势和季节性的性质。

总结趋势性和季节性结合方法,可以为:
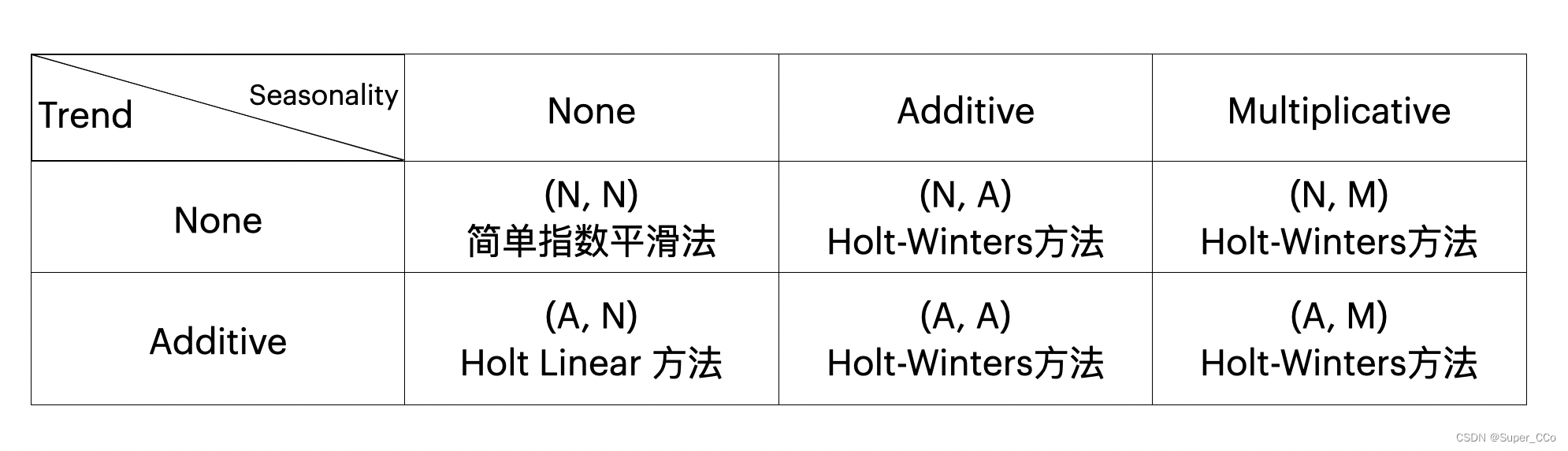
这里没有提到乘法趋势方法是因为乘法趋势方法极其不稳定,预测结果很差。因此我们也会发现它们不包含在 R & Python 的 ETS 实现包中。
注意
ETS 中需要理解的一个重要概念是何时使用加法模型以及何时使用乘法模型。
当季节性成分恒定时,加法模型效果最佳;当季节性成分在整个数据系列中不断变化时,乘法模型效果最佳。简单演示如下: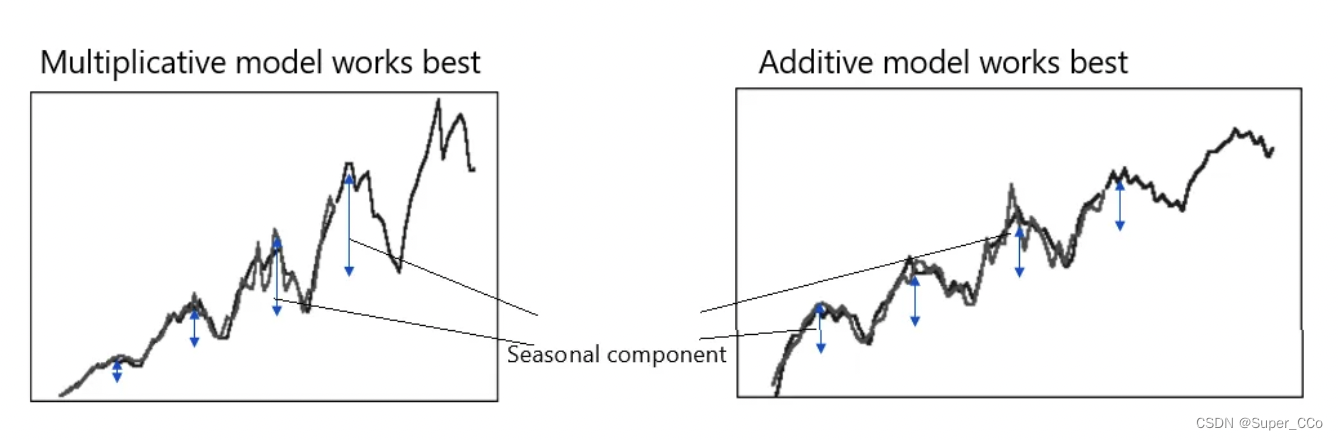
需要注意的重要一点是,乘法方法仅在数据严格为正时才有效。因此,如果需求数据为零,乘法模型就不起作用。一种出色的解决方法是用非常小的数字(例如 .1/.01 等)替换零。这将确保 ETS 算法得到有效使用并获得最佳预测。
我们在接下来的文章中会使用一个实际例子来展示ETS 模型以及对比ARIMA 系列模型来说明其与ETS的根本区别,以及如何使现实解决方法得到有效受益。我们之后也会介绍各个不同时间序列的统计学模型以及深度学习模型在时间序列上的应用及优缺点。















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









